

 Java
javaDidacticiel
Comment envoyer plusieurs fichiers en utilisant une seule connexion TCP en Java ?
Java
javaDidacticiel
Comment envoyer plusieurs fichiers en utilisant une seule connexion TCP en Java ?
Comment envoyer plusieurs fichiers en utilisant une seule connexion TCP en Java ?

Utilisez une seule connexion TCP pour envoyer plusieurs fichiers
Pourquoi ? Vous avez ce blog ? J'ai lu des choses connexes récemment. Il n'y a aucun problème à simplement utiliser Socket pour la programmation, mais cela n'établit que quelques concepts de base. On ne peut toujours rien faire pour résoudre le véritable problème.
Lorsque j'ai besoin de transférer des fichiers, je constate que je viens d'envoyer les données (données binaires), mais certaines informations sur le fichier sont perdues (extension de fichier). Et je ne peux utiliser qu'un seul Socket pour envoyer un fichier à chaque fois, et il n'y a aucun moyen d'envoyer des fichiers en continu (car je compte sur la fermeture du flux pour terminer l'envoi des fichiers, ce qui signifie que je ne connais pas la longueur du fichier , je ne peux donc envoyer des fichiers que car une connexion Socket représente un fichier).
Ces problèmes me dérangent depuis longtemps. Je suis allé sur Internet pour chercher brièvement, mais je n'ai trouvé aucun exemple prêt à l'emploi (peut-être que je ne les ai pas trouvés). ). Quelqu'un l'a mentionné, vous pouvez #🎜 vous-même 🎜#DefinitionProtocol pour l'envoyer. Cela a piqué mon intérêt et j'ai eu l'impression d'avoir compris quelque chose, car je venais d'apprendre le cours Réseau Informatique Pour être honnête, je n'ai pas très bien appris, mais je connaissais le concept. de réseau informatique.
Au cours des réseaux informatiques, de nombreux protocoles ont été évoqués, et j'ai aussi eu la notion de protocoles sans le savoir. J'ai donc trouvé une solution :Définir moi-même un protocole simple sur la couche TCP. En définissant le protocole, le problème est résolu.
Le rôle du protocoleEnvoyer des données de l'hôte 1 à l'hôte 2. Du point de vue de la couche application, ils ne peuvent voir que les données de l'application, mais nous pouvons voir à travers le diagramme, on peut voir que les données commencent à partir de l'hôte 1 et qu'un en-tête est ajouté aux données pour chaque couche inférieure, puis se propage sur le réseau lorsqu'elles atteignent l'hôte 2, un en-tête est supprimé pour chaque couche supérieure. Lorsqu'il atteint la couche application, il n'y a que des données. (Voici juste une brève explication. En fait, ce n'est pas assez rigoureux, mais cela suffit pour une simple compréhension.) #Ainsi, je peux définir moi-même un protocole simple, mettre certaines informations nécessaires dans l'en-tête du protocole, puis laisser le programme informatique analyser