


Les chercheurs en IA ignorent souvent l’intuition humaine, mais en fait nous-mêmes ne comprenons pas pleinement sa subtilité. Récemment, une équipe de recherche de Virginia Tech et Microsoft a proposé un algorithme de pensée (AoT) qui combine des capacités intuitives avec des méthodes algorithmiques pour non seulement garantir les performances du LLM, mais également réduire considérablement les coûts.
Grand modèle de langage Le développement récent a été très rapide , et il a démontré des capacités extraordinaires remarquables à résoudre des problèmes généraux, à générer du code et à suivre des instructions
Alors que les premiers modèles reposaient sur des stratégies de réponse directe, la recherche actuelle s'est orientée vers un raisonnement linéaire Path, qui consiste à décomposer le problème en sous-tâches pour découvrir des solutions, ou utiliser des mécanismes externes pour modifier la génération de jetons en modifiant le contexte.
Semblables à la cognition humaine, les premières stratégies LLM semblaient imiter le système 1 immédiat (réactions rapides), caractérisé par une prise de décision impulsive. En revanche, des méthodes plus récentes telles que la chaîne de pensées (CoT) et l'incitation du moins au plus (L2M) reflètent la nature introspective du système 2 (pensée lente). Il convient de noter que la capacité de raisonnement arithmétique du LLM peut être améliorée en intégrant des étapes de raisonnement intermédiaires.
Cependant, si la tâche nécessite une planification plus approfondie et une exploration mentale plus large, alors les limites de ces méthodes deviennent évidentes. Bien que le CoT intégrant l'autocohérence (CoT-SC) puisse utiliser plusieurs résultats du LLM pour atteindre des résultats consensuels, le manque d'évaluation détaillée peut conduire le modèle dans la mauvaise direction. L’Arbre de la Pensée (ToT) qui émergera en 2023 est une solution remarquable. Un LLM est utilisé pour générer des idées, et un autre LLM est utilisé pour évaluer les mérites de ces idées, suivi d'un cycle « pause-évaluation-continuation ». Ce processus itératif basé sur la recherche arborescente est clairement efficace, notamment pour les tâches ayant de longues suites. Les chercheurs pensent que ce développement consiste à utiliser des outils externes pour améliorer le LLM, de la même manière que les humains utilisent des outils pour contourner les limitations de leur propre mémoire de travail.
D'un autre côté, la méthode LLM améliorée présente également quelques inconvénients. Un problème évident est que le nombre de requêtes et les exigences de calcul vont augmenter considérablement. Chaque requête adressée à une API LLM en ligne telle que GPT-4 entraîne une surcharge importante et entraîne une latence accrue, ce qui est particulièrement important pour les applications en temps réel. La latence accumulée de ces requêtes peut réduire l’efficacité globale du scénario. Du côté de l'infrastructure, une interaction constante exerce une pression sur le système, limitant potentiellement la bande passante et réduisant la disponibilité des modèles. De plus, l’impact sur l’environnement ne peut être ignoré. Les requêtes fréquentes augmenteront la consommation d’énergie du centre de données déjà énergivore et augmenteront encore l’empreinte carbone
L’objectif d’optimisation des chercheurs est de réduire considérablement le nombre actuel. de requêtes utilisées par la méthode d'inférence multi-requêtes. Une telle optimisation peut permettre aux modèles de gérer des tâches qui nécessitent une application compétente des connaissances du monde et guider les gens à utiliser les ressources de l'IA de manière plus responsable et plus compétente
En réfléchissant à l'évolution du LLM du système 1 au système 2, nous pouvons voir une clé Le facteur est apparu : les algorithmes. Les algorithmes sont méthodiques et permettent aux individus d’explorer les problématiques, de formuler des stratégies et d’élaborer des solutions. Bien que de nombreuses publications traditionnelles considèrent les algorithmes comme des outils externes du LLM, compte tenu de la capacité de récurrence générative inhérente du LLM, pouvons-nous guider cette logique itérative et internaliser l'algorithme dans le LLM ?
