


Il y a quelque temps, Meta a publié le modèle d'IA "Segment Everything (SAM)", qui peut générer un masque pour n'importe quel objet dans n'importe quelle image ou vidéo, provoquant des chercheurs dans le domaine de la vision par ordinateur (CV) s'exclamer : "Le CV n'existe plus." Ensuite, il y a eu une vague de « création secondaire » dans le domaine du CV. Certains travaux ont successivement combiné des fonctions telles que la détection de cibles et la génération d'images sur la base de la segmentation, mais l'essentiel des recherches s'est basé sur des images statiques. Aujourd'hui, une nouvelle étude intitulée « Tracking Everything » propose une nouvelle méthode d'estimation du mouvement dans les vidéos dynamiques, qui permet de suivre avec précision et complètement le mouvement des objets. L'étude Il a été réalisé par des chercheurs de l'Université Cornell, de Google Research et de l'UC Berkeley. Ils ont proposé conjointement OmniMotion, une représentation de mouvement complète et globalement cohérente, et ont proposé une nouvelle méthode d'optimisation du temps de test pour effectuer une estimation précise et complète du mouvement pour chaque pixel de la vidéo.

Page d'accueil du projet : https://omnimotion.github.io/
# 🎜🎜#
Vous pouvez également visualiser de manière interactive l'état du suivi sportif : #🎜🎜 #

La piste de mouvement peut être suivie même si l'objet est bloqué, comme un chien être bloqué par un arbre en courant :

Dans le domaine de la vision par ordinateur, il existe deux estimations de mouvement couramment utilisées méthodes : suivi de caractéristiques clairsemées et flux optique dense. Cependant, les deux méthodes ont leurs propres inconvénients. Le suivi de caractéristiques éparses ne peut pas modéliser le mouvement de tous les pixels ; un flux optique dense ne peut pas capturer les trajectoires de mouvement pendant une longue période.
L'OmniMotion proposé dans cette étude utilise un volume canonique quasi-3D pour représenter la vidéo, et pour chaque pixel à travers une bijection entre espace local et espace canonique de suivi. Cette représentation permet une cohérence globale, permet le suivi de mouvement même lorsque les objets sont masqués et modélise toute combinaison de mouvement de caméra et d'objet. Cette étude démontre expérimentalement que la méthode proposée surpasse considérablement les méthodes SOTA existantes.

Cette étude prend en entrée une collection d'images avec des estimations de mouvement bruyantes appariées (par exemple, des champs de flux optique) pour former une représentation de mouvement complète et globalement cohérente de l'ensemble de la vidéo. L'étude a ensuite ajouté un processus d'optimisation qui lui a permis d'interroger la représentation avec n'importe quel pixel dans n'importe quelle image pour produire des trajectoires de mouvement fluides et précises tout au long de la vidéo. Notamment, cette méthode peut identifier quand des points du cadre sont obscurcis et peut même suivre des points via des occlusions.
Caractérisation OmniMotion
Les méthodes traditionnelles d'estimation de mouvement (telles que le flux optique par paire) perdront le suivi des objets lorsqu'ils sont obstrués. Afin de fournir des trajectoires de mouvement précises et cohérentes même sous occlusion, cette étude propose une représentation globale du mouvement OmniMotion.
Cette recherche tente de suivre avec précision le mouvement du monde réel sans reconstruction 3D dynamique explicite. La représentation OmniMotion représente la scène dans la vidéo sous la forme d'un volume 3D canonique, qui est mappé à un volume local dans chaque image via une bijection canonique locale. Les bijections canoniques locales sont paramétrées comme des réseaux de neurones et capturent le mouvement de la caméra et de la scène sans séparer les deux. Sur la base de cette approche, la vidéo peut être visualisée comme le résultat du rendu à partir du volume local d'une caméra statique fixe.
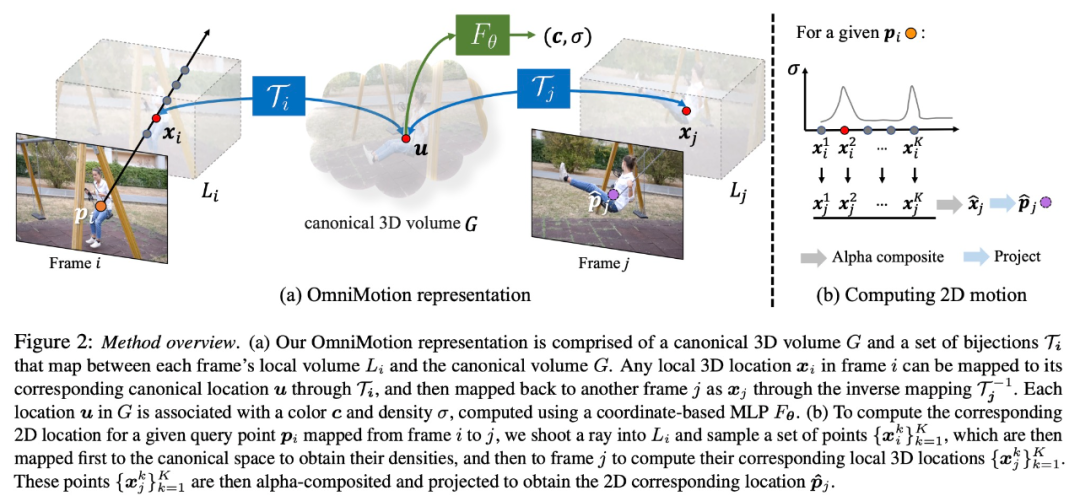
Comme OmniMotion ne fait pas clairement la distinction entre le mouvement de la caméra et celui de la scène, la représentation formée n'est pas une reconstruction de scène 3D physiquement précise. C’est pourquoi l’étude parle de caractérisation quasi-3D.
OmniMotion conserve des informations sur tous les points de la scène projetés sur chaque pixel, ainsi que leur ordre de profondeur relatif, ce qui permet de suivre les points du cadre même s'ils sont temporairement masqués.

