


Les méthodes de pré-formation multimodales stimulent également le développement de l'apprentissage des représentations 3D en alignant des formes 3D, des images 2D et des descriptions linguistiques correspondantes.
Cependant, le cadre de pré-formation multimodal existantles méthodes de collecte de données manquent d'évolutivité, ce qui limite considérablement le potentiel de l'apprentissage multimodal. Le principal goulot d'étranglement réside dans l'évolutivité et l'exhaustivité des modalités linguistiques.
Récemment, Salesforce AI s'est associé à l'Université Stanford et à l'Université du Texas à Austin pour lancer les projets ULIP (CVP R2023) et ULIP-2, qui ouvrent un nouveau chapitre dans la compréhension de la 3D.

Lien papier : https://arxiv.org/pdf/2212.05171.pdf
Lien papier : https://arxiv.org/pdf/2305.08275.pdf
Lien du code : https://github.com/salesforce/ULIP
Les chercheurs ont utilisé une approche unique pour pré-entraîner le modèle à l'aide de nuages de points 3D, d'images et de texte, en les alignant dans un espace de fonctionnalités unifié. . Cette approche permet d'obtenir des résultats de pointe dans les tâches de classification 3D et ouvre de nouvelles possibilités pour les tâches inter-domaines telles que la récupération d'image en 3D.