Une équipe de recherche de Virginia Tech et Microsoft a réuni la sophistication du raisonnement humain et la précision méthodique des méthodes algorithmiques, dans le but d'améliorer les capacités de raisonnement au sein du LLM en fusionnant les deux aspects
Selon les recherches existantes, les humains s’appuient instinctivement sur leurs expériences passées lorsqu’ils résolvent des problèmes complexes pour s’assurer qu’ils pensent de manière holistique plutôt que de se concentrer étroitement sur un seul détail. La gamme de générations de LLM n'est limitée que par sa limite symbolique, et elle semble destinée à briser les obstacles de la mémoire de travail humaine.
Inspirés par cette observation, les chercheurs ont commencé à explorer si LLM pouvait être utilisé pour parvenir à une manière hiérarchique similaire de réflexion. En se référant aux étapes intermédiaires précédentes pour exclure les options irréalisables - toutes réalisées dans le cycle de génération du LLM. Les humains sont bons en intuition, tandis que les algorithmes sont bons en exploration organisée et systématique. Les technologies actuelles telles que CoT ont tendance à éviter ce potentiel synergique et à trop se concentrer sur la précision sur site du LLM. En tirant parti des capacités récursives de LLM, les chercheurs ont construit une approche hybride homme-algorithme. Cette approche est obtenue grâce à l'utilisation d'exemples algorithmiques qui capturent l'essence de l'exploration - des candidats initiaux aux solutions éprouvées
Sur la base de ces observations, les chercheurs ont proposé l'algorithme de pensées (AoT).

Le contenu à réécrire est : Papier : https://arxiv.org/pdf/2308.10379.pdf
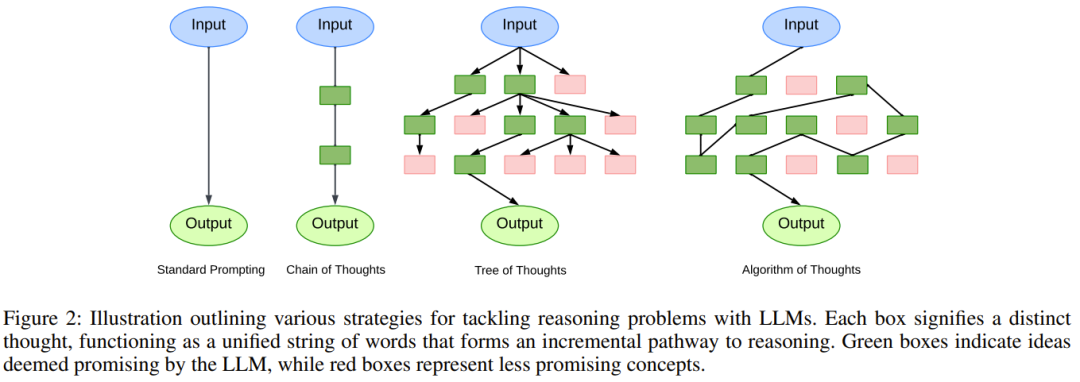
D'un point de vue plus large, cette nouvelle méthode Il devrait donner naissance à un nouveau paradigme d’apprentissage contextuel. Au lieu d'utiliser le modèle d'apprentissage supervisé traditionnel de [question, réponse] ou [question, étapes ultérieures pour obtenir la réponse], cette nouvelle approche adopte un nouveau modèle [question, processus de recherche, réponse]. Naturellement, lorsqu’un LLM est chargé d’utiliser un algorithme, nous nous attendons généralement à ce qu’il imite simplement la pensée itérative de cet algorithme. Cependant, ce qui est intéressant, c'est que LLM a la capacité d'injecter sa propre « intuition », rendant même sa recherche plus efficace que l'algorithme lui-même.
