


Cohorte signifie littéralement un groupe de personnes (avec des caractéristiques communes ou des comportements similaires), tels que des sexes et des âges différents.
Analyse de cohorte : compare les changements dans des groupes similaires au fil du temps.
Le produit continuera à être itéré au fur et à mesure que vous le développerez et le testerez, ce qui amènera les utilisateurs qui rejoignent le produit au cours de la première semaine de sortie du produit et les utilisateurs qui le rejoignent plus tard à vivre des expériences différentes. Par exemple, chaque utilisateur passera par un cycle de vie : de l'essai gratuit à l'utilisation payante, pour finalement cesser de l'utiliser. Parallèlement, pendant cette période, vous ajustez constamment votre modèle économique. Par conséquent, les utilisateurs qui « mangent des crabes » au cours du premier mois suivant le lancement du produit vivront forcément une expérience d’intégration différente de celle des utilisateurs qui rejoignent le produit après quatre mois. Quel impact cela aura-t-il sur les taux de désabonnement ? Nous avons utilisé une analyse de cohorte pour le savoir.
Chaque groupe d'utilisateurs forme une cohorte et participe à l'ensemble du processus d'essai. En comparant différentes cohortes, vous pouvez savoir si les performances globales sur les indicateurs clés s'améliorent.
Combiné avec le niveau d'analyse des utilisateurs, comme les utilisateurs acquis au cours de différents mois, les nouveaux utilisateurs de différents canaux, les utilisateurs avec des caractéristiques différentes (comme les utilisateurs sur WeChat qui communiquent avec au moins 10 amis sur WeChat chaque jour).
Analyse de cohorte, analyse comparative de ces groupes de personnes aux caractéristiques différentes pour découvrir leurs différences comportementales dans la dimension temporelle.
Par conséquent, l'analyse de cohorte est principalement utilisée pour les deux points suivants :
Comparez les indicateurs de données du même cycle d'expérience de différents groupes de cohortes pour vérifier l'effet de l'optimisation itérative du produit
Comparez les différents cycles d'expérience ( durée de vie) du même groupe de cohorte Période) des indicateurs de données pour découvrir les problèmes d'expérience à long terme
Lorsque nous effectuons une analyse de cohorte, elle peut être grossièrement divisée en deux processus : déterminer le groupe de cohorte logique de regroupement et déterminer la clé indicateurs de données d'analyse de cohorte .
Groupes avec des caractéristiques comportementales similaires
Groupes avec la même période
Par exemple :
Par mois d'acquisition de clients (regroupés par semaine ou même par jour)
Par canal d'acquisition de clients
Classés en fonction d'actions spécifiques effectuées par les utilisateurs, telles que le nombre de fois que les utilisateurs visitent le site Web ou le nombre d'achats.
Concernant les indicateurs de données clés, ils doivent être basés sur la dimension temporelle, comme la rétention, le chiffre d'affaires, le coefficient d'auto-propagation, etc.
Ce qui suit est un exemple de cas utilisant le taux de rétention comme indicateur :
Ce qui suit sont les données d'exploitation d'une entreprise de commerce électronique. Nous utiliserons ces données pour démontrer l'analyse de cohorte à l'aide de Python.
Explication détaillée du cas d'analyse de cohorte :
Les données sont le journal de paiement d'un utilisateur de commerce électronique. Les champs du journal incluent la date, le montant du paiement et l'identifiant de l'utilisateur, qui ont été désensibilisés.
import pandas as pd df = pd.read_csv('日志.csv', encoding="gb18030") df.head()
Logique de groupe :
Ceci n'est regroupé qu'en fonction du mois d'achat initial de l'utilisateur. Si le journal contient plus de champs de classification (tels que le canal, le sexe ou l'âge, etc.) , vous pouvez envisager d'autres types de logique de regroupement.
