

 Java
JavaQuestions d'entretien
Terminal Alibaba : 1 million de demandes de connexion par jour, 8 Go de mémoire, comment définir les paramètres JVM ?
Java
JavaQuestions d'entretien
Terminal Alibaba : 1 million de demandes de connexion par jour, 8 Go de mémoire, comment définir les paramètres JVM ?
Terminal Alibaba : 1 million de demandes de connexion par jour, 8 Go de mémoire, comment définir les paramètres JVM ?
Après deux ans, j'ai révisé plus de 100 CV et mené plus de 200 simulations d'entretiens.
La semaine dernière, un camarade de classe s'est vu poser cette question lors de l'entretien technique avec Alibaba Cloud : Supposons une plate-forme avec 1 million de demandes de connexion par jour et un nœud de service avec 8 Go de mémoire. Définir les paramètres JVM ? Si vous pensez que la réponse n'est pas idéale, venez me demander un avis.
Si vous avez également besoin d'une modification de CV, d'une embellissement de CV, d'un packaging de CV, de simulations d'entretiens, etc., vous pouvez me contacter.
Ce qui suit est trié pour vous sous forme de questions d'entretien, afin de faire d'une pierre deux coups :
C'est à la fois pour votre référence pratique et pour votre référence d'entretien
Tout le monde doit apprendre, à l'exception du schéma de configuration JVM. De plus, c'est la manière d'analyser les problèmes et la perspective de réfléchir aux problèmes. Ces idées et perspectives peuvent aider chacun à aller toujours plus loin.
Ensuite, entrons dans le vif du sujet.
Comment définir les paramètres JVM avec 1 million de demandes de connexion par jour et 8 Go de mémoire ?
Comment définir les paramètres JVM pour 1 million de demandes de connexion par jour et 8 Go de mémoire peut être grossièrement divisé en 8 étapes suivantes.
Étape 1 : Comment planifier la capacité lors du lancement du nouveau système ?
1. Résumé des routines
Tout nouveau système d'entreprise doit estimer la configuration du serveur et les paramètres de mémoire JVM avant d'être mis en ligne. Cette planification des capacités et des ressources n'est pas simplement une estimation aléatoire de l'architecte système, elle doit l'être. basé sur Estimez le scénario commercial où se trouve le système, déduisez un modèle de fonctionnement du système et évaluez des indicateurs tels que les performances de la JVM et la fréquence du GC. Voici une étape de modélisation que j'ai résumée sur la base de l'expérience d'experts et de ma propre pratique :
Calculez la quantité d'espace mémoire que les objets créés par le système métier occuperont par seconde, puis calculez l'espace mémoire par seconde (vitesse de création d'objet) de chaque système sous le cluster Définissez une configuration de machine et estimez la espace de nouvelle génération, comparez la fréquence à laquelle MinorGC est déclenché sous différentes tailles de nouvelle génération. Afin d'éviter des GC fréquents, vous pouvez réestimer le nombre de configurations de machines nécessaires, le nombre de machines déployées, la quantité d'espace mémoire accordée à la JVM et la quantité d'espace accordée à la nouvelle génération. Sur la base de cet ensemble de configurations, nous pouvons essentiellement calculer le modèle de fonctionnement de l'ensemble du système, combien d'objets sont créés par seconde, qui deviendront des déchets après 1 seconde, combien de temps le système fonctionne et à quelle fréquence les nouveaux la génération déclenchera GC.
2. Pratique de routine - prenons la connexion au système comme exemple
Certains étudiants sont encore confus après avoir vu ces étapes, et ils semblent en parler. Quand il s'agit de projets réels, je ne le fais toujours pas. je ne sais pas comment faire !
Parlez simplement sans pratiquer de trucs, prenez le système de connexion comme exemple pour simuler le processus de déduction :
Supposons qu'il y ait 1 million de demandes de connexion par jour et que le pic de connexion se situe le matin. On estime qu'il y aura 100 demandes de connexion par seconde pendant la période de pointe. Supposons que 3 serveurs soient déployés et que chaque machine gère 30 demandes de connexion par seconde. Supposons qu'une demande de connexion doit être traitée pendant 1 seconde. La nouvelle génération de JVM générera 30 objets de connexion chaque seconde. terminé après 1 seconde. L'objet devient un déchet. En supposant qu'un objet de demande de connexion comporte 20 champs, un objet est estimé à 500 octets et 30 connexions occupent environ 15 Ko. En tenant compte des opérations RPC et DB, de la communication réseau, de la bibliothèque d'écriture et du cache d'écriture, il peut. être étendu jusqu'à 20 à 50 fois, générant des centaines de données k-1M en environ 1 seconde. En supposant qu'une machine 2C4G soit déployée et qu'une mémoire tas 2G soit allouée, la nouvelle génération ne représente que quelques centaines de M. Selon le taux de génération de déchets de 1s1M, MinorGC sera déclenché une fois toutes les centaines de secondes. Supposons qu'une machine 4C8G soit déployée, qu'une mémoire tas 4G soit allouée et que 2G soient alloués à la nouvelle génération. Il faudra plusieurs heures pour déclencher MinorGC.
Donc, on peut en déduire grossièrement qu'un système de connexion avec 1 million de requêtes par jour, selon la configuration du cluster à 3 instances de 4C8G, allouant 4G de mémoire tas et 2G de JVM de nouvelle génération peut assurer une charge normale du système .
Évaluez essentiellement les ressources d'un nouveau système, de sorte que la capacité et la configuration nécessaires à chaque instance pour construire un nouveau système, le nombre d'instances configurées dans le cluster, etc., ne peuvent pas être décidés en tapotant la tête et la poitrine.
Étape 2 : Comment choisir un éboueur ?
Débit ou temps de réponse
Introduisez d'abord deux concepts : le débit et la faible latence
Débit = temps CPU pour exécuter les applications utilisateur / (temps CPU pour exécuter les applications utilisateur + temps de récupération de place du processeur)
Temps de réponse = consommation moyenne de temps GC
Habituellement, le débit est priorisé ou la réponse est priorisée, c'est un dilemme dans la JVM.
À mesure que la mémoire du tas augmente, la quantité que gc peut traiter en une seule fois devient plus grande et le débit est plus élevé. Cependant, le temps nécessaire pour un gc deviendra plus long, ce qui entraînera un temps d'attente plus long pour les threads en file d'attente ; au contraire, si la mémoire du tas est petite, le temps d'un gc sera court, le temps d'attente des threads en attente dans la file d'attente devient plus court et le délai est réduit, mais le nombre de requêtes simultanées devient plus petit (pas absolument cohérent).
