

 Périphériques technologiques
IA
Institut de technologie avancée de Shenzhen, Académie chinoise des sciences : nouveau réseau neuronal graphique amélioré par les connaissances pour obtenir des recommandations interprétables
Périphériques technologiques
IA
Institut de technologie avancée de Shenzhen, Académie chinoise des sciences : nouveau réseau neuronal graphique amélioré par les connaissances pour obtenir des recommandations interprétables
Institut de technologie avancée de Shenzhen, Académie chinoise des sciences : nouveau réseau neuronal graphique amélioré par les connaissances pour obtenir des recommandations interprétables

Ces dernières années, l'intelligence artificielle basée sur le big data et le deep learning a démontré une excellente puissance de calcul et des capacités d'apprentissage. Cependant, les modèles d’apprentissage profond contiennent souvent des structures non linéaires profondément imbriquées, ce qui rend difficile la détermination des facteurs spécifiques qui ont conduit à une telle décision, manquant d’interprétabilité et de transparence dans la prise de décision.
Dans le même temps, étant donné que les recommandations explicables améliorent non seulement la transparence, l'explicabilité et la crédibilité du système de recommandation, mais améliorent également la satisfaction des utilisateurs, la tâche de recommandation explicable attire de plus en plus l'attention des chercheurs. .
Avec le développement des méthodes d'apprentissage en profondeur et de la technologie de traitement du langage, lors de la fourniture de recommandations personnalisées, de nombreuses méthodes utilisent la technologie de génération de langage naturel pour générer des explications de texte naturelles [2-3]. Cependant, en raison de la rareté des données, il est difficile de générer des explications textuelles de haute qualité et leur lisibilité est médiocre.
De plus, étant donné que les graphiques de connaissances peuvent contenir plus de faits et de connexions, certains chercheurs utilisent des graphiques de connaissances pour les recommandations et améliorent l'interprétabilité des recommandations grâce à des chemins de raisonnement graphiques [4-5]. Cependant, les méthodes basées sur les chemins de graphe nécessitent certaines conditions préalables ou définitions, telles que des chemins prédéfinis ou plusieurs types d'associations dans l'ensemble de données. Dans le même temps, le graphe de connaissances peut contenir des entités redondantes, conduisant à des résultats de recommandation homogènes.

Lien papier : https://ieeexplore.ieee.org/abstract/document/9681226
À cette fin, l'auteur propose un nouveau réseau neuronal graphique amélioré par les connaissances (KEGNN) pour obtenir des recommandations interprétables.
KEGNN utilise les connaissances sémantiques de la base de connaissances externe pour acquérir des connaissances sur trois aspects des utilisateurs, des produits et de l'interaction utilisateur-produit afin d'améliorer l'intégration sémantique.
Construisez le graphe de comportement de l'utilisateur du point de vue de l'interaction utilisateur-produit et initialisez le graphe de comportement de l'utilisateur à l'aide de l'intégration sémantique améliorée par les connaissances.
Ensuite, un modèle d'apprentissage et de raisonnement du comportement des utilisateurs basé sur un réseau neuronal graphique est proposé. Ce modèle transfère les informations sur les préférences de l'utilisateur et effectue un raisonnement multi-sauts sur les graphiques de comportement des utilisateurs pour comprendre de manière globale le comportement des utilisateurs.
Enfin, une couche de filtrage collaboratif hiérarchique est conçue pour la prédiction des recommandations, et le mécanisme de copie est combiné avec le générateur GRU pour générer des explications sémantiques de haute qualité et lisibles par l'homme. Les auteurs ont mené des expériences approfondies sur trois ensembles de données du monde réel. Les résultats expérimentaux montrent que KGNN surpasse les méthodes existantes.
Méthode
L'auteur propose un réseau neuronal graphique amélioré par les connaissances pour atteindre l'interprétabilité. L'architecture de la méthode proposée est présentée dans la figure 1.
