

 Java
javaDidacticiel
Comment utiliser Quartz pour implémenter des tâches planifiées en Java ?
Java
javaDidacticiel
Comment utiliser Quartz pour implémenter des tâches planifiées en Java ?
Comment utiliser Quartz pour implémenter des tâches planifiées en Java ?

Scheduler créera une nouvelle instance de Job basée sur JobDetail à chaque exécution, afin d'éviter le problème d'accès simultané (l'instance de jobDetail est également nouvelle)
Les tâches planifiées Quzrtz sont exécutées simultanément par défaut et n'attendront pas l'exécution de la tâche précédente. Terminée, elle sera exécutée dès que l'intervalle sera écoulé. Si la tâche planifiée est exécutée trop longtemps, elle occupera des ressources pendant une longue période et entraînera le blocage d'autres tâches
@DisallowConcurrentExecution : Sur la classe de travail, l'exécution simultanée de la même définition de travail (définie par JobDetail) est interdite.
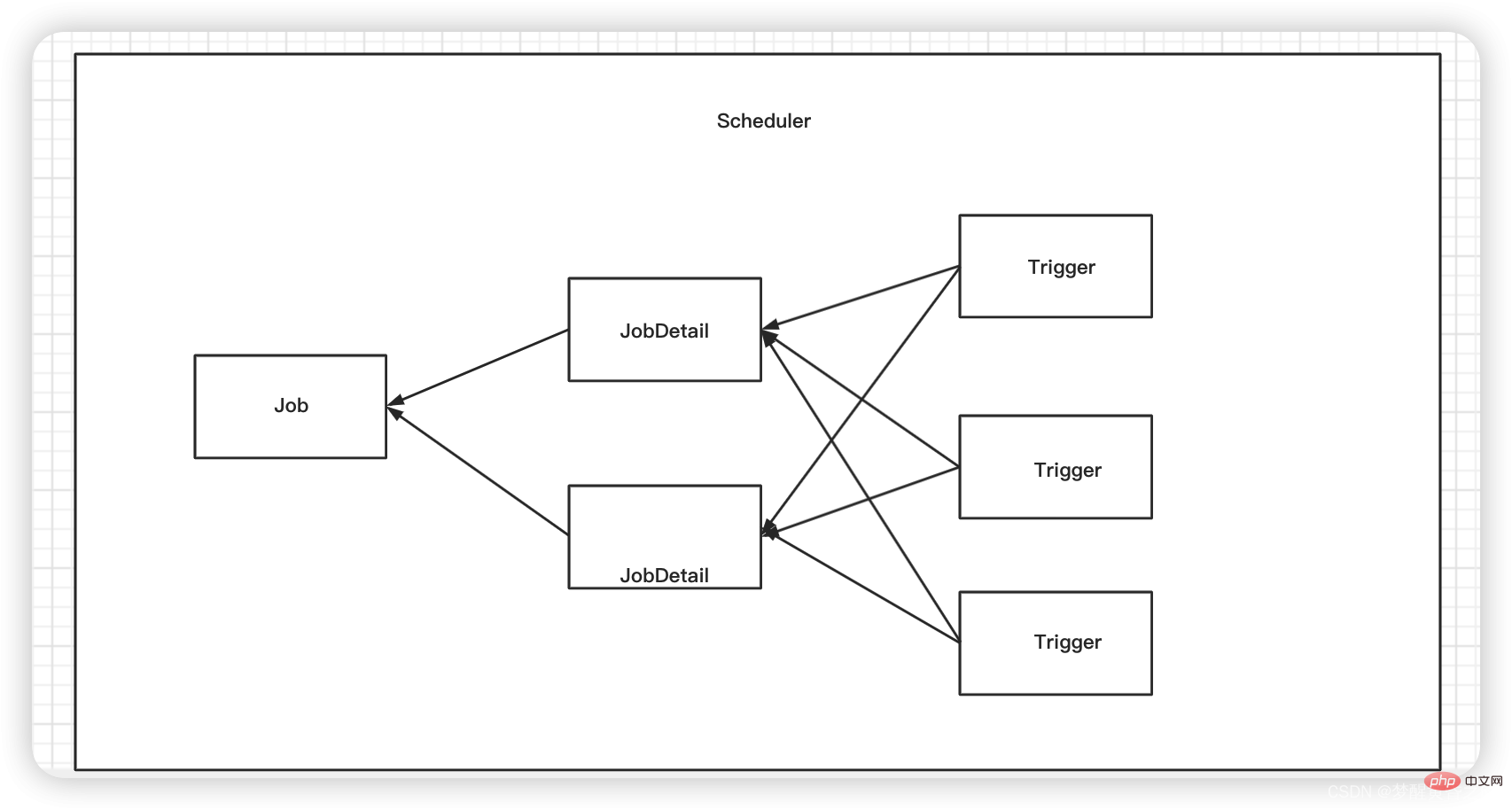
planificateur : il peut être compris comme un conteneur de travail ou un lieu de travail pour les tâches planifiées. Toutes les tâches planifiées y sont placées et peuvent être démarrées et arrêtées.
