


Les données de la base de données mysql sont stockées sur le disque sous forme de fichiers. Par défaut, elles sont placées sous /mysql/data (consultables via le datadir dans my.cnf). , l'un est frm stocke la structure de la table, l'un myd stocke les données de la table et l'autre myi stocke l'index de la table. Si la quantité de données dans une table est trop grande, alors myd et myi deviendront très volumineux et la recherche de données deviendra très lente. À ce stade, nous pouvons utiliser la fonction de partition de mysql pour correspondre physiquement à cette table. trois fichiers sont divisés en plusieurs petits blocs. De cette façon, lorsque nous recherchons une donnée, nous n'avons pas besoin de les rechercher tous. Il nous suffit de savoir dans quel bloc se trouvent les données, puis de rechercher dans celui-ci. bloc. Lorsqu'une table contient une grande quantité de données, il peut être nécessaire de répartir les données sur plusieurs disques pour empêcher qu'un seul disque puisse contenir toutes les données.
Le partitionnement de table est le processus de division d'une table dans une base de données en plusieurs parties plus petites et plus faciles à gérer en fonction de règles spécifiques. Logiquement, il n’existe qu’une seule table, mais la couche sous-jacente est composée de plusieurs partitions physiques.
Partitionnement de table : fait référence à la décomposition d'une table en plusieurs tables différentes selon certaines règles. Par exemple, les enregistrements de commandes utilisateur sont divisés en plusieurs tables en fonction du temps. La différence entre le partitionnement et le partitionnement de table est que, logiquement, le partitionnement ne concerne qu'une seule table, tandis que le partitionnement de table divise une table en plusieurs tables.
(1). Par rapport à une seule partition de disque ou de système de fichiers, plus de données peuvent être stockées.
Généralement, les données qui n'ont aucune valeur de conservation peuvent être facilement effacées en supprimant les partitions qui leur sont associées. Parfois, afin d'ajouter facilement de nouvelles données, vous pouvez créer une nouvelle partition pour stocker spécifiquement ces nouvelles données.
(3) Certaines requêtes peuvent être grandement optimisées, principalement du fait que les données qui satisfont à une instruction WHERE donnée ne peuvent être stockées que dans une ou plusieurs partitions, de sorte qu'il n'est pas nécessaire de rechercher d'autres partitions restantes lorsque recherche. Étant donné que le partitionnement peut être modifié après la création de la table partitionnée, vous pouvez réorganiser les données pour améliorer l'efficacité des requêtes couramment utilisées si vous ne l'avez pas fait lors de la première configuration du schéma de partitionnement.
Lorsque les requêtes impliquent des fonctions d'agrégation telles que SUM() et COUNT(), elles peuvent être facilement traitées en parallèle. Un exemple simple d'une telle requête est "SELECT salesperson_id, COUNT (orders) as order_total FROM sales GROUP BY salesperson_id ;". Une requête « parallèle » signifie que la requête peut être exécutée simultanément sur chaque partition et que le résultat final regroupe simplement les résultats de toutes les partitions.
(5). Obtenez un plus grand débit de requêtes en dispersant les requêtes de données sur plusieurs disques.
(1). Une table ne peut avoir qu'un maximum de 1024 partitions.
Dans MySQL 5.1, les expressions de partition ne peuvent être que des entiers ou des expressions pouvant renvoyer des entiers. La prise en charge du partitionnement d'expressions non entières est fournie dans MySQL 5.5.
Si des colonnes avec clé primaire ou index unique sont incluses dans le champ de partition, toutes les colonnes de clé primaire et les colonnes d'index unique doivent être incluses. Soit le champ de partition n'inclut pas les colonnes de clé primaire et d'index, soit il inclut toutes les colonnes de clé primaire et d'index.
(4). Les contraintes de clé étrangère ne peuvent pas être utilisées dans les tables partitionnées.
(5) Le partitionnement MySQL s'applique à toutes les données et index d'une table. Vous ne pouvez pas partitionner uniquement les données de la table mais pas l'index, vous ne pouvez pas partitionner uniquement l'index mais pas la table, et vous ne pouvez pas partitionner uniquement une partie des données. du tableau.
mysql> show variables like '%partition%'; +-------------------+-------+ | Variable_name | Value | +-------------------+-------+ | have_partitioning | YES | +-------------------+-------+ 1 row in set (0.00 sec)
have_partitioning est OUI, indiquant que le partitionnement est pris en charge.