Il comprend principalement quatre modules : apprentissage de la représentation sémantique amélioré par les connaissances, apprentissage du comportement des utilisateurs et raisonnement basé sur des réseaux de neurones graphiques, filtrage collaboratif hiérarchique et génération d'explications de texte.
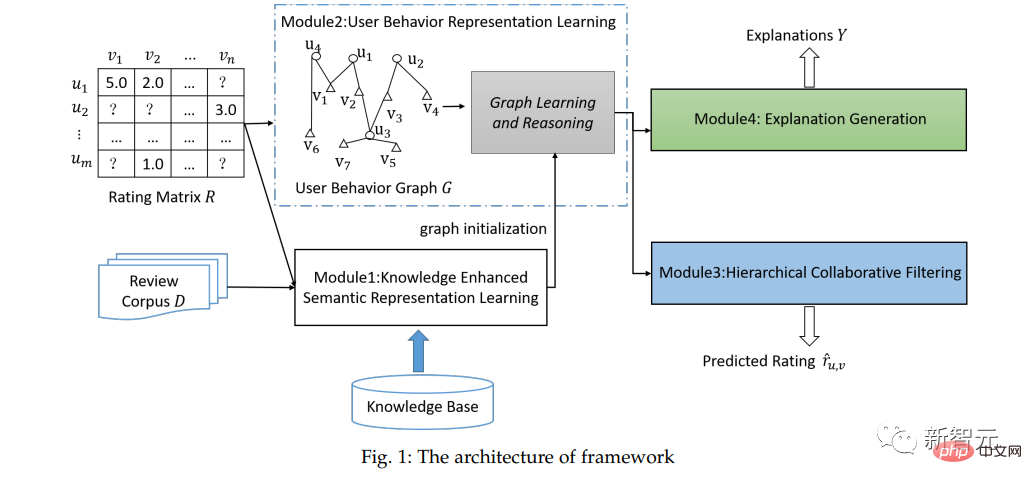
Module 1 : Afin d'apprendre l'apprentissage de la représentation sémantique des utilisateurs, des produits et des interactions utilisateur-produit, l'auteur a regroupé les documents d'évaluation des utilisateurs et des produits dans l'ordre chronologique pour former trois types de documents texte, représentés par des utilisateurs, des éléments. et les interactions utilisateur-élément.
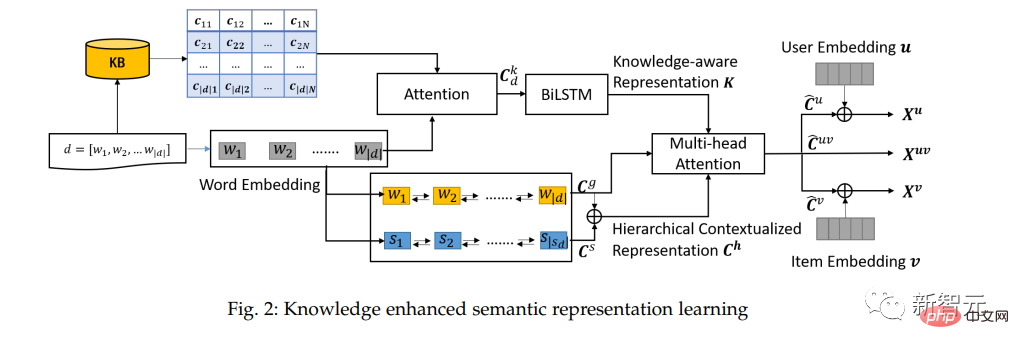
Un apprentissage supplémentaire de la représentation sémantique amélioré par les connaissances a été effectué sur les trois documents. La figure 2 montre la structure du module d'apprentissage de la représentation sémantique amélioré par les connaissances.
