


读心术可以说是人类最想要的超能力之一,同时也必定是人们最不希望别人有的一种超能力。只需在搜索引擎中输入「读心术」这个关键词,你就能找到大量相关书籍、视频和教程,足可见人们对这一能力的痴迷。但抛开那些心理学、行为学或神秘主义的内容不谈,单从技术角度看,人类的大脑信号是存在模式的,也因此读心术(解析大脑信号的模式)是可能实现的。
现如今,随着 AI 技术的发展,其分析模式的能力也越发精进,读心术正在变成现实。
前些天,得克萨斯大学奥斯汀分校发表于 Nature Neuroscience 一篇论文引起了热议,其可以通过非侵入式地读取大脑信号而重建出语义相符的连续语句 —— 不出意外,该模型同样使用了当前大受追捧的 GPT 语言模型。但我们先暂时按下这项最新的成果不表,看看稍早时间其它一些有关 AI 读心术的研究成果,以大概理解该课题的当前研究图景。
宽泛地说,读心术可分为两大类:直接读心术和间接读心术。
间接读心术是指通过间接的特征来揣度一个人的想法和情绪。这些特征包括人脸表情、身体姿态、体温、心率、呼吸节律、说话语速和语气等。近些年基于大数据的深度学习技术已经能让 AI 相当准确地通过人脸表情识别情绪,比如轻量级的开源人脸识别软件库 Deepface 能在年龄、性别、情绪和种族多项特征上整体达到 97.53% 的测试集准确度。但基于上述特征的情绪分析技术通常并不会被视为读心术,毕竟人类自身也或多或少能通过他人的表情等特征猜到其情绪,因此本文关注的读心术仅限于直接读心术。

使用 Deepfake 库得到人脸属性分析结果
直接读心术是指直接将大脑信号「翻译」成他人能理解的形式,比如文本、语音和图像。目前而言,研究者关注的大脑信号主要有三种:侵入式脑机接口、脑波(brain wave)和神经成像(neuroimaging)。
侵入式的脑机接口可以说赛博朋克作品的标配,你能在《赛博朋克 2077》等许多电影或游戏中看到它。其基本思路就是在大脑或神经系统中或附近读取神经细胞之间传递的电信号。相较于非侵入式的方法,侵入式读取的大脑信号通常准确度更高,噪声也更低。
2021 年,在论文《Neuroprosthesis for Decoding Speech in a Paralyzed Person with Anarthria》中,来自加利福尼亚大学旧金山分校的研究者提出使用 AI 帮助有语音障碍的残障人士交流。在该研究中,受试者是一位发音不清且独臂的残障人士。值得注意的是,他们在实验中使用了一种神经植入物来获取信号,该植入物组合使用了高密度皮层脑电图电极阵列和一个经过皮肤的连接器。这种侵入式的方法自然具备更高的准确度 —— 能达到最高 98% 的准确度和 75% 的中位数解码率,该模型的解码速度可达到最高每分钟 18 个词。除此之外,语言模型的应用还极大地提升了解码结果的意义表达,不再仅仅是简单的字符串堆积。
之后,该团队在 2022 年的 Nature Neuroscience 论文《Generalizable spelling using a speech neuroprosthesis in an individual with severe limb and vocal paralysis》中进一步改进了他们的系统,整合了新兴的语言模型 GPT,使性能得到了进一步提升。
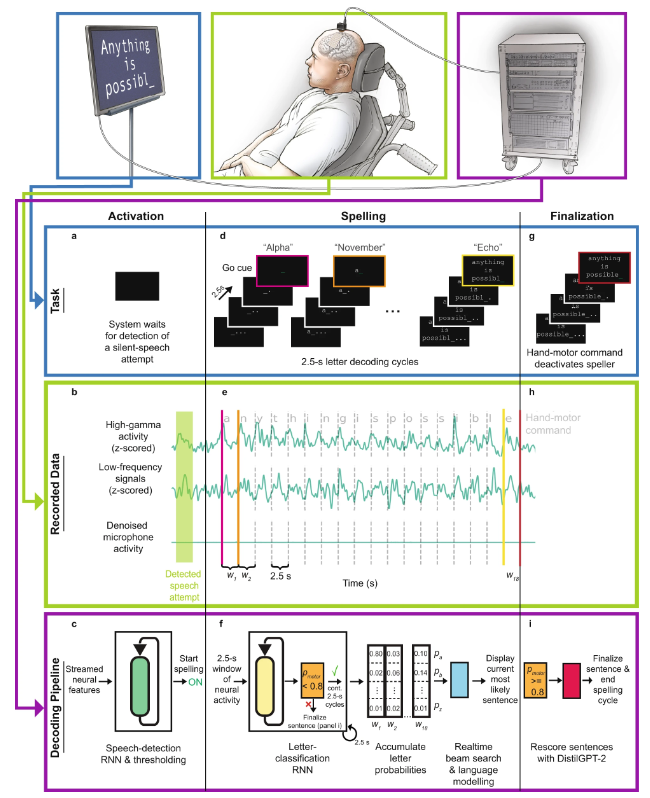
直接语音脑机接口工作流程示意图
具体来说,其工作流程为:
另一个植入式脑-机界面的研究声称成功实现了高效的手写文字识别和脑电信号转化为文本的功能。在 Nature 论文《High-performance brain-to-text communication via handwriting》,斯坦福大学的研究者成功让脊椎损伤的瘫痪人士能以每分钟 90 字符的速度打字,并且在线原始准确度达到了 94.1%,使用了语言模型的离线准确度更是超过 99%!