les informations de l'en-tête du protocole par lui-même, et chaque message de protocole équivaut à un fichier. De cette façon, plusieurs protocoles constituent plusieurs fichiers. Et les protocoles peuvent être distingués. Sinon, si plusieurs fichiers sont transmis en continu, la transmission n'a aucun sens si le flux d'octets appartenant à chaque fichier ne peut pas être distingué.Définir le format d'envoi des données (protocole) 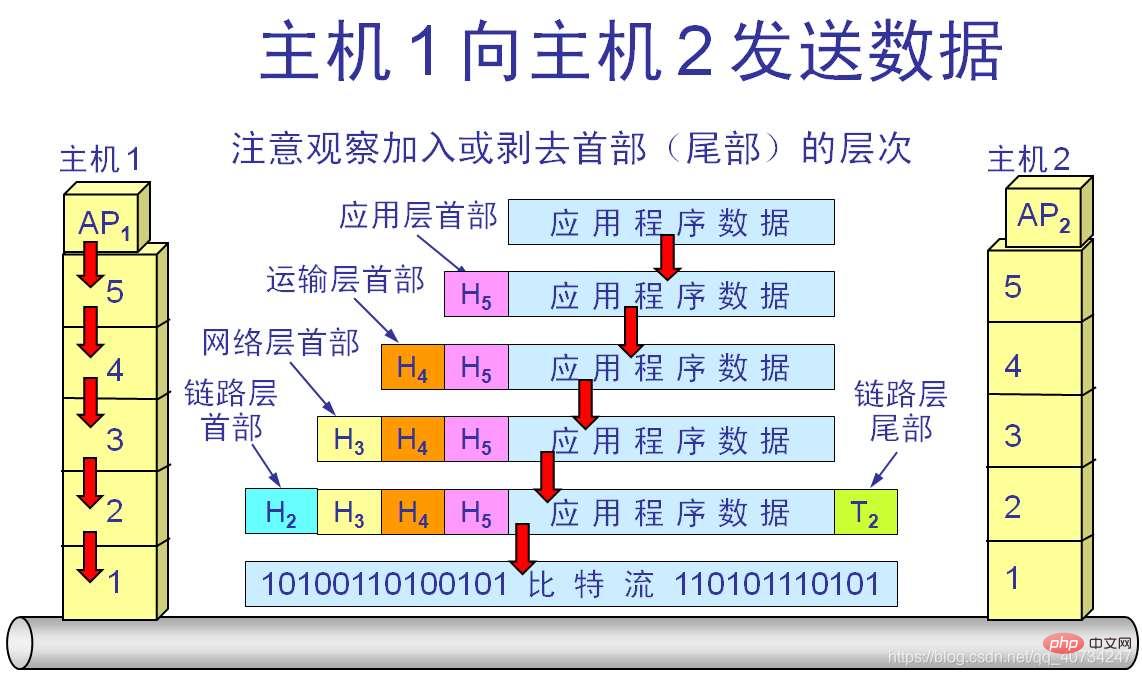
Format d'envoi : en-tête de données + corps de données
En-tête de données : une donnée d'une longueur d'un octet, représentant le contenu du fichier taper. Remarque : Comme le type de chaque fichier est différent et que la longueur est également différente, nous savons que l'en-tête du protocole a généralement une longueur fixe (nous ne considérons pas ceux de longueur variable), j'utilise donc une relation de mappage, c'est-à-dire autrement dit, un numéro d'octet représente le type d'un fichier.Donnez un exemple, comme suit :
key#🎜 🎜 #valeur
| txt | |
| 2 | |
| 3#🎜 🎜 # | |
| 4 | |
|
Remarque : ce que je fais ici est une simulation, je n'ai donc besoin que de tester quelques types. Corps de données : La partie données du fichier (données binaires). CodeClientClasse d'en-tête de protocole package com.dragon;
public class Header {
private byte type; //文件类型
private long length; //文件长度
public Header(byte type, long length) {
super();
this.type = type;
this.length = length;
}
public byte getType() {
return this.type;
}
public long getLength() {
return this.length;
}
}Envoyer la classe de fichier package com.dragon;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.net.Socket;
/**
* 模拟文件传输协议:
* 协议包含一个头部和一个数据部分。
* 头部为 9 字节,其余为数据部分。
* 规定头部包含:文件的类型、文件数据的总长度信息。
* */
public class FileTransfer {
private byte[] header = new byte[9]; //协议的头部为9字节,第一个字节为文件类型,后面8个字节为文件的字节长度。
/**
*@param src source folder
* @throws IOException
* @throws FileNotFoundException
* */
public void transfer(Socket client, String src) throws FileNotFoundException, IOException {
File srcFile = new File(src);
File[] files = srcFile.listFiles(f->f.isFile());
//获取输出流
BufferedOutputStream bos = new BufferedOutputStream(client.getOutputStream());
for (File file : files) {
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream(file))){
//将文件写入流中
String filename = file.getName();
System.out.println(filename);
//获取文件的扩展名
String type = filename.substring(filename.lastIndexOf(".")+1);
long len = file.length();
//使用一个对象来保存文件的类型和长度信息,操作方便。
Header h = new Header(this.getType(type), len);
header = this.getHeader(h);
//将文件基本信息作为头部写入流中
bos.write(header, 0, header.length);
//将文件数据作为数据部分写入流中
int hasRead = 0;
byte[] b = new byte[1024];
while ((hasRead = bis.read(b)) != -1) {
bos.write(b, 0, hasRead);
}
bos.flush(); //强制刷新,否则会出错!