Et ULIP-2 rend cette pré-formation multimodale possible sans aucune annotation manuelle, ce qui la rend évolutive à grande échelle.
ULIP-2 a obtenu des améliorations significatives des performances sur la classification zéro-shot en aval de ModelNet40, atteignant la précision la plus élevée de 74,0 % sur le benchmark réel ScanObjectNN, il a atteint 91,5 % avec seulement 1,4 million de paramètres. marque une percée dans l'apprentissage de représentations 3D multimodales évolutives sans avoir besoin d'annotation 3D humaine. " ULIP - Objaverse Triplets" et "ULIP - ShapeNet Triplets") sont open source.
Contexte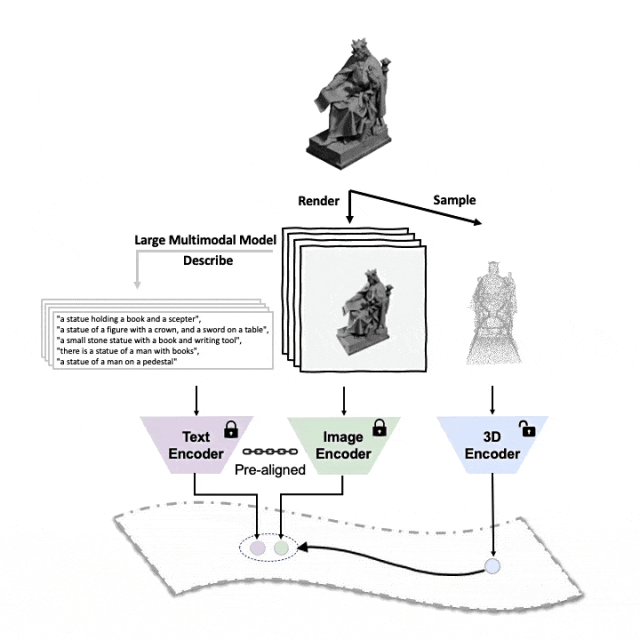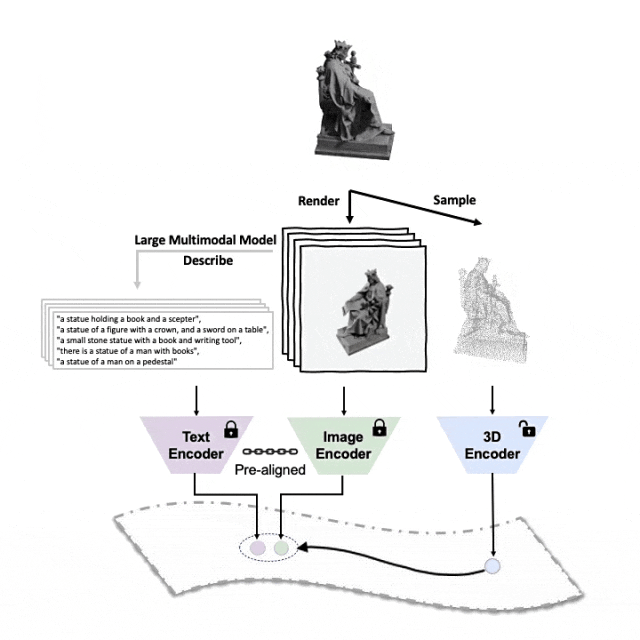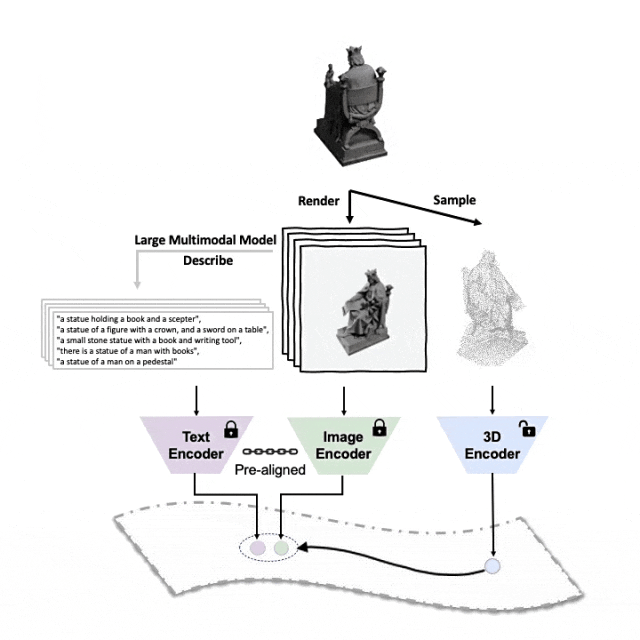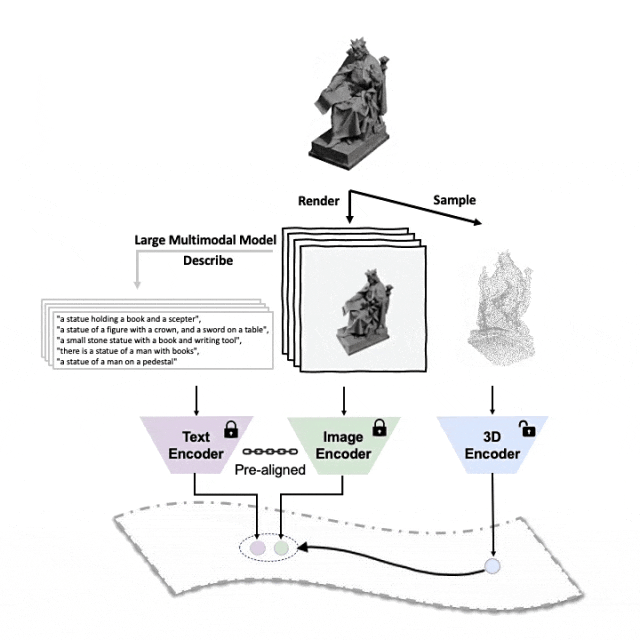
La compréhension 3D est une partie importante du domaine de l'intelligence artificielle, qui permet aux machines de percevoir et d'interagir dans un espace tridimensionnel comme les humains. Cette capacité a des applications importantes dans des domaines tels que les véhicules autonomes, la robotique, la réalité virtuelle et la réalité augmentée.
Cependant, la compréhension de la 3D a toujours été confrontée à d'énormes défis en raison de la complexité du traitement et de l'interprétation des données 3D, ainsi que du coût de la collecte et de l'annotation des données 3D.
