

 développement back-end
Tutoriel Python
Un article pour vous aider à comprendre les bases des opérations et de l'imbrication liées aux listes Python
développement back-end
Tutoriel Python
Un article pour vous aider à comprendre les bases des opérations et de l'imbrication liées aux listes Python
Un article pour vous aider à comprendre les bases des opérations et de l'imbrication liées aux listes Python
1. Opérations liées à la liste
Les données stockées dans la liste peuvent être modifiées, telles que "ajouter", "supprimer" et "modifier".
<1> Ajouter des éléments ("Ajouter" trois façons d'ajouter)
1.
#定义变量A,默认有3个元素
A = ['xiaoWang','xiaoZhang','xiaoHua']
print("-----添加之前,列表A的数据-----")
for tempName in A:
print(tempName)
#提示、并添加元素
temp = input('请输入要添加的学生姓名:')
A.append(temp)
print("-----添加之后,列表A的数据-----")
for tempName in A:
print(tempName)Résultat :2. extend()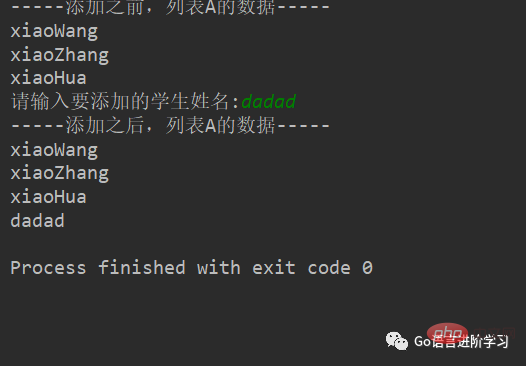
Par extend, vous pouvez ajouter des éléments d'une autre collection à la liste un par un
>>> a = [1, 2] >>> b = [3, 4] >>> a.append(b) >>> print(a) [1, 2, [3, 4]] #运行结果 >>> a.extend(b) >>> print(a) [1, 2, [3, 4], 3, 4] #运行结果3 . insert()
insert(index, object) insère l'objet élément avant la position spécifiée index
>>> a = [0, 1, 2] >>> a.insert(1, 3) >>> print(a) [0, 3, 1, 2]
<2> 修改元素("改")
修改元素的时候,要通过下标来确定要修改的是哪个元素,然后才能进行修改
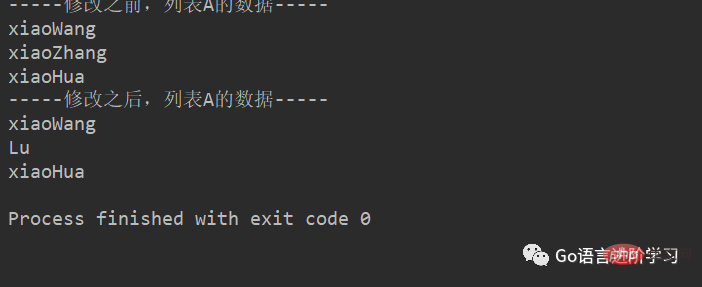
demo:
# 定义变量A,默认有3个元素
A = ['xiaoWang', 'xiaoZhang', 'xiaoHua']
print("-----修改之前,列表A的数据-----")
for tempName in A:
print(tempName)
# 修改元素
A[1] = 'Lu'
print("-----修改之后,列表A的数据-----")
for tempName in A:
print(tempName)结果:
<3> 查找元素("查"in, not in, index, count)
所谓的查找,就是看看指定的元素是否存在。
1. in, not in
Python中查找的常用方法为:
in(存在),如果存在那么结果为true,否则为false。
not in(不存在),如果不存在那么结果为true,否则false。
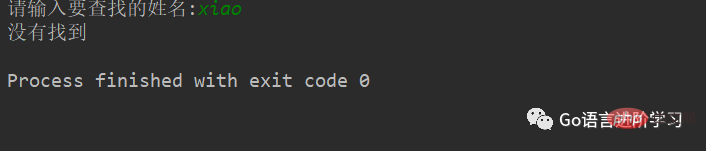
#待查找的列表
nameList = ['xiaoWang','xiaoZhang','xiaoHua']
#获取用户要查找的名字
findName = input('请输入要查找的姓名:')
#查找是否存在
if findName in nameList:
print('在字典中找到了相同的名字')
else:
print('没有找到')运行结果:(找到)

运行结果:(没有找到)
说明:
in的方法只要会用了,那么not in也是同样的用法,只不过not in判断的是不存在。
2. index, count
index和count与字符串中的用法相同
