


À l’ère de l’information d’aujourd’hui, les images ou le contenu visuel sont depuis longtemps devenus le support d’informations le plus important dans la vie quotidienne. Les modèles d’apprentissage profond s’appuient sur leur forte capacité à comprendre le contenu visuel et peuvent y effectuer divers traitements et optimisations.
Cependant, lors du développement et de l'application passés de modèles visuels, nous avons accordé plus d'attention à l'optimisation du modèle lui-même pour améliorer sa vitesse et son effet. Au contraire, peu de réflexions sérieuses sont menées sur la manière d’optimiser les étapes de pré et post-traitement des images. Par conséquent, lorsque l'efficacité de calcul du modèle devient de plus en plus élevée, en regardant le pré-traitement et le post-traitement de l'image, je ne m'attendais pas à ce qu'ils deviennent le goulot d'étranglement de l'ensemble de la tâche d'image.
Afin de résoudre ces goulots d'étranglement, NVIDIA s'est associé à l'équipe d'apprentissage automatique de ByteDance pour ouvrir en source de nombreuses bibliothèques d'opérateurs de prétraitement d'images CV-CUDA. Elles peuvent fonctionner efficacement sur le GPU et la vitesse de l'opérateur peut atteindre environ cent fois celle de celle-ci. OpenCV (fonctionnant sur le CPU) . Si nous utilisons CV-CUDA comme backend pour remplacer OpenCV et TorchVision, le débit de l'inférence entière peut atteindre plus de 20 fois celui d'origine. De plus, non seulement la vitesse est améliorée, mais en termes d'effet, CV-CUDA a été aligné sur OpenCV en termes de précision de calcul, de sorte que la formation et l'inférence peuvent être connectées de manière transparente, réduisant considérablement la charge de travail des ingénieurs.
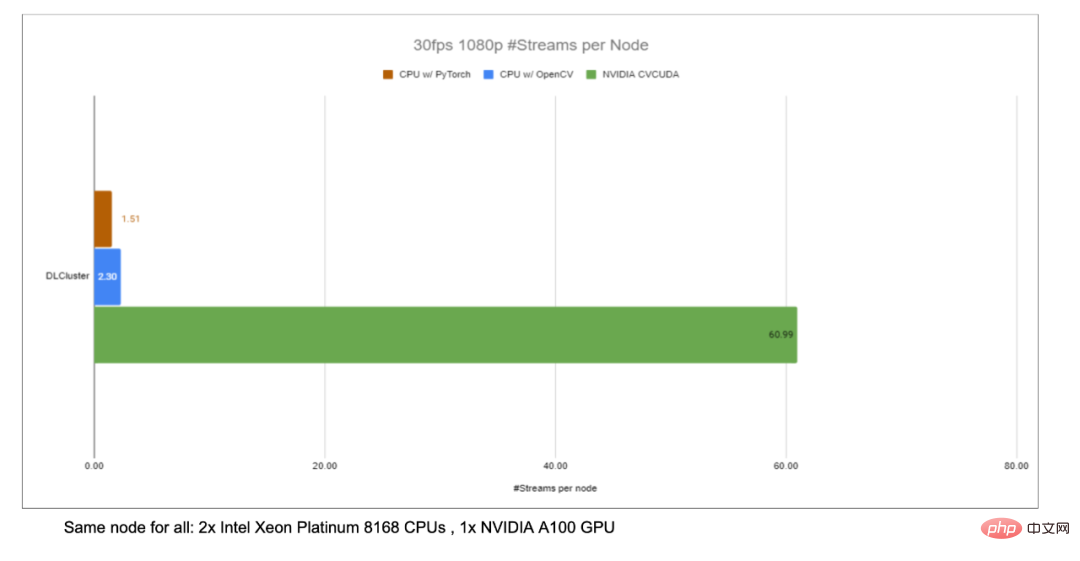
En prenant l'algorithme de flou d'arrière-plan de l'image comme exemple, en remplaçant OpenCV par CV-CUDA comme backend du pré/post-traitement de l'image, le débit de l'ensemble du processus d'inférence peut être augmenté de plus de 20 fois.