ULIP
Cadre de pré-formation tri-modal et ses tâches en aval
ULIP (déjà accepté par CVPR2023) adopte une approche unique utilisant des nuages de points 3D, des images et du texte est pré -formés sur le modèle pour les aligner dans un espace de représentation unifié.
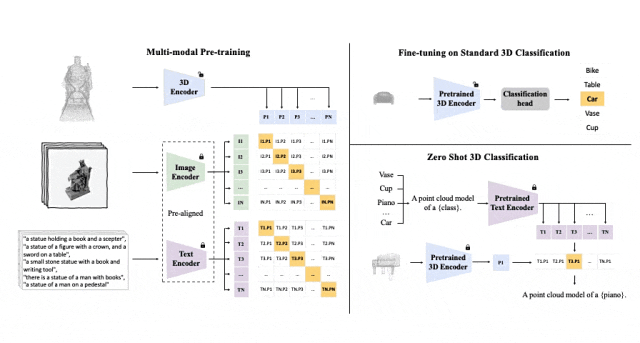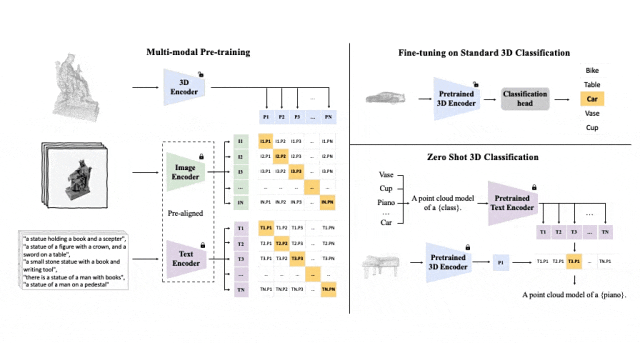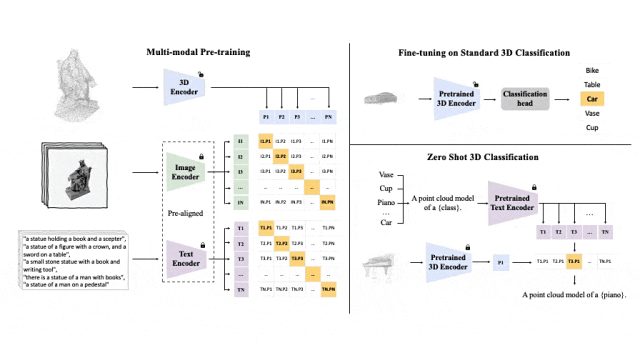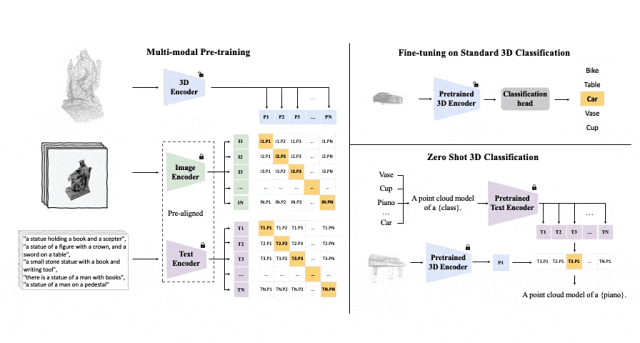
Ces encodeurs alignent les caractéristiques des trois modalités dans un espace de représentation unifié, permettant au modèle de comprendre et de classer les objets 3D plus efficacement.
Cet apprentissage amélioré de la représentation 3D améliore non seulement la compréhension du modèle des données 3D, mais rend également possibles des applications multimodales telles que la classification 3D sans plan et la récupération d'image en 3D grâce à l'encodeur 3D. Un contexte multimodal est obtenu.