>>> a = ['a', 'b', 'c', 'a', 'b'] >>> a.index('a', 1, 3) # 注意是左闭右开区间 Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: 'a' is not in list >>> a.index('a', 1, 4) >>> print(a) 3 #运行结果 >>> a.count('b') >>> print(a) 2 #运行结果 >>> a.count('d') >>> print(a) 0 #运行结果
<4> 删除元素("删"del, pop, remove)
列表元素的常用删除方法有:
del:根据下标进行删除
pop:删除最后一个元素
remove:根据元素的值进行删除
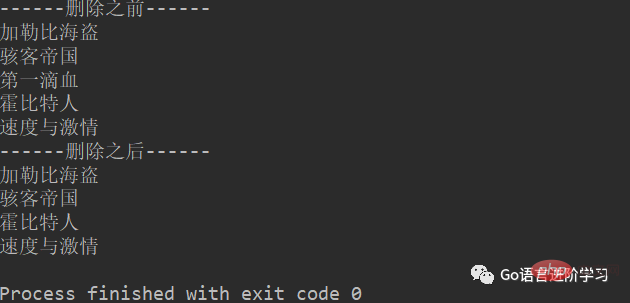
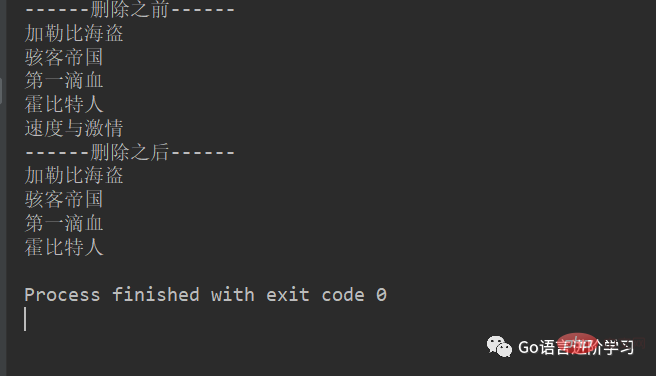
1. del
movieName = ['加勒比海盗','骇客帝国','第一滴血','霍比特人','速度与激情']
print('------删除之前------')
for tempName in movieName:
print(tempName)
del movieName[2]
print('------删除之后------')
for tempName in movieName:
print(tempName)结果:
2. pop
movieName = ['加勒比海盗','骇客帝国','第一滴血','霍比特人','速度与激情']
print('------删除之前------')
for tempName in movieName:
print(tempName)
movieName.pop()
print('------删除之后------')
for tempName in movieName:
print(tempName)结果:
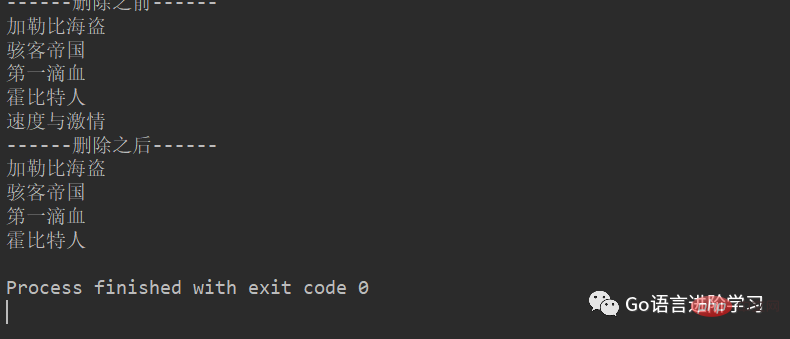
3. remove
movieName = ['加勒比海盗','骇客帝国','第一滴血','指环王','霍比特人','速度与激情']
print('------删除之前------')
for tempName in movieName:
print(tempName)
movieName.remove('指环王')
print('------删除之后------')
for tempName in movieName:
print(tempName)结果:
<5> 排序(sort, reverse)
sort方法是将list按特定顺序重新排列,默认为由小到大,参数reverse=True可改为倒序,由大到小。
reverse方法是将list逆置。
>>> a = [1, 4, 2, 3] >>> print(a) [1, 4, 2, 3] #运行结果 >>> a.reverse() >>> print(a) [3, 2, 4, 1] #运行结果 >>> a.sort() >>> print(a) [1, 2, 3, 4] #运行结果 >>> a.sort(reverse=True) >>> print(a) [4, 3, 2, 1] #运行结果
二、列表的嵌套
1. 列表嵌套
类似while循环的嵌套,列表也是支持嵌套的。
一个列表中的元素又是一个列表,那么这就是列表的嵌套。
例:
Names= [['北京','甘肃'],
['南京','天津','广东'],
['山','上海']]2. 应用
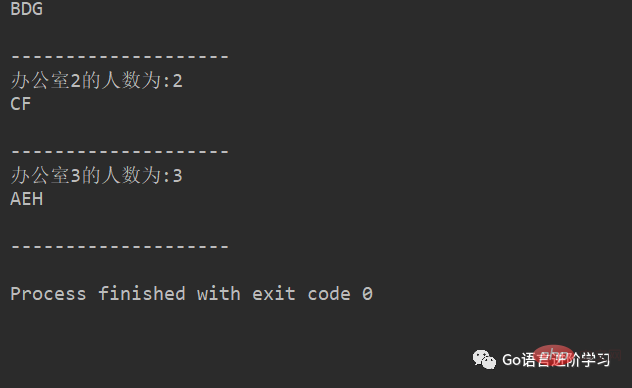
小项目练习:
学校,有3个办公室,现在有8位老师等待工位的分配,请编写程序,完成随机的分配。
#encoding=utf-8
import random
# 定义一个列表用来保存3个办公室
offices = [[],[],[]]
# 定义一个列表用来存储8位老师的名字
names = ['A','B','C','D','E','F','G','H']
i = 0
for name in names:
index = random.randint(0,2)
offices[index].append(name)
i = 1
for tempNames in offices:
print('办公室%d的人数为:%d'%(i,len(tempNames)))
i+=1
for name in tempNames:
print("%s"%name,end='')
print("\n")
print("-"*20)
运行结果如下:
三、总结
本文详细的讲解了Python基础 ,介绍了常见的列表操作,以及在实际操作中会遇到的问题,提供了解决方案。最后通过一个小项目,使读者能够更好的理解Python列表的使用方法。希望可以帮助你更好的学习。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment automatiser la saisie de données d'Excel à un formulaire Web avec Python?
Aug 12, 2025 am 02:39 AM
Comment automatiser la saisie de données d'Excel à un formulaire Web avec Python?