Tout d'abord, dans la partie représentation du contexte, la représentation d'intégration au niveau des mots et la représentation du contexte sémantique sont d'abord apprises, et BiLSTM est utilisé pour capturer globalement la couche supérieure de l'intégration au niveau des mots afin d'obtenir une représentation sémantique hiérarchique. Deuxièmement, dans le domaine de la perception des connaissances, l'auteur utilise la base de connaissances pour améliorer l'apprentissage des représentations sémantiques.
De plus, l'auteur utilise one-hot pour représenter l'encodage utilisateur/élément, utilise un mappage de couches entièrement connecté pour convertir une représentation one-hot clairsemée en représentation dense en tant que représentation inhérente de l'utilisateur/élément, et enfin, utilise plusieurs attention principale pour fusionner davantage les connaissances. La représentation perceptuelle et la représentation intrinsèque de l'utilisateur/élément produisent une représentation améliorée par les connaissances de l'interaction utilisateur/élément/utilisateur-élément.
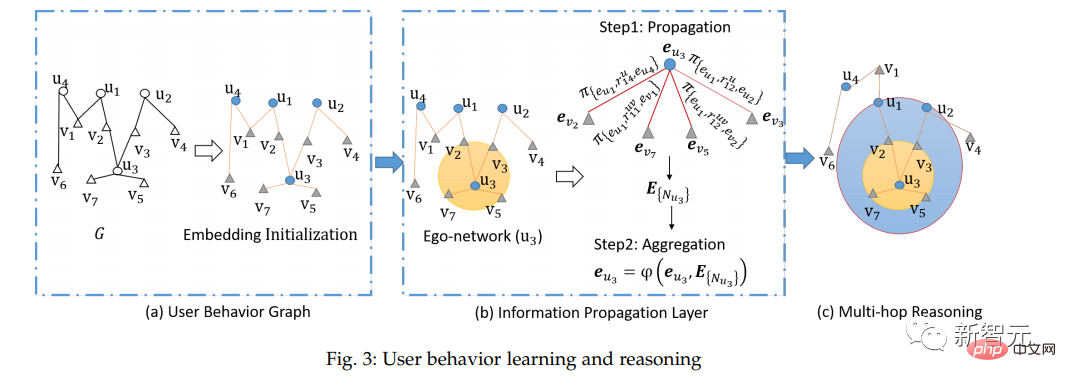
Module 2 : Afin de comprendre de manière globale les préférences de l'utilisateur, l'auteur a conçu un module d'apprentissage et de raisonnement du comportement de l'utilisateur basé sur un réseau neuronal graphique, comprenant trois étapes : construction d'un graphe de comportement de l'utilisateur, couche de diffusion d'informations et raisonnement multi-sauts, comme le montre la figure 3.
Premièrement, à partir de la relation d'interaction utilisateur-élément, l'auteur construit un graphe de comportement utilisateur et utilise une représentation sémantique améliorée par les connaissances pour initialiser la représentation de nœud et la représentation de bord du graphe de comportement utilisateur.
Deuxièmement, sur la base de l'architecture du réseau neuronal graphique, l'auteur a conçu la propagation et la fusion d'informations basées sur la couche de propagation d'informations GNN pour capturer le réseau de contiguïté de premier ordre (ego-réseau) entre les comportements des utilisateurs.
Enfin, une approche récursive est utilisée pour modéliser les informations de connexion d'ordre supérieur de la structure du graphe à l'aide d'un raisonnement multi-sauts.
