



L'effet de la pré- la formation est directe et les ressources requises sont souvent prohibitives. Si cette méthode de pré-formation existe, sa mise en route nécessite très peu de puissance de calcul, de données et de ressources manuelles, voire seulement le corpus original d'une seule personne et d'une seule carte. Après un traitement de données non supervisé et un transfert de pré-formation vers votre propre domaine, vous pouvez obtenir des capacités de raisonnement NLG, NLG et représentation vectorielle à échantillon nul. Les capacités de rappel d'autres représentations vectorielles dépassent BM25. 
 # 🎜 🎜#
# 🎜 🎜#
Dans notre scénario, le champ de données est très différent du champ général, et même le vocabulaire doit être considérablement remplacé, et l'échelle de l'entreprise est également suffisante. S'il n'est pas pré-entraîné, le modèle sera également affiné spécifiquement pour chaque tâche en aval. Les bénéfices attendus de la pré-formation sont certains. Notre corpus est pauvre en qualité, mais suffisant en quantité. Les ressources en puissance de calcul sont très limitées et peuvent être compensées en faisant correspondre les réserves de talents correspondantes. A l’heure actuelle, les conditions d’une pré-formation sont déjà réunies.
Le facteur qui détermine directement la façon dont nous commençons la pré-formation est qu'il y a trop de modèles en aval qui doivent être maintenus, ce qui nécessite des machines et des ressources humaines. Pour chaque tâche, une grande quantité de données doit être préparée pour former un modèle dédié, et la complexité de la gestion du modèle augmente considérablement. Nous explorons donc la pré-formation, dans l'espoir de créer une tâche de pré-formation unifiée qui profitera à tous les modèles en aval. Lorsque nous faisons cela, cela ne se fait pas du jour au lendemain. Plus le nombre de modèles à maintenir signifie également plus d'expérience de modèle, combinée à l'expérience de plusieurs projets précédents, y compris un apprentissage auto-supervisé, un apprentissage contrasté, un apprentissage multitâche et autres. modèles, après des expériences et des itérations répétées, la fusion s'est formée.
L'image ci-dessus est le paradigme traditionnel du pipeline NLP, basé sur le Les modèles généraux de pré-formation, une fois la pré-formation facultative à la migration terminée, collectent des ensembles de données pour chaque tâche en aval, affinent la formation et nécessitent beaucoup de main-d'œuvre et de cartes graphiques pour maintenir plusieurs modèles et services en aval.
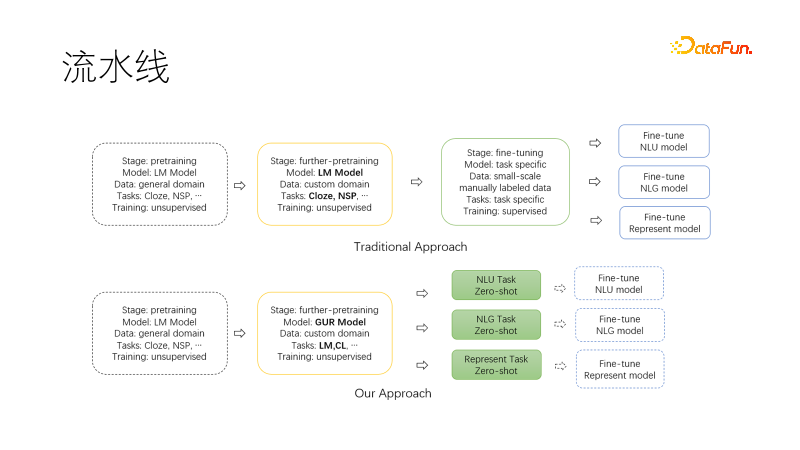
La figure suivante est le nouveau paradigme que nous avons proposé Lors de la migration vers notre domaine pour poursuivre la pré-formation, nous utilisons le langage commun. Les tâches de modélisation et d'apprentissage comparatif permettent au modèle de sortie d'avoir des capacités de représentation NLU, NLG et vectorielle à échantillon nul. Ces capacités sont modélisées et peuvent être utilisées à la demande. De cette manière, il y a moins de modèles à maintenir, notamment au démarrage du projet, ils peuvent être utilisés directement pour la recherche. Si des ajustements supplémentaires sont nécessaires, la quantité de données nécessaires est également considérablement réduite.
