

 développement back-end
Tutoriel Python
L'objectif de Python 3.12 : des performances plus efficaces !
développement back-end
Tutoriel Python
L'objectif de Python 3.12 : des performances plus efficaces !
L'objectif de Python 3.12 : des performances plus efficaces !


Selon le plan de sortie, Python 3.11.0 sortira le 24 octobre 2022.
Selon les tests, la version 3.11 aura une amélioration des performances de 10 à 60 % par rapport à la version 3.10. Cette réussite est principalement attribuée au projet « Faster CPython », également connu sous le nom de « Projet Shannon ».
La version 3.11 est un début passionnant pour l’accélération de Python. D'autres actions arriveront prochainement dans la version 3.12.
L'article suivant est traduit de "Python 3.12 Goals" par "Shannon Project", jetons-y un coup d'œil d'abord !
- Auteur : Mark Shannon
- Traducteur : Pea Flower Cat @Python Cat
- Anglais : https://github.com/faster-cpython/ideas/wiki/Python-3.12-Goals
Le contenu de cet article peut être sujet à changement, la version actuelle prévaudra !
Cet article est un résumé du contenu principal que Faster CPython prévoit d'implémenter dans la version 3.12.
Optimiseur de suivi
Le principal moyen d'améliorer la vitesse dans Python 3.11 est de remplacer les opcodes individuels par des opcodes contextuels plus rapides (opcodes de spécialisation adaptative). La prochaine grande amélioration consiste à optimiser plusieurs opérations de l'opcode.
Pour ce faire, de nombreux opcodes de haut niveau existants seront remplacés par des opcodes de bas niveau, tels que ceux utilisés pour vérifier les numéros de version et les décomptes de références. Ces opcodes plus simples sont plus faciles à optimiser, par exemple, les opérations de comptage de références redondantes peuvent être supprimées.
Ces opcodes de niveau inférieur nous donnent également un ensemble d'instructions adaptées à la génération de code machine (dans les projets CPython et JIT tiers).
Pour ce faire, une boucle d'interprétation sera générée en fonction de la description déclarative.
Cela peut réduire certains bugs causés par le maintien de la boucle d'interprétation synchronisée avec certaines fonctions associées (mark_stacks, stack_effect, etc.), et nous permet également d'expérimenter des changements plus importants dans la boucle d'interprétation.
Parallélisme multithread
Python dispose actuellement d'un verrou d'interpréteur global (GIL) par processus, ce qui entrave le parallélisme multithread.
- PEP-684 : https://peps.python.org/pep-0684
- PEP-554 : https://peps.python.org/pep-0554