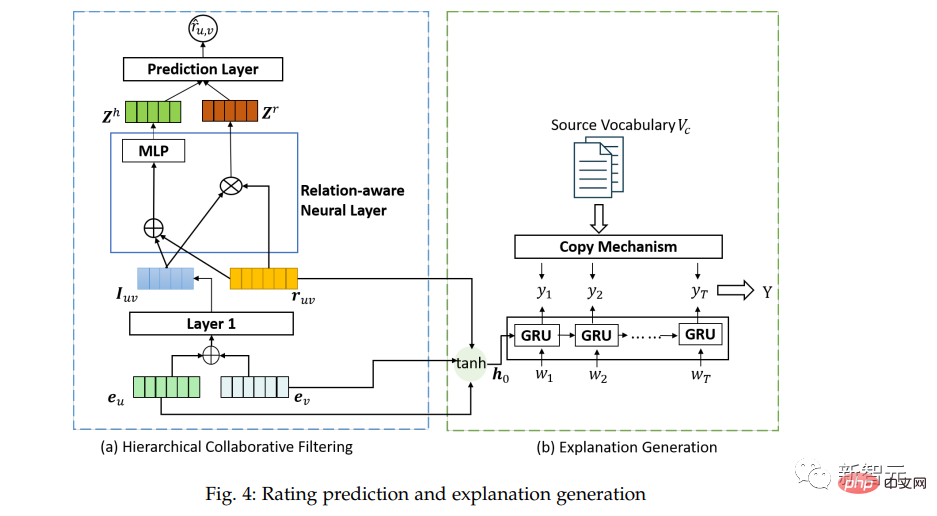
Module 3 : L'auteur conçoit un algorithme de filtrage collaboratif neuronal hiérarchique basé sur le cadre de filtrage collaboratif neuronal, comme le montre la figure 4(a), qui comprend principalement trois couches de couches de filtrage collaboratif neuronal pour atteindre l'utilisateur -prédiction d'interaction entre éléments.
La première couche de collaboration neuronale est une couche entièrement connectée. La représentation de l'utilisateur et la représentation du produit obtenues dans l'apprentissage et le raisonnement des graphiques de comportement de l'utilisateur sont assemblées en entrée, et la première couche de représentation de l'interaction utilisateur-produit est en sortie, comme le montre la Formule 1 :
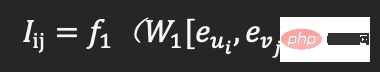
(Formule 1)
Dans la deuxième couche, nous concevons une couche de réseau neuronal sensible aux relations qui fusionne la représentation de la relation utilisateur-élément et la sortie de la première couche.
Utilise deux méthodes de fusion, à savoir le produit Hadamard (comme la formule 2) et la fusion non linéaire de couches entièrement connectées (telle que la formule 3), pour produire respectivement une représentation d'interaction utilisateur-produit sensible aux relations et une représentation d'interaction de haut niveau :
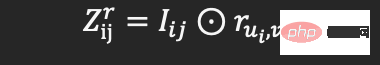
(Formule 2)
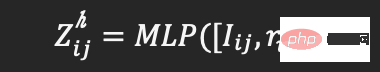
(Formule 3)
La troisième couche utilise une représentation d'interaction utilisateur-élément sensible aux relations et une représentation d'interaction de haut niveau comme entrée pour obtenir une prédiction de note, comme le montre la formule 4 :

(Formule 4)
Module 4 : Combinant le modèle de génération et le mécanisme de copie (mode génération et mode copie), l'auteur conçoit un nouveau module de génération d'explications de texte pour générer des textes de haute qualité lisibles par l'homme. explications.
La partie droite de la figure 4 montre les détails de ce module. Le réseau neuronal récurrent GRU est utilisé comme générateur d'explications ; un mécanisme de copie est également introduit pour extraire les informations des commentaires originaux des utilisateurs, et deux modes (mode génération et mode copie) sont combinés pour générer des explications textuelles intuitives (séquences de mots), qui sont faciles à lire et à comprendre pour les utilisateurs.
Expérience
Sélection d'ensembles de données
Cet article utilise trois ensembles de données du noyau Amazon5, à savoir l'électronique, la cuisine domestique et l'équipement musical. La plage de notation est [0,5]. Pour tous les ensembles de données, les auteurs ont sélectionné au hasard 80 % des interactions utilisateur-élément dans chaque ensemble de données comme ensemble d'apprentissage, 10 % des interactions utilisateur-élément comme ensemble de test et les 10 % restants des interactions utilisateur-élément ont été considérés. comme ensemble de validation.