2. Comment se pré-entraîner
#🎜🎜 ## 🎜🎜#
Il s'agit de notre architecture de modèle pré-entraînée, comprenant l'encodeur, le décodeur et la tête de représentation vectorielle du Transformer.
Les objectifs de la pré-formation incluent la modélisation du langage et la représentation contrastive. La fonction de perte est Perte totale = Perte LM + Perte α CL Elle est formée conjointement avec des tâches de modélisation du langage et des tâches de représentation contrastive, où α représente le coefficient de poids. La modélisation du langage utilise un modèle de masque, similaire à T5, qui décode uniquement la partie du masque. La tâche de représentation contrastive est similaire à CLIP. Dans un lot, il existe une paire d'échantillons positifs d'entraînement associés et d'autres échantillons non négatifs. Pour chaque paire d'échantillons (i, I) i, il existe un échantillon positif I et l'autre. les échantillons sont des échantillons négatifs, utilisant une perte d'entropie croisée symétrique pour forcer la représentation des échantillons positifs à être proche et la représentation des échantillons négatifs à être éloignée. L'utilisation du décodage T5 peut raccourcir la longueur de décodage. Une représentation vectorielle non linéaire est placée au-dessus de l'encodeur de chargement de tête. L'une est que la représentation vectorielle doit être plus rapide dans le scénario, et l'autre est que les deux fonctions affichées agissent à distance pour éviter les conflits de cibles d'entraînement. Voici donc la question. Les tâches Cloze sont très courantes et ne nécessitent pas d'échantillons. Alors, d'où viennent les paires d'échantillons similaires ?

Bien sûr, en tant que méthode de pré-entraînement, les paires d'échantillons doivent être extraites par un algorithme non supervisé. Habituellement, la méthode de base utilisée pour extraire des échantillons positifs dans le domaine de la recherche d'informations est le reverse cloze, qui extrait plusieurs fragments d'un document et suppose qu'ils sont liés. Ici, nous divisons le document en phrases, puis énumérons les paires de phrases. Nous utilisons la sous-chaîne commune la plus longue pour déterminer si deux phrases sont liées. Comme le montre la figure, deux paires de phrases positives et négatives sont prises. Si la sous-chaîne commune la plus longue est suffisamment longue dans une certaine mesure, elle est jugée similaire, sinon elle ne l'est pas. Le seuil est choisi par vous-même. Par exemple, une phrase longue nécessite trois caractères chinois et davantage de lettres anglaises. Une phrase courte peut être plus détendue.
Nous utilisons la corrélation comme paire d'échantillons au lieu de l'équivalence sémantique car les deux objectifs sont contradictoires. Comme le montre la figure ci-dessus, les significations de chat attrapant la souris et de souris attrapant le chat sont opposées mais liées. Notre recherche de scénarios est principalement axée sur la pertinence. De plus, la corrélation est plus large que l’équivalence sémantique, et l’équivalence sémantique est plus adaptée à un ajustement continu basé sur la corrélation.
Certaines phrases sont filtrées plusieurs fois et certaines phrases ne sont pas filtrées. Nous limitons la fréquence des phrases sélectionnées. Pour les phrases infructueuses, elles peuvent être copiées en tant qu'échantillons positifs, intégrées aux phrases sélectionnées, ou le cloze inversé peut être utilisé comme échantillons positifs.