PEP-684 proposé Un La solution consiste à garantir que tous les états globaux sont thread-safe et déplacés vers le verrou global de l'interpréteur de chaque sous-interprète.
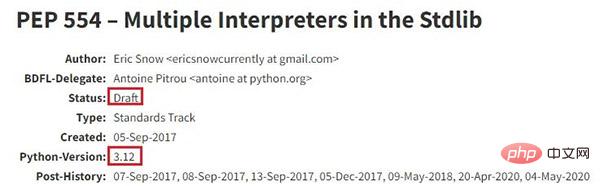
PEP-554 propose une solution pour Python pour créer des sous-interprètes (actuellement uniquement une fonctionnalité de l'API C), réalisant ainsi un véritable parallélisme multithread.
- Remarque Python Cat : le PEP-554 a été proposé dès 2017, dans le but d'atterrir dans les versions Python 3.8-3.9, mais il s'est retourné contre lui. Dès 2019, j'ai également traduit un article "Le Python GIL a-t-il été tué ?". Le couteau de boucher a été balancé, laissez-le voler pendant un moment ~~
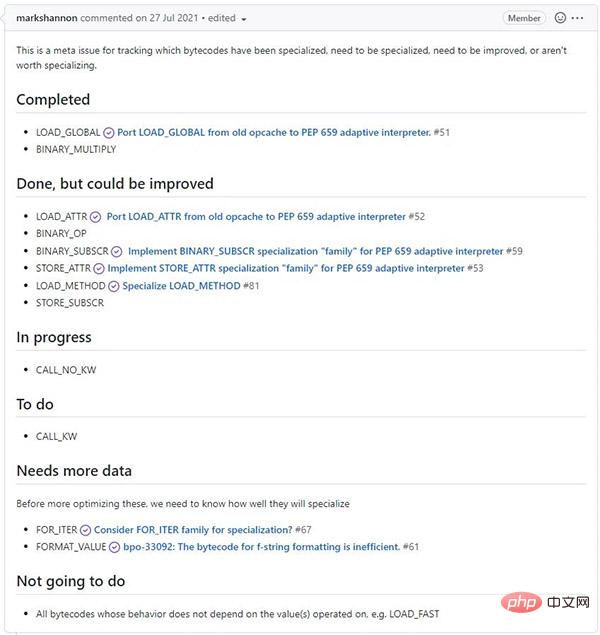
Plus de spécialisation
Nous avons analysé quels bytecodes bénéficieront le plus de la spécialisation et prévoyons d'achever les améliorations restantes à haut rendement dans la version 3.12.
//m.sbmmt.com/link/7392ea4ca76ad2fb4c9c3b6a5c6e31e3
Structures d'objets plus petites
Il existe de nombreuses possibilités de réduire la taille des structures d'objets Python. Comme ils sont fréquemment utilisés, cela profite non seulement à l’utilisation globale de la mémoire, mais également à la cohérence du cache. Nous prévoyons de mettre en œuvre certaines des idées les plus prometteuses dans la version 3.12.
Il existe certains compromis entre compatibilité ascendante et performances, et un PEP devra peut-être être proposé pour parvenir à un consensus.
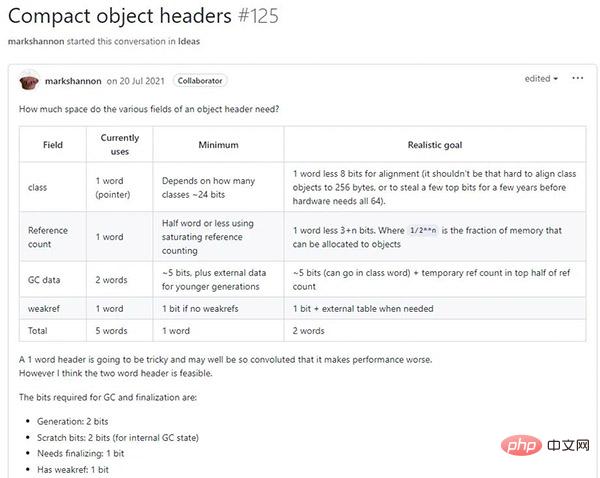
Réduire les frais de gestion de la mémoire
Nous allons non seulement réduire la taille des objets, mais également rendre leur disposition plus régulière.
Cela optimise non seulement l'allocation et la désallocation de mémoire, mais accélère également la traversée des objets lors du GC et de la réallocation.
Stabilité de l'API
En plus des projets susmentionnés, l'équipe de développement améliorera également la qualité globale de la base de code CPython :
- En réduisant le couplage des différentes étapes de compilation, le compilateur est plus facile à maintenir et à tester.
- Surveiller et améliorer activement la couverture du code des suites de tests CPython au niveau du langage C.
- Améliorez la suite de tests de performances Python pour inclure des tests de charge plus représentatifs dans le monde réel.
- Aider aux problèmes et aux relations publiques de CPython, en particulier ceux liés aux performances.
- Ajout de machines pour les benchmarks standard et ajout de résultats de tests pour macOS et Windows.
- Continuer à travailler avec des projets majeurs qui utilisent fortement le noyau Python pour les aider à s'adapter aux changements de l'interpréteur CPython.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.


Stock Market GPT
Recherche d'investissement basée sur l'IA pour des décisions plus intelligentes

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)