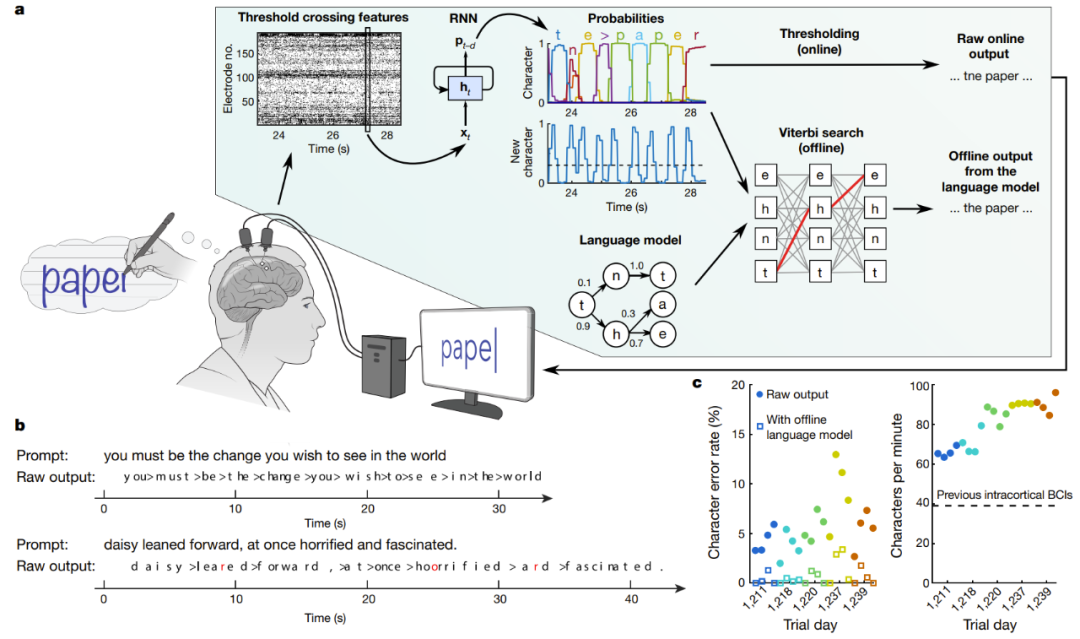
实时解码受试者尝试手写的大脑信号
图中 a 是解码算法的示意图。首先,每个电极上的神经活动被暂时合并及平滑化。然后,使用 RNN 将神经群体时间序列转换成概率时间序列,其描述了每个字符的可能性和任何新字符开始的概率。该 RNN 有 1 秒的输出延迟(d),让其在确定字符的身份之前有时间完整地观察每个字符。最后,设定字符概率的阈值,为实时使用得到「原始在线输出」(当新字符的概率在时间 t 超过某个阈值时,就在时间 t+0.3 秒给出最有可能的字符并将其展示在屏幕上)。在离线的回顾性分析中,研究者将字符概率与一个具有大词汇库的语言模型组合到一起,用以解码参与者最有可能写下的文本。
基于近几十年脑科学的研究成果,我们知道大脑中神经细胞传递信号过程中会有微小电流,这就会产生细微的电磁波动。当大量神经细胞同时工作时,可采用非侵入式的精密仪器捕获到这些电磁波动。1875 年,科学家首次在动物身上观察到了一种流动的电场现象,即脑波。1925 年,Hans Berger 发明了脑电图(EEG),并首次记录到了人类大脑的电活动现象。此后的近百年里,EEG 技术不断改进,其精度和实时性能都已经达到了相当高的程度并已得到了商业应用,现在你甚至能买到便携式的脑波检测分析设备。
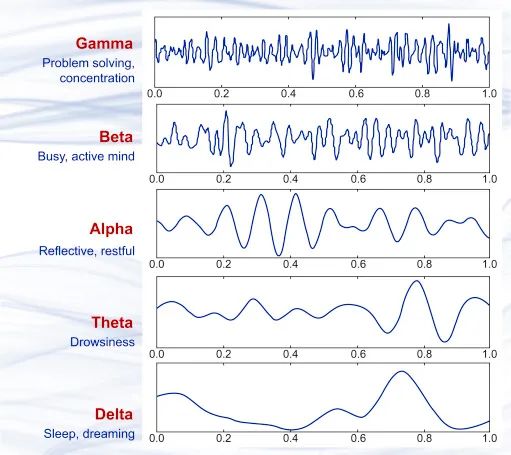
几种不同的脑波波形样本,从上到下依次为 γ 波(35Hz 以上)、β 波(12-35 Hz)、α 波 (8-12 Hz)、θ 波 (4-8 Hz)、δ 波(0.5-4 Hz),它们分别大致于不同的大脑状态。
