


Si un ensemble ne contient que quelques éléments entiers, Redis utilisera l'ensemble d'entiers intset. Regardez d'abord la structure des données d'intset :
typedef struct intset { // 编码方式 uint32_t encoding; // 集合包含的元素数量 uint32_t length; // 保存元素的数组 int8_t contents[]; } intset;
En fait, la structure de données d'intset est relativement facile à comprendre. Un élément de stockage de données, la longueur stocke le nombre d'éléments, qui correspond à la taille du contenu, et le codage est la méthode de codage utilisée pour stocker les données.
Nous pouvons savoir grâce au code que le type d'encodage comprend :
#define INTSET_ENC_INT16 (sizeof(int16_t)) #define INTSET_ENC_INT32 (sizeof(int32_t)) #define INTSET_ENC_INT64 (sizeof(int64_t))
En fait, nous pouvons le voir. Le type d'encodage Redis fait référence à la taille des données. En tant que base de données en mémoire, cette conception est adoptée pour économiser de la mémoire.
Comme il existe trois structures de données de petite à grande, utilisez autant que possible de petites structures de données pour économiser de la mémoire lors de l'insertion de données. Si les données insérées sont plus grandes que la structure de données d'origine, l'expansion sera déclenchée.
Il y a trois étapes pour l'expansion :
Selon le type de nouveaux éléments, modifier le type de données de l'ensemble du tableau et réaffecter l'espace
Remplacer les données d'origine par le nouveau type de données et remplacer it Il doit être à la position et conserver l'ordre
avant d'insérer de nouveaux éléments
La collection d'entiers ne prend pas en charge les opérations de rétrogradation. Une fois mise à niveau, elle ne peut pas être rétrogradée.
La liste de sauts est un type de liste chaînée, une structure de données qui utilise l'espace pour échanger du temps. La liste de sauts prend en charge la complexité O(logN) en moyenne et la complexité O(N) au pire.
La liste de sauts est composée d'un zskiplist et de plusieurs zskiplistNode. Jetons d'abord un coup d'œil à leur structure :
/* ZSETs use a specialized version of Skiplists *//* * 跳跃表节点 */ typedef struct zskiplistNode { // 成员对象 robj *obj; // 分值 double score; // 后退指针 struct zskiplistNode *backward; // 层 struct zskiplistLevel { // 前进指针 struct zskiplistNode *forward; // 跨度 unsigned int span; } level[]; } zskiplistNode; /* * 跳跃表 */ typedef struct zskiplist { // 表头节点和表尾节点 struct zskiplistNode *header, *tail; // 表中节点的数量 unsigned long length; // 表中层数最大的节点的层数 int level; } zskiplist;
Donc, sur la base de ce code, nous pouvons dessiner le diagramme de structure suivant :
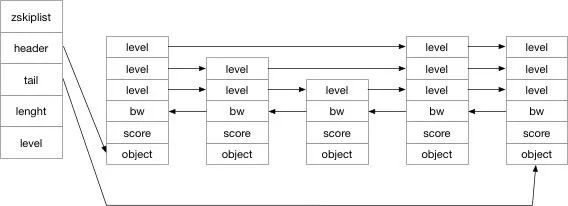
En fait, la liste de sauts est une structure de données qui utilise l'espace pour échanger du temps, en utilisant le niveau comme l'index de la liste chaînée.
Quelqu'un a déjà demandé à l'auteur de Redis pourquoi il utilise des tables de sauts au lieu d'arbres pour créer des index ? La réponse de l'auteur est :
Économisez la mémoire.
Lors de l'utilisation de ZRANGE ou ZREVRANGE, cela implique un scénario typique d'opération de liste chaînée. Les performances de complexité temporelle sont similaires à celles des arbres équilibrés.
Le point le plus important est que la mise en œuvre de la table de sauts est très simple et peut atteindre le niveau O(logN).
Liste chaînée compressée L'auteur de Redis la présente comme une liste doublement chaînée conçue pour économiser autant de mémoire que possible.