Les chercheurs affirment qu'au cœur de leur stratégie de recherche se trouve la reconnaissance des lacunes majeures du paradigme actuel d'apprentissage contextuel. Bien que CoT puisse améliorer la cohérence des connexions de pensée, des problèmes surviennent parfois, conduisant à de mauvaises étapes intermédiaires
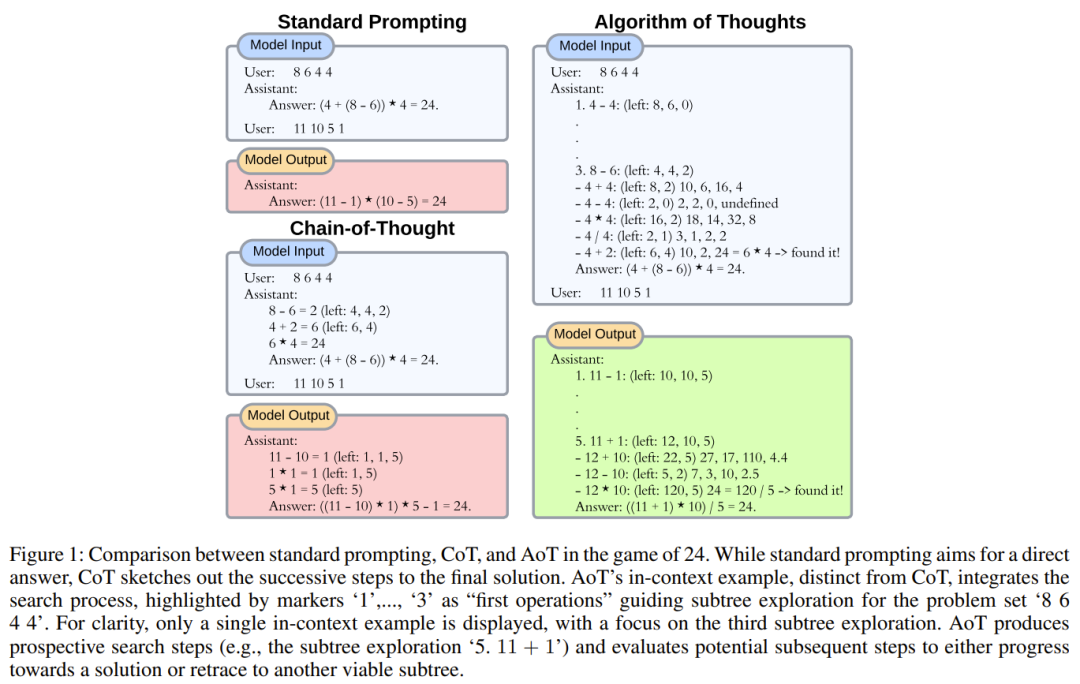
Pour illustrer ce phénomène, les chercheurs ont conçu une expérience. Lors de l'interrogation de text-davinci-003 avec une tâche arithmétique (telle que 11 − 2 =), les chercheurs ajouteront plusieurs équations contextuelles qui produiront le même résultat (telles que 15 − 5 = 10, 8 + 2 = 10).
