


Évolution de l'architecture de la base de données
Au début, la plupart des projets utilisaient une base de données sur une seule machine. À mesure que le trafic du serveur devient de plus en plus important, il est confronté à davantage de problèmes. et plus de demandes. Nous avons séparé la lecture et l'écriture de la base de données, en utilisant plusieurs copies de la base de données esclave (esclave) pour être responsable de la lecture, et en utilisant la base de données principale (maître) pour être responsable de l'écriture. Le maître et l'esclave réalisent la synchronisation et la mise à jour des données. réplication maître-esclave pour maintenir la cohérence des données. La bibliothèque esclave peut être étendue horizontalement, donc davantage de demandes de lecture ne sont pas un problème
Mais lorsque le niveau d'utilisateur augmente et qu'il y a de plus en plus de demandes d'écriture, comment s'assurer que la charge de la base de données est suffisante ? L'ajout d'un maître ne peut pas résoudre le problème, car les données doivent être cohérentes et les opérations d'écriture nécessitent une synchronisation entre deux maîtres, ce qui équivaut à une duplication, et la conception de l'architecture est plus complexe
Dans ce cas, le partitionnement est nécessaire, stockez les bibliothèques et des tables sur différents serveurs MySQL, et chaque serveur peut équilibrer le nombre de demandes d'écriture
Une seule base de données est trop volumineuse : la capacité de traitement d'une seule base de données est limitée, et le serveur sur lequel elle se trouve En raison d'un espace disque insuffisant et de goulots d'étranglement d'E/S, une seule base de données doit être divisée en bases de données plus nombreuses et plus petites
Une seule table est trop grande : l'efficacité CURD est très faible, La quantité de données est trop volumineux, ce qui entraîne un fichier d'index trop volumineux et les E/S du disque mettent du temps à charger l'index, ce qui entraîne l'expiration du délai d'attente de la requête. Il ne suffit donc pas d'utiliser des index. Vous devez diviser une seule table en plusieurs tables avec des ensembles de données plus petits. Les algorithmes de fractionnement de table fournis par MyCat sont tous dans Rule.xml, qui peuvent être fractionnés selon différents algorithmes de fractionnement de table, tels que le fractionnement basé sur le temps, le hachage cohérent, l'utilisation directe de la clé primaire pour modulo le nombre de tables fractionnées, etc.
Stratégie de fractionnementSi une seule base de données est trop volumineuse, déterminez d'abord s'il y a trop de tables ou trop de données :
S'il y a trop de données en raison d'un trop grand nombre de tables, utilisez la division verticale, c'est-à-dire divisez-le en différentes bibliothèques selon l'entreprise