Il est impossible de donner la priorité au débit ou à la réponse en même temps. C'est une question qui doit être pesée.
Considérations dans la conception du garbage collector
La JVM ne permet pas le garbage collection et la création de nouveaux objets pendant le GC (tout comme vous ne pouvez pas nettoyer et jeter les déchets en même temps). JVM nécessite un temps de pause Stop the World, et STW entraînera une brève pause du système et sera incapable de traiter aucune demande. La nouvelle génération a une fréquence de collecte élevée, une priorité de performances et des algorithmes de réplication couramment utilisés ; ; l'ancienne génération a une basse fréquence et est sensible à l'espace, évitez les méthodes de copie. L'objectif de tous les éboueurs est de rendre les GC moins fréquents, plus courts et de réduire l'impact des GC sur le système !
CMS et G1
La configuration actuelle du garbage collector principal consiste à utiliser ParNew dans la nouvelle génération et la combinaison CMS dans l'ancienne génération, ou à utiliser complètement le collecteur G1
Du point de vue des tendances futures, G1 est le. officiel Éboueur maintenu et plus respecté.
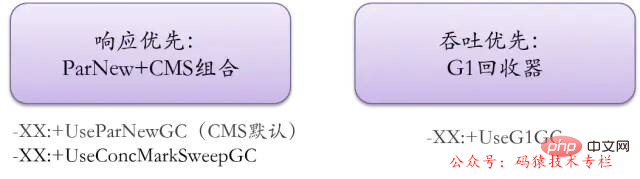
Système d'entreprise :
CMS recommandé pour les services sensibles à la latence Pour les services à grande mémoire nécessitant un débit élevé, utilisez le recycleur G1 !
Mécanisme de fonctionnement du garbage collector CMS
CMS est principalement un collecteur pour l'ancienne génération. Par défaut, il exécutera un algorithme de défragmentation après un algorithme FullGC pour nettoyer les fragments de mémoire.
| CMS GC | Description | Arrêtez le monde | Vitesse |
|---|---|---|---|
| 1. Marque de départ | La marque initiale marque uniquement les objets avec lesquels GCRoots peut s'associer directement, ce qui est très rapide | Oui | Bientôt |
| 2. Marquage simultané | La phase de marquage simultané est le processus de traçage GCRoots | Non | Lent |
| 3. erreur de programme lors du marquage simultané Enregistrement de marque de la partie de l'objet qui continue de fonctionner et provoque des modifications de marque. | Oui | Rapide | |
| 4. Collecte des déchets | Nettoyage simultané des objets poubelles (algorithme de marquage et de balayage) | Non | Lent |
Avantages : collecte simultanée, privilégiant la « faible latence ». Aucun STW n'a eu lieu dans les deux étapes les plus longues, et les étapes nécessitant un STW ont été réalisées très rapidement. Inconvénients : 1. Consommation du processeur ; 2. Déchets flottants 3. Fragmentation de la mémoire Scénarios applicables : Faites attention à la vitesse de réponse du serveur et nécessitez le temps de pause du système le plus court.
En bref :
CM est recommandé pour les systèmes d'entreprise sensibles à la latence ;
pour les services de mémoire volumineux qui nécessitent un débit élevé, utilisez le recycleur G1 !
Étape 3 : Comment planifier la proportion et la taille de chaque partition
L'idée générale est la suivante :
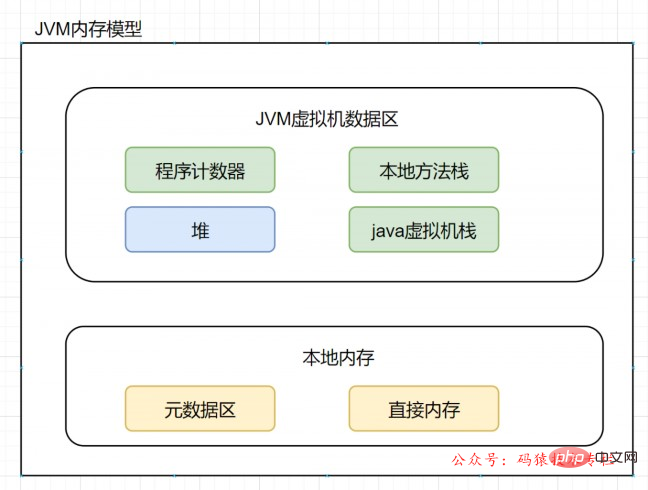
Tout d'abord, le paramètre le plus important et le plus central de la JVM est d'évaluer la mémoire et l'allocation. La première étape. est de spécifier la taille du tas, c'est ce qui doit être fait lorsque le système est en ligne. -Xms est la taille initiale du tas, -Xmx est la taille maximale du tas dans le service Java en arrière-plan, elle est généralement désignée comme la moitié de. la mémoire système. Si elle est trop grande, elle occupera les ressources système du serveur. Si elle est trop petite, la JVM ne pourra pas être utilisée de manière optimale.
Deuxièmement, vous devez spécifier la taille de la nouvelle génération de -Xmn. Ce paramètre est très critique et très flexible. Bien que Sun recommande officiellement une taille de 3/8, elle doit être déterminée en fonction du scénario commercial et est ciblée. pour les services sans état ou à état léger (maintenant pour les systèmes d'entreprise les plus courants (tels que les applications Web), la nouvelle génération peut généralement même recevoir 3/4 de la taille de la mémoire tas ; pour les services avec état (communs tels que les services de messagerie instantanée, les passerelles couche d'accès et autres systèmes), la nouvelle génération peut recevoir la valeur par défaut. Réglez le rapport sur 1/3. Le service est avec état, ce qui signifie qu'il y aura plus d'informations de cache local et d'état de session résidant en mémoire, donc plus d'espace devrait être configuré dans l'ancienne génération pour stocker ces objets.
Enfin, définissez la taille de la mémoire de la pile -Xss et définissez la taille de la pile d'un seul thread. La valeur par défaut est liée à la version et au système du JDK, et est généralement définie par défaut sur 512 ~ 1024 Ko. Si un service d’arrière-plan possède des centaines de threads résidents, la mémoire de la pile occupera également des centaines de M.