}
}
}
private byte[] getHeader(Header h) {
byte[] header = new byte[9];
byte t = h.getType();
long v = h.getLength();
header[0] = t; //版本号
header[1] = (byte)(v >>> 56); //长度
header[2] = (byte)(v >>> 48);
header[3] = (byte)(v >>> 40);
header[4] = (byte)(v >>> 32);
header[5] = (byte)(v >>> 24);
header[6] = (byte)(v >>> 16);
header[7] = (byte)(v >>> 8);
header[8] = (byte)(v >>> 0);
return header;
}
/**
* 使用 0-127 作为类型的代号
* */
private byte getType(String type) {
byte t = 0;
switch (type.toLowerCase()) {
case "txt": t = 0; break;
case "png": t=1; break;
case "jpg": t=2; break;
case "jpeg": t=3; break;
case "avi": t=4; break;
}
return t;
}
}Remarque :
Classe de test package com.dragon;
import java.io.IOException;
import java.net.Socket;
import java.net.UnknownHostException;
//类型使用代号:固定长度
//文件长度:long->byte 固定长度
public class Test {
public static void main(String[] args) throws UnknownHostException, IOException {
FileTransfer fileTransfer = new FileTransfer();
try (Socket client = new Socket("127.0.0.1", 8000)) {
fileTransfer.transfer(client, "D:/DBC/src");
}
}
}Côté serveurClasse d'analyse de protocole package com.dragon;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.Socket;
import java.util.UUID;
/**
* 接受客户端传过来的文件数据,并将其还原为文件。
* */
public class FileResolve {
private byte[] header = new byte[9];
/**
* @param des 输出文件的目录
* */
public void fileResolve(Socket client, String des) throws IOException {
BufferedInputStream bis = new BufferedInputStream(client.getInputStream());
File desFile = new File(des);
if (!desFile.exists()) {
if (!desFile.mkdirs()) {
throw new FileNotFoundException("无法创建输出路径");
}
}
while (true) {
//先读取文件的头部信息
int exit = bis.read(header, 0, header.length);
//当最后一个文件发送完,客户端会停止,服务器端读取完数据后,就应该关闭了,
//否则就会造成死循环,并且会批量产生最后一个文件,但是没有任何数据。
if (exit == -1) {
System.out.println("文件上传结束!");
break;
}
String type = this.getType(header[0]);
String filename = UUID.randomUUID().toString()+"."+type;
System.out.println(filename);
//获取文件的长度
long len = this.getLength(header);
long count = 0L;
