


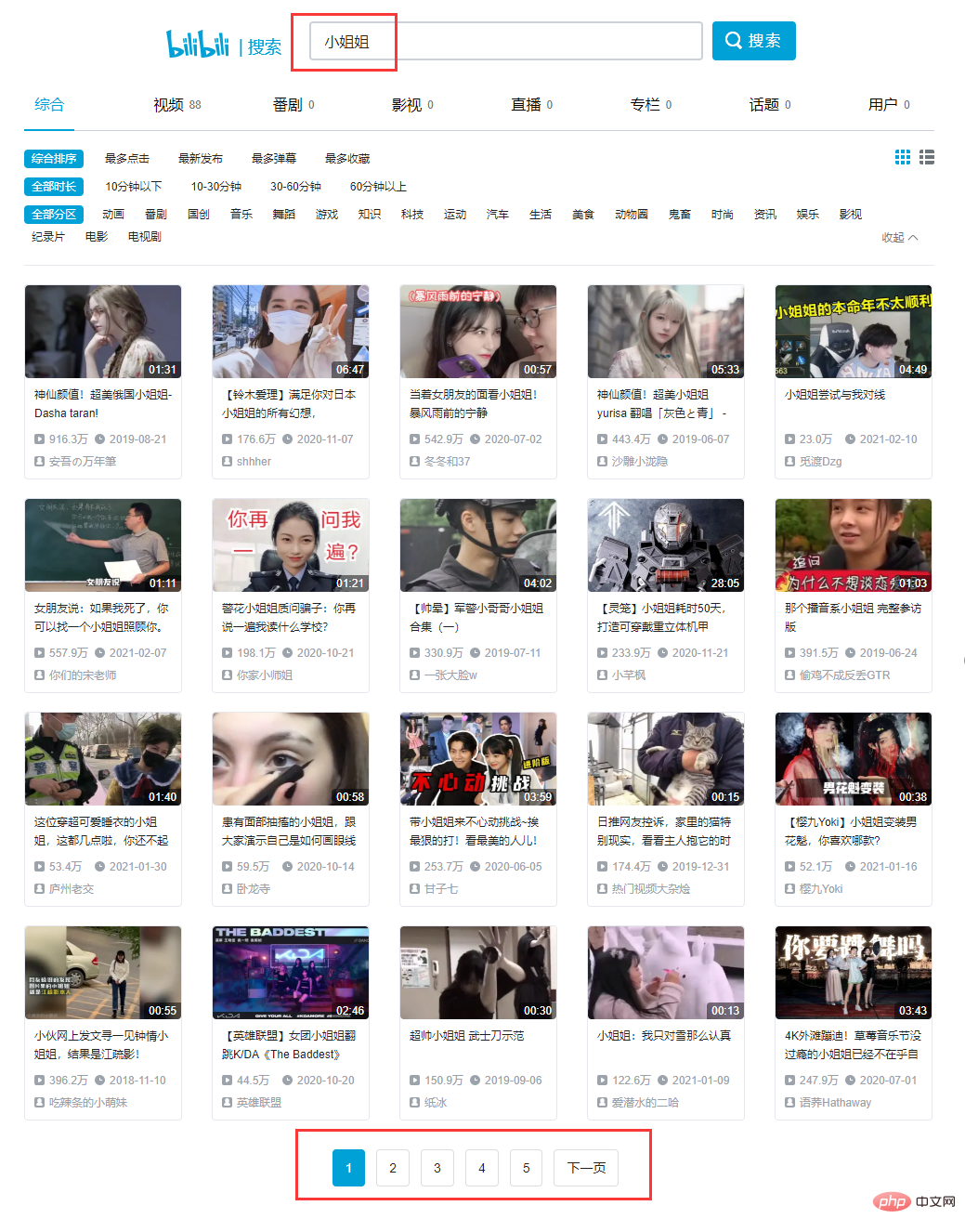
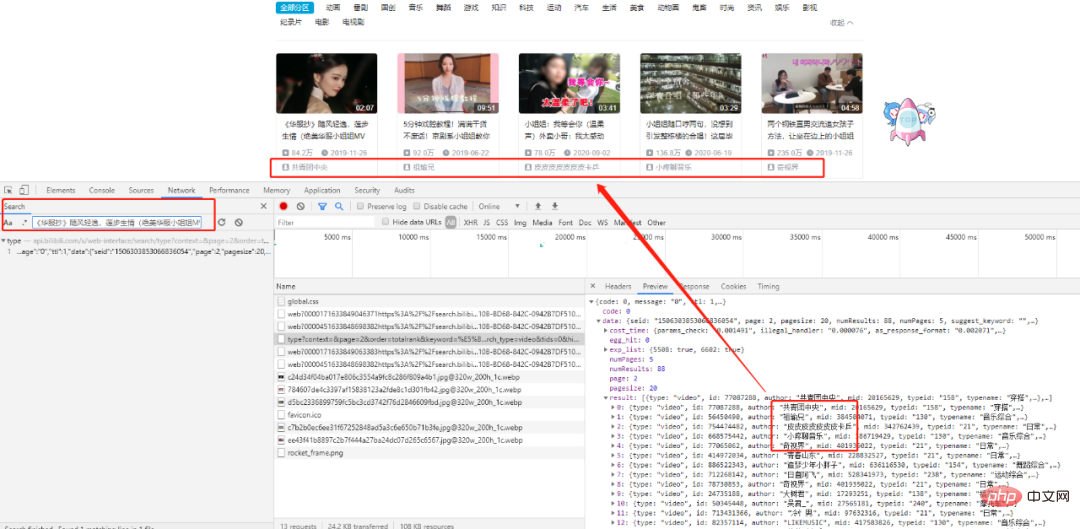
Recherchez le premier titre, nous pouvons trouver la requête XHR correspondante. Après une analyse minutieuse, nous constatons que toutes les données existent dans un ensemble de données au format json, et notre cible est dans la liste result.
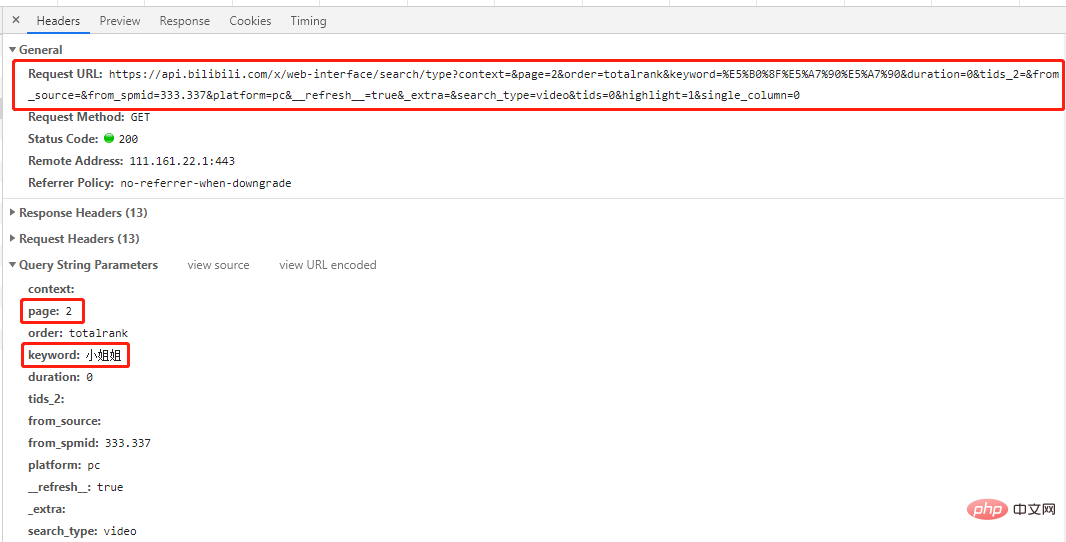
Il s'agit d'une get request, le nombre d'entrées dans la demande est de page et mot-clédeux entrées correspondent respectivement aux numéros de page et aux mots-clés demandés.
Consultez quelques pages supplémentaires pour trouver le modèle :
# 第一页 'https://api.bilibili.com/x/web-interface/search/all/v2?context=&page=1&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&tids=0&highlight=1&single_column=0' # 第二页 'https://api.bilibili.com/x/web-interface/search/type?context=&page=2&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&search_type=video&tids=0&highlight=1&single_column=0' # 第三页 'https://api.bilibili.com/x/web-interface/search/type?context=&page=3&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&search_type=video&tids=0&highlight=1&single_column=0'
Vous pouvez voir qu'à l'exception de la première page, seul le paramètre de page est différent dans les URL des autres pages, alors essayonsLa page 1 est également demandée en utilisant les URL des autres pages, et les résultats sera le même. Vous pouvez obtenir les résultats souhaités (essayez-le vous-même).
Conclusion : Seul le paramètre de page est différent pour toutes les URL de page, et les autres sont les mêmes.