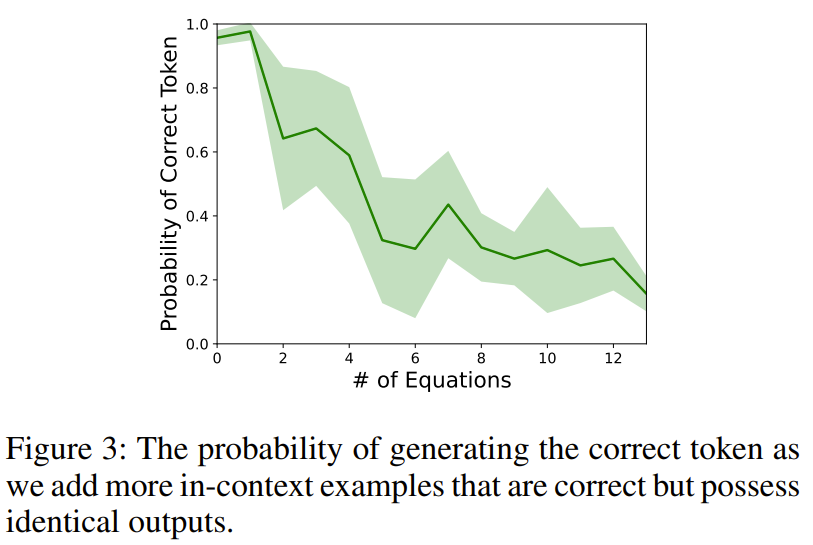
Après enquête, il a été constaté que la précision des résultats a chuté, ce qui suggère que le simple fait de fournir un raisonnement correct dans son contexte peut par inadvertance nuire aux compétences arithmétiques sous-jacentes du LLM
Pour réduire ce biais, laissez les exemples plus de diversité pourrait être une solution viable, mais cela pourrait légèrement modifier la répartition des résultats. Le simple fait d'ajouter quelques tentatives infructueuses (comme une recherche aléatoire) peut encourager par inadvertance le modèle à réessayer sans réellement résoudre le problème. Comprenant la véritable nature du comportement algorithmique (où les recherches échouées et les récupérations ultérieures sont importantes, ainsi que l'apprentissage de ces tentatives), la façon dont les chercheurs intègrent des exemples contextuels consiste à suivre le modèle des algorithmes de recherche, en particulier la recherche en profondeur d'abord (DFS) et Recherche en largeur d'abord (BFS). La figure 1 donne un exemple.
L'objectif principal de cet article est une classe de tâches similaires aux problèmes de recherche arborescente
Pour ce type de tâches, il est nécessaire de décomposer le problème principal et de construire une solution réalisable pour chaque partie. Nous devons ensuite décider d’adopter ou d’abandonner certaines voies, et éventuellement choisir de réévaluer celles qui ont le plus grand potentiel.
L’approche des chercheurs consiste à tirer parti des capacités itératives du LLM pour résoudre dans une analyse générative unifiée les questions de requête pour chaque sous-ensemble. En se limitant à une ou deux interactions LLM, l'approche peut naturellement intégrer les idées des candidats contextuels précédents et résoudre des problèmes complexes qui nécessitent une exploration approfondie du domaine de solution. Les chercheurs fournissent également des informations sur la taille de l'esprit et sur le type d'exemples contextuels à fournir LLM pour améliorer l'efficacité des jetons. Les composants clés de l'algorithme de recherche arborescente et leur représentation dans le nouveau cadre seront présentés ci-dessous
1. Décomposer en sous-problèmes. Face à un problème, construire un arbre de recherche décrivant des chemins de raisonnement réalisables est déjà une tâche difficile même sans examiner les aspects réels de la résolution du problème. Toute décomposition doit prendre en compte non seulement les relations entre les sous-tâches, mais également la facilité de résoudre chaque problème.
Prenons comme exemple une simple addition à plusieurs chiffres : bien qu'il soit efficace pour les ordinateurs de convertir des valeurs numériques en nombres binaires, les humains trouvent généralement les nombres décimaux plus intuitifs. De plus, même si les sous-problèmes sont les mêmes, les méthodes d’exécution peuvent être différentes. L’intuition peut trouver des raccourcis entre les étapes menant à une solution, et sans intuition, des étapes plus détaillées peuvent être nécessaires.
Afin de créer l'invite correcte (c'est-à-dire un exemple d'algorithme contextuel), ces subtilités sont très importantes et déterminent le nombre minimum de jetons requis pour que LLM obtienne des performances fiables. Cela satisfait non seulement aux contraintes de contexte de LLM, mais est également important pour la capacité de LLM à résoudre des problèmes qui résonnent avec son contexte en utilisant une quantité similaire de jetons.
2. Proposez une solution à la sous-question. L'une des méthodes courantes actuelles consiste à échantillonner directement la probabilité de sortie du jeton LLM. Bien que cette méthode soit efficace pour les réponses ponctuelles (avec certaines limites), elle est également incapable de gérer certains scénarios, par exemple lorsque la séquence d'échantillons doit être intégrée dans une invite ultérieure ou évaluée dans une invite ultérieure. Pour minimiser les requêtes de modèle, les chercheurs ont utilisé un processus de création de solutions non-stop. Autrement dit, générer directement et continuellement des solutions aux principaux sous-problèmes sans aucune pause de génération.