Paramètres JVM mémoire à moitié| Taille maximale de la mémoire du tas Java | Mémoire du tas Java 4/1 | la moitié de la mémoire du système d'exploitation | |
|---|---|---|---|
| 1/3 du montant réduit | sun recommande 3/8 | ||
| -Xss | La taille de la mémoire de pile de chaque thread | est liée à idk | sun |
Pour la mémoire 8G, il suffit généralement d'allouer la moitié de la mémoire maximale. Parce que la machine occupe encore une certaine quantité de mémoire, la mémoire 4G est généralement allouée à la JVM
Introduction d'un lien de test de résistance aux performances, testant les étudiants. appuyez sur l'interface de connexion pendant 1 seconde. La vitesse de génération d'objet est de 60 M, en utilisant le recycleur combiné de ParNew+CMS
La configuration normale des paramètres JVM est la suivante :
-Xms3072M -Xmx3072M -Xss1M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:SurvivorRatio=8
Un tel paramètre peut provoquer des gc complets fréquents en raison de la dynamique. principe de jugement sur l'âge de l'objet. Pourquoi?
Pendant le test de stress, la zone Eden sera pleine dans un court laps de temps (par exemple, après 20 secondes). Lors d'une nouvelle exécution à ce moment-là, les objets ne pourront pas être alloués et MinorGC sera déclenché. que S1 charge 100M après ce GC, et il passera immédiatement. MinorGC sera à nouveau déclenché dans 20S. Les 100M d'objets survivants supplémentaires + 100M dans la zone S1 ne peuvent plus être placés avec succès dans la zone S2. Le mécanisme d'âge de la JVM sera déclenché et un lot d'objets d'environ 100 Mo sera poussé vers l'ancienne génération pour le stockage, s'il continue à fonctionner pendant un certain temps, le système peut déclencher un FullGC dans une heure.
Lorsqu'elle est allouée selon le ratio par défaut de 8:1:1, la zone de survivant n'est qu'environ 10 % de 1G, soit des dizaines pour 100M,
如果 每次minor GC垃圾回收过后进入survivor对象很多,并且survivor对象大小很快超过 Survivor 的 50% , 那么会触发动态年龄判定规则,让部分对象进入老年代.
而一个GC过程中,可能部分WEB请求未处理完毕, 几十兆对象,进入survivor的概率,是非常大的,甚至是一定会发生的.
如何解决这个问题呢?为了让对象尽可能的在新生代的eden区和survivor区, 尽可能的让survivor区内存多一点,达到200兆左右,
于是我们可以更新下JVM参数设置:
-Xms3072M -Xmx3072M -Xmn2048M -Xss1M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:SurvivorRatio=8 说明: ‐Xmn2048M ‐XX:SurvivorRatio=8 年轻代大小2g,eden与survivor的比例为8:1:1,也就是1.6g:0.2g:0.2g
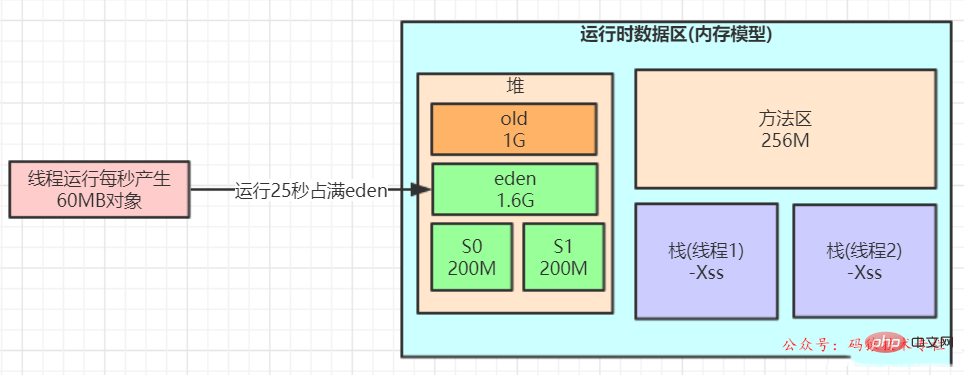
survivor达到200m,如果几十兆对象到底survivor, survivor 也不一定超过 50%
这样可以防止每次垃圾回收过后,survivor对象太早超过 50% ,
这样就降低了因为对象动态年龄判断原则导致的对象频繁进入老年代的问题,
Quelles sont les règles de détermination dynamique de l'âge de la JVM ?
Règles de jugement d'âge dynamique pour les objets entrant dans l'ancienne génération (seuil de calcul de l'âge de promotion dynamique) : Lors du GC Mineur, lorsque la taille des objets d'âge 1 à N chez le Survivant dépasse 50 % du Survivant, les objets supérieurs ou égal à l'âge N sera placé Saisie de la vieillesse.
La stratégie d'optimisation de base est de conserver autant que possible les objets survivants à court terme dans le survivant et de ne pas entrer dans l'ancienne génération. De cette façon, ces objets seront recyclés lors des gc mineurs et n'entreront pas dans l'ancienne génération et causeront. gc complet.
Comment évaluer la mémoire nouvelle génération et l'allouer de manière appropriée ?
Mention spéciale ici, le paramètre le plus important et essentiel de la JVM est d'évaluer la mémoire et l'allocation.
La première étape consiste à spécifier la taille de la mémoire du tas. Ceci est requis lorsque le système est mis en ligne. , -Xmx La taille maximale du tas est généralement spécifiée comme étant la moitié de la mémoire système dans les services Java en arrière-plan. Si elle est trop grande, elle occupera les ressources système du serveur. Si elle est trop petite, les meilleures performances de la JVM ne seront pas possibles. être exercé.
Deuxièmement, vous devez spécifier la taille de la nouvelle génération de -Xmn. Ce paramètre est très critique et a une grande flexibilité. Bien que Sun recommande officiellement une taille de 3/8, elle doit être déterminée en fonction du scénario métier :
.Pour les services sans état ou à état léger (maintenant les systèmes d'entreprise les plus courants tels que les applications Web), la nouvelle génération peut généralement même recevoir les 3/4 de la taille de la mémoire tas Pour les services avec état (systèmes courants ; tels que les services de messagerie instantanée, les couches d'accès à la passerelle, etc.) La nouvelle génération peut être définie selon le ratio par défaut de 1/3.
Le service est avec état, ce qui signifie qu'il y aura plus d'informations de cache local et d'état de session résidant en mémoire, ce qui signifie que plus d'espace devrait être mis en place pour l'ancienne génération pour stocker ces objets.
étape 4 : Quelle est la taille de mémoire de pile appropriée ?