 Comment installer des packages à partir d'un fichier exigence.txt dans Python
Sep 18, 2025 am 04:24 AM
Comment installer des packages à partir d'un fichier exigence.txt dans Python
Sep 18, 2025 am 04:24 AM
Exécutez pipinstall-rrequirements.txt pour installer le package de dépendance. Il est recommandé de créer et d'activer l'environnement virtuel d'abord pour éviter les conflits, s'assurer que le chemin du fichier est correct et que le PIP a été mis à jour et utiliser des options telles que --No-Deps ou --User pour ajuster le comportement d'installation si nécessaire.
 Comment tester le code Python avec Pytest
Sep 20, 2025 am 12:35 AM
Comment tester le code Python avec Pytest
Sep 20, 2025 am 12:35 AM
Python est un outil de test simple et puissant dans Python. Après l'installation, les fichiers de test sont automatiquement découverts en fonction des règles de dénomination. Écrivez une fonction commençant par test_ pour les tests d'assurance, utilisez @ pytest.fixture pour créer des données de test réutilisables, vérifiez les exceptions via PyTest.Rais, prend en charge l'exécution de tests spécifiés et plusieurs options de ligne de commande et améliore l'efficacité des tests.
 Comment gérer les arguments de ligne de commande dans Python
Sep 21, 2025 am 03:49 AM
Comment gérer les arguments de ligne de commande dans Python
Sep 21, 2025 am 03:49 AM
TheargParsemoduleisthereComMendwaytoHandleCommand-lineargumentsInpython, fournissantRobustParsing, Typevalidation, HelpMessages, AnderrorHling; usys.argvforsimplécasesrequiringminimalsepup.
 Qu'est-ce que le bip? Pourquoi sont-ils si importants pour l'avenir du bitcoin?
Sep 24, 2025 pm 01:51 PM
Qu'est-ce que le bip? Pourquoi sont-ils si importants pour l'avenir du bitcoin?
Sep 24, 2025 pm 01:51 PM
Table des matières Qu'est-ce que la proposition d'amélioration du bitcoin (BIP)? Pourquoi le BIP est-il si important? Comment le processus BIP historique fonctionne-t-il pour la proposition d'amélioration du bitcoin (BIP)? Qu'est-ce qu'un signal de type BIP et comment un mineur l'envoie-t-il? La racine de racine et les inconvénients d'un essai rapide de la conclusion du BIP - des améliorations de Bitcoin ont été apportées depuis 2011 par le biais d'un système appelé Bitcoin Improvement Proposition ou «BIP». Bitcoin Improvement Proposition (BIP) fournit des lignes directrices sur la façon dont le bitcoin peut se développer en général, il existe trois types possibles de BIP, dont deux sont liés aux changements technologiques de Bitcoin chaque BIP commence par des discussions informelles parmi les développeurs de Bitcoin qui peuvent rassembler n'importe où, y compris TWI
 Des débutants aux experts: 10 sites Web de données publiques gratuites incontournables
Sep 15, 2025 pm 03:51 PM
Des débutants aux experts: 10 sites Web de données publiques gratuites incontournables
Sep 15, 2025 pm 03:51 PM
Pour les débutants en science des données, le cœur du saut de "l'inexpérience" à "l'expert de l'industrie" est une pratique continue. La base de la pratique est les ensembles de données riches et diversifiés. Heureusement, il existe un grand nombre de sites Web sur Internet qui offrent des ensembles de données publiques gratuits, qui sont des ressources précieuses pour améliorer les compétences et affiner vos compétences.
 Comment pouvez-vous créer un gestionnaire de contexte en utilisant le décorateur @contextManager dans Python?
Sep 20, 2025 am 04:50 AM
Comment pouvez-vous créer un gestionnaire de contexte en utilisant le décorateur @contextManager dans Python?
Sep 20, 2025 am 04:50 AM
Importer @ contextManagerfromContextLibandDeFineAgeneratorFonctionnement toTyieldSexactlyOnce, où les actes de championnalsAnterAndCodeLifteryiel
 Comment choisir un ordinateur adapté à l'analyse des mégadonnées? Guide de configuration pour l'informatique haute performance
Sep 15, 2025 pm 01:54 PM
Comment choisir un ordinateur adapté à l'analyse des mégadonnées? Guide de configuration pour l'informatique haute performance
Sep 15, 2025 pm 01:54 PM
L'analyse des mégadonnées doit se concentrer sur le CPU multi-core, la mémoire de grande capacité et le stockage à plusieurs niveaux. Les processeurs multi-core tels qu'AmDepyc ou RyzentHreadripper sont préférés, en tenant compte du nombre de cœurs et de performances monocomes; La mémoire est recommandée pour commencer avec 64 Go et la mémoire ECC est préférée pour assurer l'intégrité des données; Le stockage utilise NVMESSD (système et données chaudes), SATASSD (données communes) et disque dur (données froides) pour améliorer l'efficacité globale de traitement.
 Comment écrire des scripts d'automatisation pour les tâches quotidiennes dans Python
Sep 21, 2025 am 04:45 AM
Comment écrire des scripts d'automatisation pour les tâches quotidiennes dans Python
Sep 21, 2025 am 04:45 AM
Identifiez la répétitivetasksworthautomating, tels organisationfilesorSensemberSeMails, se concentrant sur le plan de la forme