通过脑波来分析人的情绪和想法方面,最常见的方法是分析 P300 波,即受试者的大脑在看到刺激物后大约 300 毫秒时产生的脑波。解析脑波的研究在脑波被发现以后就一直没有中断,比如 2001 年,该领域颇具争议的研究者 Lawrence Farwell 提出了一种算法,可以通过评估脑波响应来检测受试者是否经历过某个事件,并且即便受试者试图隐瞒也无济于事。也就是说,这是一种基于脑波的测谎仪。
由于脑波本身是一种具备模式的信号,因此使用神经网络来分析脑波也就成了自然而然的事情。下面我们将通过近些年的一些研究介绍科学们正通过什么方法来将脑波信号翻译成语音、文本和图像。
2019 年,俄罗斯一个研究团队提出了一个视觉脑机接口(BCI)系统,可基于脑波来重建图像。其研究思路很直接,就是从脑电波信号提取特征,然后提取特征向量,再进行映射,找到特征在隐藏空间中的位置,最后解码和重建出图像。其中,图像解码器是用了一个图像到图像卷积自动编码器模型的一部分,包含 1 个全连接输入层,之后是 5 个去卷积模块,每个模块都由 1 个去卷积层和 ReLU 激活组成,而最后一个模块的激活是双曲正切激活层。
该模型另一个重要组件是 EEG 特征映射器,其功能是将数据从 EEG 特征域转译到图像解码器的隐藏空间域。该团队在模型中运用了LSTM作为循环单元,并且采用注意力机制进行进一步细化。其损失函数是最小化 EEG 和图像的特征表征之间的均方误差。详情参阅他们的论文《Natural image reconstruction from brain waves: a novel visual BCI system with native feedback》。