Aug 12, 2025 am 02:39 AM
La méthode de remplissage des données Excel dans les formulaires Web à l'aide de Python est: utilisez d'abord des pandas pour lire les données Excel, puis utilisez le sélénium pour contrôler le navigateur pour remplir et soumettre automatiquement le formulaire; Les étapes spécifiques incluent l'installation de bibliothèques Pandas, OpenPyxl et Selenium, en téléchargeant le pilote de navigateur correspondant, en utilisant des pandas pour lire le nom, le courrier électronique, le téléphone et d'autres champs dans le fichier data.xlsx, le lancement du navigateur via le sélénium pour ouvrir la page Web cible, localiser les éléments de formulaire et remplir le traitement de données, en utilisant le formulaire Web pour traiter le contenu dynamique, ajouter le contenu de la charge dynamique, ajouter un traitement exception et traiter toutes les lignes de données dans une boucle.
 Qu'est-ce que l'analyse des sentiments dans le trading des crypto-monnaies?
Aug 14, 2025 am 11:15 AM
Qu'est-ce que l'analyse des sentiments dans le trading des crypto-monnaies?
Aug 14, 2025 am 11:15 AM
Table des matières Qu'est-ce que l'analyse des sentiments dans le trading des crypto-monnaies? Pourquoi l'analyse des sentiments est importante dans l'investissement des crypto-monnaies sources clés de données d'émotion a. Plateforme de médias sociaux b. Médias d'information c. Outils pour l'analyse des sentiments et la technologie Utilisé couramment des outils dans l'analyse des sentiments: Techniques adoptées: intégrer l'analyse des sentiments dans les stratégies de trading comment les traders l'utilisent: Exemple de stratégie: supposer le scénario de trading BTC Réglage du scénario: Signal émotionnel: interprétation des commerçants: Décision: Résultats: Limitations et risques de l'analyse des sentiments en utilisant de plus en plus les émotions pour le commerce des crypto-oreilles. Une récente étude en 2025 de Hamid
 Comment gérer les grands ensembles de données dans Python qui ne rentrent pas dans la mémoire?
Aug 14, 2025 pm 01:00 PM
Comment gérer les grands ensembles de données dans Python qui ne rentrent pas dans la mémoire?