Si la quantité de données dans une seule table est trop importante, utilisez le fractionnement horizontal, c'est-à-dire divisez les données de la table en plusieurs tables selon une certaine règle (algorithme de fractionnement de table défini dans Rule.xml)
Le principe du partitionnement des bases de données et des tables doit être de considérer d'abord le fractionnement vertical, puis le fractionnement horizontal
3. Le fractionnement verticalLe partitionnement des sous-bases de données et la séparation en lecture-écriture peuvent être effectués. ensemble
server.xml
<user name="root"> <property name="password">123456</property> <property name="schemas">USERDB1,USERDB2</property> </user>
schema.xml
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 逻辑数据库 --> <schema name="USERDB1" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1" /> <!-- 两个逻辑库对应两个不同的数据节点 --> <schema name="USERDB2" checkSQLschema="false" sqlMaxLimit="100"dataNode="dn2" /> <!-- 存储节点 --> <dataNode name="dn1" dataHost="node1" database="mytest1" /> <!-- 两个数据节点对应两个不同的物理机器 --> <dataNode name="dn2" dataHost="node2" database="mytest2" /> <!-- USERDB1对应mytest1,USERDB2对应mytest2 --> <!-- 数据库主机 --> <dataHost name="node1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.131.129" url="192.168.131.129:3306" user="root" password="123456" /> </dataHost> <dataHost name="node2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.0.6" url="192.168.0.6:3306" user="root" password="123456" /> </dataHost> </mycat:schema>
Les deux bibliothèques logiques correspondent à deux nœuds de données différents, et les deux nœuds de données correspondent à deux nœuds de données différents. machines physiques
mytest1 et mytest2 sont divisés en différentes bibliothèques sur différentes machines, chacune contenant une partie de la table. Elles étaient à l'origine combinées sur une seule machine, mais maintenant elles sont divisées verticalement.Le client doit se connecter à différentes bibliothèques logiques. Différentes bibliothèques logiques sont utilisées en fonction des opérations commerciales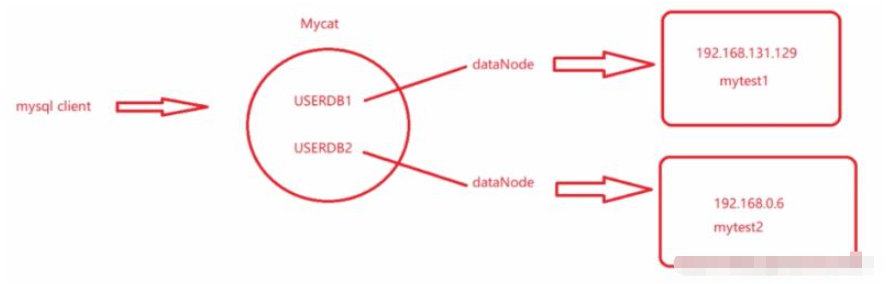
 2. Le partitionnement vertical de la table
2. Le partitionnement vertical de la table
Le partitionnement vertical de la table est basé sur les champs de colonnes. Il est généralement utilisé pour les grandes tables comportant des centaines de colonnes afin d'éviter les problèmes de « page croisée » provoqués par de grandes quantités de données lors des requêtes.
4. Sous-base de données et sous-table horizontales
Pour une seule table avec une énorme quantité de données (comme une table de commande), selon certaines règles (RANGE, module HASH, etc.), divisé en plusieurs tables. Non recommandé car les tables sont toujours dans la même base de données, il peut donc y avoir des goulots d'étranglement d'E/S lors de l'exécution d'opérations sur l'ensemble de la base de données