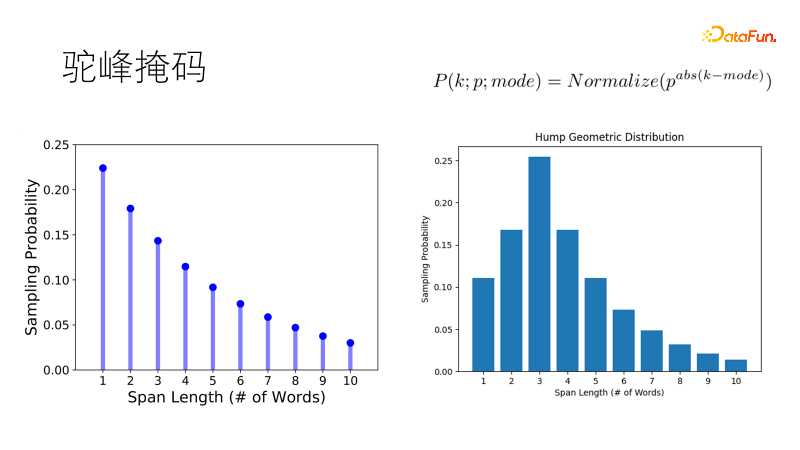
Les méthodes de masquage traditionnelles telles que SpanBert utilisent une distribution géométrique pour échantillonner la longueur du masque. Les masques courts ont une probabilité élevée et les masques longs ont une faible probabilité et conviennent aux phrases longues. Mais notre corpus est fragmenté Face à des phrases courtes d’un ou vingt mots, la tendance traditionnelle est de masquer deux mots simples plutôt qu’un double mot, ce qui ne répond pas à nos attentes. Nous avons donc amélioré cette distribution afin qu'elle ait la plus grande probabilité d'échantillonner la longueur optimale, et la probabilité d'autres longueurs diminue progressivement, tout comme la bosse d'un chameau, devenant une distribution géométrique à bosse de chameau, qui est plus robuste dans notre courte phrase. des scénarios riches.
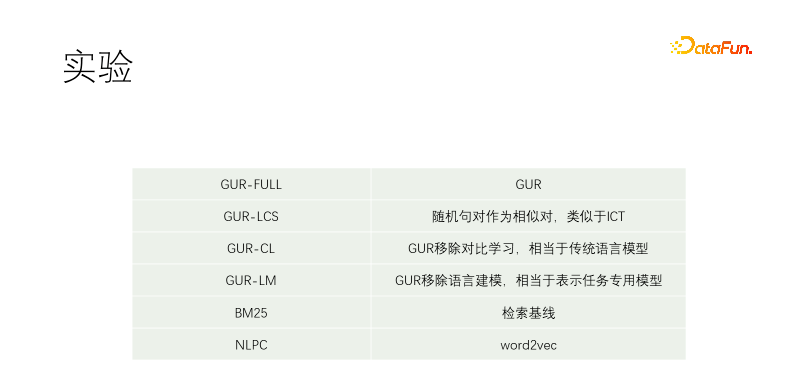
Nous avons mené une expérience contrôlée. Y compris GUR-FULL, qui utilise la modélisation du langage et la représentation contrastive vectorielle ; les paires d'échantillons UR-LCS ne sont pas filtrées par LCS ; UR-CL n'a pas d'apprentissage de représentation contrastive, ce qui est équivalent à un modèle de langage traditionnel ; l'apprentissage de représentation contrastive, sans apprentissage de modélisation du langage, équivaut à un réglage précis spécifiquement pour les tâches en aval ; NLPC est un opérateur word2vec dans Baidu ;
L'expérience a commencé par un pré-entraînement T5-small et s'est poursuivi. Les corpus de formation comprennent Wikipédia, Wikisource, CSL et nos propres corpus. Notre propre corpus est capturé à partir de la bibliothèque de matériaux, et la qualité est très mauvaise. La partie de meilleure qualité est le titre de la bibliothèque de matériaux. Par conséquent, lors de la recherche d’échantillons positifs dans d’autres documents, presque toutes les paires de textes sont filtrées, tandis que dans notre corpus, le titre est utilisé pour correspondre à chaque phrase du texte. GUR-LCS n'a pas été sélectionné par LCS. Si cela n'est pas fait de cette façon, la paire d'échantillons sera trop mauvaise. Si cela est fait de cette façon, la différence avec GUR-FULL sera beaucoup plus petite.