# 导包 import re import time import json import random import requests from fake_useragent import UserAgent
2.2 获取页面信息
# 获取页面信息
def get_datas(url,headers):
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = chardet.detect(r.content)['encoding']
datas = json.loads(r.text)
return datas# 获取图片链接信息
def get_hrefs(datas):
titles,hrefs = [],[]
for data in datas['data']['result']:
# 标题
title = data['title']
# 时长
duration = data['duration']
# 播放量
video_review =data['video_review']
# 发布时间
date_rls = data['pubdate']
pubdate = time.strftime('%Y-%m-%d %H:%M', time.localtime(date_rls))
# 作者
author = data['author']
# 图片链接
link_pic = data['pic']
href_pic = 'https:' + link_pic
titles.append(title)
hrefs.append(href_pic)
return titles, hrefs代码解析了视频标题,时长,播放量,发布时间,作者,图片链接等参数,这里我们只取标题和图片链接,其他参数可根据需要自行增,删。
# 保存图片
def download_jpg(titles, hrefs):
path = "D:/B站小姐姐/"
if not os.path.exists(path):
os.mkdir(path)
for i in range(len(hrefs)):
title_t = titles[i].replace('/','').replace(',','').replace('?','')
title_t = title_t.replace(' ','').replace('|','').replace('。','')
filename = '{}{}.jpg'.format(path,title_t)
with open(filename, 'wb') as f:
req = requests.get(url=hrefs[i], headers=headers)
f.write(req.content)
time.sleep(random.uniform(1.5,3.4))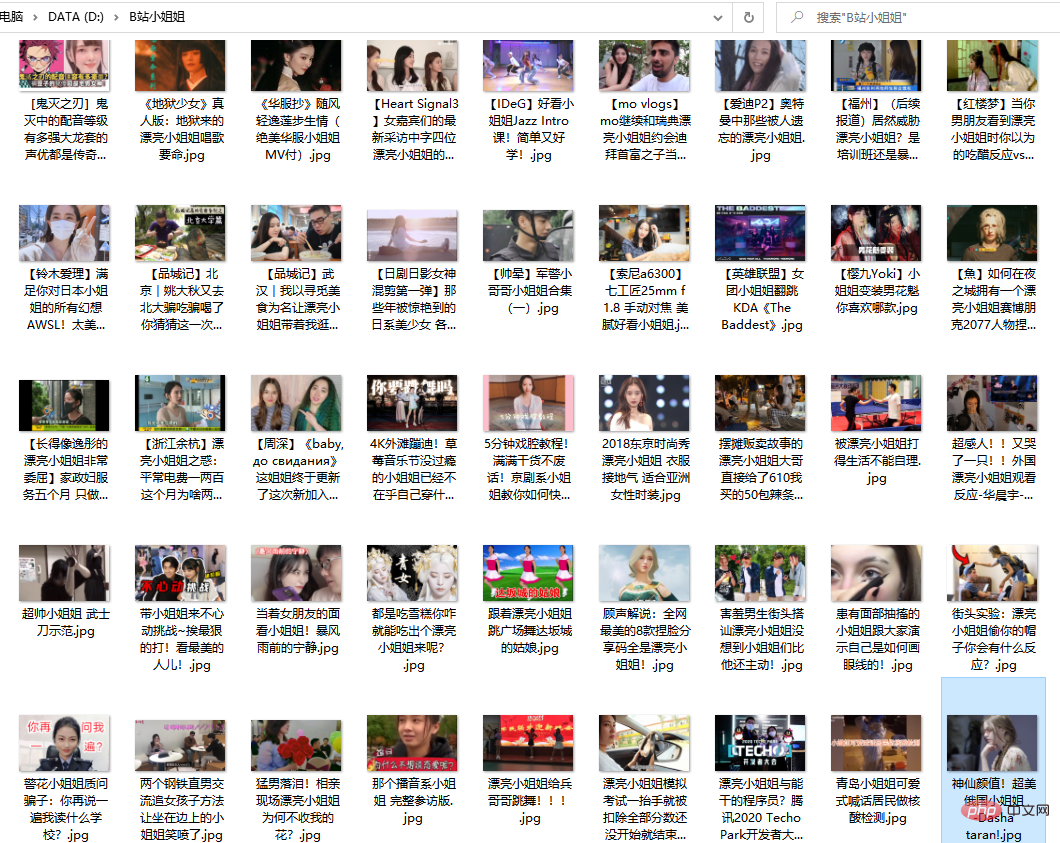
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!





























![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