serveur. sur une machine. Cette table n'a pas besoin d'être divisée. La clé primaire de la table étudiant est id. Divisez-la en fonction de l'identifiant et placez-la sur dn1 et dn2. Au final, cette table sera divisée sur deux machines. le physique Ils sont séparés, mais logiquement ils ne font qu'un. À quelle table ajouter, requête sur deux machines et comment fusionner ces opérations sont toutes effectuées par mycatLa règle de fractionnement est modulo (mod - long), Le nombre de machines existantes sur le module ID pour chaque insertion (2)
De plus, l'algorithme de fractionnement suivant doit être configuré dans Rule.xml
Trouvez l'algorithme mod-long, car nous mappons la table logique étudiant sur deux hôtes séparément, donc le nombre de nœuds de données modifiés est de 2

2. Windows L'hôte
 Connectez-vous au port 8066 de mycat
Connectez-vous au port 8066 de mycat
 Utilisez MyCat pour insérer deux données dans la table utilisateur
Utilisez MyCat pour insérer deux données dans la table utilisateur
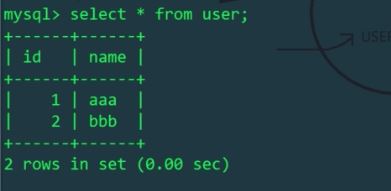
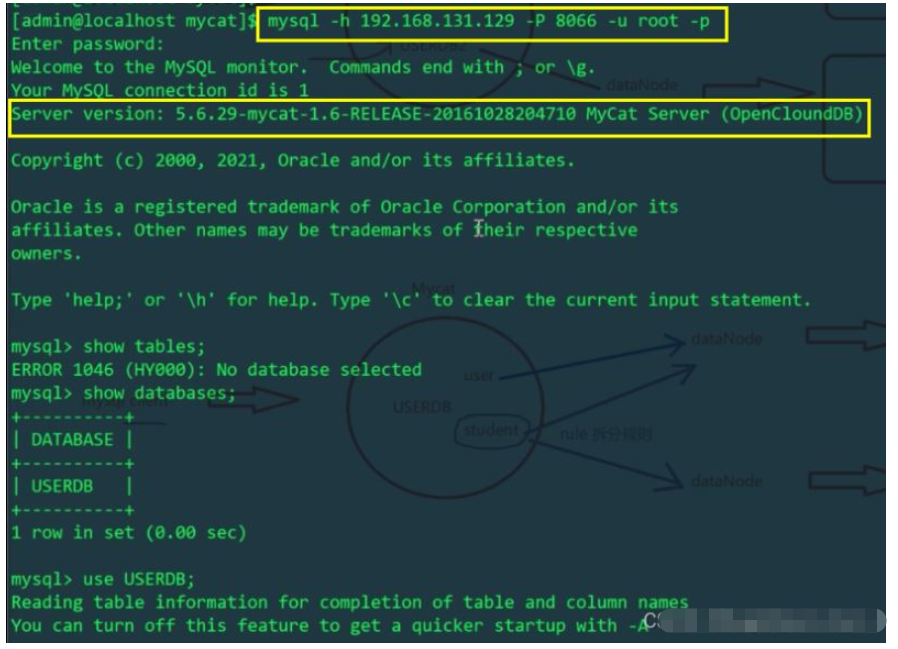 En raison du fichier de configuration schema.xml, l'utilisateur de la table logique se trouve uniquement dans la bibliothèque mytest1 de l'hôte Linux. Oui, l'utilisateur de table logique exploité par mycat affectera la table physique sur l'hôte Linux mais pas la table sur l'hôte Windows. Nous vérifions respectivement les tables utilisateur des hôtes Linux et Windows :
En raison du fichier de configuration schema.xml, l'utilisateur de la table logique se trouve uniquement dans la bibliothèque mytest1 de l'hôte Linux. Oui, l'utilisateur de table logique exploité par mycat affectera la table physique sur l'hôte Linux mais pas la table sur l'hôte Windows. Nous vérifions respectivement les tables utilisateur des hôtes Linux et Windows :

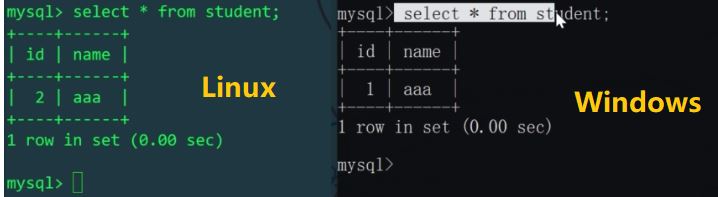
 Nous savons que dans le fichier de configuration schema.xml, la table logique étudiant correspond à deux machines Il y a deux tables dans les deux bibliothèques mytest1 et mytest2 sur l'hôte, donc les deux données insérées dans la table logique affecteront en réalité les deux tables physiques (utilisez
Nous savons que dans le fichier de configuration schema.xml, la table logique étudiant correspond à deux machines Il y a deux tables dans les deux bibliothèques mytest1 et mytest2 sur l'hôte, donc les deux données insérées dans la table logique affecteront en réalité les deux tables physiques (utilisez

id%机器数
.
Ça y est Cela équivaut à diviser la table des étudiants horizontalement. Lors d'une requête via MyCat, il vous suffit de saisir normalement. Nous configurons la table pour qu'elle soit divisée et placée sur ces deux nœuds de données. MyCat interrogera les deux bases de données en fonction. la configuration. Et effectuez la fusion des données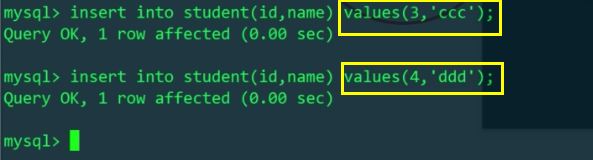
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