Indicateurs de données clés :
Pour ces données, il existe au moins 3 indicateurs de données qui peuvent être analysés :
Taux de rétention
Montant du paiement par habitant
Nombre d'achats par habitant
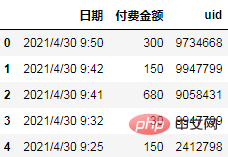
Parce que nous regroupons par mois, nous devons d'abord rééchantillonner les dates en mois :
df['购买月份'] = pd.to_datetime(df.日期).dt.to_period("M")
df.head()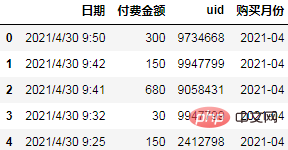
Calculez le paiement total pour chaque utilisateur pour chaque mois :
order = df.groupby(["uid", "购买月份"], as_index=False).agg(
月付费总额=("付费金额","sum"),
月付费次数=("uid","count"),
)
order.head()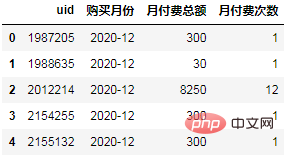
Calculez chaque utilisateur Le premier mois d'achat est utilisé comme le même groupe de périodes et mappé aux données d'origine :
order["首单月份"] = order.groupby("uid")['购买月份'].transform("min")
order.head()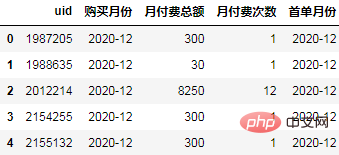
Calculez la différence mensuelle entre l'heure de chaque enregistrement d'achat et l'heure du premier achat, et réinitialisez l'étiquette de différence mensuelle :
order["标签"] = (order.购买月份-order.首单月份).apply(lambda x:"同期群人数" if x.n==0 else f"+{x.n}月")
order.head()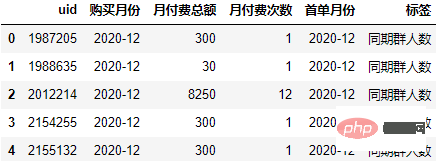
Les deux mois sont de type période. Après soustraction, une colonne de type objet est obtenue, et le type de chaque élément de cette colonne est pandas._libs.tslibs.offsets.MonthEnd
Le type MonthEnd a l'attribut n et peut renvoyer un entier de différence spécifique.
Nous avons dit plus tôt qu'il existe au moins 3 indicateurs de données qui peuvent être analysés :
Taux de rétention
Montant du paiement par habitant
Nombre d'achats par habitant
通过数据透视表可以一次性计算所需的数据:
cohort_number = order.pivot_table(index="首单月份", columns="标签",
values="uid", aggfunc="count",
fill_value=0).rename_axis(columns="留存率")
cohort_number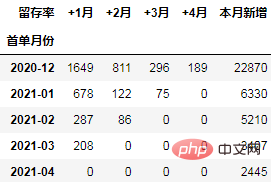
注意:rename_axis(columns=None)用于删除列标签的轴名称。rename_axis(columns=“留存率”)则设置轴名称为留存率。
将 本月新增 列移动到第一列:
cohort_number.insert(0, "同期群人数", cohort_number.pop("同期群人数"))
cohort_number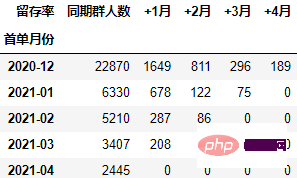
具体过程是先通过pop删除该列,然后插入到0位置,并命名为指定的列名。
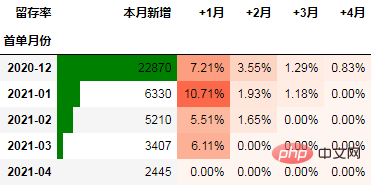
在本次的分析中,留存率的具体计算方式为:+N月留存率=+N月付款用户数/首月付款用户数
cohort_number.iloc[:, 1:] = cohort_number.iloc[:, 1:].divide(cohort_number.本月新增, axis=0) cohort_number
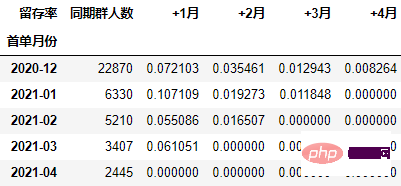
以百分比形式显示,并设置颜色:
out1 = (cohort_number.style