-Taille de la mémoire de la pile Xss, définissez la taille de la pile d'un seul thread. La valeur par défaut est liée à la version et au système du JDK, et est généralement définie par défaut sur 512 ~ 1024 Ko. Si un service d’arrière-plan possède des centaines de threads résidents, la mémoire de la pile occupera également des centaines de M.
étape 5 : Quel est l'âge de l'objet avant qu'il convient de le déplacer vers l'ancienne génération ?
En supposant qu'un gc mineur prend vingt à trente secondes et que la plupart des objets deviennent généralement des déchets en quelques secondes,
Si l'objet n'a pas été recyclé depuis si longtemps, par exemple, il n'a pas été recyclé depuis 2 minutes, on peut considérer que ces objets sont des objets qui survivront longtemps et seront donc déplacés vers l'ancienne génération au lieu de continuer à occuper l'espace de la zone survivant.
所以,可以将默认的15岁改小一点,比如改为5,
那么意味着对象要经过5次minor gc才会进入老年代,整个时间也有一两分钟了(5*30s= 150s),和几秒的时间相比,对象已经存活了足够长时间了。
所以:可以适当调整JVM参数如下:
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐XX:SurvivorRatio=8 ‐XX:MaxTenuringThreshold=5
step6:多大的对象,可以直接到老年代比较合适?
对于多大的对象直接进入老年代(参数-XX:PretenureSizeThreshold),一般可以结合自己系统看下有没有什么大对象 生成,预估下大对象的大小,一般来说设置为1M就差不多了,很少有超过1M的大对象,
所以:可以适当调整JVM参数如下:
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐XX:SurvivorRatio=8 ‐XX:MaxTenuringThreshold=5 ‐XX:PretenureSizeThreshold=1M
step7:垃圾回收器CMS老年代的参数优化
JDK8默认的垃圾回收器是-XX:+UseParallelGC(年轻代)和-XX:+UseParallelOldGC(老年代),
如果内存较大(超过4个G,只是经验 值),还是建议使用G1.
这里是4G以内,又是主打“低延时” 的业务系统,可以使用下面的组合:
ParNew+CMS(-XX:+UseParNewGC -XX:+UseConcMarkSweepGC)
新生代的采用ParNew回收器,工作流程就是经典复制算法,在三块区中进行流转回收,只不过采用多线程并行的方式加快了MinorGC速度。
老生代的采用CMS。再去优化老年代参数:比如老年代默认在标记清除以后会做整理,还可以在CMS的增加GC频次还是增加GC时长上做些取舍,
如下是响应优先的参数调优:
XX:CMSInitiatingOccupancyFraction=70
设定CMS在对内存占用率达到70%的时候开始GC(因为CMS会有浮动垃圾,所以一般都较早启动GC)
XX:+UseCMSInitiatinpOccupancyOnly
和上面搭配使用,否则只生效一次
-XX:+AlwaysPreTouch
强制操作系统把内存真正分配给IVM,而不是用时才分配。
综上,只要年轻代参数设置合理,老年代CMS的参数设置基本都可以用默认值,如下所示:
‐Xms3072M ‐Xmx3072M ‐Xmn2048M ‐Xss1M ‐XX:MetaspaceSize=256M ‐XX:MaxMetaspaceSize=256M ‐XX:SurvivorRatio=8 ‐XX:MaxTenuringThreshold=5 ‐XX:PretenureSizeThreshold=1M ‐XX:+UseParNewGC ‐XX:+UseConcMarkSweepGC ‐XX:CMSInitiatingOccupancyFraction=70 ‐XX:+UseCMSInitiatingOccupancyOnly ‐XX:+AlwaysPreTouch
参数解释
1.‐Xms3072M ‐Xmx3072M 最小最大堆设置为3g,最大最小设置为一致防止内存抖动
2.‐Xss1M 线程栈1m
3.‐Xmn2048M ‐XX:SurvivorRatio=8 年轻代大小2g,eden与survivor的比例为8:1:1,也就是1.6g:0.2g:0.2g
4.-XX:MaxTenuringThreshold=5 年龄为5进入老年代 5.‐XX:PretenureSizeThreshold=1M 大于1m的大对象直接在老年代生成
6.‐XX:+UseParNewGC ‐ XX:+UseConcMarkSweepGC 使用ParNew+cms垃圾回收器组合‐XX:+UseParNewGC ‐XX:+UseConcMarkSweepGC 使用ParNew+cms垃圾回收器组合
7.‐XX:CMSInitiatingOccupancyFraction=70 老年代中对象达到这个比例后触发fullgc
8.‐XX:+UseCMSInitiatinpOccupancyOnly 老年代中对象达到这个比例后触发fullgc,每次
9.‐XX:+AlwaysPreTouch
‐XX:CMSInitiatingOccupancyFraction=70 老年代中对象达到这个比例后触发fullgc8.‐XX:+AlwaysPreTouch code> 强制操作系统把内存真正分配给IVM,而不是用时才分配。
step8:配置OOM时候的内存dump文件和GC日志
🎜🎜额外增加了GC日志打印、OOM自动dump等配置内容,帮助进行问题排查🎜-XX:+HeapDumpOnOutOfMemoryError
在Out Of Memory,JVM快死掉的时候,输出Heap Dump到指定文件。
不然开发很多时候还真不知道怎么重现错误。
路径只指向目录,JVM会保持文件名的唯一性,叫java_pid${pid}.hprof。
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=${LOGDIR}/
因为如果指向特定的文件,而文件已存在,反而不能写入。
输出4G的HeapDump,会导致IO性能问题,在普通硬盘上,会造成20秒以上的硬盘IO跑满,
需要注意一下,但在容器环境下,这个也会影响同一宿主机上的其他容器。
GC的日志的输出也很重要:
-Xloggc:/dev/xxx/gc.log -XX:+PrintGCDateStamps -XX:+PrintGCDetails
GC的日志实际上对系统性能影响不大,打日志对排查GC问题很重要。
一份通用的JVM参数模板
一般来说,大企业或者架构师团队,都会为项目的业务系统定制一份较为通用的JVM参数模板,但是许多小企业和团队可能就疏于这一块的设计,如果老板某一天突然让你负责定制一个新系统的JVM参数,你上网去搜大量的JVM调优文章或博客,结果发现都是零零散散的、不成体系的JVM参数讲解,根本下不了手,这个时候你就需要一份较为通用的JVM参数模板了,不能保证性能最佳,但是至少能让JVM这一层是稳定可控的,
在这里给大家总结了一份模板:
基于4C8G系统的ParNew+CMS回收器模板(响应优先),新生代大小根据业务灵活调整!
