


Pour traiter les données, cet seul outil d'IA suffit !
En vous appuyant sur le grand modèle de langage (LLM) qui se cache derrière, il vous suffit de décrireles données que vous souhaitez voir en une phrase, et de lui laisser le reste !
Le traitement, l'analyse et même la visualisation peuvent être effectués facilement, Vous n'avez même pas besoin de faire la collecte vous-même.
 Pictures
Pictures
Cet assistant de données d'IA basé sur LLM s'appelle Data-Copilot et a été développé par l'équipe de l'Université du Zhejiang.
La prépublication de l'article concerné a été publiée.
Le contenu suivant est fourni par le contributeur
Divers secteurs tels que la finance, la météorologie et l'énergie génèrent chaque jour une grande quantité de données hétérogènes. Il existe un besoin urgent d’un outil permettant de gérer, traiter et afficher efficacement ces données.
DataCopilot gère et traite de manière autonome des données massives en déployant de grands modèles de langage pour répondre aux divers besoins des utilisateurs en matière de requêtes, de calculs, de prédictions, de visualisation et autres.
Il vous suffit de saisir du texte pour indiquer à DataCopilot les données que vous souhaitez voir, sans opérations fastidieuses, Pas besoin d'écrire votre propre code, DataCopilot transforme de manière autonome les données d'origine en un résultat de visualisation qui répond au mieux à l'intention de l'utilisateur.
Afin de parvenir à un cadre universel couvrant diverses formes de tâches liées aux données, l'équipe de recherche a proposé Data-Copilot.
Ce modèle résout les problèmes de risque de fuite de données, de faible puissance de calcul et d'incapacité à gérer des tâches complexes causées par la simple utilisation de LLM.
 Photos
Photos
Lors de la réception de demandes complexes, Data-Copilot concevra et planifiera indépendamment des interfaces indépendantes pour construire un flux de travail répondant aux intentions de l'utilisateur.