Performance de prédiction des scores
Dans la comparaison des méthodes, l'auteur a comparé KEGNN avec CTR, PMF, NARRE, NRT, GCMC, LightGCN et RippleNet (en calculant le RMSE et le MAE de chaque méthode), comme le montre le chiffre.
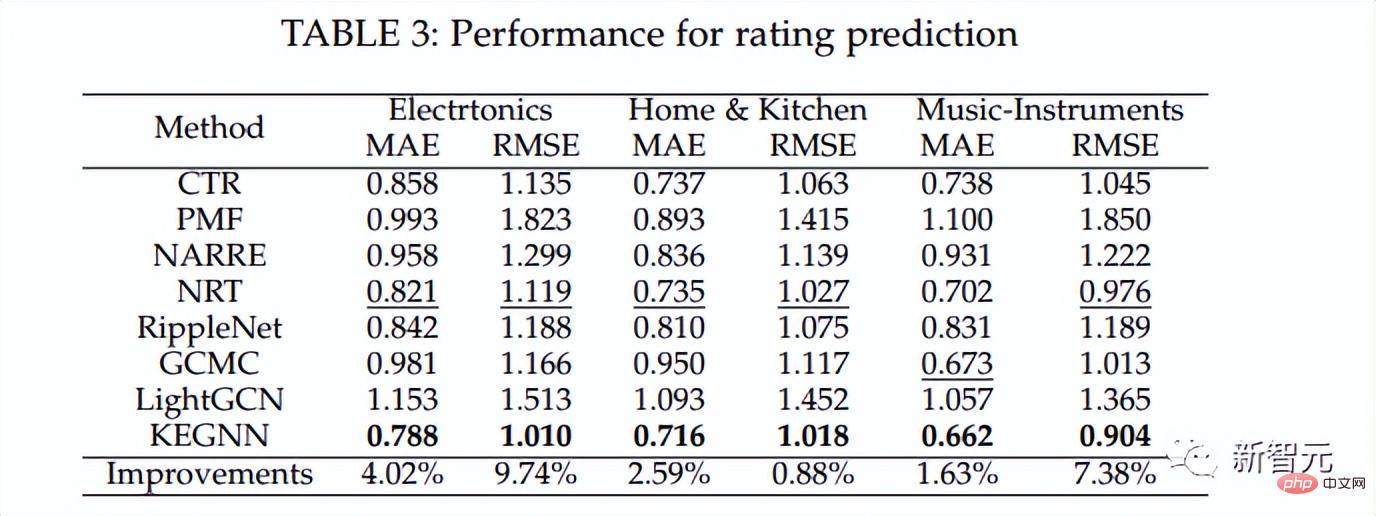
Comme le montrent les résultats, la méthode KEGNN de l'auteur surpasse toutes les méthodes comparées en MAE et RMSE pour tous les ensembles de données.