La fonction de perte pré-entraînement de l'ULIP est la suivante :
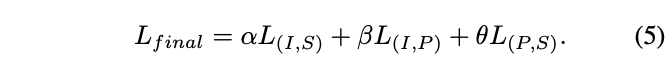
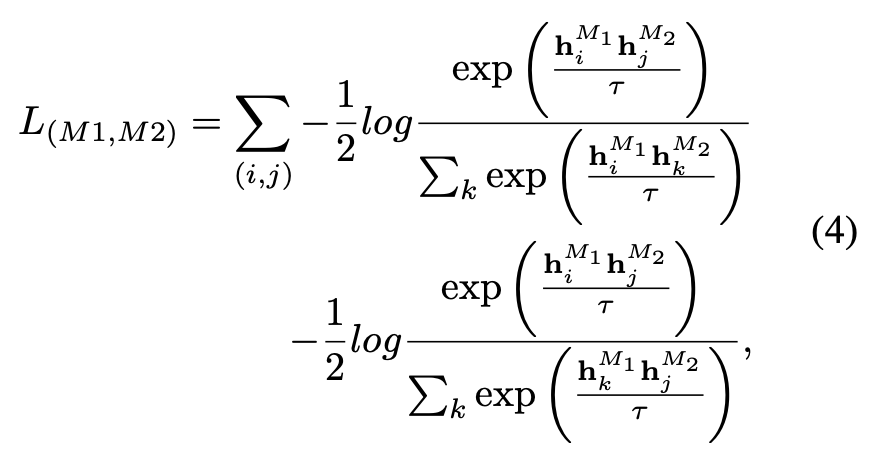

Étonnamment, comparé aux autres modèles 3D récupérés, le premier modèle 3D récupéré a l'apparence la plus proche de l'image de requête.
Par exemple, lorsque nous utilisons des images de différents types d'avions (chasseurs et avions de ligne) pour la récupération (deuxième et troisième lignes), le plus proche récupéré. Le nuage de points 3D préserve toujours les différences subtiles de l’image de requête.
ULIP-2
ULIP -2 Basé sur ULIP, utilisez des modèles multimodaux à grande échelle pour générer des descriptions de langage correspondantes complètes pour les objets 3D, collectant ainsi des données de pré-formation multimodales évolutives sans aucune annotation manuelle, rendant le processus de pré-formation et de post-formation -formation Le modèle est plus efficace et son adaptabilité est renforcée.
ULIP-2 consiste à générer des descriptions multi-angles et dans différents langages pour chaque objet 3D, puis à utiliser ces descriptions pour entraîner le modèle à créer des objets 3D et des images 2D. , Il est aligné sur la description du langage dans l'espace des fonctionnalités.
Ce framework permet la création de grands ensembles de données trimodaux sans annotation manuelle, utilisant ainsi pleinement le potentiel de la pré-formation multimodale.
ULIP-2 a également publié les ensembles de données trimodales à grande échelle générés : "ULIP - Objaverse Triplets" et "ULIP - ShapeNet Triplets".

#🎜🎜 ## 🎜🎜#Résultats expérimentaux La série ULIP a obtenu des résultats étonnants en peaufinant les expériences sur les tâches multimodales en aval et l'expression 3D, en particulier dans ULIP-2 Le pré -la formation peut être réalisée sans aucune annotation manuelle.
ULIP-2 a obtenu des améliorations significatives (74,0 % de précision top-1) dans la tâche de classification zéro-shot en aval de ModelNet40 sur le benchmark réel ScanObjectNN lors des tests ; , il a atteint une précision globale de 91,5 % en utilisant seulement 1,4 million de paramètres, marquant une percée dans l'apprentissage de représentations 3D multimodales évolutives sans avoir besoin d'annotation 3D manuelle.