Si vous souhaitez essayer une bibliothèque de prétraitement visuel plus rapide et meilleure, vous pouvez essayer cet outil open source. Adresse Open source : https://github.com/CVCUDA/CV-CUDA
De nombreux ingénieurs en algorithmes impliqués dans l'ingénierie et produits savent que, bien que nous ne discutions souvent que de « recherches de pointe » telles que la structure du modèle et les tâches de formation, afin de réellement fabriquer un produit fiable, nous rencontrerons de nombreux problèmes d'ingénierie. Au contraire, la formation du modèle est la partie la plus simple.
Le prétraitement de l'image est un tel problème d'ingénierie. Nous pouvons simplement appeler certaines API pour effectuer une transformation géométrique, un filtrage, une transformation de couleur, etc. sur l'image lors d'expériences ou de formation, et nous ne nous en soucions pas particulièrement. Mais lorsque nous repensons l’ensemble du processus de raisonnement, nous constatons que le prétraitement des images est devenu un goulot d’étranglement en termes de performances, en particulier pour les tâches visuelles comportant des processus de prétraitement complexes.
Ces goulots d'étranglement en termes de performances se reflètent principalement dans le processeur. De manière générale, pour les processus de traitement d'image conventionnels, nous effectuerons d'abord un prétraitement sur le CPU, puis le placerons sur le GPU pour exécuter le modèle, et enfin retournerons au CPU, et nous devrons peut-être effectuer un post-traitement.
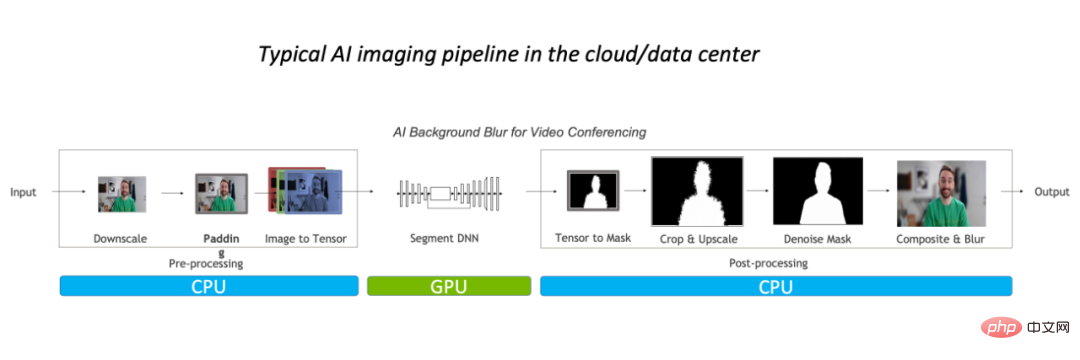
Prenons l'exemple de l'algorithme de flou d'arrière-plan de l'image. Dans le processus de traitement d'image conventionnel, le traitement pronostique est principalement effectué sur le processeur, représentant 90 % de la charge de travail globale, ce qui est devenu le goulot d'étranglement de. cette tâche.
Donc, pour les applications vidéo ou les scènes complexes telles que la modélisation d'images 3D, parce que le nombre d'images ou d'informations sur l'image est suffisamment grand, le processus de prétraitement est suffisamment complexe et le délai requis est suffisamment faible, optimisez le opérateur de pré/post-traitement C'est déjà imminent. Une meilleure approche, bien sûr, consiste à remplacer OpenCV par une solution plus rapide.
Pourquoi OpenCV n'est toujours pas assez bon ?
Dans CV, la bibliothèque de traitement d'image la plus utilisée est bien sûr OpenCV, maintenue depuis longtemps. Elle dispose d'une très large gamme d'opérations de traitement d'image et peut essentiellement répondre aux besoins de pré/post-traitement de diverses tâches visuelles. Cependant, à mesure que la charge de la tâche d'image augmente, sa vitesse n'est plus en mesure de suivre, car la plupart des opérations d'image d'OpenCV sont implémentées par le CPU, manquent d'implémentation GPU, ou il y a des problèmes avec l'implémentation GPU.