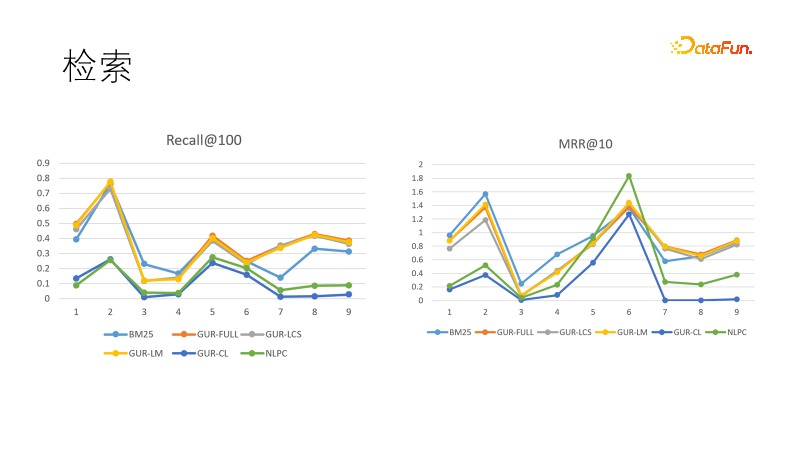
Nous évaluons l'effet de représentation vectorielle du modèle dans plusieurs tâches de récupération. L'image de gauche montre les performances de plusieurs modèles en rappel. Nous avons constaté que les modèles appris grâce à la représentation vectorielle étaient les plus performants, surpassant BM25. Nous avons également comparé les objectifs de classement, et cette fois, BM25 est revenu pour gagner. Cela montre que le modèle dense a une forte capacité de généralisation et que le modèle clairsemé a un fort déterminisme, et que les deux peuvent se compléter. En fait, dans les tâches en aval dans le domaine de la recherche d’informations, des modèles denses et des modèles clairsemés sont souvent utilisés ensemble.
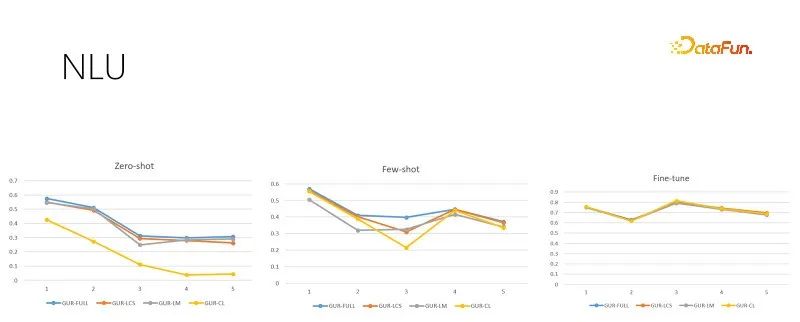
Les images ci-dessus sont dans des couleurs différentes formation Taille de l'échantillon des tâches d'évaluation NLU, chaque tâche comporte des dizaines, voire des centaines de catégories, et l'effet est évalué par le score ACC. Le modèle GUR convertit également les étiquettes de classification en vecteurs pour trouver l'étiquette la plus proche pour chaque phrase. La figure ci-dessus, de gauche à droite, montre un échantillon nul, un petit échantillon et une évaluation suffisamment fine en fonction de la taille croissante de l'échantillon de formation. L'image de droite représente les performances du modèle après un réglage suffisamment fin, qui montre la difficulté de chaque sous-tâche et constitue également le plafond des performances avec un échantillon nul et un petit échantillon. On peut voir que le modèle GUR peut réaliser un raisonnement à échantillon nul dans certaines tâches de classification en s'appuyant sur la représentation vectorielle. Et la capacité d’échantillons réduits du modèle GUR est la plus remarquable.