try (BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream(new File(des, filename)))){
int hasRead = 0;
byte[] b = new byte[1024];
while (count < len && (hasRead = bis.read(b)) != -1) {
bos.write(b, 0, hasRead);
count += (long)hasRead;
/**
* 当文件最后一部分不足1024时,直接读取此部分,然后结束。
* 文件已经读取完成了。
* */
int last = (int)(len-count);
if (last < 1024 && last > 0) {
//这里不考虑网络原因造成的无法读取准确的字节数,暂且认为网络是正常的。
byte[] lastData = new byte[last];
bis.read(lastData);
bos.write(lastData, 0, last);
count += (long)last;
}
}
}
}
}
/**
* 使用 0-127 作为类型的代号
* */
private String getType(int type) {
String t = "";
switch (type) {
case 0: t = "txt"; break;
case 1: t = "png"; break;
case 2: t = "jpg"; break;
case 3: t = "jpeg"; break;
case 4: t = "avi"; break;
}
return t;
}
private long getLength(byte[] h) {
return (((long)h[1] << 56) +
((long)(h[2] & 255) << 48) +
((long)(h[3] & 255) << 40) +
((long)(h[4] & 255) << 32) +
((long)(h[5] & 255) << 24) +
((h[6] & 255) << 16) +
((h[7] & 255) << 8) +
((h[8] & 255) << 0));
}
}Remarque :
if (exit == -1) {
System.out.println("文件上传结束!");
break;
}Classe de test Testez simplement une connexion ici. Ceci est juste un exemple illustratif. package com.dragon;
import java.io.IOException;
import java.net.ServerSocket;
import java.net.Socket;
public class Test {
public static void main(String[] args) throws IOException {
try (ServerSocket server = new ServerSocket(8000)){
Socket client = server.accept();
FileResolve fileResolve = new FileResolve();
fileResolve.fileResolve(client, "D:/DBC/des");
}
}
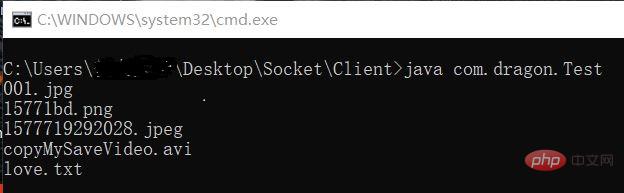
}Résultats des testsClient
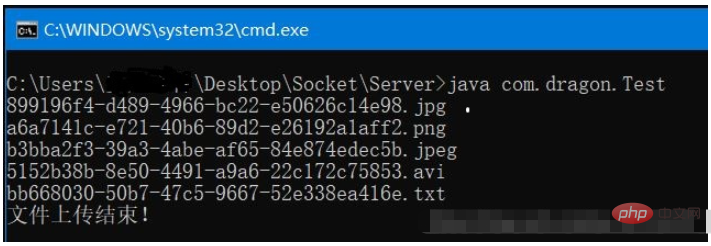
Serveur
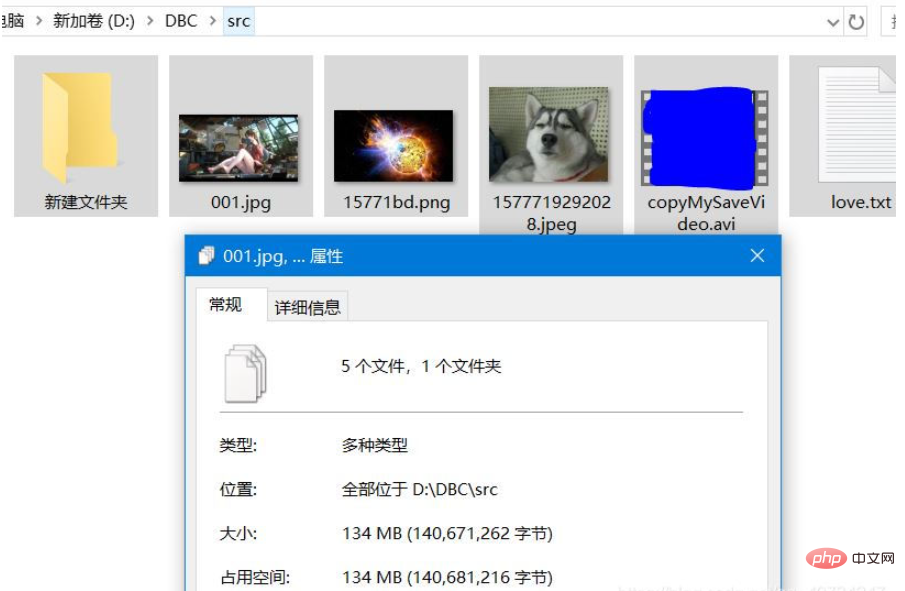
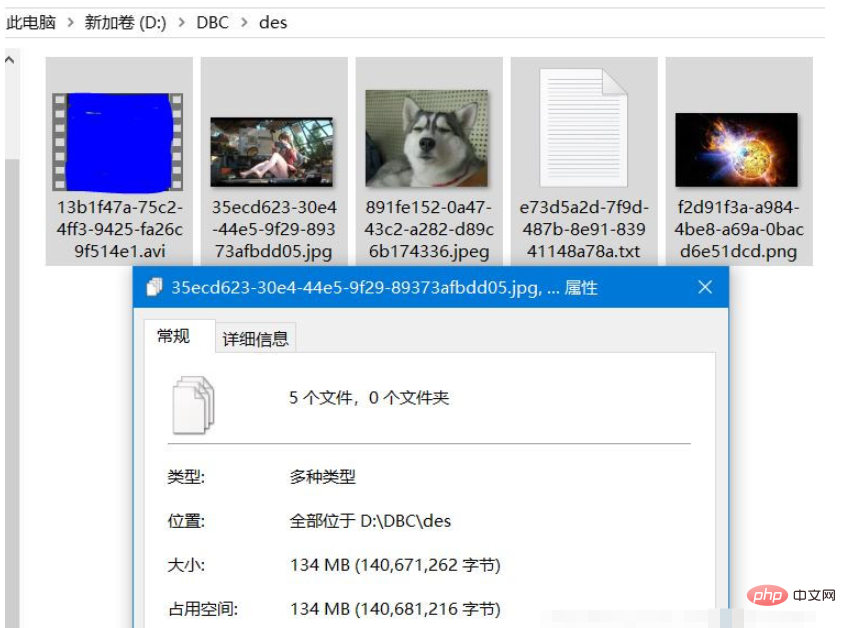
Répertoire de fichiers source Celui-ci contient les cinq types de fichiers que j'ai testés. Faites attention à comparer les informations de taille du fichier. Pour les tests IO, j'aime utiliser les tests d'image et de vidéo, car ce sont des fichiers très spéciaux. S'il y a une légère erreur (moins ou plus d'octets), le fichier sera fondamentalement endommagé. , et les performances L'image ne s'affiche pas correctement et la vidéo ne peut pas être lue normalement.