-Xms4g -Xmx4g -Xmn2g -Xss1m -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=10 -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnly -XX:+AlwaysPreTouch -XX:+HeapDumpOnOutOfMemoryError -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -Xloggc:gc.log
如果是GC的吞吐优先,推荐使用G1,基于8C16G系统的G1回收器模板:
G1收集器自身已经有一套预测和调整机制了,因此我们首先的选择是相信它,
即调整-XX:MaxGCPauseMillis=N参数,这也符合G1的目的——让GC调优尽量简单!
同时也不要自己显式设置新生代的大小(用-Xmn或-XX:NewRatio参数),
如果人为干预新生代的大小,会导致目标时间这个参数失效。
-Xms8g -Xmx8g -Xss1m -XX:+UseG1GC -XX:MaxGCPauseMillis=150 -XX:InitiatingHeapOccupancyPercent=40 -XX:+HeapDumpOnOutOfMemoryError -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -Xloggc:gc.log
| G1参数 | 描述 | 默认值 |
|---|---|---|
| XX:MaxGCPauseMillis=N | 最大GC停顿时间。柔性目标,JVM满足90%,不保证100%。 | 200 |
| -XX:nitiatingHeapOccupancyPercent=n | 当整个堆的空间使用百分比超过这个值时,就会融发MixGC | 45 |
Pour -XX:MaxGCPauseMillis Pour code>, le paramétrage a une tendance claire : plus faible ↓ : le délai est plus faible, mais MinorGC est fréquent, MixGC recycle moins l'ancienne zone, et augmente le risque de Full GC. Augmentation ↑ : davantage d'objets seront recyclés à la fois, mais le temps de réponse global du système sera également allongé. <code style='margin-right: 2px;margin-left: 2px;padding: 2px 4px;outline: 0px;font-size: 14px;border-radius: 4px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(255, 93, 108);'>-XX:MaxGCPauseMillis来说,参数的设置带有明显的倾向性:调低↓:延迟更低,但MinorGC频繁,MixGC回收老年代区减少,增大Full GC的风险。调高↑:单次回收更多的对象,但系统整体响应时间也会被拉长。
针对InitiatingHeapOccupancyPercent
InitiatingHeapOccupancyPercent In en d'autres termes, l'effet de l'ajustement de la taille des paramètres est également différent : baisse ↓ : déclenchement de MixGC plus tôt, gaspillage de CPU. Augmentation ↑ : Accumulez plusieurs générations de régions de recyclage, augmentant le risque de FullGC. Résumé du réglage
Idées de réglage complètes avant la mise en ligne du système :1. Estimation commerciale : en fonction de la concurrence attendue et des besoins moyens en mémoire de chaque tâche, évaluez ensuite le nombre de machines nécessaires pour l'héberger, quelle configuration est requise pour chaque machine. 2. Estimation de la capacité : En fonction de la vitesse de traitement des tâches du système, allouez ensuite raisonnablement la taille des zones Eden et Surivior, et la taille de la mémoire de l'ancienne génération. 3. Sélection du recycleur : pour les systèmes avec priorité de réponse, il est recommandé d'utiliser le recycleur ParNew+CMS ; pour les services de grande mémoire multicœur axés sur le débit (taille du tas ≥ 8 G), il est recommandé d'utiliser le recycleur G1. . 🎜4. Idée d'optimisation : laisser les objets à durée de vie courte être recyclés dans l'étape MinorGC (en même temps, les objets survivants après recyclage
5. Le processus de réglage résumé jusqu'à présent est principalement basé sur l'étape de test et de vérification avant la mise en ligne, nous essayons donc de définir les paramètres JVM de la machine à la valeur optimale avant la mise en ligne !
Le réglage JVM n'est qu'un moyen, mais tous les problèmes ne peuvent pas être résolus par le réglage JVM. La plupart des applications Java n'ont pas besoin d'optimisation JVM. Nous pouvons suivre certains des principes suivants :
Avant de vous connecter, vous devez d'abord considérer. régler les paramètres JVM de la machine à l'optimum ; Réduire le nombre d'objets créés (niveau code) Réduire l'utilisation de variables globales et d'objets volumineux (niveau code) ; ajustements Optimisation et réglage du code, l'optimisation JVM est un dernier recours (niveau code et architecture) -
Il vaut mieux analyser la situation du GC et optimiser le code que d'optimiser les paramètres JVM (niveau code) ; En tenant compte des principes ci-dessus, nous avons constaté qu'en fait, la méthode d'optimisation la plus efficace est l'optimisation de l'architecture et du niveau de code, tandis que l'optimisation JVM est le dernier recours, qui peut également être considérée comme la dernière « compression » de la configuration du serveur. . Qu'est-ce que ZGC ?
ZGC (Z Garbage Collector) est un garbage collector développé par Oracle avec une faible latence comme objectif principal.
Il s'agit d'un collecteur basé sur une disposition de mémoire de région dynamique, (temporairement) sans génération d'âge, et utilise des technologies telles que des barrières de lecture, des pointeurs teints et un mappage multiple de mémoire pour implémenter des algorithmes de tri de marques simultanés.
Nouvellement ajouté dans le JDK 11, il est encore au stade expérimental
Les principales fonctionnalités sont : le recyclage des téraoctets de mémoire (maximum 4T), et le temps de pause ne dépasse pas 10 ms.
Avantages : faibles pauses, débit élevé, peu de mémoire supplémentaire consommée lors de la collecte ZGC
Inconvénients : déchets flottants
Actuellement très peu utilisé, et il faut encore du temps d'écriture pour devenir vraiment populaire.
Comment choisir un éboueur ?