.format("{:.2%}", subset=cohort_number.columns[1:])
.bar(subset="同期群人数", color="green")
.background_gradient("Reds", subset=cohort_number.columns[1:], high=1, axis=None)
)
out1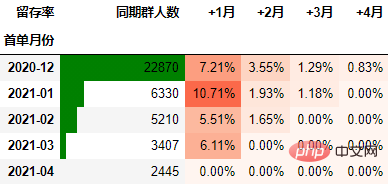
至此计算完毕。
要从从人均付款金额角度考虑,需要考虑同期群基期这个整体。具体计算方式是先计算各月的付款总额,然后除以基期的总人数:
cohort_amount = order.pivot_table(index="首单月份", columns="标签",
values="月付费总额", aggfunc="sum",
fill_value=0).rename_axis(columns="人均付款金额")
cohort_amount.insert(0, "首月人均付费", cohort_amount.pop("同期群人数"))
cohort_amount.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_amount.iloc[:, 1:] = cohort_amount.iloc[:, 1:].divide(cohort_amount.同期群人数, axis=0)
out2 = (cohort_amount.style
.format("{:.2f}", subset=cohort_amount.columns[1:])
.background_gradient("Reds", subset=cohort_amount.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
out2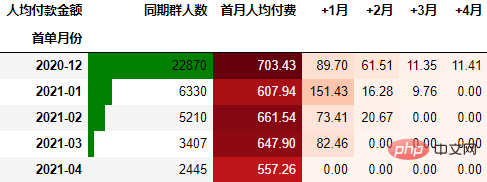
可以看到,12月份的同期群首月新用户人均消费为703.43元,然后逐月递减,到+4月后这些用户人均消费仅11.41元。而随着版本的迭代发展,新增用户的首月消费并没有较大提升,且接下来的消费趋势反而不如12月份。由此可见产品的发展受到了一定的瓶颈,需要思考增长营收的出路了。
一般来说, 通过同期群分析可以比较好指导我们后续更深入细致的数据分析,为产品优化提供参考。
依然按照上面一样的套路:
cohort_count = order.pivot_table(index="首单月份", columns="标签",
values="月付费次数", aggfunc="sum",
fill_value=0).rename_axis(columns="人均购买次数")
cohort_count.insert(0, "首月人均频次", cohort_count.pop("同期群人数"))
cohort_count.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_count.iloc[:, 1:] = cohort_count.iloc[:,
1:].divide(cohort_count.同期群人数, axis=0)
out3 = (cohort_count.style
.format("{:.2f}", subset=cohort_count.columns[1:])
.background_gradient("Reds", subset=cohort_count.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
out3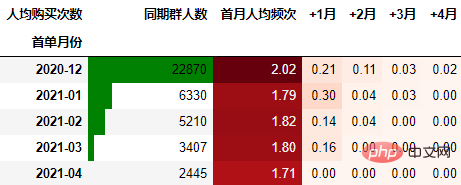
可以得到类似上述一致的结论。
下面我们看看每个月的总体消费情况:
order.groupby("购买月份").agg(
付费人数=("uid", "count"),
人均付款金额=("月付费总额", "mean"),
月付费总额=("月付费总额", "sum")
)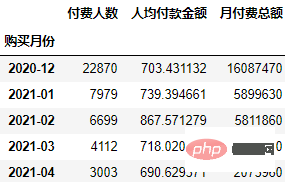
可以看到总体付费人数和付费金额都在逐月下降。
对于Styler类型,我们可以调用render方法转化为网页源代码,通过以下方式即可将其导入到一个网页文件中:
with open("out.html", "w") as f:
f.write(out1.render())
f.write(out2.render())
f.write(out3.render())如果你的电脑安装了谷歌游览器,还可以安装dataframe_image,将这个表格导出为图片。
安装:pip install dataframe_image
import dataframe_image as dfi dfi.export(obj=out1, filename='留存率.jpg') dfi.export(obj=out2, filename='人均付款金额.jpg') dfi.export(obj=out3, filename='人均购买次数.jpg')
dfi.export的参数:
obj : 被导出的Datafream对象
filename : 文件保存位置
fontsize : 字体大小
max_rows : 最大行数
max_cols : 最大列数
table_conversion : 使用谷歌游览器或原生’matplotlib’, 只要写非’chrome’的值就会使用原生’matplotlib’