Expérience d'ablation
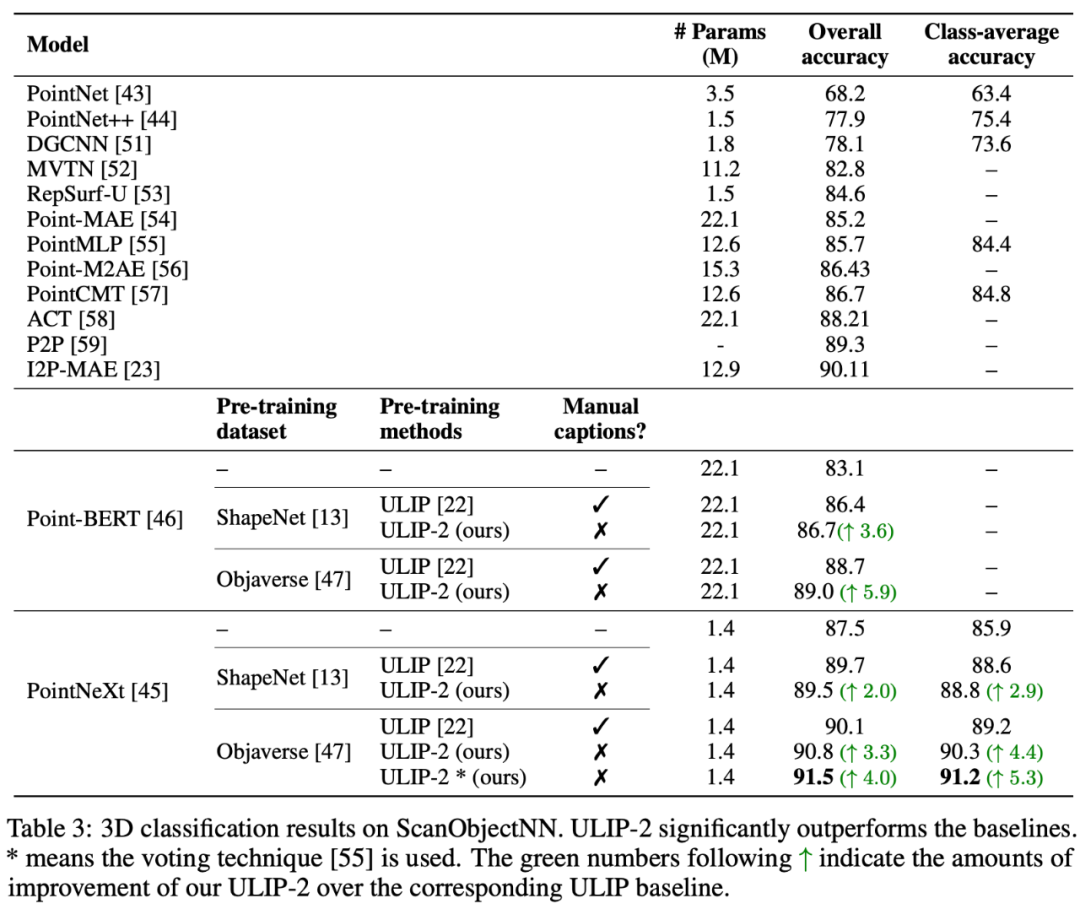 Les deux articles ont mené des expériences d'ablation détaillées.
Les deux articles ont mené des expériences d'ablation détaillées.