Explication de la qualité de génération
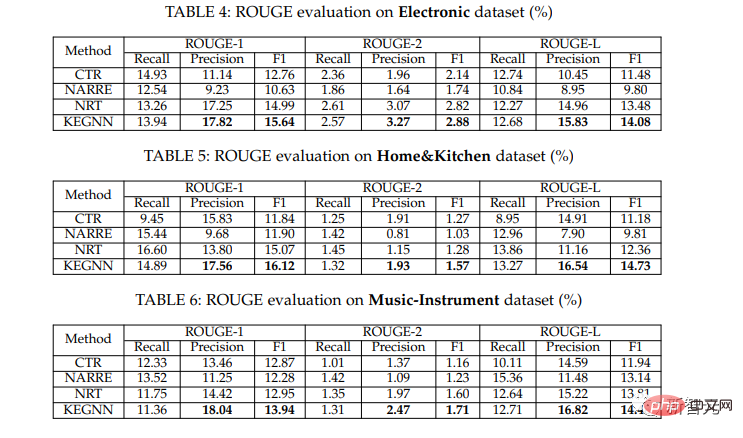
Comme le montrent les résultats, la méthode de l'auteur a les meilleures performances en précision et en indice F1, mais le taux de rappel n'est pas aussi bon que CTR ou NARRE. Les résultats de l'évaluation de la qualité montrent que les explications textuelles générées par les auteurs ressemblent à des analyses de la vérité sur le terrain liées aux comportements de traitement et révèlent les intentions implicites des utilisateurs derrière les comportements de traitement. Les auteurs étudient plus en détail l’interprétabilité dans une analyse de cas ultérieure.
Analyse de cas
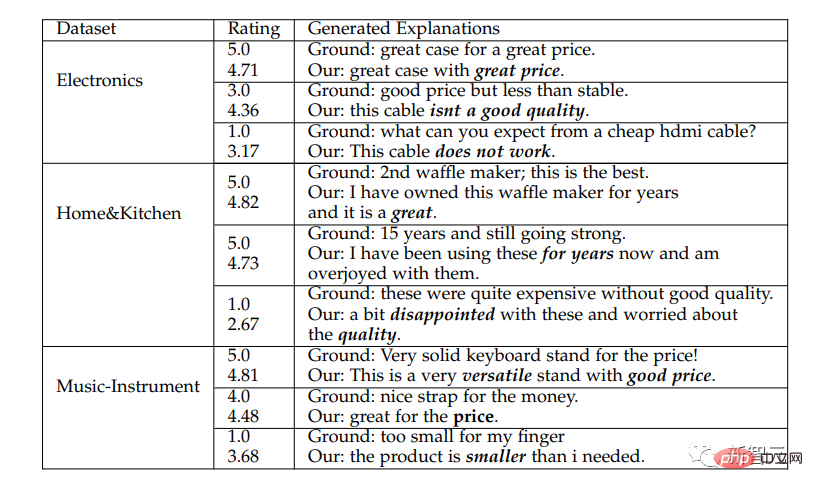
L'auteur sélectionne certains cas pour démontrer l'interprétabilité des explications générées. Les cas sélectionnés proviennent tous de l'ensemble de test. Par conséquent, le texte réel est masqué pendant le processus de génération d'explications. trois ensembles de données Un cas typique est présenté dans le tableau ci-dessus. Ground représente les commentaires réels donnés par les utilisateurs.
À partir de l'étude de cas, nous pouvons voir que la méthode de l'auteur génère des explications qui expliquent le choix de l'utilisateur et les raisons d'achat pour les articles notés. Les concepts et aspects explicables sont mis en évidence en italique gras, indiquant l'intention sous-jacente du comportement de l'utilisateur et démontrant l'explicabilité des résultats recommandés.
Conclusion
Cet article propose une méthode de recommandation explicable basée sur le réseau neuronal Knowledge Enhanced Graph (KEGNN), qui utilise les connaissances sémantiques dans des bases de connaissances externes pour améliorer l'apprentissage de la représentation utilisateur, élément et utilisateur-élément.
L'auteur a construit un graphique de comportement d'utilisateur et a conçu un module d'apprentissage et de raisonnement du comportement d'utilisateur basé sur un réseau neuronal graphique pour comprendre de manière globale le comportement des utilisateurs.
Enfin, le générateur GRU et le mécanisme de copie sont combinés pour générer des explications sémantiques de texte, et un filtrage collaboratif neuronal hiérarchique est utilisé pour obtenir des recommandations précises. Veuillez consulter les détails du papier pour plus de détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Pourquoi est-il nécessaire de passer des pointeurs lors de l'utilisation de bibliothèques Go et Viper?