Dans l'expérience de recherche et développement des étudiants en algorithmie NVIDIA et ByteDance, ils ont découvert que les quelques opérateurs dans OpenCV implémentés par GPU ont trois problèmes majeurs :
Par exemple, l'exactitude des résultats ; du premier problème ne peut pas être aligné, NVIDIA et byte Les étudiants de l'algorithme de battement découvriront que lors de notre formation, un certain opérateur d'OpenCV utilise le CPU, mais en raison de problèmes de performances dans la phase d'inférence, l'opérateur GPU correspondant à OpenCV est utilisé à la place. Peut-être que la précision des résultats du CPU et du GPU ne peut pas être alignée, ce qui entraîne une inférence complète. Il y a une anomalie dans la précision du processus. Lorsqu'un tel problème survient, vous devez soit revenir à l'implémentation du processeur, soit consacrer beaucoup d'efforts pour réaligner la précision, ce qui est un problème difficile à résoudre.
Comme OpenCV n'est toujours pas assez performant, certains lecteurs peuvent se demander : qu'en est-il de Torchvision ? Il sera en fait confronté aux mêmes problèmes qu'OpenCV. De plus, les ingénieurs déployant des modèles sont plus susceptibles d'utiliser C++ pour implémenter le processus d'inférence pour plus d'efficacité. Par conséquent, ils ne pourront pas utiliser Torchvision et devront se tourner vers une telle bibliothèque visuelle C++. comme OpenCV Cela entraînera un autre dilemme : aligner la précision de Torchvision avec OpenCV.
En général, le pré/post-traitement actuel des tâches visuelles sur le CPU est devenu un goulot d'étranglement, mais les outils traditionnels tels qu'OpenCV ne peuvent pas bien le gérer. Par conséquent, la migration des opérations vers le GPU, une bibliothèque d'opérateurs de traitement d'image efficace CV-CUDA implémentée entièrement basée sur CUDA, est devenue une nouvelle solution.
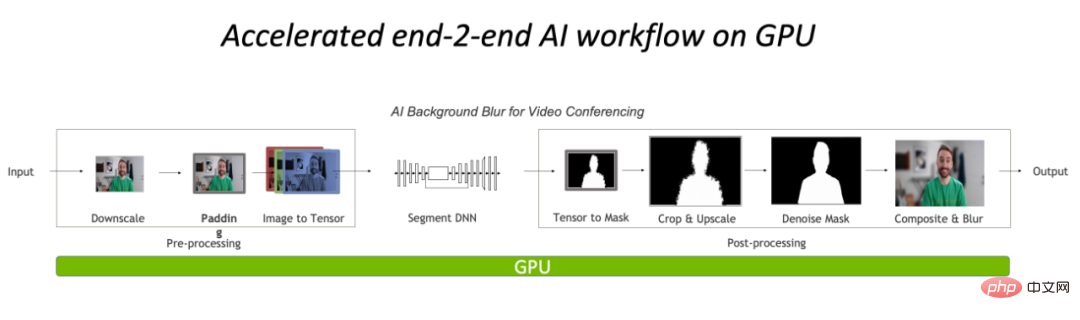
Pré-traitement et post-traitement complets sur le GPU, ce qui réduira considérablement le goulot d'étranglement du CPU dans la partie traitement d'image.
En tant que bibliothèque d'opérateurs de pré/post-traitement basée sur CUDA, les ingénieurs en algorithmes attendent peut-être trois choses avec impatience : assez rapide, assez polyvalent et suffisamment facile à utiliser. CV-CUDA, développé conjointement par NVIDIA et l'équipe d'apprentissage automatique de ByteDance, peut exactement répondre à ces trois points. Il utilise la puissance de calcul parallèle du GPU pour améliorer la vitesse de l'opérateur, aligne les résultats de fonctionnement d'OpenCV pour être suffisamment polyvalent et est facile à utiliser. avec l'interface C++/Python.