Comment choisir dans un scénario réel ? Voici quelques suggestions, j'espère qu'elles vous seront utiles :
1 Si la taille de votre tas n'est pas très grande (par exemple 100 Mo), le choix d'un collecteur en série est généralement la solution. le plus efficace. Paramètres :
-XX:+UseSerialGC code>. <code style='margin-right: 2px;margin-left: 2px;padding: 2px 4px;outline: 0px;font-size: 14px;border-radius: 4px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(255, 93, 108);'>-XX:+UseSerialGC。2、如果你的应用运行在单核的机器上,或者你的虚拟机核数只有 单核,选择串行收集器依然是合适的,这时候启用一些并行收集器没有任何收益。参数:
-XX:+UseSerialGC。3、如果你的应用是“吞吐量”优先的,并且对较长时间的停顿没有什么特别的要求。选择并行收集器是比较好的。参数:
2. Si votre application s'exécute sur une machine monocœur, ou si votre machine virtuelle n'a qu'un seul cœur, il est toujours approprié de choisir un collecteur série. Pour le moment, il n'y a aucun avantage à activer certains collecteurs parallèles. Paramètres :-XX:+UseParallelGC-XX:+UseSerialGC code>. 🎜🎜3. Si votre application donne la priorité au "débit" et n'a pas d'exigences particulières pour les longues pauses. Il est préférable de choisir un collecteur parallèle. Paramètres : <code style="margin-right: 2px;margin-left: 2px;padding: 2px 4px;outline: 0px;font-size: 14px;border-radius: 4px;background-color: rgba(27, 31, 35, 0.05);famille de polices : " operator mono consolas monaco menlo monospace de mot break-all rgb>-XX:+UseParallelGC code>. 🎜<p data-tool="mdnice编辑器" style='margin-top: 0.8em;margin-bottom: 0.8em;padding-top: 8px;padding-bottom: 8px;outline: 0px;color: rgb(53, 53, 53);font-family: Optima-Regular, Optima, PingFangSC-light, PingFangTC-light, "PingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;letter-spacing: 0.8px;text-align: left;white-space: normal;word-spacing: 0.8px;background-color: rgb(255, 255, 255);line-height: 1.75;'>4. Si votre application a des exigences de temps de réponse élevées et souhaite moins de pauses. Même une pause d'une seconde entraînera un grand nombre d'échecs de requêtes, il est donc raisonnable de choisir G1, ZGC ou CMS. Bien que les pauses GC de ces collecteurs soient généralement plus courtes, des ressources supplémentaires sont nécessaires pour gérer le travail et le débit est généralement inférieur. Paramètres : <code style='margin-right: 2px;margin-left: 2px;padding: 2px 4px;outline: 0px;font-size: 14px;border-radius: 4px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(255, 93, 108);'>-XX:+UseConcMarkSweepGC、-XX:+UseG1GC、-XX:+UseZGCetc. À partir des points de départ ci-dessus, nos serveurs Web ordinaires ont des exigences très élevées en matière de réactivité.La sélectivité est en réalité concentrée sur CMS, G1 et ZGC. Pour certaines tâches planifiées, l’utilisation d’un collecteur parallèle constitue un meilleur choix.
Pourquoi Hotspot utilise-t-il le métaespace pour remplacer la génération permanente ?
Qu'est-ce que le métaespace ? Qu'est-ce que la génération permanente ? Pourquoi utiliser le métaespace au lieu de la génération permanente ?
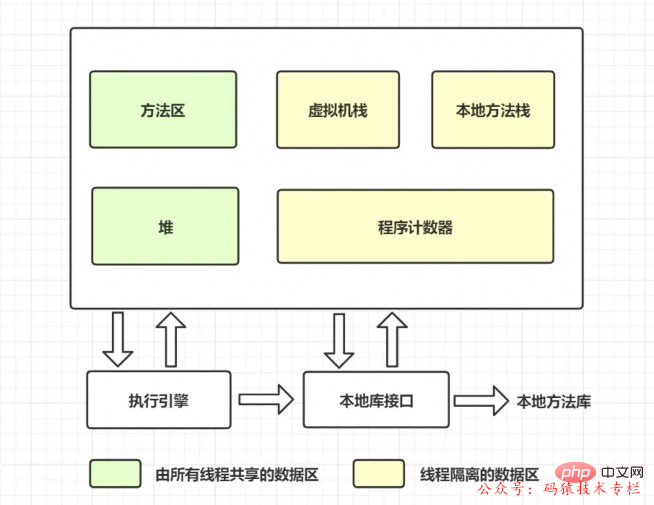
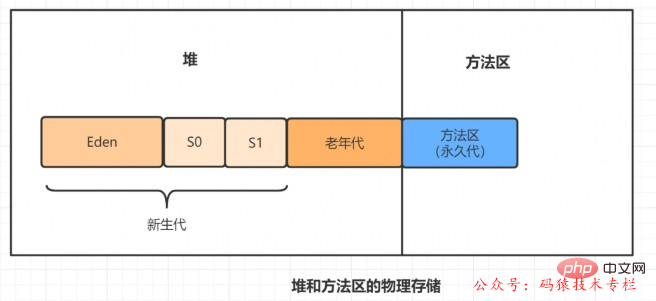
Passons d'abord en revue la zone de méthode et examinons le diagramme de mémoire de données lorsque la machine virtuelle est en cours d'exécution, comme suit :
La zone de méthode, comme le tas, est une zone de mémoire partagée par chaque thread. Elle est utilisée pour stocker des données telles que des informations de classe, des constantes, des variables statiques et du code compilé juste à temps qui ont été chargés par. la machine virtuelle.
Qu'est-ce que la génération permanente ? Qu’est-ce que cela a à voir avec le domaine de la méthode ?
Si vous développez et déployez sur la machine virtuelle HotSpot, de nombreux programmeurs appellent la zone de méthode la génération permanente.
On peut dire que le domaine de la méthode est la spécification et que la génération permanente est la mise en œuvre de la spécification par Hotspot.
Dans Java7 et les versions précédentes, la zone méthode est implémentée dans la génération permanente.
Qu'est-ce que le métaespace ? Qu’est-ce que cela a à voir avec le domaine de la méthode ?
Pour Java8, HotSpots a annulé la génération permanente et l'a remplacée par du métaespace.
En d'autres termes, la zone méthode est toujours là, mais l'implémentation a changé, de la génération permanente au métaespace.
Pourquoi la génération permanente est-elle remplacée par le métaespace ?
La zone méthode de la génération permanente est contiguë à la mémoire physique utilisée par le tas.
La génération permanente est configurée via les deux paramètres suivants~
-XX:PremSize code> : Définissez la taille initiale de la génération permanente<code style='margin-right: 2px;margin-left: 2px;padding: 2px 4px;outline: 0px;font-size: 14px;border-radius: 4px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(255, 93, 108);'>-XX:PremSize:设置永久代的初始大小-XX:MaxPermSize
-XX:MaxPermSize: Définit la valeur maximale de la génération permanente, la valeur par défaut est 64MPour la génération permanente
, si de nombreuses classes sont générées dynamiquement,java.lang .OutOfMemoryError est susceptible de se produire : PermGen space error
, car l'allocation d'espace de génération permanente est limitée. Le scénario le plus typique est celui où il existe de nombreuses pages jsp dans le développement Web.Après JDK8, la zone de méthode existe dans le métaespace.