(1), Partitionnement RANGE : allouez plusieurs lignes aux partitions en fonction des valeurs de colonnes appartenant à un intervalle continu donné.
(2) Partitionnement LISTE : Semblable au partitionnement par RANGE, la différence est que le partitionnement LISTE est sélectionné en fonction de la valeur de colonne correspondant à une certaine valeur dans un ensemble de valeurs discrètes.
(3), Partitionnement HASH : sélectionnez une partition basée sur la valeur de retour d'une expression définie par l'utilisateur, qui est calculée à l'aide des valeurs de colonne des lignes à insérer dans le tableau. Toute expression MySQL valide qui produit une valeur entière non négative peut être incluse dans cette fonction.
(4) Partitionnement KEY : similaire au partitionnement HASH, la différence est que le partitionnement KEY ne prend en charge que le calcul d'une ou plusieurs colonnes et que le serveur MySQL fournit sa propre fonction de hachage. Il doit y avoir une ou plusieurs colonnes contenant des valeurs entières.
Remarque : dans MySQL version 5.1, les partitions RANGE, LIST et HASH nécessitent que la clé de partition soit de type INT ou renvoie le type INT via une expression. Lors du partitionnement KEY, en plus des colonnes de type BLOB et TEXT, d'autres types de colonnes peuvent également être utilisés comme clés de partition.
Partition selon la plage La plage doit être continue mais ne pas se chevaucher. Utilisez les mots-clés PARTITION BY RANGE, VALUES LESS THAN. Si vous n'utilisez pas le mot-clé COLUMNS, les crochets RANGE doivent être un nom de champ entier ou une fonction qui renvoie un entier défini.
drop table if exists employees;
create table employees(
id int not null,
fname varchar(30),
lname varchar(30),
hired date not null default '1970-01-01',
separated date not null default '9999-12-31',
job_code int not null default 0,
store_id int not null default 0
)engine=myisam default charset=utf8
partition by range(store_id)(
partition p0 values less than (6),
partition p1 values less than (11),
partition p2 values less than (16),
partition p3 values less than (21)
);insert into employees (id,fname,lname,hired,store_id) values(1,'张三','张','2015-05-04',1); insert into employees (id,fname,lname,hired,store_id) values(2,'李四','李','2016-10-01',5); insert into employees (id,fname,lname,hired,store_id) values(3,'王五','王','2016-11-14',10); insert into employees (id,fname,lname,hired,store_id) values(4,'赵六','赵','2017-08-24',15); insert into employees (id,fname,lname,hired,store_id) values(5,'田七','田','2018-05-20',20);
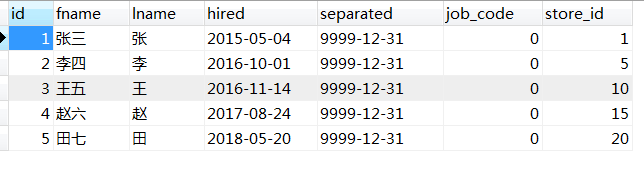
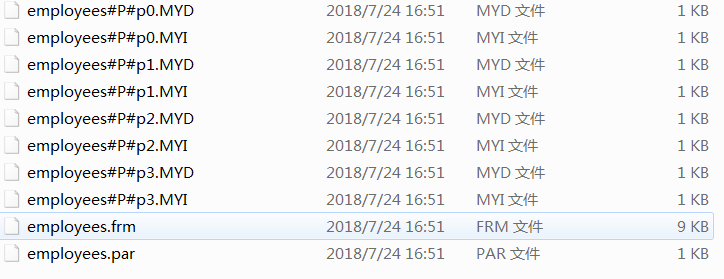
按照这种分区方案,在商店1到5工作的雇员相对应的所有行被保存在分区P0中,商店6到10的雇员保存在P1中,依次类推。注意,每个分区都是按顺序进行定义,从最低到最高。这是PARTITION BY RANGE 语法的要求。
对于包含数据(6,'亢八','亢','2018-06-24',13)的一个新行,可以很容易地确定它将插入到p2分区中。
insert into employees (id,fname,lname,hired,store_id) values(6,'亢八','亢','2018-06-24',13);
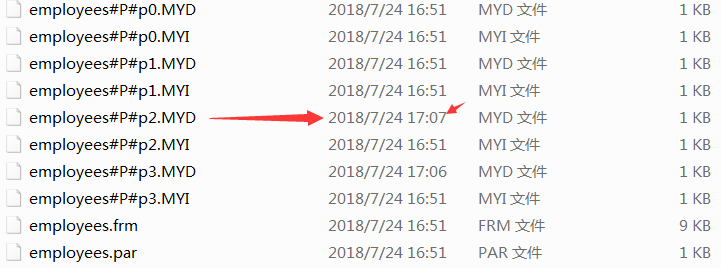