Sans assistance humaine, il peut transformer habilement des données brutes provenant de différentes sources et dans différents formats en sortie humanisée telle que des graphiques, des tableaux et du texte.
 Photos
Photos
Les principales contributions du projet Data-Copilot incluent :
Autant prendre l'exemple suivant pour voir les performances de Data-Copilot :
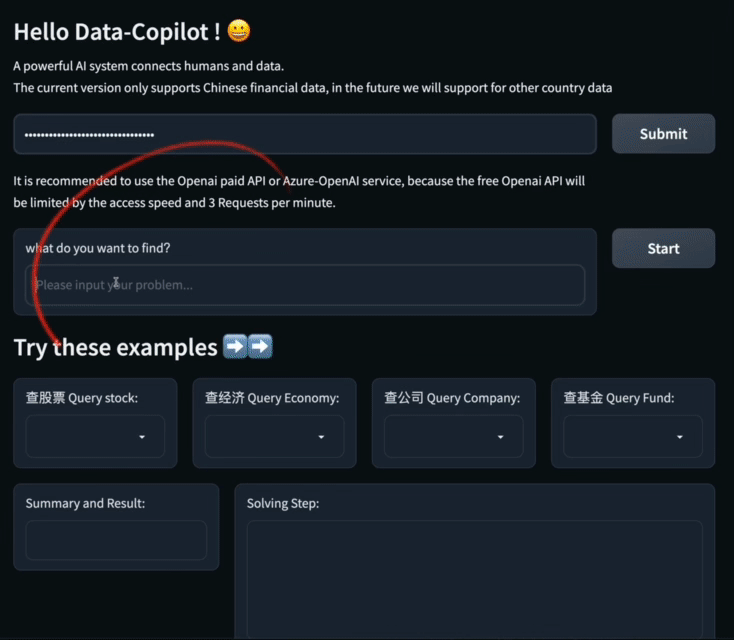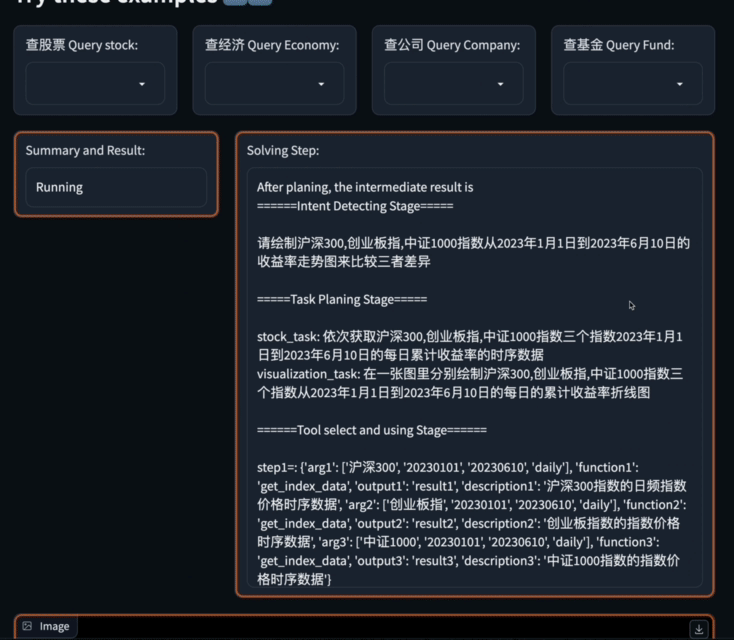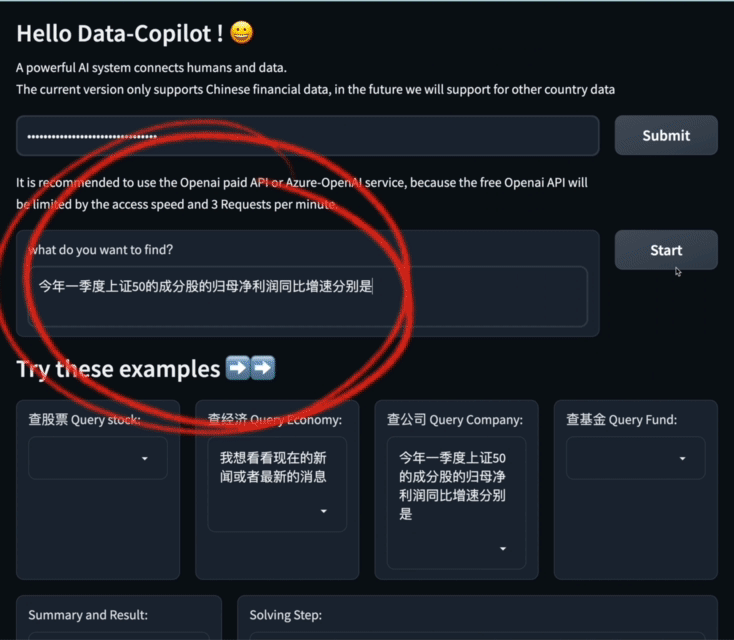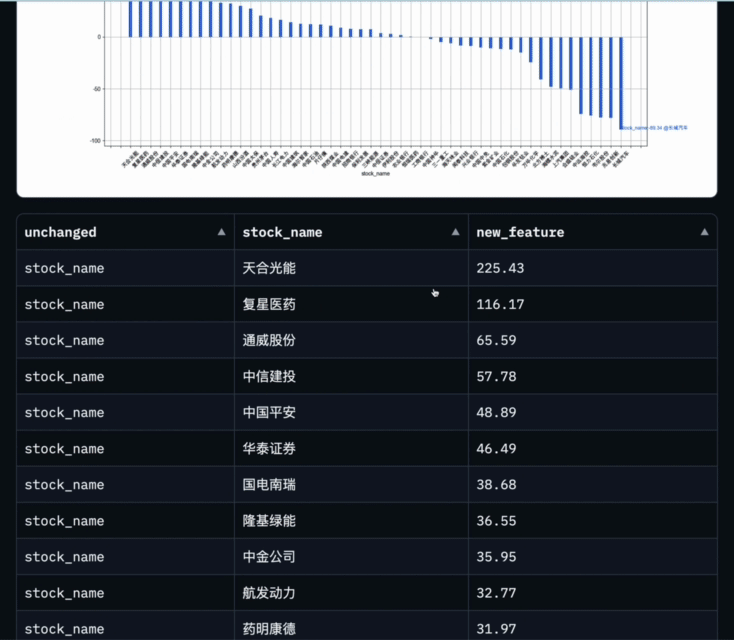
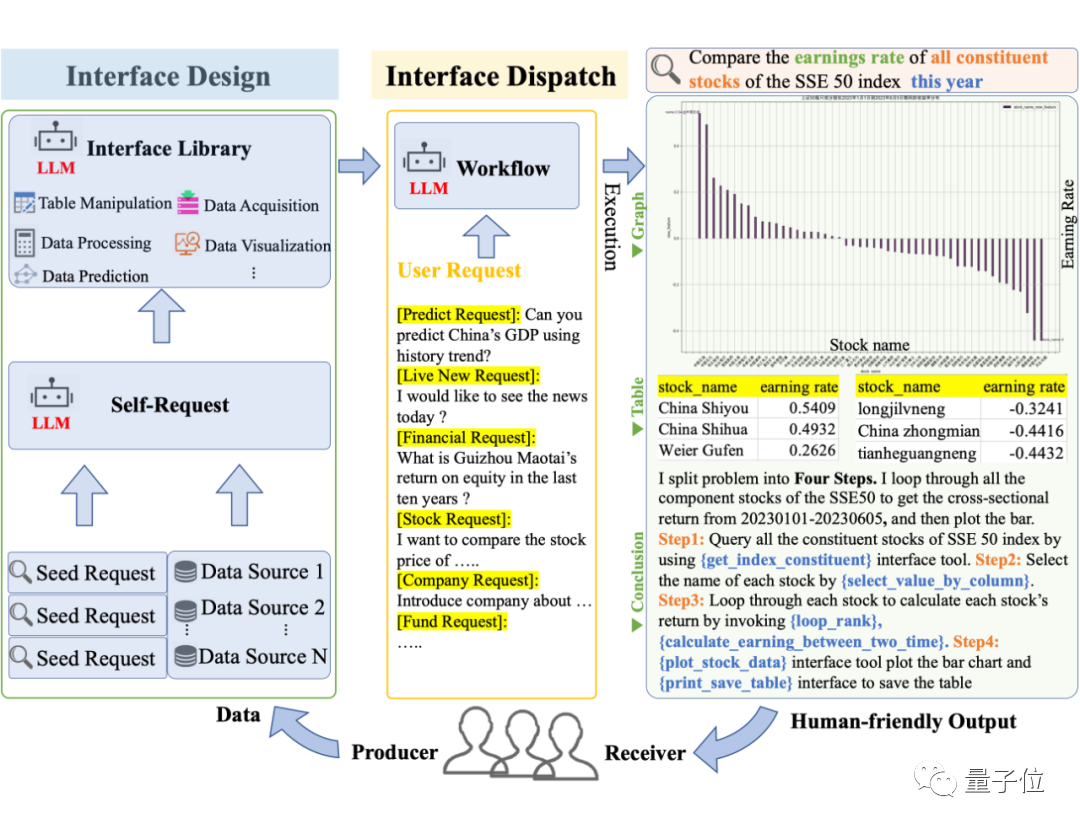
Quel est le taux de croissance d'une année sur l'autre du bénéfice net de tous les titres constitutifs du Indice Shanghai Stock Exchange 50 au premier trimestre de cette année
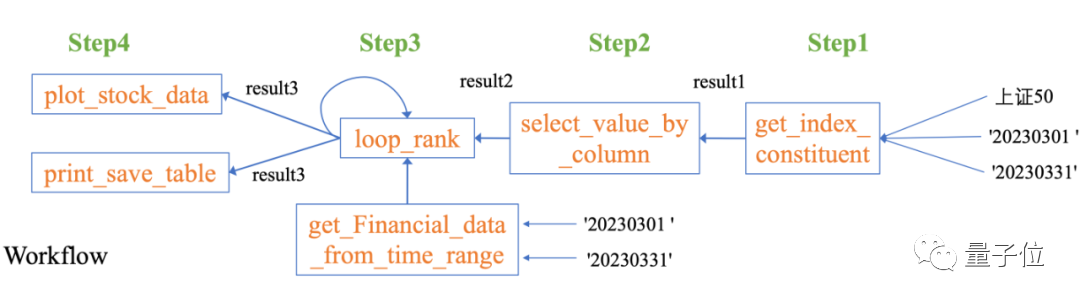
Data-Copilot Nous avons conçu indépendamment un tel flux de travail :
 Photos
Photos
Pour résoudre ce problème complexe, Data-Copilot utilise l'interface loop_rank pour implémenter plusieurs requêtes en boucle .