Contenu réécrit : Cette méthode présente de nombreux avantages. Premièrement, toutes les réponses générées se trouvent dans le même contexte partagé, ce qui élimine le besoin de générer des requêtes de modèle distinctes pour chaque réponse à des fins d'évaluation. Deuxièmement, même si cela peut sembler contre-intuitif au premier abord, les probabilités de marqueurs isolés ou de groupes de marqueurs ne conduisent pas toujours à des sélections significatives. La figure 4 montre un schéma simple

3. Mesurer les perspectives de sous-problèmes. Comme mentionné ci-dessus, les techniques existantes s'appuient sur des indices supplémentaires pour identifier le potentiel des nœuds d'arbre afin d'aider à prendre des décisions sur les directions d'exploration. Nos observations suggèrent que le LLM a intrinsèquement tendance à donner la priorité aux candidats prometteurs s'ils peuvent être résumés dans des exemples contextuels. Cela réduit le besoin d’une ingénierie d’invite complexe et permet l’intégration d’heuristiques sophistiquées, qu’elles soient intuitives ou basées sur les connaissances. De même, la nouvelle méthode n'inclut pas d'invites disjointes, ce qui permet une évaluation immédiate de la faisabilité du candidat au sein du même résultat généré.
4. Revenez à un meilleur nœud. Le choix du nœud à explorer ensuite (y compris le retour aux nœuds précédents) dépend essentiellement de l'algorithme de recherche arborescente choisi. Bien que des recherches antérieures aient utilisé des méthodes externes telles que des mécanismes de codage pour le processus de recherche, cela limiterait son attrait plus large et nécessiterait une personnalisation supplémentaire. Le nouveau design proposé dans cet article adopte principalement la méthode DFS complétée par l'élagage. L'objectif est de maintenir la proximité entre les nœuds enfants avec le même nœud parent, encourageant ainsi LLM à donner la priorité aux fonctionnalités locales par rapport aux fonctionnalités distantes. En outre, les chercheurs ont également proposé des indicateurs de performance de la méthode AoT basée sur BFS. Les chercheurs affirment que le besoin de mécanismes de personnalisation supplémentaires peut être éliminé en tirant parti de la capacité inhérente du modèle à tirer des enseignements d'exemples contextuels.
Les chercheurs ont mené une expérience sur des mini-jeux de mots de 24 points et 5x5. Les résultats montrent que la méthode AoT surpasse les méthodes à invite unique (telles que les méthodes standard, CoT, CoT-SC) en termes de performances et est également comparable aux méthodes qui utilisent des mécanismes externes (tels que ToT)
Cela est clairement visible à partir du tableau 1, il s'avère que la méthode de recherche arborescente utilisant LLM est nettement meilleure que la méthode de conception d'invite standard combinant CoT/CoT-SC
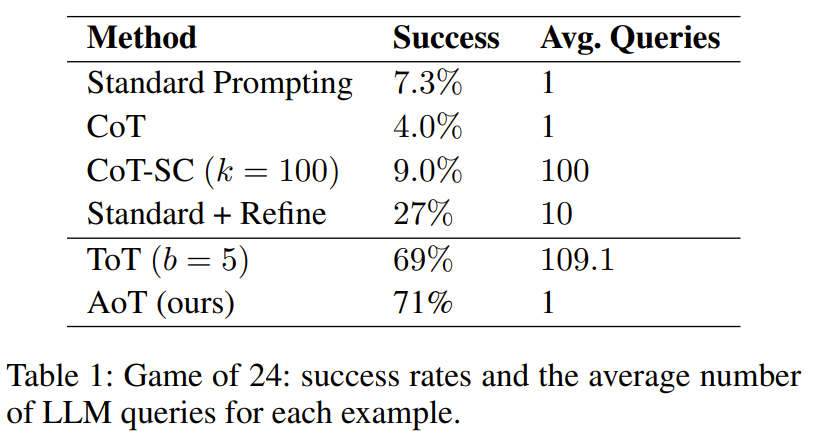
Dans la mini tâche de remplissage de mots, le tableau 3 montre l'efficacité de l'AoT et son taux de réussite en matière de remplissage de mots surpasse les méthodes précédentes en utilisant diverses techniques d'incitation

Cependant, il est pire que ToT. Une observation importante est que le volume de requêtes utilisé par ToT est énorme, dépassant de plus de cent fois celui de l’AoT. Un autre facteur qui rend l’AoT inférieur au ToT est que les capacités de retour en arrière inhérentes aux exemples algorithmiques ne sont pas entièrement activées. Si cette capacité pouvait être entièrement débloquée, cela entraînerait une phase de génération beaucoup plus longue. En revanche, ToT a l’avantage d’utiliser une mémoire externe pour le backtracking.
