

 développement back-end
Tutoriel Python
Faire le point sur les différences entre la bibliothèque urllib et la bibliothèque de requêtes en Python
développement back-end
Tutoriel Python
Faire le point sur les différences entre la bibliothèque urllib et la bibliothèque de requêtes en Python
Faire le point sur les différences entre la bibliothèque urllib et la bibliothèque de requêtes en Python
1. Introduction
Lorsque vous utilisez un robot d'exploration Python, vous devez simuler le lancement de requêtes réseau. Les principales bibliothèques utilisées sont la bibliothèque de requêtes et la bibliothèque urllib intégrée à Python. use request, qui est une extension de urllib encapsulée à nouveau.
Quelle est la différence entre eux ?
Ce qui suit est une explication détaillée à travers des cas pour comprendre les principales différences dans leur utilisation.
2. Bibliothèque urllib
Introduction : L'objet de réponse de la bibliothèque urllib crée d'abord des objets http et de requête, puis les charge dans reques.urlopen pour terminer la requête http.
Ce qui est renvoyé est http, un objet de réponse, qui est en fait un attribut HTML. Utilisez .read().decode() pour le décoder et le convertir en type chaîne str. Après le décodage, les caractères chinois peuvent être affichés.
Exemple :
from urllib import request
#请求头
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'
}
wd = {"wd": "中国"}
url = "http://www.baidu.com/s?"
req = request.Request(url, headers=headers)
response = request.urlopen(req)
print(type(response))
print(response)
res = response.read().decode()
print(type(res))
print(res)Résultat de course :
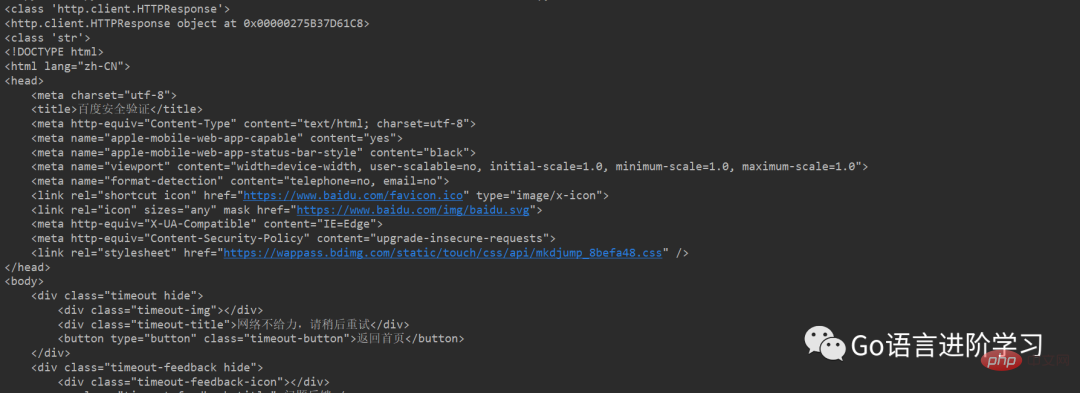
Remarque :
Habituellement, en explorant les pages Web, lors de la construction de requêtes http, vous devez en ajouter des informations supplémentaires, telles que Useragent, cookies, etc., ou ajouter un serveur proxy. Il s’agit souvent de mécanismes anti-exploration nécessaires.
三、requests库
简介:requests库调用是requests.get方法传入url和参数,返回的对象是Response对象,打印出来是显示响应状态码。
通过.text 方法可以返回是unicode 型的数据,一般是在网页的header中定义的编码形式,而content返回的是bytes,二级制型的数据,还有 .json方法也可以返回json字符串。
如果想要提取文本就用text,但是如果你想要提取图片、文件等二进制文件,就要用content,当然decode之后,中文字符也会正常显示。
requests的优势:Python爬虫时,更建议用requests库。因为requests比urllib更为便捷,requests可以直接构造get,post请求并发起,而urllib.request只能先构造get,post请求,再发起。
例:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Linux; U; Android 8.1.0; zh-cn; BLA-AL00 Build/HUAWEIBLA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/8.9 Mobile Safari/537.36"
}
wd = {"wd": "中国"}
url = "http://www.baidu.com/s?"
