


Le modèle de base pré-entraîné basé sur un apprentissage auto-supervisé sur un large éventail d'ensembles de données a démontré une excellente capacité à transférer des connaissances vers différentes tâches en aval. En conséquence, ces modèles sont également appliqués à des problèmes plus complexes tels que le raisonnement à long terme, le contrôle, la recherche et la planification, ou déployés dans des applications telles que le dialogue, la conduite autonome, les soins de santé et la robotique. À l'avenir, ils fourniront également des interfaces avec des entités et des agents externes. Par exemple, dans les applications de dialogue, les modèles de langage communiquent avec des personnes lors de plusieurs tours ; dans le domaine de la robotique, les modèles de contrôle de perception effectuent des actions dans des environnements réels.
Ces scénarios posent de nouveaux défis pour le modèle de base, notamment : 1) comment apprendre des commentaires d'entités externes (telles que les évaluations humaines de la qualité des conversations), 2) Comment s'adapter à des modalités inhabituelles (telles que les actions des robots) dans des ensembles de données linguistiques ou visuelles à grande échelle, 3) Comment raisonner et planifier le futur à long terme.
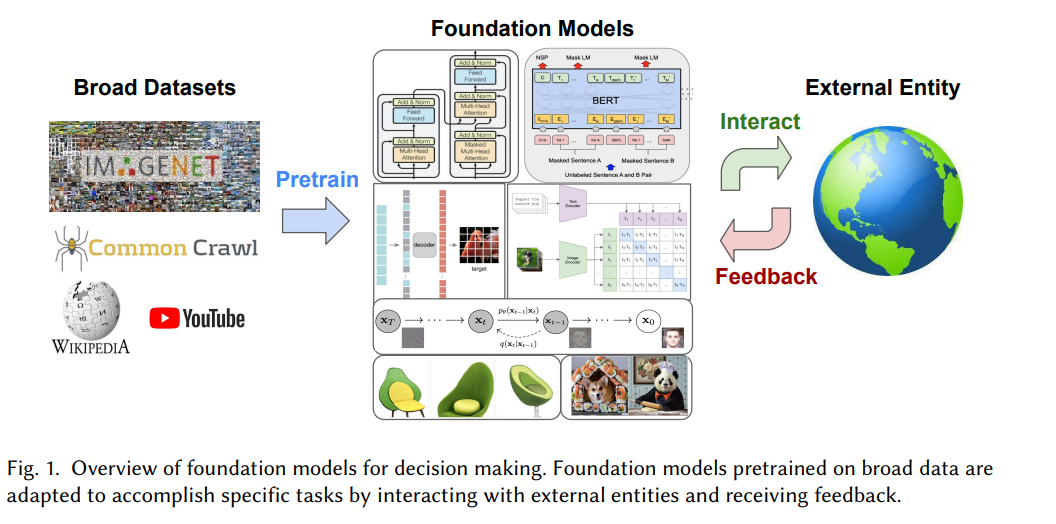
Ces questions ont toujours été au cœur de la prise de décision séquentielle dans le sens traditionnel, couvrant des domaines tels que l'apprentissage par renforcement, l'apprentissage par imitation, la planification, la recherche et le contrôle optimal. Contrairement au paradigme dans lequel les modèles de base sont pré-entraînés à l'aide de vastes ensembles de données contenant des milliards de jetons d'images et de texte, les travaux antérieurs sur la prise de décision séquentielle se sont principalement concentrés sur des paramètres spécifiques à une tâche ou sur un tableau blanc avec des connaissances préalables limitées.
Bien que le manque ou l'absence de connaissances préalables rende la prise de décision séquentielle difficile, la recherche sur la prise de décision séquentielle a dépassé la performance humaine sur de multiples tâches, comme jouer à des jeux de société, Jeux vidéo Atari et robots d'exploitation pour compléter la navigation et le fonctionnement, etc.
Cependant, étant donné que ces méthodes apprennent à résoudre la tâche à partir de zéro sans connaissances approfondies de la vision, du langage ou d'autres ensembles de données, elles souffrent souvent en termes de généralisation et d'efficacité des échantillons. Les performances sont médiocres, par exemple il faut 7 GPU fonctionnant pendant une journée pour résoudre un seul jeu Atari. Intuitivement, des ensembles de données étendus similaires à ceux utilisés par le modèle de base devraient également être utiles pour les modèles de prise de décision séquentielle. Par exemple, il existe d’innombrables articles et vidéos sur Internet expliquant comment jouer aux jeux Atari. De la même manière qu’une connaissance approfondie des propriétés des objets et des scènes est utile aux robots, la connaissance des désirs et des émotions humains peut améliorer les modèles conversationnels.
Bien que les recherches sur les modèles de base et la prise de décision séquentielle soient généralement disjointes en raison d'applications et de préoccupations différentes, il existe de plus en plus d'études qui se croisent. En termes de modèles de base, avec l’émergence de grands modèles de langage, les applications cibles sont passées de simples tâches sans tir ou en quelques tâches à des problèmes qui nécessitent désormais un raisonnement à long terme ou des interactions multiples. En revanche, dans le domaine de la prise de décision séquentielle, inspirés par le succès des modèles de vision et de langage à grande échelle, les chercheurs ont commencé à préparer des ensembles de données de plus en plus volumineux pour l’apprentissage d’agents multimodèles, multitâches et interactifs généraux.
Les frontières entre les deux domaines sont de plus en plus floues, et certains travaux récents ont étudié l'utilisation de modèles de base pré-entraînés (tels que CLIP et ViT) dans le domaine visuel les contextes amorcent la formation des agents interactifs, tandis que d'autres travaux ont étudié des modèles de base en tant qu'agents conversationnels optimisés grâce à l'apprentissage par renforcement et au feedback humain. Des travaux sont également en cours sur l'adaptation de grands modèles de langage pour interagir avec des outils externes tels que des moteurs de recherche, des calculatrices, des outils de traduction, des simulateurs MuJoCo et des interprètes de programmes.
Récemment, des chercheurs de l'équipe Google Brain, de l'UC Berkeley et du MIT ont écrit que la combinaison de modèles de base et de recherche interactive sur la prise de décision serait mutuellement bénéfique. D'une part, l'application du modèle sous-jacent à des tâches impliquant des entités externes peut bénéficier d'un retour d'information interactif et d'une planification à long terme. La prise de décision séquentielle, en revanche, peut exploiter la connaissance mondiale du modèle sous-jacent pour résoudre les tâches plus rapidement et mieux généraliser.