déclencheur : il peut être compris comme la configuration des règles de travail d'une tâche planifiée. Par exemple, il peut être appelé toutes les quelques minutes, ou il peut être exécuté à une heure spécifiée chaque jour.
jobDetail : informations sur la tâche planifiée, telles que la configuration du nom de la tâche planifiée, du groupe, etc.
job : là où se trouve la véritable logique métier de traitement des tâches planifiées.
Exemple simple
TestClient.Java
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
public class TaskClient {
public static void main(String[] args) {
JobDetail jobDetail = JobBuilder.newJob(TaskJob.class)
.withIdentity("job1", "group1") //设置JOB的名字和组
.build();
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger1", "trigger1")
.startNow()
.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(1)
.repeatForever())
.build();
try {
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
scheduler.scheduleJob(jobDetail,trigger);
scheduler.start();
} catch (SchedulerException ex) {
ex.printStackTrace();
}
}
}TaskJob.Java
import cn.hutool.core.date.DateUtil;
import org.quartz.Job;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
public class TaskJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
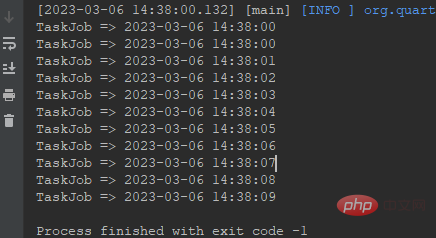
System.out.println("TaskJob => " + DateUtil.now());
}
}
usingJobData
Passez les paramètres à la tâche planifiée via usingJobData
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
public class TaskClient {
public static void main(String[] args) {
JobDetail jobDetail = JobBuilder.newJob(TaskJob.class)
.withIdentity("job1", "group1")
.usingJobData("job","jobDetail1.JobDataMap.Value")
.build();
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger1", "trigger1")
.usingJobData("trigger","trigger.JobDataMap.Value")
.startNow()
.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(1)
.repeatForever())
.build();
try {
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
scheduler.scheduleJob(jobDetail,trigger);
scheduler.start();
} catch (SchedulerException ex) {
ex.printStackTrace();
}
}
}TaskJob.java
import org.quartz.Job;
import org.quartz.JobDataMap;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
public class TaskJob implements Job {
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
JobDataMap jobDataMap = context.getJobDetail().getJobDataMap();
JobDataMap triggerMap = context.getTrigger().getJobDataMap();
JobDataMap mergeMap = context.getMergedJobDataMap();
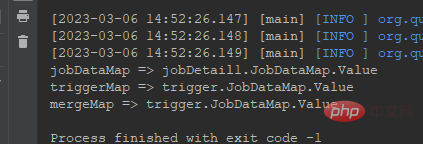
System.out.println("jobDataMap => " + jobDataMap.getString("job"));
System.out.println("triggerMap => " + triggerMap.getString("trigger"));
System.out.println("mergeMap => " + mergeMap.getString("trigger"));
}
} 
Assignation via les attributs
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
public class TaskClient {
public static void main(String[] args) {
JobDetail jobDetail = JobBuilder.newJob(TaskJob.class)
.withIdentity("job1", "group1")
.usingJobData("job","jobDetail1.JobDataMap.Value")
.usingJobData("name","jobDetail1.name.Value") //通过 setName 自动赋值
.build();
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger1", "trigger1")
.usingJobData("trigger","trigger.JobDataMap.Value")
.usingJobData("name","trigger.name.Value") //如果 Trigger 有值,会覆盖 JobDetail
.startNow()
.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(1)
.repeatForever())
.build();
try {
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
scheduler.scheduleJob(jobDetail,trigger);
scheduler.start();
} catch (SchedulerException ex) {
ex.printStackTrace();
}
}
}import org.quartz.*;
public class TaskJob implements Job {
private String name;
public void setName(String name) {
this.name = name;
}
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
System.out.println("name => " + name);
}
}Exécution non concurrente
@DisallowConcurrentExecution Sur la classe de travail, il est interdit d'exécuter simultanément plusieurs instances de la même définition de travail (définie par JobDetail).