CV-CUDALa vitesse de
CV-CUDA se reflète d'abord dans la mise en œuvre efficace de l'opérateur. Après tout, il est écrit par NVIDIA Le code de calcul parallèle CUDA doit avoir subi une implémentation efficace. beaucoup d'optimisation. Deuxièmement, il prend en charge les opérations par lots, qui peuvent exploiter pleinement la puissance de calcul du périphérique GPU. Par rapport à l'exécution en série d'images sur le CPU, les opérations par lots sont nettement plus rapides. Enfin, grâce aux architectures GPU telles que Volta, Turing et Ampere auxquelles CV-CUDA est adapté, les performances sont hautement optimisées au niveau du noyau CUDA de chaque GPU pour obtenir les meilleurs résultats. En d’autres termes, plus la carte GPU que vous utilisez est performante, plus ses capacités d’accélération seront exagérées.
Comme le montre le tableau précédent du taux d'accélération du débit du flou d'arrière-plan, si CV-CUDA est utilisé pour remplacer le pré- et post-traitement d'OpenCV et de TorchVision, le débit de l'ensemble du processus d'inférence est augmenté de plus de 20 fois. Parmi eux, le prétraitement effectue des opérations telles que Resize, Padding et Image2Tensor sur l'image, et le post-traitement effectue des opérations telles que Tensor2Mask, Crop, Resize et Denoise sur les résultats de la prédiction.
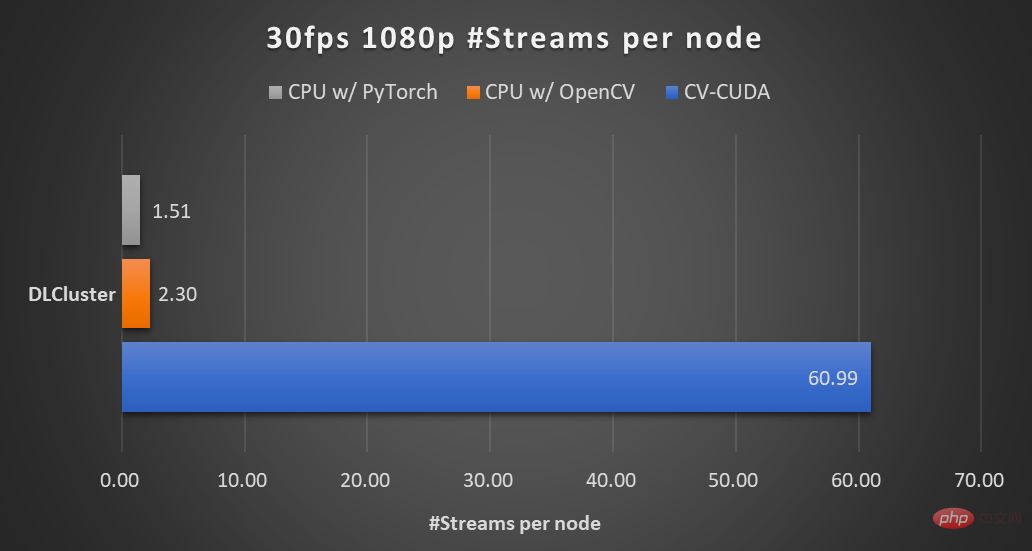
Traitement de vidéo 1080p à 30 ips sur le même nœud de calcul (2x processeurs Intel Xeon Platinum 8168, 1x GPU NVIDIA A100), en utilisant le parallélisme maximal pris en charge par différentes bibliothèques CV Numéro de flux. Le test a utilisé 4 processus, chaque processus batchSize étant de 64. Pour les performances d'un seul opérateur, les partenaires de NVIDIA et ByteDance ont également effectué des tests de performances. Le débit de nombreux opérateurs sur le GPU peut atteindre cent fois celui du CPU.