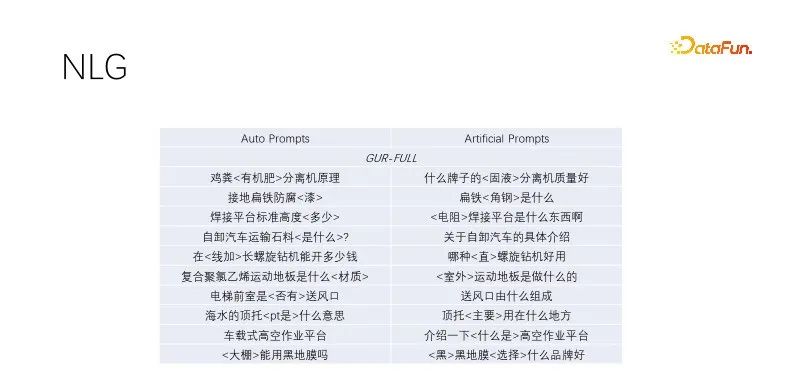
C'est zéro chez NLG Sample performance. Lorsque nous effectuons la génération de titres et l'expansion des requêtes, nous exploitons les titres avec un trafic de haute qualité, conservons les mots-clés et masquons de manière aléatoire les non-mots-clés. Les modèles formés par la modélisation linguistique fonctionnent bien. Cet effet d'invite automatique est similaire à l'effet de cible construit manuellement, avec une plus grande diversité et capable de répondre à une production de masse. Plusieurs modèles ayant subi des tâches de modélisation de langage fonctionnent de la même manière. La figure ci-dessus utilise l'exemple de modèle GUR.
Cet article propose un nouveau pré- paradigme de formation, les expériences de contrôle ci-dessus montrent que la formation conjointe ne provoquera pas de conflits d'objectifs. Lorsque le modèle GUR continue d'être pré-entraîné, il peut augmenter ses capacités de représentation vectorielle tout en conservant ses capacités de modélisation de langage. Pré-entraînement une fois, inférence avec zéro échantillon original partout. Convient pour une pré-formation à faible coût pour les services commerciaux.

Le lien ci-dessus enregistre notre Pour détails de la formation et références, voir la citation de l'article. La version du code est un peu plus récente que l'article. J’espère apporter une petite contribution à la démocratisation de l’IA. Les grands et petits modèles ont leurs propres scénarios d'application. En plus d'être directement utilisé pour les tâches en aval, le modèle GUR peut également être utilisé conjointement avec de grands modèles. Dans le pipeline, nous utilisons d'abord le petit modèle pour la reconnaissance, puis le grand modèle pour instruire des tâches. Le grand modèle peut également produire des échantillons pour le petit modèle, et le petit modèle GUR peut fournir une récupération vectorielle pour le grand modèle.
Le modèle présenté dans le document est un petit modèle sélectionné pour explorer plusieurs expériences. En pratique, le gain est évident s'il s'agit d'un modèle plus grand. est sélectionné. Notre exploration n'est pas suffisante et des travaux supplémentaires sont nécessaires. Si vous le souhaitez, vous pouvez contacter laohur@gmail.com et espérer progresser avec tout le monde.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelle est la valeur de retour de la fonction
Quelle est la valeur de retour de la fonction
 point de symbole spécial
point de symbole spécial
 Méthodes de chiffrement courantes pour le stockage de données chiffrées
Méthodes de chiffrement courantes pour le stockage de données chiffrées
 Introduction aux commandes pour créer de nouveaux fichiers sous Linux
Introduction aux commandes pour créer de nouveaux fichiers sous Linux
 Les dernières nouvelles officielles d'aujourd'hui concernant PaiCoin sont vraies
Les dernières nouvelles officielles d'aujourd'hui concernant PaiCoin sont vraies
 le bios ne peut pas détecter le disque SSD
le bios ne peut pas détecter le disque SSD
 emplacement.recherche
emplacement.recherche
 Barre oblique du tableau Excel divisée en deux
Barre oblique du tableau Excel divisée en deux








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