import cn.hutool.core.date.DateUtil;
import org.quartz.*;
@DisallowConcurrentExecution
public class TaskJob implements Job {
@Override
public void execute(JobExecutionContext context) {
System.out.println("Time => " + DateUtil.now());
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}@PersistJobDataAfterExecution
Persistent JobDataMap dans JobDetail (non valide pour le datamap dans le déclencheur) si une tâche n'est pas
import cn.hutool.core.date.DateUtil;
import org.quartz.*;
//持久化JobDetail中的JobDataMap(对 trigger 中的 datamap 无效),如果一个任务不是
@PersistJobDataAfterExecution
public class TaskJob implements Job {
@Override
public void execute(JobExecutionContext context) {
JobDataMap triggerMap = context.getJobDetail().getJobDataMap();
triggerMap.put("count", triggerMap.getInt("count") + 1);
System.out.println("Time => " + DateUtil.now() + " count =>" + triggerMap.getInt("count"));
}
}Client
import org.quartz.*;
import org.quartz.impl.StdSchedulerFactory;
public class TaskClient {
public static void main(String[] args) {
JobDetail jobDetail = JobBuilder.newJob(TaskJob.class)
.withIdentity("job1", "group1")
.usingJobData("job","jobDetail1.JobDataMap.Value")
.usingJobData("name","jobDetail1.name.Value") //通过 setName 自动赋值
.usingJobData("count",0) //通过 setName 自动赋值
.build();
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger1", "trigger1")
.usingJobData("trigger","trigger.JobDataMap.Value")
.usingJobData("name","trigger.name.Value") //如果 Trigger 有值,会覆盖 JobDetail
.startNow()
.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(1)
.repeatForever())
.build();
try {
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
scheduler.scheduleJob(jobDetail,trigger);
scheduler.start();
} catch (SchedulerException ex) {
ex.printStackTrace();
}
}
}Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment utiliser l'API HTTPClient en Java
Aug 12, 2025 pm 02:27 PM
Comment utiliser l'API HTTPClient en Java
Aug 12, 2025 pm 02:27 PM
Le cœur de l'utilisation du javahttpclientapi est de créer un httpclient, de créer un httprequest et de traiter httpResponse. 1. Utilisez httpclient.newhttpclient () ou httpclient.newbuilder () pour configurer les délais d'expiration, proxy, etc. pour créer des clients; 2. Utilisez httpRequest.newBuilder () pour définir URI, méthode, en-tête et corps pour construire des demandes; 3. Envoyez des demandes synchrones via client.send () ou envoyez des demandes asynchrones via client.sendaSync (); 4. Utilisez des handleurs.