Apr 02, 2025 pm 04:00 PM
Pourquoi est-il nécessaire de passer des pointeurs lors de l'utilisation de bibliothèques Go et Viper?
Apr 02, 2025 pm 04:00 PM
GO POINTER SYNTAXE ET ATTENDRE DES PROBLÈMES DANS LA BIBLIOTHÈQUE VIPER Lors de la programmation en langage Go, il est crucial de comprendre la syntaxe et l'utilisation des pointeurs, en particulier dans ...
 Comment rendre les données publiques disponibles pour tous les contrôleurs du framework Go Gin?
Apr 02, 2025 am 10:21 AM
Comment rendre les données publiques disponibles pour tous les contrôleurs du framework Go Gin?
Apr 02, 2025 am 10:21 AM
Comment faire en sorte que tous les contrôleurs obtiennent des données publiques dans le framework Gogin? Utilisation de Go ...
 GO Language Slice: Pourquoi ne signale-t-il pas une erreur lorsque l'indice de tranche à élément unique 1 interception?
Apr 02, 2025 pm 02:24 PM
GO Language Slice: Pourquoi ne signale-t-il pas une erreur lorsque l'indice de tranche à élément unique 1 interception?
Apr 02, 2025 pm 02:24 PM
GO Language Slice Index: Pourquoi une tranche à élément unique intercepte-t-elle de l'index 1 sans erreur? En langue GO, les tranches sont une structure de données flexible qui peut se référer au bas ...
 Comment implémenter des opérations sur les listes liées Linux Iptables à Golang?
Apr 02, 2025 am 10:18 AM
Comment implémenter des opérations sur les listes liées Linux Iptables à Golang?
Apr 02, 2025 am 10:18 AM
Utilisation de Golang pour implémenter Linux ...
 Pourquoi toutes les valeurs deviennent-elles le dernier élément lors de l'utilisation de la plage dans le langage GO pour traverser les tranches et stocker des cartes?
Apr 02, 2025 pm 04:09 PM
Pourquoi toutes les valeurs deviennent-elles le dernier élément lors de l'utilisation de la plage dans le langage GO pour traverser les tranches et stocker des cartes?
Apr 02, 2025 pm 04:09 PM
Pourquoi l'itération de la carte dans GO fait-elle que toutes les valeurs deviennent le dernier élément? En langue go, face à des questions d'entrevue, vous rencontrez souvent des cartes ...
 GO Language Slice Index: Pourquoi l'interception de la tranche à élément unique ne va-t-elle pas au-delà des limites?
Apr 02, 2025 pm 02:36 PM
GO Language Slice Index: Pourquoi l'interception de la tranche à élément unique ne va-t-elle pas au-delà des limites?
Apr 02, 2025 pm 02:36 PM
Exploration du problème de l'indice de tranchage GO de GO: tranche à élément unique interceptant dans GO, les tranches sont une structure de données flexible qui peut être utilisée pour les tableaux ou autres ...
 Comment importer correctement les packages personnalisés sous les modules GO?
Apr 02, 2025 pm 03:42 PM
Comment importer correctement les packages personnalisés sous les modules GO?
Apr 02, 2025 pm 03:42 PM
Dans le développement du langage GO, l'introduction correctement des packages personnalisés est une étape cruciale. Cet article ciblera "Golang ...
 Comportement de la concurrence du langage GO sans tamponner les canaux: pourquoi y a-t-il deux possibilités d'exécution des résultats?
Apr 02, 2025 am 10:24 AM
Comportement de la concurrence du langage GO sans tamponner les canaux: pourquoi y a-t-il deux possibilités d'exécution des résultats?
Apr 02, 2025 am 10:24 AM
Les caractéristiques non bloquantes et le comportement simultané des canaux de langue GO analyseront en détail les résultats de l'opération d'un code de langue GO lors de l'utilisation du canal et expliquent le ...