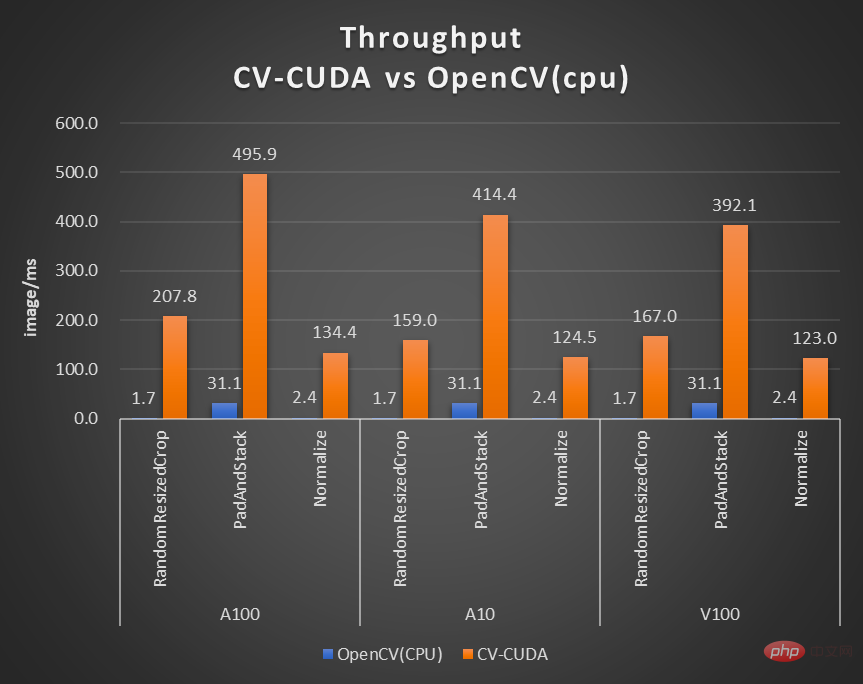
La taille de l'image est de 480*360, la sélection du processeur est Intel(R) Core(TM) i9-7900X, la taille du lot est de 1 et le nombre de processus est de 1
Bien que de nombreux pré/ les opérateurs de post-traitement ne le sont pas. Afin d'obtenir les performances efficaces mentionnées ci-dessus pour les multiplications matricielles simples et d'autres opérations, CV-CUDA a en fait effectué de nombreuses optimisations au niveau des opérateurs. Par exemple, un grand nombre de stratégies de fusion de noyau sont adoptées pour réduire le temps d'accès au lancement du noyau et l'accès à la mémoire globale est optimisé pour améliorer l'efficacité de la lecture et de l'écriture des données, tous les opérateurs sont traités de manière asynchrone pour réduire le temps d'attente synchrone, etc. . La polyvalence et la flexibilité de
CV-CUDA
La stabilité des résultats de calcul est trop importante pour les projets réels, tels que les opérations de redimensionnement courantes, OpenCV, OpenCV-gpu et Torchvision La mise en œuvre les méthodes sont différentes, donc de la formation au déploiement, il y aura beaucoup plus de travail pour aligner les résultats.
Au début de la conception de CV-CUDA, on considérait que de nombreux ingénieurs étaient habitués à utiliser la version CPU d'OpenCV dans la bibliothèque de traitement d'image actuelle. Par conséquent, lors de la conception d'opérateurs, qu'il s'agisse de paramètres de fonction ou de résultats de traitement d'image, alignez autant que possible la version du CPU OpenCV opérateur. Par conséquent, lors de la migration d'OpenCV vers CV-CUDA, seules quelques modifications sont nécessaires pour obtenir des résultats de calcul cohérents, et le modèle n'a pas besoin d'être recyclé.
De plus, CV-CUDA est conçu au niveau de l'opérateur, donc quel que soit le processus de pré/post-traitement du modèle, il peut être librement combiné et offre une grande flexibilité.
L'équipe d'apprentissage automatique de ByteDance a déclaré qu'il existe de nombreux modèles formés au sein de l'entreprise et que la logique de prétraitement requise est également diversifiée, avec de nombreuses exigences logiques de prétraitement personnalisées. La flexibilité de CV-CUDA peut garantir que chaque OP prend en charge l'arrivée d'objets de flux et d'objets de mémoire vidéo (classes Buffer et Tensor, qui stockent les pointeurs de mémoire vidéo en interne), afin que les ressources GPU correspondantes puissent être configurées de manière plus flexible. Lors de la conception et du développement de chaque opération, il prend non seulement en compte la polyvalence, mais fournit également des interfaces personnalisées à la demande, couvrant divers besoins en matière de prétraitement d'image.