Adresse papier : https://arxiv.org /pdf/2303.04129v1.pdf
Pour promouvoir des recherches plus poussées à l'intersection de ces deux domaines, les chercheurs ont limité l'espace problématique du modèle de base . Il fournit également des outils techniques pour comprendre la recherche actuelle, passe en revue les défis actuels et les questions restées sans réponse, et prédit des solutions potentielles et des approches prometteuses pour relever ces défis.
Le document est principalement divisé en 5 chapitres principaux suivants.
Le chapitre 2 passe en revue le contexte pertinent de la prise de décision séquentielle et fournit quelques exemples de scénarios dans lesquels les modèles sous-jacents et la prise de décision sont mieux considérés ensemble. Vient ensuite une description de la manière dont les différentes composantes d'un système de prise de décision sont construites autour du modèle sous-jacent.

Le chapitre 3 explore comment les modèles fondateurs servent de modèles génératifs de comportement (tels que la découverte de compétences) et de modèles génératifs de l'environnement (tels que la conduite d'un raisonnement basé sur des modèles).
Le chapitre 4 explore comment les modèles de base servent d'apprenants de représentation pour les dynamiques d'état, d'action, de récompense et de transfert (par exemple, modèles de langage de vision plug-and-play, apprentissage de représentation basé sur un modèle).

Le chapitre 5 explore comment les modèles basés sur le langage servent d'agents et d'environnements interactifs, permettant d'envisager de nouveaux problèmes et applications dans un cadre de prise de décision séquentiel (raisonnement de modèle de langage, dialogue, utilisation d'outils).

Dans le dernier chapitre, le chercheur décrit les problèmes et les défis non résolus et propose des solutions potentielles (comme comment utiliser un large éventail de données, comment construire l'environnement et quels modèles de base et séquentiels les aspects décisionnels peuvent être améliorés).

Veuillez vous référer au document original pour plus de détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Utilisation des éléments en python
Utilisation des éléments en python L'installation de l'imprimante a échoué
L'installation de l'imprimante a échoué Quel logiciel est le podcasting ?
Quel logiciel est le podcasting ? La signification du volume d'affichage des titres d'aujourd'hui
La signification du volume d'affichage des titres d'aujourd'hui Comment utiliser le logiciel de programmation jsp
Comment utiliser le logiciel de programmation jsp Comment configurer l'actualisation automatique d'une page Web
Comment configurer l'actualisation automatique d'une page Web La carte réseau sans fil ne peut pas se connecter
La carte réseau sans fil ne peut pas se connecter méthode d'appel du service Web
méthode d'appel du service Web




















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