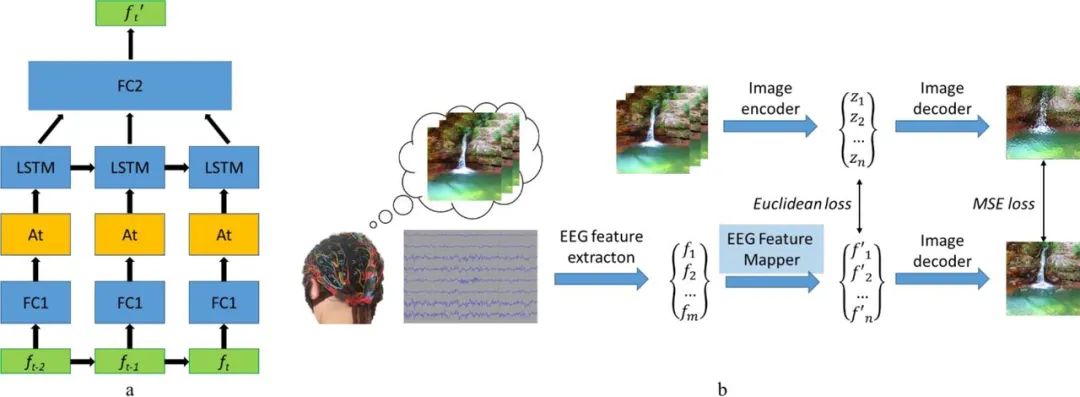
EEG 特征映射器的模型结构 (a) 和训练例程 (b)
下面是一些示例结果,可以看出重建图像与原始图像之间存在显著关联。

受试者看到的原始图像(每对图左)以及根据受试者脑波重建的图像(每对图右)
2022 年,Meta AI 团队在论文《Decoding speech from non-invasive brain recordings》提出了一种可从脑电图(EEG)或脑磁图(MEG)信号解码出语音信号的神经网络架构。
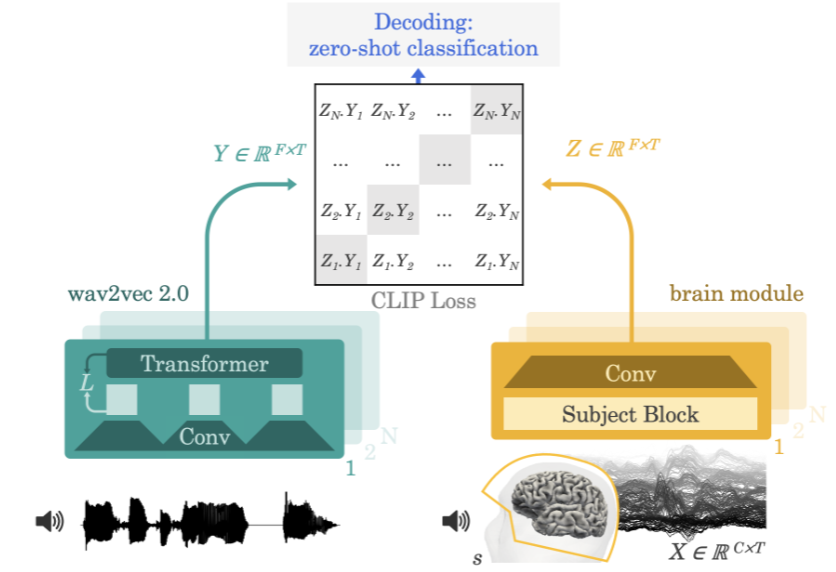
Meta AI 团队的方法示意图
该团队采用的方法是让实验参与者一边听故事或句子一边记录其大脑活动的脑电图或脑磁图。为此,该模型首先会通过一个预训练自监督模型(wav2vec 2.0)提取 3 秒语音信号(Y)的深度上下文表征,同时还会学习相应对齐的 3 秒窗口(X)中的大脑活动的表征(Z)。表征 Z 是由一个深度卷积网络给出的。在评估时,研究者向模型输入剩下的句子,并根据每个大脑表征计算出每段 3 秒的语言片段。由此,这样的解码过程可以做到 zero-shot,从而让模型可以预测出训练集不曾有的音频片段。
科学家还能使用一种名为功能性磁共振成像(fMRI)的技术来了解大脑的活动情况。这项技术诞生于 1990 年代初期,其工作机制是通过磁共振成像观察大脑中的血液流动来检测大脑活动。该技术能揭示出大脑中特定功能区是否活跃。
当我们说某个大脑区域「更活跃」时,我们指的是什么呢?fMRI 又是如何检测这种活动的?