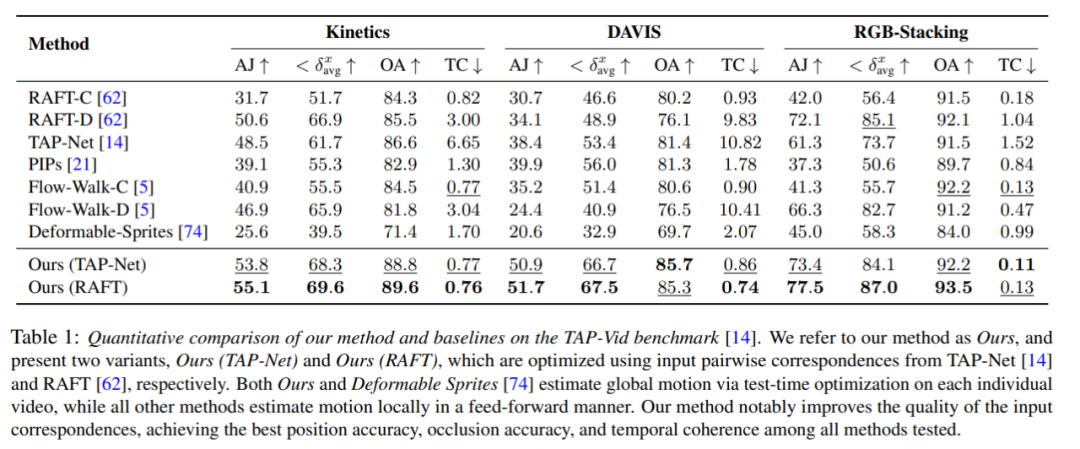
Comparaison quantitative
Les chercheurs ont comparé la méthode proposée avec le benchmark TAP-Vid, et les résultats sont présentés dans le tableau 1. On peut constater que sur différents ensembles de données, leur méthode permet toujours d’obtenir la meilleure précision de position, d’occlusion et de cohérence temporelle. Leur méthode gère bien les différentes entrées de correspondance par paire de RAFT et TAP-Net et apporte des améliorations cohérentes par rapport aux deux méthodes de base.
Comparaison qualitative
Comme le montre la figure 3, les chercheurs ont effectué une comparaison qualitative entre leur méthode et la méthode de base. La nouvelle méthode présente d'excellentes capacités de reconnaissance et de suivi lors d'événements d'occlusion (longs), tout en fournissant des positions raisonnables pour les points pendant les occlusions et en gérant une grande parallaxe de mouvement de caméra.

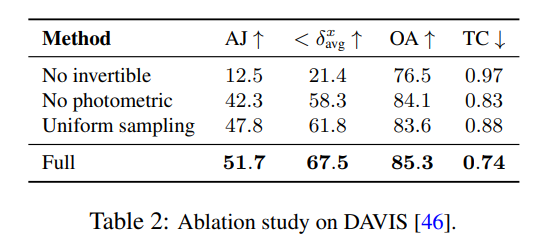
Expériences et analyses d'ablation
Les chercheurs ont utilisé des expériences d'ablation pour vérifier l'efficacité de leurs décisions de conception, et les résultats sont présentés dans le tableau 2.
Dans la figure 4, ils montrent des cartes de pseudo-profondeur générées par leur modèle pour démontrer le classement de profondeur appris.

Il est important de noter que ces chiffres ne correspondent pas à la profondeur physique, mais ils démontrent que la nouvelle méthode est capable de déterminer efficacement l'ordre relatif entre différentes surfaces en utilisant uniquement des signaux de flux photométriques et optiques, ce qui est utile pour le suivi dans occlusions Cruciales. D’autres expériences d’ablation et des résultats analytiques peuvent être trouvés dans le matériel supplémentaire.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