Dans "ULIP : Learning a Unified Representation of Language, Images, and Point Clouds for 3D Understanding", étant donné que le cadre de pré-formation de l'ULIP implique la participation de trois modalités, l'auteur a utilisé des expériences pour explorer s'il fallait aligner seulement deux des Est-il préférable d'aligner un mode ou les trois modes ? Les résultats expérimentaux sont les suivants :
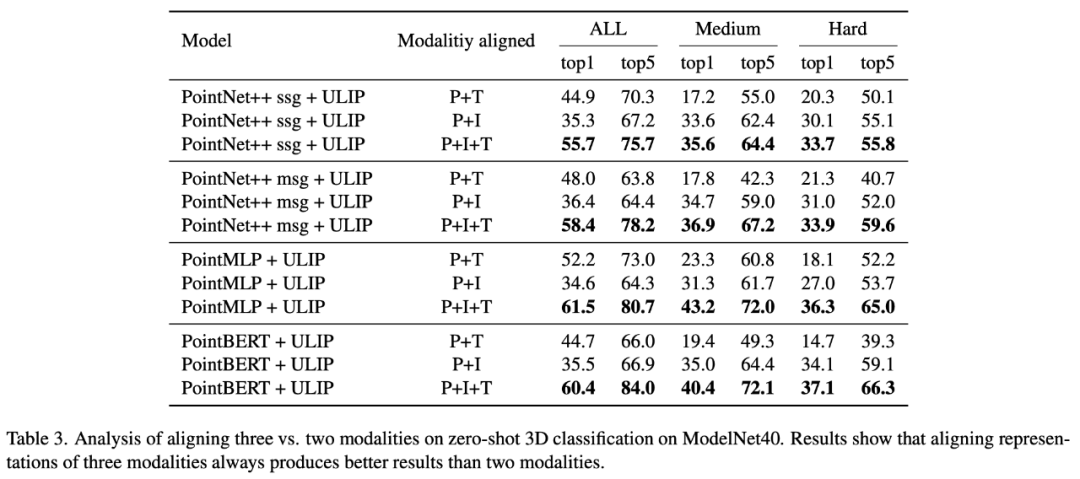
Comme le montrent les résultats expérimentaux, dans différents squelettes 3D, l'alignement de trois modes est plus cohérent que l'alignement. seulement deux Cette modalité est bonne, ce qui prouve également la rationalité du cadre de pré-formation de l'ULIP.
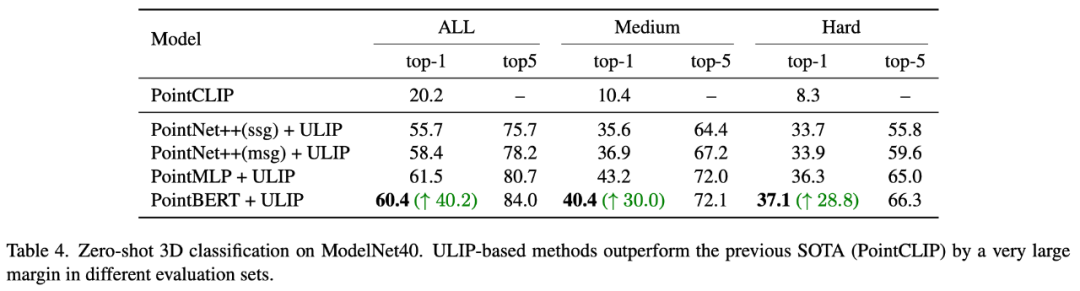
Dans "ULIP-2 : Towards Scalable Multimodal Pre-training for 3D Understanding", l'auteur a exploré l'impact de différents modèles multimodaux à grande échelle sur le cadre pré-entraîné :
 .
.
Les résultats expérimentaux montrent que l'effet de la pré-formation du cadre ULIP-2 peut être amélioré avec la mise à niveau du modèle multimodal à grande échelle utilisé, et qu'il présente un certain potentiel de croissance.
Dans ULIP-2, l'auteur a également exploré comment l'utilisation de différents nombres de vues pour générer l'ensemble de données trimodal affecterait les performances globales de pré-entraînement :
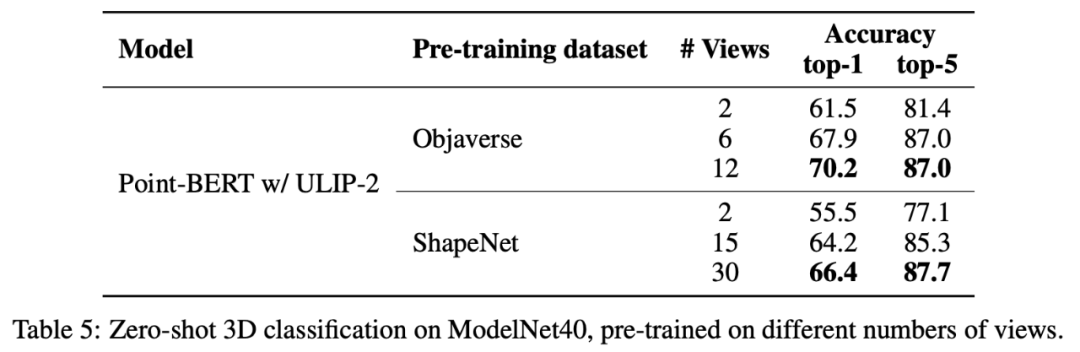
. Résultats expérimentaux Il est montré qu'à mesure que le nombre de vues utilisées augmente, l'effet de la classification zéro du modèle pré-entraîné augmente également.