当一个大脑区域中的神经元开始发出比之前更多的电信号时,我们就说这个大脑区域更活跃了。举个例子,如果你在抬腿时某个特定的大脑区域变得更加活跃,那么就可以认为这片大脑区域负责控制抬腿动作。
fMRI 是通过检测血液中的含氧水平来检测这种电活动。这被称为血氧水平依赖(BOLD)反应。其工作方式为:当神经元更加活跃时,就会需要红细胞提供更多氧。为此,周围的血管就会变宽以便让更多血液流过。所以,当神经元更加活跃时,氧浓度就会上升。相比于脱氧血液,含氧血液产生的场干扰更少,这让神经元的信号(实际上就是水中的氢)能持续更长时间。所以当信号留存时间更长时,fMRI 就知道该区域有更多氧,也就说明这里更加活跃。用颜色编码这种活动之后,就能得到 fMRI 影像。
接下来我们就看看前文提到的使用 GPT 重建出语义相符的连续语句的研究《Semantic reconstruction of continuous language from non-invasive brain recordings》。他们提出了一种非侵入式的解码器,可以根据 fMRI 记录中语义含义的大脑皮层表征而重建出连续的自然语言。当出现新的大脑记录时,该解码器能生成可理解的词序列,其能复现受试者听到的语音、想象的语音甚至无声视频中的含义,这表明单个语言解码器可以应用于一系列不同的语义任务。该语言解码器的工作流程如下:
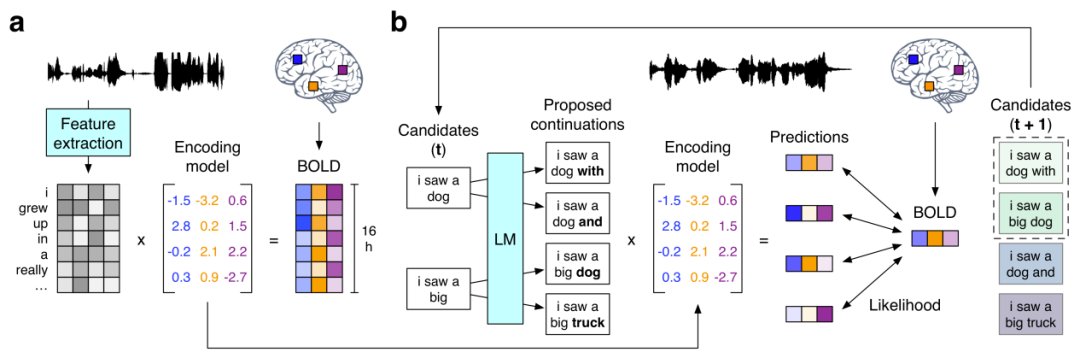
(a) 当三位受试者听 16 小时的叙事故事时记录到的 BOLD fMRI 反应。系统为每位受试者都估计了一个编码模型,以预测作为刺激物的词的语义特征所引发的大脑反应。(b) 为了基于全新的大脑记录重建语言,解码器维持着一个候选词序列集合。当检测到新的词时,会有一个语言模型为每个序列提议连续性,然后会用该编码模型评估每种连续条件下所记录大脑反应的可能性。最后保留最有可能的连续序列。
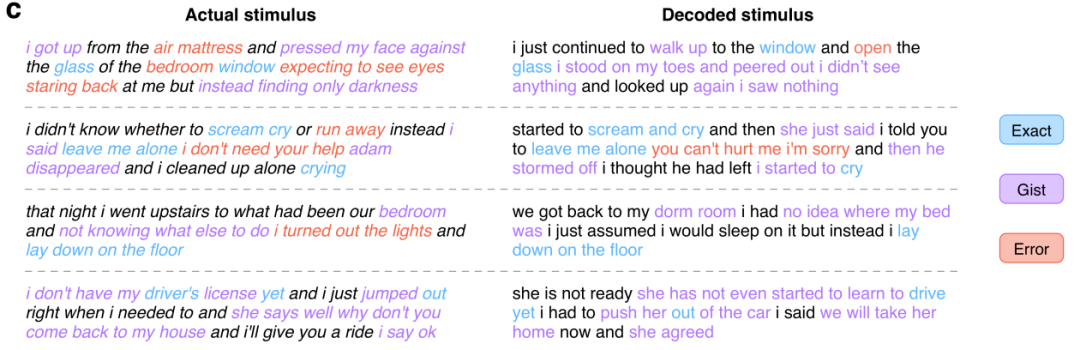
在这其中,语言模型使用的正是现处于 AI 领域研究核心的 GPT 模型。研究者在一个大型语料库上对所用 GPT 进行了微调,该语料库包含超过 2 亿词 Reddit 评论以及来自 The Moth Radio Hour 和 Modern Love 的 240 个自传故事。模型训练了 50 epoch,最大上下文长度为 100。下面展示了一些实验结果:
最后我们再来看看这一篇 CVPR 2023 论文《Seeing Beyond the Brain: Conditional Diffusion Model with Sparse Masked Modeling for Vision Decoding》。来自新加坡国立大学、香港中文大学和斯坦福大学的研究者宣称他们提出的 MinD-Vis 模型首次实现了将基于 fMRI 的大脑活动信号解码成图像的成就,并且重建出的图像不仅细节丰富而且还包含准确的语义和图像特征(纹理和形状等)。
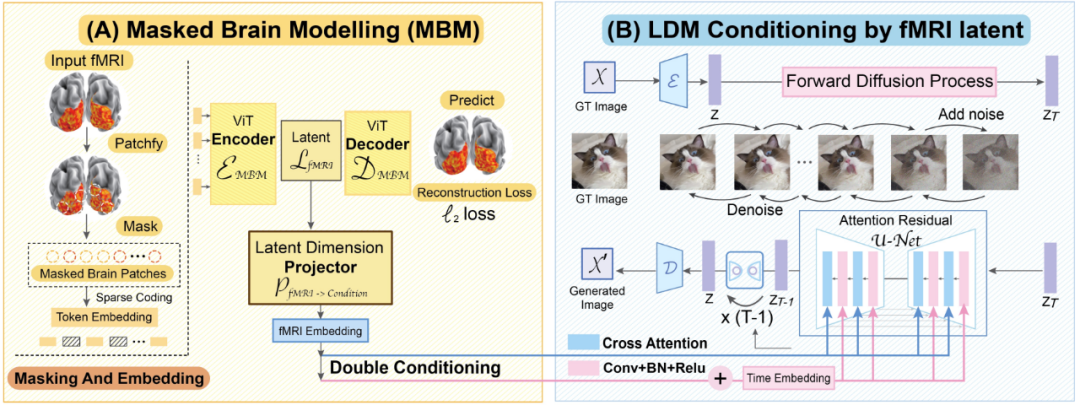
MinD-Vis 工作流程示意图
我们来看看 MinD-Vis 的两个工作阶段。如图所示,在 A 阶段,使用 SC-MBM(稀疏编码的掩码大脑建模)在 fMRI 上进行预训练。然后为 fMRI 随机加掩码,再将它们 token 化成大型嵌入。研究者训练了一个自动编码器来恢复被掩盖的图块。在 B 阶段,通过双条件(double conditioning)与隐含扩散模型(LDM)整合。使用一个隐含维度投射算法,通过两条路径将 fMRI 隐含空间投射到 LDM 条件空间。其中一条路径是直接连接 LDM 中的交叉注意力头。另一条路径是将 fMRI 隐含量加到时间嵌入中。