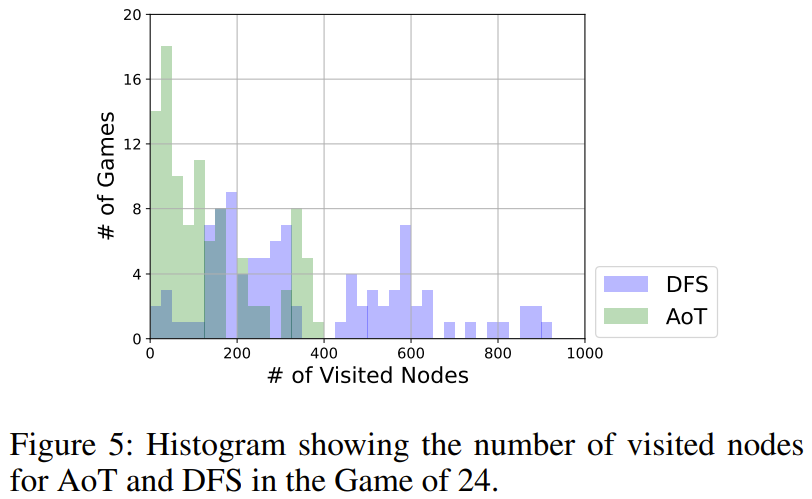
AoT peut-il réaliser une percée basée sur l'imitation de DFS ?
Comme le montre la figure 5, AoT utilise globalement moins de nœuds que la version DFS. DFS adopte une stratégie unifiée dans la sélection des sous-arbres à explorer, tandis que le LLM d'AoT intègre ses heuristiques inhérentes. Cette amplification de l'algorithme de base reflète les avantages des capacités de raisonnement récursif de LLM
Comment le choix de l'algorithme affectera-t-il les performances de l'AoT ?