La mémoire physique n'est plus continue avec le tas, mais existe directement dans la mémoire locale. Théoriquement, la taille de la machine 🎜🎜Vous pouvez définir la taille du métaespace via les paramètres suivants :🎜-XX:MetaspaceSize code>, la taille de l'espace initiale. Lorsque cette valeur est atteinte, le garbage collection sera déclenché pour le déchargement du type. En même temps, le GC ajustera la valeur : si une grande quantité d'espace est libérée, la valeur sera réduite de manière appropriée. ; si une petite quantité d'espace est libérée, alors lorsqu'elle ne dépasse pas MaxMetaspaceSize, augmentez cette valeur de manière appropriée. <code style='margin-right: 2px;margin-left: 2px;padding: 2px 4px;outline: 0px;font-size: 14px;border-radius: 4px;background-color: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(255, 93, 108);'>-XX:MetaspaceSize,初始空间大小,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize时,适当提高该值。-XX:MaxMetaspaceSize,最大空间,默认是没有限制的。-XX:MinMetaspaceFreeRatio,在GC之后,最小的Metaspace剩余空间容量的百分比,减少为分配空间所导致的垃圾收集-XX:MaxMetaspaceFreeRatio
-XX:MaxMetaspaceSize, l'espace maximum, est illimité par défaut. <p data-tool="mdnice编辑器" style='margin-top: 0.8em;margin-bottom: 0.8em;padding-top: 8px;padding-bottom: 8px;outline: 0px;color: rgb(53, 53, 53);font-family: Optima-Regular, Optima, PingFangSC-light, PingFangTC-light, "PingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;letter-spacing: 0.8px;text-align: left;white-space: normal;word-spacing: 0.8px;background-color: rgb(255, 255, 255);line-height: 1.75;'></p> <p data-tool="mdnice编辑器" style='margin-top: 0.8em;margin-bottom: 0.8em;padding-top: 8px;padding-bottom: 8px;outline: 0px;color: rgb(53, 53, 53);font-family: Optima-Regular, Optima, PingFangSC-light, PingFangTC-light, "PingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;letter-spacing: 0.8px;text-align: left;white-space: normal;word-spacing: 0.8px;background-color: rgb(255, 255, 255);line-height: 1.75;'></p> <code style="margin-right: 2px;margin-left: 2px;padding: 2px 4px;outline: 0px;font-size: 14px;border-radius: 4px;background-color: rgba(27, 31, 35, 0.05);famille de polices : " operator mono consolas monaco menlo monospace de mot break-all rgb>-XX:MinMetaspaceFreeRatio, après GC, le pourcentage minimum de capacité d'espace restant de Metaspace est réduit au garbage collection causé par l'espace alloué<p data-tool="mdnice编辑器" style='margin-top: 0.8em;margin-bottom: 0.8em;padding-top: 8px;padding-bottom: 8px;outline: 0px;color: rgb(53, 53, 53);font-family: Optima-Regular, Optima, PingFangSC-light, PingFangTC-light, "PingFang SC", Cambria, Cochin, Georgia, Times, "Times New Roman", serif;font-size: 16px;letter-spacing: 0.8px;text-align: left;white-space: normal;word-spacing: 0.8px;background-color: rgb(255, 255, 255);line-height: 1.75;'></p>🎜🎜<code style="margin-right: 2px;margin-left: 2px;padding: 2px 4px ;contour : 0px;taille de police : 14px;rayon de bordure : 4px;couleur d'arrière-plan : rgba(27, 31, 35, 0,05);famille de police : " operator mono consolas monaco menlo mot monospace break-all rgb>-XX:MaxMetaspaceFreeRatio, après GC, le pourcentage de la capacité d'espace restante maximale du Metaspace est réduit à la quantité causée par la libération d'espace Garbage Collection🎜🎜🎜🎜Alors, pourquoi utiliser le métaespace pour remplacer la génération permanente ? 🎜🎜En apparence, il s'agit d'éviter les exceptions MOO. 🎜🎜Parce que PermSize et MaxPermSize sont généralement utilisés pour définir la taille de la génération permanente, qui détermine la limite supérieure de la génération permanente, mais il n'est pas toujours possible de savoir à quelle taille elle doit être définie si vous utilisez la valeur par défaut. , il est facile de rencontrer des erreurs MOO. 🎜Lors de l'utilisation du métaespace, le nombre de classes de métadonnées pouvant être chargées n'est plus contrôlé par MaxPermSize, mais par l'espace réellement disponible du système.
Qu'est-ce que Stop The World ? Qu'est-ce qu'OopMap ? Qu'est-ce qu'un endroit sûr ?
Le processus de collecte des déchets impliquera le déplacement d'objets.
Afin de garantir l'exactitude des mises à jour des références d'objets, tous les threads utilisateur doivent être mis en pause. Une pause comme celle-ci est décrite par le concepteur de la machine virtuelle comme Stop The World. Également appelé STW.
Dans HotSpot, il existe une structure de données (table de mappage) appelée OopMap.
Une fois l'action de chargement de classe terminée, HotSpot calculera quel type de données se trouve à quel décalage dans l'objet et l'enregistrera dans OopMap.
Pendant le processus de compilation juste à temps, une OopMap sera également générée à des emplacements spécifiques, enregistrant les emplacements de la pile et les registres qui sont des références.
Ces positions spécifiques se situent principalement à : 1. La fin de la boucle (boucle non comptée)
2. Avant le retour de la méthode / après avoir appelé l'instruction d'appel de la méthode
3. Les emplacements où des exceptions peuvent être levées
Ces emplacements sont appelés points de sécurité.
Lorsque le programme utilisateur est exécuté, il n'est pas possible de mettre en pause et de démarrer le garbage collection à n'importe quelle position dans le flux d'instructions de code, mais il doit être exécuté jusqu'à un point sûr avant de pouvoir être mis en pause.
 .
. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.