response = requests.get(url, params=wd, headers=headers)
data = response.text
data2 = response.content
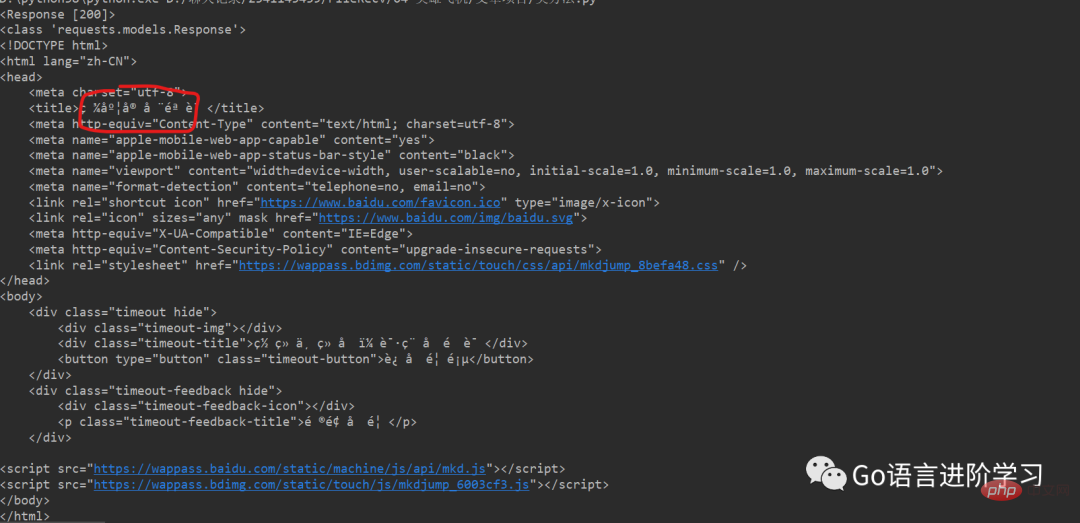
print(response)
print(type(response))
print(data)
print(type(data))
print(data2)
print(type(data2))
print(data2.decode())
print(type(data2.decode()))运行结果 (可以直接获取整网页的信息,打印控制台):
四、总结
1. 本文基于Python基础,主要介绍了urllib库和requests库的区别。
2. 在使用urllib内的request模块时,返回体获取有效信息和请求体的拼接需要decode和encode后再进行装载。进行http请求时需先构造get或者post请求再进行调用,header等头文件也需先进行构造。
3. requests是对urllib的进一步封装,因此在使用上显得更加的便捷,建议在实际应用当中尽量使用requests。
4. 希望能给一些对爬虫感兴趣,有一个具体的概念。方法只是一种工具,试着去爬一爬会更容易上手,网络也会有很多的坑,做爬虫更需要大量的经验来应付复杂的网络情况。
5. 希望大家一起探讨学习, 一起进步。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelles sont les stratégies courantes pour déboguer une fuite de mémoire à Python?
Aug 06, 2025 pm 01:43 PM
Quelles sont les stratégies courantes pour déboguer une fuite de mémoire à Python?
Aug 06, 2025 pm 01:43 PM
UsetracemalloctotrackMemoryAllocations et identifier les high-momemorylines; 2.MonitorObjectCountSwithgcandobjgraphtodetectGrowingObjectTypes; 3.inspectreferencyclesandlong-livefreencesUsingobjgraph.show_backrefscheckForonColdCyledCycles; 4.USEMMORY_PROFOF
 Qu'est-ce que l'analyse des sentiments dans le trading des crypto-monnaies?
Aug 14, 2025 am 11:15 AM
Qu'est-ce que l'analyse des sentiments dans le trading des crypto-monnaies?
Aug 14, 2025 am 11:15 AM
Table des matières Qu'est-ce que l'analyse des sentiments dans le trading des crypto-monnaies? Pourquoi l'analyse des sentiments est importante dans l'investissement des crypto-monnaies sources clés de données d'émotion a. Plateforme de médias sociaux b. Médias d'information c. Outils pour l'analyse des sentiments et la technologie Utilisé couramment des outils dans l'analyse des sentiments: Techniques adoptées: intégrer l'analyse des sentiments dans les stratégies de trading comment les traders l'utilisent: Exemple de stratégie: supposer le scénario de trading BTC Réglage du scénario: Signal émotionnel: interprétation des commerçants: Décision: Résultats: Limitations et risques de l'analyse des sentiments en utilisant de plus en plus les émotions pour le commerce des crypto-oreilles. Une récente étude en 2025 de Hamid
 Comment automatiser la saisie de données d'Excel à un formulaire Web avec Python?
Aug 12, 2025 am 02:39 AM
Comment automatiser la saisie de données d'Excel à un formulaire Web avec Python?
Aug 12, 2025 am 02:39 AM
La méthode de remplissage des données Excel dans les formulaires Web à l'aide de Python est: utilisez d'abord des pandas pour lire les données Excel, puis utilisez le sélénium pour contrôler le navigateur pour remplir et soumettre automatiquement le formulaire; Les étapes spécifiques incluent l'installation de bibliothèques Pandas, OpenPyxl et Selenium, en téléchargeant le pilote de navigateur correspondant, en utilisant des pandas pour lire le nom, le courrier électronique, le téléphone et d'autres champs dans le fichier data.xlsx, le lancement du navigateur via le sélénium pour ouvrir la page Web cible, localiser les éléments de formulaire et remplir le traitement de données, en utilisant le formulaire Web pour traiter le contenu dynamique, ajouter le contenu de la charge dynamique, ajouter un traitement exception et traiter toutes les lignes de données dans une boucle.