Data-Copilot a obtenu ce résultat après avoir exécuté ce workflow :
L'abscisse est le nom de chaque stock de composants, et l'ordonnée est le taux de croissance d'une année sur l'autre du bénéfice net au premier trimestre
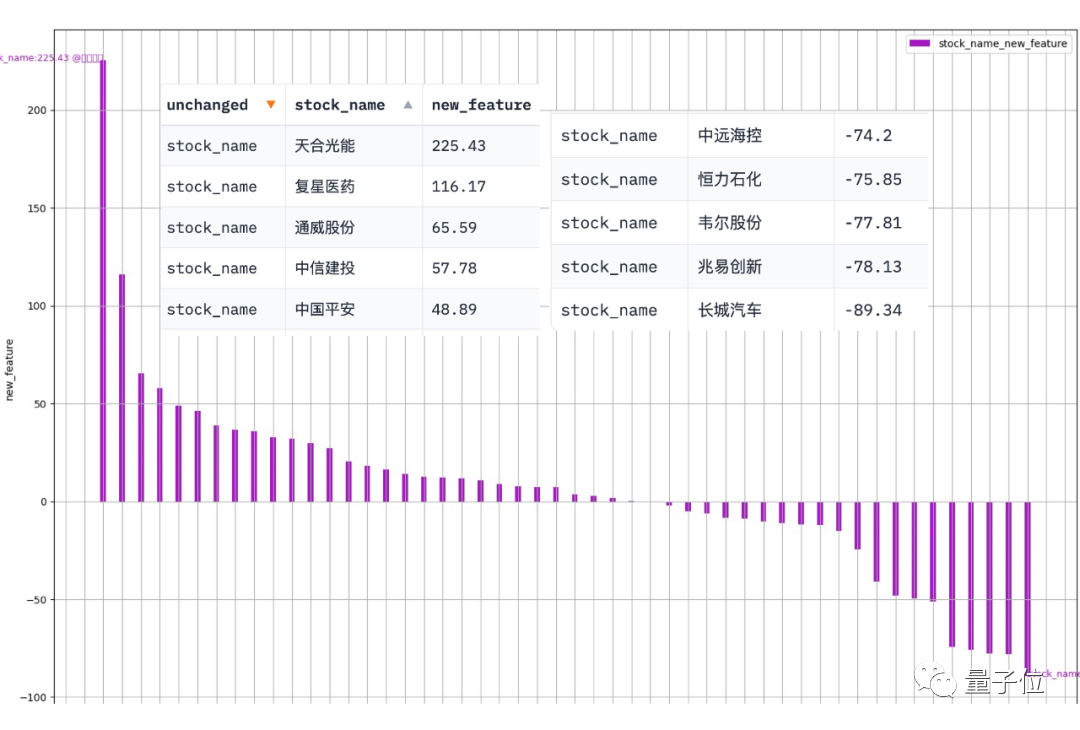 Photos
Photos
En plus des processus généraux de traitement des données, Data-Copilot peut également générer une grande variété de flux de travail.
L'équipe de recherche a testé Data-Copilot dans deux modes de flux de travail : prédictif et parallèle.
Data-Copilot peut également prédire des parties autres que les données connues. Par exemple, saisissez la question suivante :
Prédire le PIB trimestriel de la Chine au cours des quatre trimestres suivants
Data-Copilot déploie ce flux de travail :
Obtenir l'historique. Données PIB → Utiliser un modèle de régression linéaire pour prédire l'avenir → Tableau de sortie
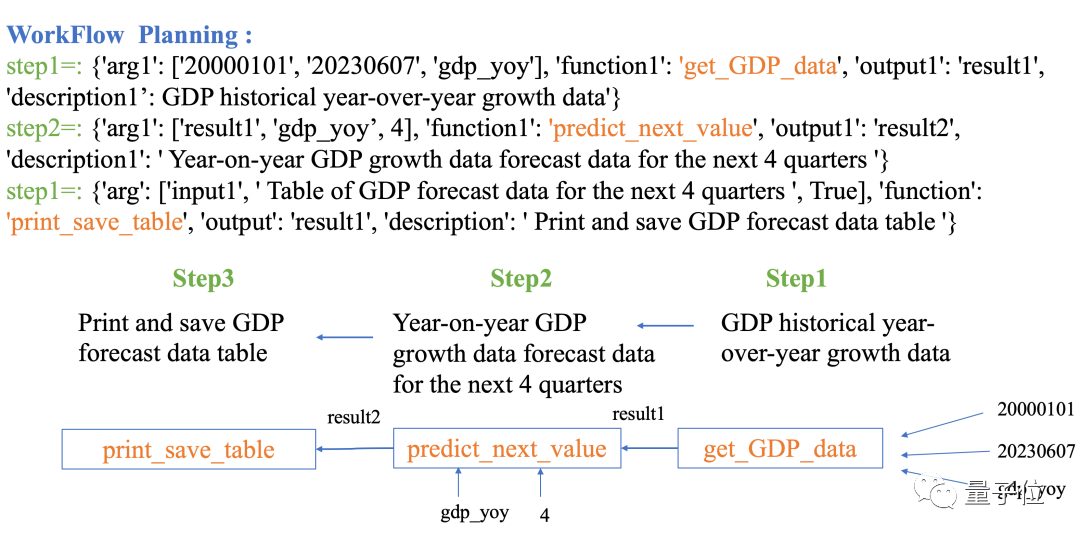 image
image
Les résultats après exécution sont les suivants :
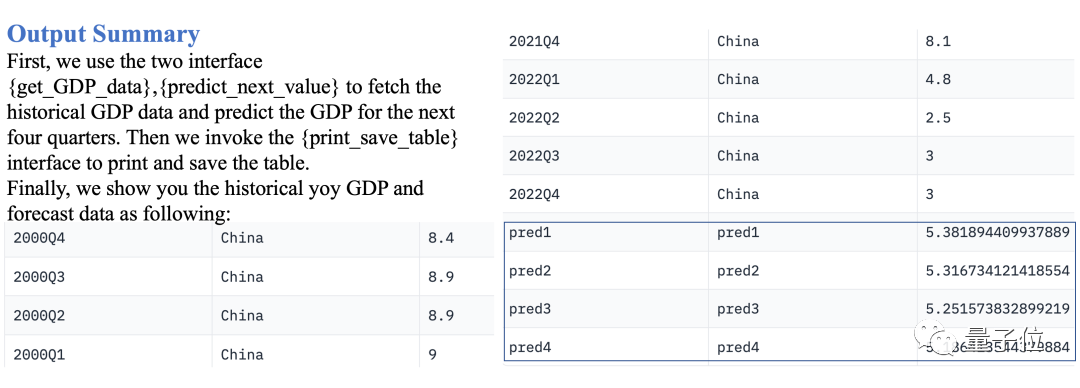 Photos
Photos
Je veux voir les ratios cours/bénéfice de CATL et Kweichow Moutai au cours des trois dernières années
Le flux de travail correspondant est :
Obtenir les données sur le cours des actions → Calculer les indices associés → Générer des graphiques
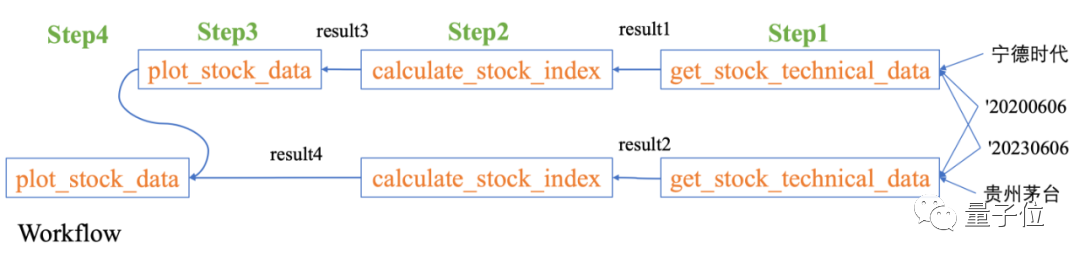 Image
Image
Le travail lié des deux actions est parallèle en même temps, et le graphique final est le suivant :
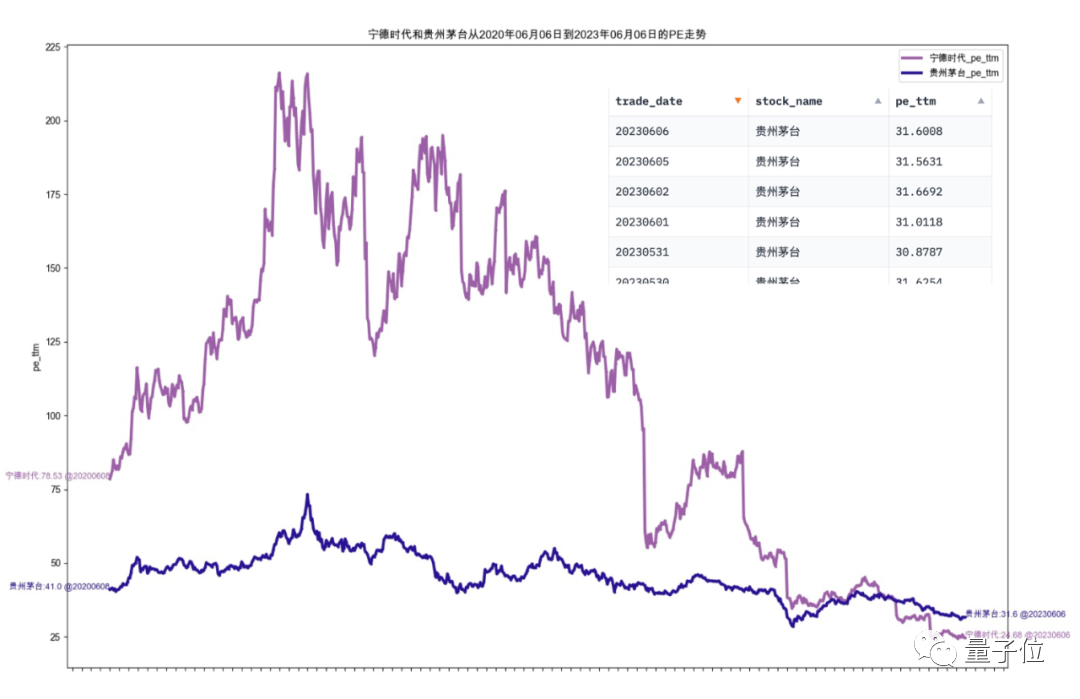 Image