Répertoire des fichiers de destination
|
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Excel trouver et remplacer ne fonctionne pas
Aug 13, 2025 pm 04:49 PM
Excel trouver et remplacer ne fonctionne pas
Aug 13, 2025 pm 04:49 PM
CheckkSearchSettings like "MatchEnteRireCellContents" et "MatchCase" ByExpandingOptionsInFindanDreplace, garantissant "lookin" issettominuesand »dans" TOCORRECTSCOPE; 2.LOORHFORHIDDENCHARACTER
 Comment configurer la journalisation dans une application Java?
Aug 15, 2025 am 11:50 AM
Comment configurer la journalisation dans une application Java?
Aug 15, 2025 am 11:50 AM
L'utilisation de SLF4J combinée avec la journalisation ou le log4j2 est le moyen recommandé de configurer les journaux dans les applications Java. Il introduit des bibliothèques API et implémentation en ajoutant des dépendances Maven correspondantes; 2. Obtenez l'enregistreur via le loggerfactory de SLF4J dans le code et écrivez le code journal découplé et efficace à l'aide de méthodes de journalisation paramétrée; 3. Définir le format de sortie du journal, le niveau, la cible (console, le fichier) et le contrôle du journal du package via Logback.xml ou les fichiers de configuration log4j2.xml; 4. Activer éventuellement la fonction de balayage de fichiers de configuration pour atteindre un ajustement dynamique du niveau de journal, et Springboot peut également être géré via des points de terminaison de l'actionneur; 5. Suivez les meilleures pratiques, y compris
 Comment déployer une application Java
Aug 17, 2025 am 12:56 AM
Comment déployer une application Java
Aug 17, 2025 am 12:56 AM
Préparez-vous en application par rapport à Mavenorgradletobuildajarorwarfile, externalisationConfiguration.2.ChoOSEADPLOYENDIRONMENT: Runonbaremetal / vmwithjava-jarandsystemd, deploywarontomcat, compeneriserisewithdocker, orusecloudplatformslikelise.