但是如果增加了一个编号为第21的商店(7,'周九','周','2018-07-24',21),将会发生什么呢?在这种方案下,由于没有规则把store_id大于20的商店包含在内,服务器将不知道把该行保存在何处,将会导致错误。
insert into employees (id,fname,lname,hired,store_id) values(7,'周九','周','2018-07-24',21); ERROR 1526 (HY000): Table has no partition for value 21
要避免这种错误,可以通过在CREATE TABLE语句中使用一个“catchall” VALUES LESS THAN子句,该子句提供给所有大于明确指定的最高值的值:
create table employees(
id int not null,
fname varchar(30),
lname varchar(30),
hired date not null default '1970-01-01',
separated date not null default '9999-12-31',
job_code int not null default 0,
store_id int not null default 0
)engine=myisam default charset=utf8
partition by range(store_id)(
partition p0 values less than (6),
partition p1 values less than (11),
partition p2 values less than (16),
partition p3 values less than (21),
partition p4 values less than MAXVALUE
);drop table if exists quarterly_report_status; create table quarterly_report_status( report_id int not null, report_status varchar(20) not null, report_updated timestamp not null default current_timestamp on update current_timestamp ) partition by range(unix_timestamp(report_updated))( partition p0 values less than (unix_timestamp('2008-01-01 00:00:00')), partition p1 values less than (unix_timestamp('2008-04-01 00:00:00')), partition p2 values less than (unix_timestamp('2008-07-01 00:00:00')), partition p3 values less than (unix_timestamp('2008-10-01 00:00:00')), partition p4 values less than (unix_timestamp('2009-01-01 00:00:00')), partition p5 values less than (unix_timestamp('2009-04-01 00:00:00')), partition p6 values less than (unix_timestamp('2009-07-01 00:00:00')), partition p7 values less than (unix_timestamp('2009-10-01 00:00:00')), partition p8 values less than (unix_timestamp('2010-01-01 00:00:00')), partition p9 values less than maxvalue );
添加COLUMNS关键字可定义非integer范围及多列范围,不过需要注意COLUMNS括号内只能是列名,不支持函数;多列范围时,多列范围必须呈递增趋势:
drop table if exists member; create table member( firstname varchar(25) not null, lastname varchar(25) not null, username varchar(16) not null, email varchar(35), joined date not null ) partition by range columns(joined)( partition p0 values less than ('1960-01-01'), partition p1 values less than ('1970-01-01'), partition p2 values less than ('1980-01-01'), partition p3 values less than ('1990-01-01'), partition p4 values less than maxvalue )
drop table if exists rc3; create table rc3( a int, b int ) partition by range columns(a,b)( partition p0 values less than (0,10), partition p1 values less than (10,20), partition p2 values less than (20,30), partition p3 values less than (30,40), partition p4 values less than (40,50), partition p5 values less than (maxvalue,maxvalue) )
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 )engine=myisam default charset=utf8 partition by range(year(separated))( partition p0 values less than (1991), partition p1 values less than (1996), partition p2 values less than (2001), partition p4 values less than MAXVALUE );