Image
Data-Copilot est une méthode générale grand système de modèle de langage avec conception d'interface et Il y a deux étapes principales dans la planification de l'interface.
Data-Copilot réalise un traitement et une visualisation hautement automatisés des données en générant automatiquement des requêtes et en concevant indépendamment des interfaces pour répondre aux besoins des utilisateurs et afficher les résultats aux utilisateurs sous diverses formes.
 Photos
Photos
Comme le montre l'image ci-dessus, la gestion des données doit être mise en œuvre en premier et la première étape nécessite des outils d'interface.
Data-Copilot concevra un grand nombre d'interfaces comme outils de gestion de données. Les interfaces sont des modules composés de langage naturel (description fonctionnelle) et de code (implémentation), qui sont responsables de tâches telles que l'acquisition et le traitement des données.
Comme indiqué ci-dessous : Outil d'interface conçu par Data-Copilot pour le traitement des données
 image
image
Au cours de l'étape précédente, les chercheurs ont obtenu divers outils pour l'acquisition, le traitement et la visualisation des données. Outils d'interface communs. Chaque interface possède une description fonctionnelle claire et explicite. Comme le montre la figure ci-dessus pour les deux requêtes, Data-Copilot forme un flux de travail allant des données aux résultats sous plusieurs formulaires en planifiant et en appelant différentes interfaces dans des requêtes en temps réel.