Trouvé dans l'expérience, le tableau 5 montre que les trois variantes AoT sont supérieures au CoT pour une seule requête
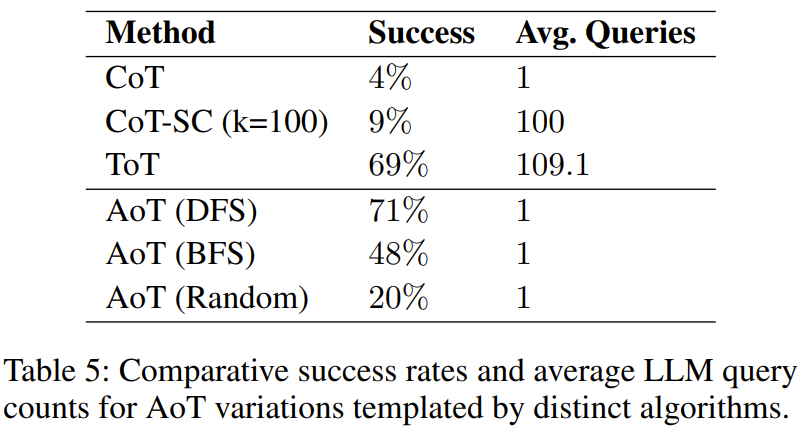
Ce résultat est comme prévu puisqu'il recherche quel que soit l'algorithme et revisite les erreurs potentielles - soit par des tentatives aléatoires dans la variante de recherche aléatoire, soit par un retour en arrière dans une configuration de recherche en profondeur d'abord (DFS) ou de recherche en largeur d'abord (BFS). Il convient de noter que l'efficacité des recherches structurées, la version DFS d'AoT et la version BFS d'AoT, sont toutes deux meilleures que la version aléatoire d'AoT, ce qui met en évidence les avantages des informations algorithmiques dans la découverte de solutions. Cependant, la version BFS d'AoT est en retard par rapport à la version DFS d'AoT. En analysant plus en détail les erreurs de la version BFS d'AoT, les chercheurs ont découvert que par rapport à la version DFS d'AoT, la version BFS d'AoT est plus difficile à identifier la meilleure opération
Lors de l'ajustement du comportement d'AoT, nous avons besoin faire attention aux exemples d'algorithmes Le nombre d'étapes de recherche
montre dans la figure 6 l'impact du nombre total d'étapes de recherche. Parmi eux, AoT (long) et AoT (court) représentent respectivement des versions plus longues et plus courtes par rapport aux résultats originaux générés par l'AoT
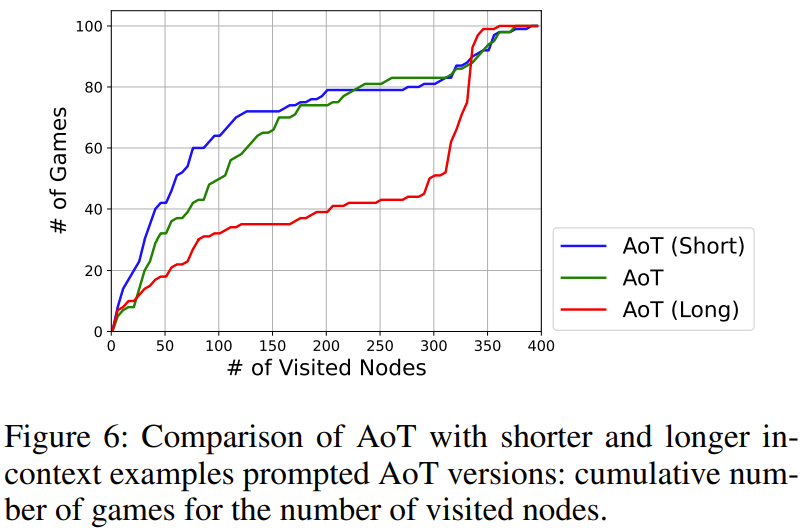
Les résultats de recherche montrent que l'étape de recherche produira un biais implicite dans la vitesse de recherche du LLM. . Il est important de noter que même en cas de faux pas, il est toujours important de mettre l’accent sur l’exploration de directions à potentiel
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 Comment résoudre le problème selon lequel la valeur de retour scanf est ignorée
Comment résoudre le problème selon lequel la valeur de retour scanf est ignorée
 Solution d'erreur d'application de fichier Win10 taskmgr.exe
Solution d'erreur d'application de fichier Win10 taskmgr.exe
 emplacement.assign
emplacement.assign
 Explication détaillée de la commande imp dans Oracle
Explication détaillée de la commande imp dans Oracle
 Solution au code d'erreur d'affichage de l'ordinateur 651
Solution au code d'erreur d'affichage de l'ordinateur 651
 Solution à l'invite d'écran noir de l'ordinateur manquant avec le système d'exploitation
Solution à l'invite d'écran noir de l'ordinateur manquant avec le système d'exploitation
 L'Apple Store ne peut pas se connecter
L'Apple Store ne peut pas se connecter





















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