Cela conforte également le point de l'ULIP-2 selon lequel une description linguistique plus complète et plus diversifiée aura un effet positif sur la pré-formation multimodale.
De plus, ULIP-2 a également exploré l'impact de la prise des descriptions linguistiques de différents topk triés par CLIP sur la pré-formation multimodale. Les résultats expérimentaux sont les suivants :
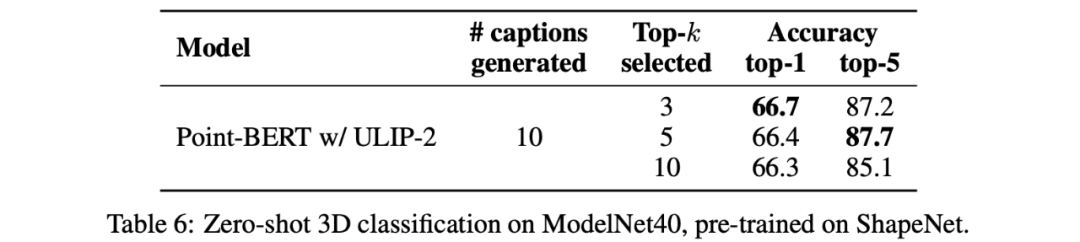
Les résultats expérimentaux. montrent que : Le framework ULIP-2 a un certain degré de robustesse face à différents topk. Top 5 est utilisé comme paramètre par défaut dans l'article.
Le projet ULIP (CVPR2023) et ULIP-2 lancés conjointement par Salesforce AI, l'Université de Stanford et l'Université du Texas à Austin changent le domaine de la compréhension 3D.
ULIP aligne différentes modalités dans un espace unifié, améliorant l'apprentissage des fonctionnalités 3D et permettant des applications multimodales.
ULIP-2 a été développé davantage pour générer des descriptions globales de langage pour les objets 3D, créer et ouvrir la source d'un grand nombre d'ensembles de données trimodaux, et ce processus ne nécessite pas d'annotation manuelle.
Ces projets établissent de nouvelles références en matière de compréhension 3D, ouvrant la voie à un avenir où les machines comprennent véritablement notre monde tridimensionnel.
Salesforce AI :
Le Xue, Mingfei Gao, Chen Xing, Ning Yu, Shu Zhang, Junnan Li (Li Junnan), Caiming Xiong (Xiong Caiming), Ran Xu (Xu Ran), Juan Carlos Niebles, Silvio Savarese.
Université de Stanford :
Prof Silvio Savarese, Professeur Juan Carlos Niebles, Professeur Jiajun Wu(Wu Jiajun).
UT Austin :
Prof Roberto Martín-Martín.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Que sont les boîtes mail internationales ?
Que sont les boîtes mail internationales ?
 Comment extraire l'audio d'une vidéo en Java
Comment extraire l'audio d'une vidéo en Java
 Processus détaillé de mise à niveau du système Win7 vers le système Win10
Processus détaillé de mise à niveau du système Win7 vers le système Win10
 fichier hôte
fichier hôte
 Les photos Windows ne peuvent pas être affichées
Les photos Windows ne peuvent pas être affichées
 valeur absolue python
valeur absolue python
 Comment calculer la factorielle d'un nombre en python
Comment calculer la factorielle d'un nombre en python
 La solution au paramètre d'interface chinoise de vscode ne prend pas effet
La solution au paramètre d'interface chinoise de vscode ne prend pas effet








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