 Comment implémenter un itérateur personnalisé dans une classe Python?
Aug 06, 2025 pm 01:17 PM
Comment implémenter un itérateur personnalisé dans une classe Python?
Aug 06, 2025 pm 01:17 PM
Définir__iter __ () ToreturnTheiteratorObject, typiquement SellorAsParateiteratoratance.2.Define__Next __ () ToreturnTheNextValueAndraiStopitérityWenex Hausted.
 Comment utiliser l'énumération pour boucler avec un index dans Python
Aug 11, 2025 pm 01:14 PM
Comment utiliser l'énumération pour boucler avec un index dans Python
Aug 11, 2025 pm 01:14 PM
Lorsque vous devez parcourir la séquence et accéder à l'index, vous devez utiliser la fonction énumérer (). 1. EnuMerate () fournit automatiquement l'index et la valeur, ce qui est plus concis que Range (LEN (séquence)); 2. Vous pouvez spécifier l'index de démarrage via le paramètre de démarrage, tel que start = 1 pour réaliser un nombre basé sur 1; 3. Vous pouvez l'utiliser en combinaison avec la logique conditionnelle, comme sauter le premier élément, limitant le nombre de boucles ou format la sortie; 4. Applicable à tout objet itérable tel que les listes, les chaînes et les tuples, et le déballage des éléments de support; 5. Améliorez la lisibilité du code, évitez la gestion manuelle des compteurs et réduisez les erreurs.
 Comment gérer les grands ensembles de données dans Python qui ne rentrent pas dans la mémoire?
Aug 14, 2025 pm 01:00 PM
Comment gérer les grands ensembles de données dans Python qui ne rentrent pas dans la mémoire?
Aug 14, 2025 pm 01:00 PM
Lors du traitement de grands ensembles de données qui dépassent la mémoire dans Python, ils ne peuvent pas être chargés en RAM en même temps. Au lieu de cela, des stratégies telles que le traitement de la chasse, le stockage du disque ou le streaming doivent être adoptées; Les fichiers CSV peuvent être lus en morceaux via les paramètres ChunkSize de Pandas et le bloc traité par bloc. La daste peut être utilisée pour réaliser la parallélisation et la planification des tâches similaires à la syntaxe Pandas pour prendre en charge les opérations de données de mémoire importantes. Écrivez les fonctions du générateur pour lire les fichiers texte ligne par ligne pour réduire l'utilisation de la mémoire. Utilisez le format de stockage en colonne de parquet combiné avec Pyarrow pour lire efficacement des colonnes ou des groupes de lignes spécifiques. Utilisez Memmap de Numpy pour mapper la mémoire de grands tableaux numériques pour accéder aux fragments de données à la demande, ou stocker des données dans des données légères telles que SQLite ou DuckDB.
 Comment copier des fichiers et des répertoires d'un endroit à un autre à Python
Aug 11, 2025 pm 06:11 PM
Comment copier des fichiers et des répertoires d'un endroit à un autre à Python
Aug 11, 2025 pm 06:11 PM
Pour copier des fichiers et des répertoires, le module Shuttil de Python fournit une approche efficace et sécurisée. 1. Utilisez ShutLil.copy () ou ShutLil.copy2 () pour copier un seul fichier, qui conserve les métadonnées; 2. Utilisez ShutLil.CopyTree () pour copier récursivement l'intégralité du répertoire. Le répertoire cible ne peut pas exister à l'avance, mais la cible peut être autorisée à exister via dirrs_exist_ok = true (python3.8); 3. Vous pouvez filtrer des fichiers spécifiques en combinaison avec les paramètres Ignore et shuttil.ignore_patterns () ou des fonctions personnalisées; 4. La copie du répertoire nécessite uniquement OS.Walk () et Os.MakeDirs ()
 Comment utiliser Python pour l'analyse et la prédiction boursières?
Aug 11, 2025 pm 06:56 PM
Comment utiliser Python pour l'analyse et la prédiction boursières?
Aug 11, 2025 pm 06:56 PM
Python peut être utilisé pour l'analyse et la prédiction boursières. La réponse est oui. En utilisant des bibliothèques telles que la yfinance, en utilisant des pandas pour le nettoyage des données et l'ingénierie des caractéristiques, la combinaison de Matplotlib ou de la mer pour l'analyse visuelle, puis en utilisant des modèles tels que ARIMA, Random Forest, XGBOost ou LSTM pour construire un système de prédiction et évaluer les performances grâce à un backtesting. Enfin, l'application peut être déployée avec Flask ou Fastapi, mais l'attention doit être accordée à l'incertitude des prévisions du marché, des risques de sur-ajustements et des coûts de transaction, et le succès dépend de la qualité des données, de la conception du modèle et des attentes raisonnables.