Guidé par des descriptions d'interfaces et des exemples, Data-Copilot orchestre la planification des interfaces au sein de chaque étape, soit séquentiellement, soit en parallèle.
Data-Copilot réduit considérablement la dépendance à l'égard d'un travail et d'une expertise fastidieux en intégrant des LLM à chaque étape des tâches liées aux données, transformant automatiquement les données brutes en résultats de visualisation conviviaux basés sur les demandes des utilisateurs.
Page du projet GitHub : https://github.com/zwq2018/Data-Copilot
Adresse papier : https://arxiv.org/abs/2306.07209
HuggingFace DÉMO : https://huggingface .co/spaces/zwq2018/Data-Copilot
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment lier des données dans une liste déroulante
Comment lier des données dans une liste déroulante
 Comment définir la transparence en CSS
Comment définir la transparence en CSS
 paramètres de compatibilité du navigateur Edge
paramètres de compatibilité du navigateur Edge
 Comment résoudre Autorisation refusée
Comment résoudre Autorisation refusée
 Le rôle de l'interface VGA
Le rôle de l'interface VGA
 L'amplificateur de signal wifi est-il utile ?
L'amplificateur de signal wifi est-il utile ?
 Solution à javascript :;
Solution à javascript :;
 Quelles sont les méthodes pour empêcher l'injection SQL ?
Quelles sont les méthodes pour empêcher l'injection SQL ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