chrome_path : 指定谷歌游览器位置
import pandas as pd
import dataframe_image as dfi
df = pd.read_csv('日志.csv', encoding="gb18030")
df['购买月份'] = pd.to_datetime(df.日期).dt.to_period("M")
order = df.groupby(["uid", "购买月份"], as_index=False).agg(
月付费总额=("付费金额", "sum"),
月付费次数=("uid", "count"),
)
order["首单月份"] = order.groupby("uid")['购买月份'].transform("min")
order["标签"] = (
order.购买月份-order.首单月份).apply(lambda x: "同期群人数" if x.n == 0 else f"+{x.n}月")
cohort_number = order.pivot_table(index="首单月份", columns="标签",
values="uid", aggfunc="count",
fill_value=0).rename_axis(columns="留存率")
cohort_number.insert(0, "同期群人数", cohort_number.pop("同期群人数"))
cohort_number.iloc[:, 1:] = cohort_number.iloc[:,1:].divide(cohort_number.同期群人数, axis=0)
out1 = (cohort_number.style
.format("{:.2%}", subset=cohort_number.columns[1:])
.bar(subset="同期群人数", color="green")
.background_gradient("Reds", subset=cohort_number.columns[1:], high=1, axis=None)
)
cohort_amount = order.pivot_table(index="首单月份", columns="标签",
values="月付费总额", aggfunc="sum",
fill_value=0).rename_axis(columns="人均付款金额")
cohort_amount.insert(0, "首月人均付费", cohort_amount.pop("同期群人数"))
cohort_amount.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_amount.iloc[:, 1:] = cohort_amount.iloc[:, 1:].divide(cohort_amount.同期群人数, axis=0)
out2 = (cohort_amount.style
.format("{:.2f}", subset=cohort_amount.columns[1:])
.background_gradient("Reds", subset=cohort_amount.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
cohort_count = order.pivot_table(index="首单月份", columns="标签",
values="月付费次数", aggfunc="sum",
fill_value=0).rename_axis(columns="人均购买次数")
cohort_count.insert(0, "首月人均频次", cohort_count.pop("同期群人数"))
cohort_count.insert(0, "同期群人数", cohort_number.同期群人数)
cohort_count.iloc[:, 1:] = cohort_count.iloc[:,
1:].divide(cohort_count.同期群人数, axis=0)
out3 = (cohort_count.style
.format("{:.2f}", subset=cohort_count.columns[1:])
.background_gradient("Reds", subset=cohort_count.columns[1:], axis=None)
.bar(subset="同期群人数", color="green")
)
outs = [out1, out2, out3]
with open("out.html", "w") as f:
for out in outs:
f.write(out.render())
display(out)
dfi.export(obj=out1, filename='留存率.jpg')
dfi.export(obj=out2, filename='人均付款金额.jpg')
dfi.export(obj=out3, filename='人均购买次数.jpg')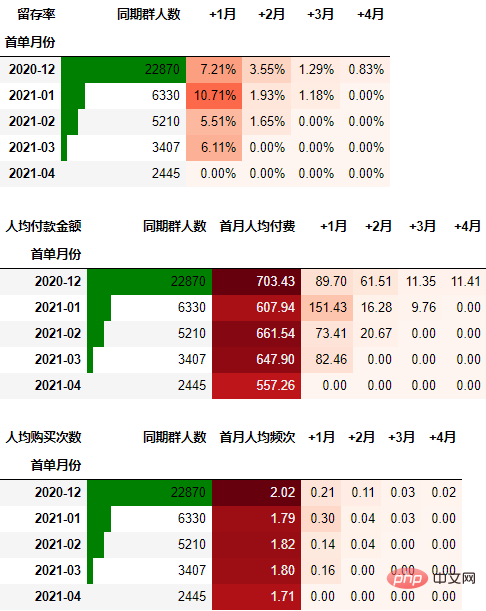
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!





























![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