只需删除分区,就能清除“旧的”数据。如果你使用上面最近的那个例子给出的分区方案,你只需简单地使用”alter table staff drop partition p0;”来删除所有在1991年前就已经停止工作的雇员相对应的所有行。对于有大量行的表,这比运行一个如”delete from staff WHERE year(separated) <= 1990;”这样的一个DELETE查询要有效得多。
(2)、想要使用一个包含有日期或时间值,或包含有从一些其他级数开始增长的值的列。
(3)、经常运行直接依赖于用于分割表的列的查询。例如,当执行一个如”select count(*) from staff where year(separated) = 200 group by store_id;”这样的查询时,MySQL可以很迅速地确定只有分区p2需要扫描,这是因为余下的分区不可能包含有符合该WHERE子句的任何记录。
根据具体数值分区,每个分区数值不重叠,使用PARTITION BY LIST、VALUES IN关键字。在不使用COLUMNS关键字的情况下,与Range分区类似,List括号内必须是整数字段名或返回确定整数的函数。
类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
LIST分区通过使用“PARTITION BY LIST(expr)”来实现,其中“expr”是某列值或一个基于某个列值、并返回一个整数值的表达式,然后通过“VALUES IN (value_list)”的方式来定义每个分区,其中“value_list”是一个通过逗号分隔的整数列表。
假定有20个音像店,分布在4个有经销权的地区,如下表所示:
====================
地区 商店ID 号
北区 3, 5, 6, 9, 17
东区 1, 2, 10, 11, 19, 20
4, 12, 13, 14, 18是西区的编号
中心区 7, 8, 15, 16
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 ) partition by list(store_id)( partition pNorth values in (3,5,6,9,17), partition pEast values in (1,2,10,11,19,20), partition pWest values in (4,12,13,14,18), partition pCentral values in (7,8,15,16) );
这使得在表中增加或删除指定地区的雇员记录变得容易起来。例如,假定西区的所有音像店都卖给了其他公司。那么与在西区音像店工作雇员相关的所有记录(行)可以使用查询“ALTER TABLE staff DROP PARTITION pWest;”来进行删除,它与具有同样作用的DELETE(删除)“DELETE FROM staff WHERE store_id IN (4,12,13,14,18);”比起来,要有效得多。
如果试图插入列值(或分区表达式的返回值)不在分区值列表中的一行时,那么“INSERT”查询将失败并报错。
当插入多条数据出错时,如果表的引擎支持事务(Innodb),则不会插入任何数据;如果不支持事务,则出错前的数据会插入,后面的不会执行。
与Range分区相同,添加COLUMNS关键字可支持非整数和多列。
Hash分区主要用来确保数据在预先确定数目的分区中平均分布,Hash括号内只能是整数列或返回确定整数的函数,实际上就是使用返回的整数对分区数取模。
要使用HASH分区来分割一个表,要在CREATE TABLE 语句上添加一个“PARTITION BY HASH (expr)”子句,其中“expr”是一个返回一个整数的表达式。它可以仅仅是字段类型为MySQL整型的一列的名字。此外,你很可能需要在后面再添加一个“PARTITIONS num”子句,其中num是一个非负的整数,它表示表将要被分割成分区的数量。
如果没有包括一个PARTITIONS子句,那么分区的数量将默认为1
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 ) partition by hash(store_id) partitions 4;
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 ) partition by hash(year(hired)) partitions 4;
Hash分区也存在与传统Hash分表一样的问题,可扩展性差。MySQL也提供了一个类似于一致Hash的分区方法-线性Hash分区,只需要在定义分区时添加LINEAR关键字。
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 ) partition by linear hash(year(hired)) partitions 4;
线性哈希功能,它与常规哈希的区别在于,线性哈希功能使用的一个线性的2的幂(powers-of-two)运算法则,而常规哈希使用的是求哈希函数值的模数。
Key分区与Hash分区很相似,只是Hash函数不同,定义时把Hash关键字替换成Key即可,同样Key分区也有对应与线性Hash的线性Key分区方法。
drop table if exists staff; create table staff( id int not null, fname varchar(30), lname varchar(30), hired date not null default '1970-01-01', separated date not null default '9999-12-31', job_code int not null default 0, store_id int not null default 0 ) partition by key(store_id) partitions 4;
在KEY分区中使用关键字LINEAR和在HASH分区中使用具有同样的作用,分区的编号是通过2的幂(powers-of-two)算法得到,而不是通过模数算法。
另外,当表存在主键或唯一索引时可省略Key括号内的列名,Mysql将按照主键-唯一索引的顺序选择,当找不到唯一索引时报错。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié





















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