La structure des données donnée dans les commentaires dans le code d'une liste de compression est la suivante :
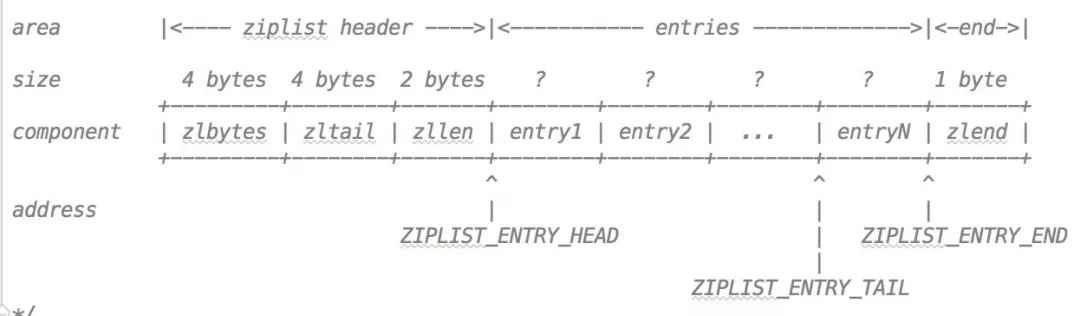
zlbytesreprésente le nombre d'octets mémoire utilisés par l'ensemble de la liste de compressionzlbytes表示的是整个压缩列表使用的内存字节数
zltail指定了压缩列表的尾节点的偏移量
zllen是压缩列表 entry 的数量
entry就是 ziplist 的节点
zlend标记压缩列表的末端
这个列表中还有单个指针:
ZIPLIST_ENTRY_HEAD列表开始节点的头偏移量
ZIPLIST_ENTRY_TAIL列表结束节点的头偏移量
ZIPLIST_ENTRY_END列表的尾节点结束的偏移量
再看看一个 entry 的结构:
/* * 保存 ziplist 节点信息的结构 */ typedef struct zlentry { // prevrawlen :前置节点的长度 // prevrawlensize :编码 prevrawlen 所需的字节大小 unsigned int prevrawlensize, prevrawlen; // len :当前节点值的长度 // lensize :编码 len 所需的字节大小 unsigned int lensize, len; // 当前节点 header 的大小 // 等于 prevrawlensize + lensize unsigned int headersize; // 当前节点值所使用的编码类型 unsigned char encoding; // 指向当前节点的指针 unsigned char *p; } zlentry;
依次解释一下这几个参数。
prevrawlen前置节点的长度,这里多了一个 size,其实是记录了 prevrawlen 的尺寸。Redis 为了节约内存并不是直接使用默认的 int 的长度,而是逐渐升级的。
同理len记录的是当前节点的长度,lensize记录的是 len 的长度。headersize就是前文提到的两个 size 之和。encoding就是这个节点的数据类型。这里注意一下 encoding 的类型只包括整数和字符串。p
zltailSpécifie le décalage du nœud de queue de la liste compressée
zllenest le nombre d'entrées dans la liste compressée
entryest le nœud du ziplist
zlendcode> Marque la fin de la liste compressée Il y a aussi un seul pointeur dans cette liste :
ZIPLIST_ENTRY_HEADLe décalage de tête du nœud de départ du list
ZIPLIST_ENTRY_TAILLa tête du nœud final de la liste Offset
ZIPLIST_ENTRY_ENDLe décalage de la fin du nœud final de la listeRegardez la structure de une nouvelle entrée : rrreeeExpliquez tour à tour ces paramètres.
prevrawlenLa longueur du nœud précédent. Il y a ici une taille supplémentaire, qui enregistre en fait la taille du prevrawlen. Afin d'économiser de la mémoire, Redis n'utilise pas directement la longueur int par défaut, mais la met progressivement à niveau.
lenenregistre la longueur du nœud actuel et
lensizeenregistre la longueur de len.
headersizeest la somme des deux tailles mentionnées ci-dessus.
encodingest le type de données de ce nœud. Notez ici que les types de codage incluent uniquement des entiers et des chaînes.
pLe pointeur du nœud, pas besoin de trop expliquer. Une chose à noter est que chaque nœud enregistre la longueur du nœud précédent. Si un nœud est mis à jour ou supprimé, les données après ce nœud doivent également être modifiées. Le pire des cas est que si chaque nœud est à zéro. Le point limite qui doit être étendu amènera les nœuds après ce nœud à modifier le paramètre de taille, déclenchant une réaction en chaîne. À l’heure actuelle, la pire complexité temporelle de compression de la liste chaînée est O(n^2). Cependant, tous les nœuds sont à des valeurs critiques, on peut donc dire que la probabilité est relativement faible.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Logiciel de base de données couramment utilisé
Logiciel de base de données couramment utilisé Que sont les bases de données en mémoire ?
Que sont les bases de données en mémoire ? Lequel a une vitesse de lecture plus rapide, mongodb ou redis ?
Lequel a une vitesse de lecture plus rapide, mongodb ou redis ? Comment utiliser Redis comme serveur de cache
Comment utiliser Redis comme serveur de cache Comment Redis résout la cohérence des données
Comment Redis résout la cohérence des données Comment MySQL et Redis assurent-ils la cohérence des doubles écritures ?
Comment MySQL et Redis assurent-ils la cohérence des doubles écritures ? Quelles données le cache Redis stocke-t-il généralement ?
Quelles données le cache Redis stocke-t-il généralement ? Quels sont les 8 types de données de Redis
Quels sont les 8 types de données de Redis




















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