从论文给出的实验结果看,这个模型的读心能力确实非常不错:

其中左图是受试者看到的原始图片,红框标记了 MinD-Vis 的重建结果,而后面三列是其它方法的结果。
随着数据量的增长和算法的改进,人工智能正在越来越深刻地理解我们这个世界,而我们人类作为这个世界的一部分自然也是被理解的对象 —— 通过发掘人类大脑的活动模式,机器正在获得从底层理解人类所思所想的能力。也许未来某一天,AI 能够成为真正的读心大师,甚至可能还将具备高保真地捕捉人类梦境的能力!
上文只是简单介绍了 AI 在直接读心方面的一些近期研究成果,而实际上已经有一些公司开始致力于相关技术的商业化,比如以 Neuralink 和 Blackrock Neurotech 为代表的脑机接口和神经技术公司,它们未来的潜在产品将具有激动人心的应用前景,比如帮助无法表达的残障人士重建与世界的联系、远程操控在深海和太空等危险区域作业的机器。同时,这些技术的发展也让许多人看到了破译人类意识之谜的希望。
当然,这类技术也引发了不少人关于隐私、安全和道德伦理的担忧,毕竟我们已经在许多电影或小说中看到过这类技术被用于邪恶目的了。现如今,这类技术的进一步发展已经不可避免,因此如何确保这些技术与人类的利益保持一致就成了需要所有相关人士和政策制定者思考和讨论的重要问题。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ?
Quelles compétences sont nécessaires pour travailler dans l'industrie PHP ? Quels sont les paramètres de configuration du serveur vidéo ?
Quels sont les paramètres de configuration du serveur vidéo ? Comment afficher les processus sous Linux
Comment afficher les processus sous Linux Que signifie le concept de métaverse ?
Que signifie le concept de métaverse ? A quoi sert principalement javascript ?
A quoi sert principalement javascript ? Comment utiliser la fonction fréquence
Comment utiliser la fonction fréquence Introduction aux types de zones de texte HTML
Introduction aux types de zones de texte HTML Paiement sans mot de passe Taobao
Paiement sans mot de passe Taobao




















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



