


OpenAI的ChatGPT能够理解各种各样的人类指令,并在不同的语言任务中表现出色。这归功于一种新颖的大规模语言模型微调方法——RLHF(通过强化学习对齐人类反馈)。
RLHF方法解锁了语言模型遵循人类指令的能力,使得语言模型的能力与人类需求和价值观保持一致。
目前,RLHF的研究工作主要使用PPO算法对语言模型进行优化。然而,PPO算法包含许多超参数,并且在算法迭代过程中需要多个独立模型相互配合,因此错误的实现细节可能会导致训练结果不佳。
同时,从与人类对齐的角度来看,强化学习算法并不是必须的。

论文地址:https://arxiv.org/abs/2304.05302v1
项目地址:https://github.com/GanjinZero/RRHF
为此,阿里巴巴达摩院和清华大学的作者们提出了一种名为基于排序的人类偏好对齐的方法——RRHF。
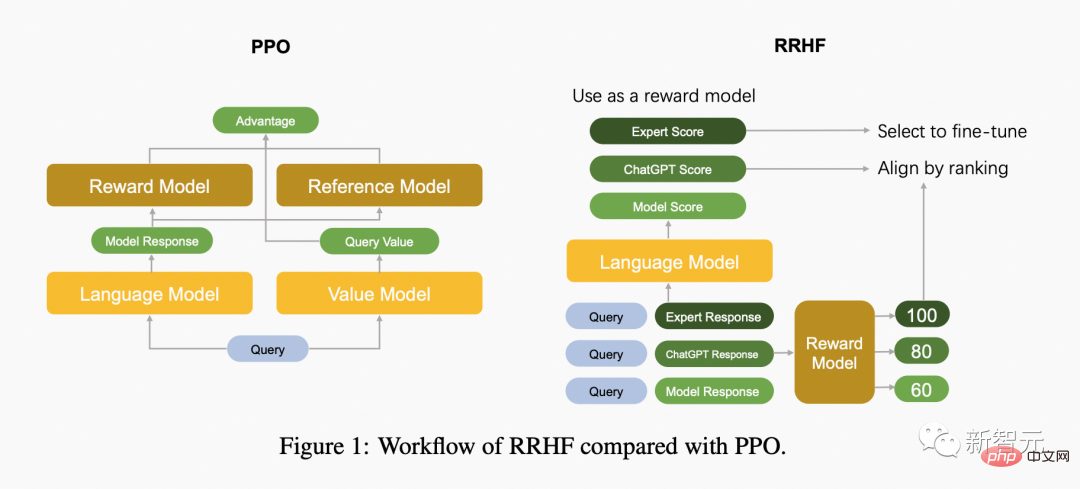
RRHF不需要强化学习,可以利用不同语言模型生成的回复,包括ChatGPT、GPT-4或当前的训练模型。RRHF通过对回复进行评分,并通过排名损失来使回复与人类偏好对齐。
与PPO不同,RRHF的训练过程可以利用人类专家或GPT-4的输出作为对比。训练好的RRHF模型可以同时用作生成语言模型和奖励模型。
Playgound AI的CEO表示,这是最近最有意思的一篇论文
下图中对比了PPO算法和RRHF算法的区别。
RRHF对于输入的查询,首先通过不同的方式获得k个回复,再用奖励模型对这k个回复分别打分。对于每一个回复采用对数概率的方式进行得分:
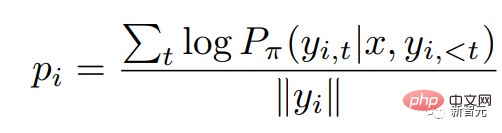
其中是自回归语言模型的概率分布。
我们希望对于奖励模型给分高的回复给与更大的概率,也就是希望和奖励得分相匹配。我们通过排序损失优化这个目标:
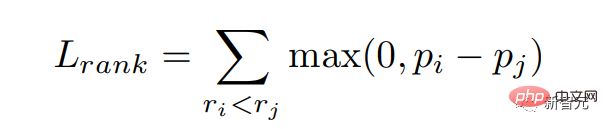
额外的,我们还给模型一个目标是去直接学习得分最高的回复:
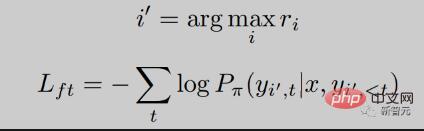
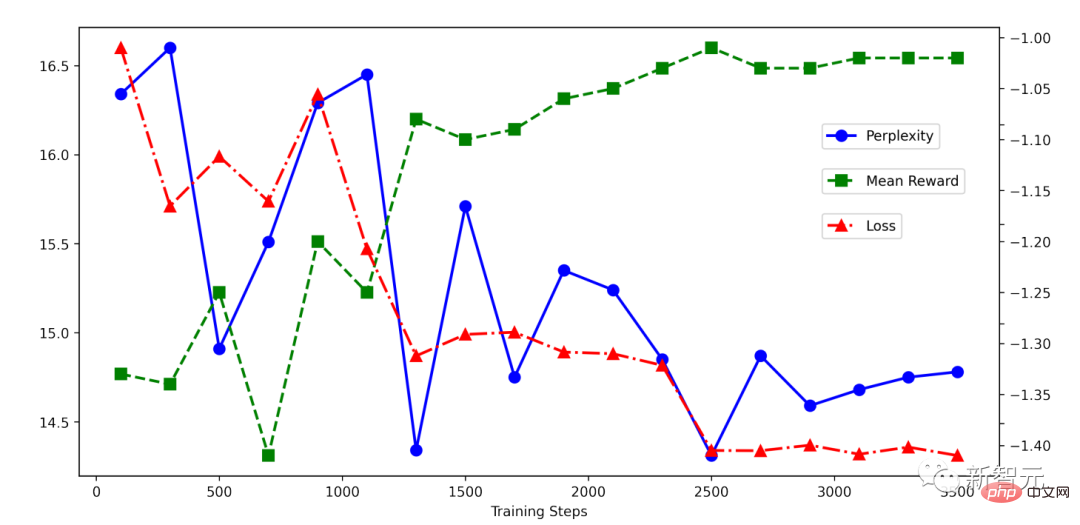
可以看到RRHF训练的过程十分简单,下面给出了一个RRHF训练时的loss下降情况,可以看到下降的十分稳定,而且奖励得分随着loss下降稳步上升。
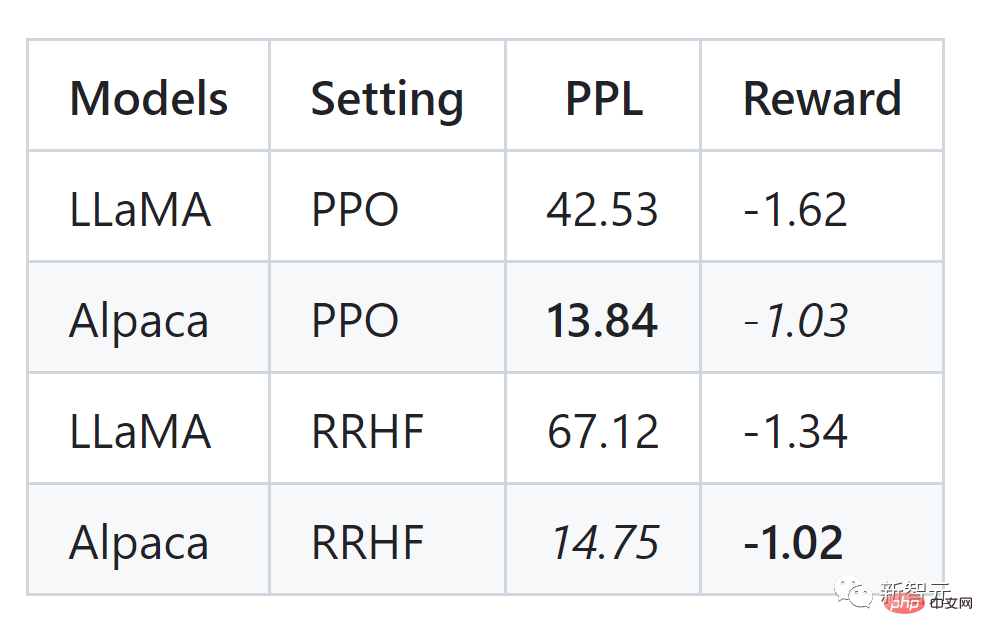
文章作者在HH数据集上进行了实验,也可以看到和PPO可比的效果:
RRHF算法可以有效地将语言模型输出概率与人类偏好对齐,其训练思路非常简单,训练完成的模型有几个特点:
RRHF方法利用OpenAI的chatGPT或GPT-4作为得分模型和ChatGPT、Alpaca等模型的输出作为训练样本,开发了两个新的语言模型,分别是Wombat-7B和Wombat-7B-GPT4。训练的时间在2-4个小时不等,十分轻量化。
袋熊Wombat作为新的开源预训练模型相比于LLaMA、Alpaca等可以更好的与人类偏好对齐。作者们实验发现Wombat-7B拥有角色扮演和进行反事实推理等复杂的能力。
如果让Wombat介绍来自3000年的未来科技,Wombat会这样回答(翻译自英文):
希望我们的未来如Wombat预测的一样越来越好。

参考资料:
https://github.com/GanjinZero/RRHF
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quels sont les logiciels de programmation du microcontrôleur ?
Quels sont les logiciels de programmation du microcontrôleur ?
 Comment résoudre le problème de l'absence du fichier msxml6.dll
Comment résoudre le problème de l'absence du fichier msxml6.dll
 vue v-si
vue v-si
 Quel plugin est Composer ?
Quel plugin est Composer ?
 Comment connecter des fichiers HTML et des fichiers CSS
Comment connecter des fichiers HTML et des fichiers CSS
 win10 se connecte à une imprimante partagée
win10 se connecte à une imprimante partagée
 Définir l'imprimante par défaut
Définir l'imprimante par défaut
 Type de commande de redémarrage Linux
Type de commande de redémarrage Linux





















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