 Correction: Ethernet 'réseau non identifié'
Aug 12, 2025 pm 01:53 PM
Correction: Ethernet 'réseau non identifié'
Aug 12, 2025 pm 01:53 PM
RestartyourRouterAndComputerToresolvetemporaryGlithes.2.RunthenetWorkTrouleshooTerviATheSystemTraytomAticalMatterFixComMonissues.3.RenewtheipAddressusingcomandPomptSADMinistratorByrunningIpConfig / Release, Ipconfig / Renew, NetShwinsockReset, etnetSh
 Excel trouver et remplacer ne fonctionne pas
Aug 13, 2025 pm 04:49 PM
Excel trouver et remplacer ne fonctionne pas
Aug 13, 2025 pm 04:49 PM
CheckkSearchSettings like "MatchEnteRireCellContents" et "MatchCase" ByExpandingOptionsInFindanDreplace, garantissant "lookin" issettominuesand »dans" TOCORRECTSCOPE; 2.LOORHFORHIDDENCHARACTER
 Qu'est-ce qu'une liste liée en Java?
Aug 12, 2025 pm 12:14 PM
Qu'est-ce qu'une liste liée en Java?
Aug 12, 2025 pm 12:14 PM
LinkedList est une liste liée bidirectionnelle dans Java, implémentant la liste et les interfaces de Deque. Il convient aux scénarios où les éléments sont fréquemment insérés et supprimés. Surtout lorsqu'il fonctionne aux deux extrémités de la liste, il a une efficacité élevée, mais les performances d'accès aléatoire sont médiocres et la complexité du temps est O (n). L'insertion et la suppression peuvent atteindre O (1) à des endroits connus. Par conséquent, il convient à la mise en œuvre de piles, de files d'attente ou de situations où les structures doivent être modifiées dynamiquement et ne convient pas aux opérations à forte intensité de lecture qui accèdent fréquemment par index. La conclusion finale est que LinkedList est meilleur que ArrayList lorsqu'il est fréquemment modifié mais a moins d'accès.
 The Best Ides for Java Development: une revue comparative
Aug 12, 2025 pm 02:55 PM
The Best Ides for Java Development: une revue comparative
Aug 12, 2025 pm 02:55 PM
Thebestjavaidein2024Denpendyourndeds: 1.chooseintellijideaforprofessional, l'entreprise, le development orfulldevelopmentduetoitsSuperiorCodeIntelligence, le framewory
 Edge ne sauvant pas l'histoire
Aug 12, 2025 pm 05:20 PM
Edge ne sauvant pas l'histoire
Aug 12, 2025 pm 05:20 PM
Tout d'abord, Checkif "ClearbrowsingDataOnClose" IsTurneDOninsettingsandTurnitofftoenSureHistoryissaved.2.Confirmyou'renotusingInprivateMode, asitdoesNotsAvehistoryByDesigr.3.Disable ExtensionStendatoryToUleoutHeleft
 Comment déployer une application Java
Aug 17, 2025 am 12:56 AM
Comment déployer une application Java
Aug 17, 2025 am 12:56 AM
Préparez-vous en application par rapport à Mavenorgradletobuildajarorwarfile, externalisationConfiguration.2.ChoOSEADPLOYENDIRONMENT: Runonbaremetal / vmwithjava-jarandsystemd, deploywarontomcat, compeneriserisewithdocker, orusecloudplatformslikelise.
 Comment configurer la journalisation dans une application Java?
Aug 15, 2025 am 11:50 AM
Comment configurer la journalisation dans une application Java?
Aug 15, 2025 am 11:50 AM
L'utilisation de SLF4J combinée avec la journalisation ou le log4j2 est le moyen recommandé de configurer les journaux dans les applications Java. Il introduit des bibliothèques API et implémentation en ajoutant des dépendances Maven correspondantes; 2. Obtenez l'enregistreur via le loggerfactory de SLF4J dans le code et écrivez le code journal découplé et efficace à l'aide de méthodes de journalisation paramétrée; 3. Définir le format de sortie du journal, le niveau, la cible (console, le fichier) et le contrôle du journal du package via Logback.xml ou les fichiers de configuration log4j2.xml; 4. Activer éventuellement la fonction de balayage de fichiers de configuration pour atteindre un ajustement dynamique du niveau de journal, et Springboot peut également être géré via des points de terminaison de l'actionneur; 5. Suivez les meilleures pratiques, y compris