Stock Market GPT
Recherche d'investissement basée sur l'IA pour des décisions plus intelligentes

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1651
1651
 276
276

 Résolution des problèmes communs de Java NullpointerException avec facultatif
Aug 31, 2025 am 07:11 AM
Résolution des problèmes communs de Java NullpointerException avec facultatif
Aug 31, 2025 am 07:11 AM
Facultatif est une classe de conteneurs introduite par Java 8. Il est utilisé pour indiquer clairement qu'une valeur peut être vide, évitant ainsi NullPointerException; 2. Il simplifie la vérification null nul en fournissant MAP, Orelse et d'autres méthodes, empêchant les méthodes de renvoyer les valeurs de rendement de la collection NULL et de normaliser; 3. Les meilleures pratiques incluent uniquement les valeurs de retour, d'éviter l'utilisation de champs ou de paramètres, de distinguer Orelse de Orelseget, et de ne pas appeler Get () directement; 4. Facultatif ne doit pas être abusé. Si les méthodes non vides n'ont pas besoin d'être enveloppées, les opérations facultatives inutiles doivent être évitées dans le flux; L'utilisation correcte de facultatif peut considérablement améliorer la sécurité et la lisibilité du code, mais elle nécessite de bonnes habitudes de programmation.
 Modifier les signets dans Chrome
Aug 27, 2025 am 12:03 AM
Modifier les signets dans Chrome
Aug 27, 2025 am 12:03 AM
L'édition de signets de Chrome est simple et pratique. Les utilisateurs peuvent saisir le gestionnaire de signets via les touches de raccourci Ctrl Shift O (Windows) ou CMD Shift O (Mac), ou entrer dans le menu du navigateur; 1. Lors de la modification d'un seul signet, cliquez avec le bouton droit pour sélectionner "Modifier", modifiez le titre ou l'URL et cliquez sur "Terminer" pour enregistrer; 2. Lorsque vous organisez des signets par lots, vous pouvez maintenir CTRL (ou CMD) dans des signets à choix multiples dans le gestionnaire de signets, cliquez avec le bouton droit pour sélectionner "passer à" ou "Copier" le dossier cible; 3. Lors de l'exportation et de l'importation de signets, cliquez sur le bouton "Résoudre" pour sélectionner "Exporter Bookmark" pour enregistrer en tant que fichier HTML, puis restaurer la fonction "Importer Bookmark" si nécessaire.
 Entrez la touche ne fonctionnant pas sur mon clavier
Aug 30, 2025 am 08:36 AM
Entrez la touche ne fonctionnant pas sur mon clavier
Aug 30, 2025 am 08:36 AM
Tout d'abord, CheckForPhysicsUesuesLikeeDebrisordAmageAndCleantheyBoardOrtestwithanExternalone; 2.TestertheenterkeyIndifferentAppstodetermineiftheissueIssoftware-spécifique; 3.restartyourcomputertoresolvetetemporaryglitches; 4.DisableStickykeys, Filterkeys, Ortogglek
 Qu'est-ce qu'une fuite de mémoire en Java?
Aug 28, 2025 am 05:37 AM
Qu'est-ce qu'une fuite de mémoire en Java?
Aug 28, 2025 am 05:37 AM
AmemémoryleakinjavaoccurSwhenUnReachableObjectsarenotgarBageCollecyDuetolingingreFerences, seadtoExcessiveMemoryusageAndPotentialoutoutofMemoryError.ComMonCauseSeSestaticCollesectionreweting
 Que sont les cours de wrapper et pourquoi sont-ils utilisés en Java?
Sep 01, 2025 am 05:58 AM
Que sont les cours de wrapper et pourquoi sont-ils utilisés en Java?
Sep 01, 2025 am 05:58 AM
WrapperclassesaSareUsedToconvertprimeTatatyTySIntoObjects, permettant à la consommation, permettant de surtout, fournissant des méthodes et de la supportation d'auto-oboxing / déborde.
 Comment trouver la valeur max ou min dans un flux en Java
Aug 27, 2025 am 04:14 AM
Comment trouver la valeur max ou min dans un flux en Java
Aug 27, 2025 am 04:14 AM
Utilisez les méthodes max () et min () pour combiner le comparateur pour trouver les valeurs maximales et minimales dans le flux, telles que Comparator.NaturalOrder () ou Integer :: Comparez les types de base; 2. Pour les objets personnalisés, utilisez Comparator.Charepring () pour comparer en fonction de champs spécifiques, tels que Person :: Getage; 3. Étant donné que le résultat est facultatif, la situation du flux vide doit être gérée. Vous pouvez utiliser iSpresent () pour vérifier ou orelse () pour fournir des valeurs par défaut. Il est recommandé d'utiliser IntStream pour les types de base pour éviter de boxer les frais généraux et d'améliorer les performances. En fin de compte, vous devriez toujours être correctement terminé.
 CVE-2024-20674 | Fonction de sécurité Windows Kerberos contourner la vulnérabilité
Sep 02, 2025 pm 05:18 PM
CVE-2024-20674 | Fonction de sécurité Windows Kerberos contourner la vulnérabilité
Sep 02, 2025 pm 05:18 PM
Le 0x00 avantpoix Kerberos a été créé par le MIT comme solution à ces problèmes de cybersécurité. Est une architecture client / serveur qui fournit un traitement de vérification de sécurité sur le réseau. Grâce à la vérification, l'identité de l'expéditeur et du récepteur des transactions réseau peut être assurée d'être vraie. Le service peut également vérifier la validité (intégrité) des données transmises dans les deux sens et crypter les données pendant la transmission (confidentialité). 0x01 Description de la vulnérabilité Un attaquant ayant accès à un réseau de victime peut exploiter cette vulnérabilité en établissant une attaque intermédiaire (MITM) ou d'autres techniques d'usurpation des réseaux locaux, puis en envoyant un message de Kerberos malveillant à l'ordinateur de la victime du client et en faisant semblant d'être un serveur d'authentification Kerberos. 0x02cve
 Comment formater les nombres en Java en utilisant Decimalformat
Aug 30, 2025 am 03:09 AM
Comment formater les nombres en Java en utilisant Decimalformat
Aug 30, 2025 am 03:09 AM
Utilisez Decimalformat pour contrôler avec précision les formats numériques. 1. Utilisez des chaînes de motifs telles que "#, ###. ##" pour le formatage de base, où # représente un nombre facultatif, 0 représente un numéro de diffusion incontournable, est un mille séparateur et est un point décimal; 2. Les modes communs incluent "0,00" pour conserver deux décimales, "0,000.000" pour compléter l'alignement zéro, etc.; 3. Évitez les méthodes de notation scientifique, vous pouvez définir la Notation (False) ou utiliser un mode avec des chiffres suffisants; 4. Vous pouvez définir le mode d'arrondi via setRoundingMode (), comme Half_up, Down, etc.