Aug 14, 2025 pm 01:00 PM
Lors du traitement de grands ensembles de données qui dépassent la mémoire dans Python, ils ne peuvent pas être chargés en RAM en même temps. Au lieu de cela, des stratégies telles que le traitement de la chasse, le stockage du disque ou le streaming doivent être adoptées; Les fichiers CSV peuvent être lus en morceaux via les paramètres ChunkSize de Pandas et le bloc traité par bloc. La daste peut être utilisée pour réaliser la parallélisation et la planification des tâches similaires à la syntaxe Pandas pour prendre en charge les opérations de données de mémoire importantes. Écrivez les fonctions du générateur pour lire les fichiers texte ligne par ligne pour réduire l'utilisation de la mémoire. Utilisez le format de stockage en colonne de parquet combiné avec Pyarrow pour lire efficacement des colonnes ou des groupes de lignes spécifiques. Utilisez Memmap de Numpy pour mapper la mémoire de grands tableaux numériques pour accéder aux fragments de données à la demande, ou stocker des données dans des données légères telles que SQLite ou DuckDB.
 Comment copier des fichiers et des répertoires d'un endroit à un autre à Python
Aug 11, 2025 pm 06:11 PM
Comment copier des fichiers et des répertoires d'un endroit à un autre à Python
Aug 11, 2025 pm 06:11 PM
Pour copier des fichiers et des répertoires, le module Shuttil de Python fournit une approche efficace et sécurisée. 1. Utilisez ShutLil.copy () ou ShutLil.copy2 () pour copier un seul fichier, qui conserve les métadonnées; 2. Utilisez ShutLil.CopyTree () pour copier récursivement l'intégralité du répertoire. Le répertoire cible ne peut pas exister à l'avance, mais la cible peut être autorisée à exister via dirrs_exist_ok = true (python3.8); 3. Vous pouvez filtrer des fichiers spécifiques en combinaison avec les paramètres Ignore et shuttil.ignore_patterns () ou des fonctions personnalisées; 4. La copie du répertoire nécessite uniquement OS.Walk () et Os.MakeDirs ()
 Comment utiliser Python pour l'analyse et la prédiction boursières?
Aug 11, 2025 pm 06:56 PM
Comment utiliser Python pour l'analyse et la prédiction boursières?
Aug 11, 2025 pm 06:56 PM
Python peut être utilisé pour l'analyse et la prédiction boursières. La réponse est oui. En utilisant des bibliothèques telles que la yfinance, en utilisant des pandas pour le nettoyage des données et l'ingénierie des caractéristiques, la combinaison de Matplotlib ou de la mer pour l'analyse visuelle, puis en utilisant des modèles tels que ARIMA, Random Forest, XGBOost ou LSTM pour construire un système de prédiction et évaluer les performances grâce à un backtesting. Enfin, l'application peut être déployée avec Flask ou Fastapi, mais l'attention doit être accordée à l'incertitude des prévisions du marché, des risques de sur-ajustements et des coûts de transaction, et le succès dépend de la qualité des données, de la conception du modèle et des attentes raisonnables.
 Comment déboguer votre code python
Aug 13, 2025 am 12:18 AM
Comment déboguer votre code python
Aug 13, 2025 am 12:18 AM
Useprint () instructionSOcheckVariableValuesAndexEcutionflow, ajoutlabelsandtypesforclarity, andRemoveThembeForComting; 2.Ushepylepylebugger (pdb) withreakpoint () topauseeexecution, inspectvariables, andstepthroughcodeinteractive; 3.HandleExceptionsusin;
 Comment utiliser l'énumération pour boucler avec un index dans Python
Aug 11, 2025 pm 01:14 PM
Comment utiliser l'énumération pour boucler avec un index dans Python
Aug 11, 2025 pm 01:14 PM
Lorsque vous devez parcourir la séquence et accéder à l'index, vous devez utiliser la fonction énumérer (). 1. EnuMerate () fournit automatiquement l'index et la valeur, ce qui est plus concis que Range (LEN (séquence)); 2. Vous pouvez spécifier l'index de démarrage via le paramètre de démarrage, tel que start = 1 pour réaliser un nombre basé sur 1; 3. Vous pouvez l'utiliser en combinaison avec la logique conditionnelle, comme sauter le premier élément, limitant le nombre de boucles ou format la sortie; 4. Applicable à tout objet itérable tel que les listes, les chaînes et les tuples, et le déballage des éléments de support; 5. Améliorez la lisibilité du code, évitez la gestion manuelle des compteurs et réduisez les erreurs.
 Comment déboguer le code Python dans le texte sublime?
Aug 14, 2025 pm 04:51 PM
Comment déboguer le code Python dans le texte sublime?
Aug 14, 2025 pm 04:51 PM
UsuBrimeText’sBuildSystemTorunpyThonscriptsandcatcherRorSpressingCtrl baftersettingthecorrectBuildSystemorCreatacustomone.2.InsertStrategicprint () StatementScocheckVariableValues, Types, etxExecutionflow, usingLabelSAndrepr () Forclarit