 Liaison des données XML avec Castor en Java
Aug 15, 2025 am 03:43 AM
Liaison des données XML avec Castor en Java
Aug 15, 2025 am 03:43 AM
CASTORENablesxml-to-javaObjectMappingViadefaultConverionsOrexplicitMappingFiles; 1) DefinejavaclasseswithGetters / seters; 2) useUnmarShallertOConvertXmltoObjects; 3)
 Comment écrire un client / serveur TCP simple en C
Aug 17, 2025 am 01:50 AM
Comment écrire un client / serveur TCP simple en C
Aug 17, 2025 am 01:50 AM
La réponse est que l'écriture d'un client et serveur TCP simples nécessite l'interface de programmation de socket fournie par le système d'exploitation. Le serveur termine la communication en créant des prises, des adresses de liaison, en écoutant les ports, en acceptant les connexions et en envoyant et recevant des données. Le client réalise l'interaction en créant des sockets, en se connectant aux serveurs, en envoyant des demandes et en recevant des réponses. L'exemple de code montre l'implémentation de base de l'utilisation de l'API Socket Berkeley sur Linux ou MacOS, y compris les fichiers d'en-tête nécessaires, les paramètres du port, la gestion des erreurs et la version des ressources. Après la compilation, exécutez d'abord le serveur, puis exécutez le client pour obtenir une communication bidirectionnelle. La plate-forme Windows doit initialiser la bibliothèque WinSock. Cet exemple est un modèle d'E / S de blocage, adapté à l'apprentissage de la programmation de base de socket.
 JS Ajouter un élément au début du tableau
Aug 14, 2025 am 11:51 AM
JS Ajouter un élément au début du tableau
Aug 14, 2025 am 11:51 AM
Dans JavaScript, la méthode la plus courante pour ajouter des éléments au début d'un tableau est d'utiliser la méthode Unsich (); 1. En utilisant unsith () modifiera directement le tableau d'origine, vous pouvez ajouter un ou plusieurs éléments pour retourner la nouvelle longueur du tableau ajouté; 2. Si vous ne souhaitez pas modifier le tableau d'origine, il est recommandé d'utiliser l'opérateur d'extension (tel que [Newelement, ... Arr]) pour créer un nouveau tableau; 3. Vous pouvez également utiliser la méthode CONCAT () pour combiner le nouveau tableau d'éléments avec le numéro d'origine, renvoyez le nouveau tableau sans modifier le tableau d'origine; En résumé, utilisez Unsich () lors de la modification du tableau d'origine et recommandez l'opérateur d'extension lorsque vous gardez le tableau d'origine inchangé.
 Comparaison des performances: Java Vs. GO pour les services backend
Aug 14, 2025 pm 03:32 PM
Comparaison des performances: Java Vs. GO pour les services backend
Aug 14, 2025 pm 03:32 PM
GOTYPICAL OFFERSBETTERRUNTIMEPERFORMANCE AVEC LA MAINTRÉE DE PUTHROUGHTANDLOWERLATENCE, ENTERTFORI / O-HEAVYSERVICES, DUETOITSLIGHT LONDEGOROUTINESANDERFICENTSCHEDULL
 Comment travailler avec JSON à Java
Aug 14, 2025 pm 03:40 PM
Comment travailler avec JSON à Java
Aug 14, 2025 pm 03:40 PM
ToworkwithJSONinJava,useathird-partylibrarylikeJackson,Gson,orJSON-B,asJavalacksbuilt-insupport;2.Fordeserialization,mapJSONtoJavaobjectsusingObjectMapperinJacksonorGson.fromJson;3.Forserialization,convertJavaobjectstoJSONstringsviawriteValueAsString