CV-CUDAFacile à utiliser
Peut-être que de nombreux ingénieurs penseront que CV-CUDA implique l'opérateur CUDA sous-jacent, il devrait donc être plus difficile à utiliser ? Mais ce n'est pas le cas, même si elle ne s'appuie pas sur des API de niveau supérieur, la couche inférieure de CV-CUDA fournira elle-même des structures telles que la classe Allocator, il n'est donc pas difficile de l'ajuster en C++. De plus, au niveau supérieur, CV-CUDA fournit des interfaces de conversion de données pour PyTorch, OpenCV et Pillow, afin que les ingénieurs puissent rapidement remplacer et appeler les opérateurs de manière familière.
De plus, étant donné que CV-CUDA possède à la fois une interface C++ et une interface Python, il peut être utilisé à la fois dans des scénarios de formation et de déploiement de services. L'interface Python est utilisée pour vérifier rapidement les capacités du modèle pendant la formation, et l'interface C++ est utilisée pour. des prédictions plus efficaces lors du déploiement. CV-CUDA évite le processus fastidieux d’alignement des résultats de prétraitement et améliore l’efficacité du processus global.
Interface C++ de CV-CUDA pour le redimensionnement
Si nous utilisons CV-CUDA Python pendant l'interface du processus de formation, En fait, il sera très simple à utiliser. Il suffit de quelques étapes simples pour migrer toutes les opérations de prétraitement initialement sur le CPU vers le GPU.
Prenons l'exemple de la classification des images, lors de la phase de prétraitement, nous devons décoder l'image en un tenseur et la recadrer pour l'adapter à la taille d'entrée du modèle. Après le recadrage, nous devons convertir la valeur du pixel en un type de données à virgule flottante. et effectuer la normalisation. Une fois transformé, il peut ensuite être transmis au modèle d'apprentissage profond pour une propagation vers l'avant. Ci-dessous, nous utiliserons quelques blocs de code simples pour découvrir comment CV-CUDA prétraite les images et interagit avec Pytorch.

Le processus de pré-traitement de la reconnaissance d'image conventionnelle, utilisant CV-CUDA, unifiera le processus de pré-traitement et le calcul du modèle sur le GPU.
Comme suit, après avoir utilisé l'API torchvision pour charger l'image sur le GPU, le type Torch Tensor peut être directement converti en l'objet CV-CUDA nvcvInputTensor via as_tensor, afin que l'API de l'opération de prétraitement CV-CUDA puisse être directement appelé pour compléter le traitement de l'image dans les différentes transformations du GPU.
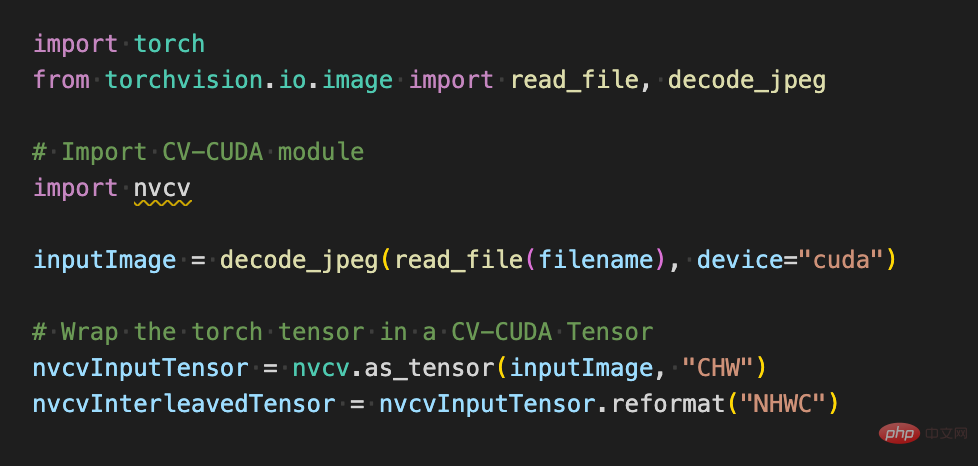
Les lignes de code suivantes utiliseront CV-CUDA pour terminer le processus de prétraitement de reconnaissance d'image dans le GPU : recadrer l'image et normaliser les pixels. Parmi eux, resize() convertit le tenseur de l'image en taille du tenseur d'entrée du modèle ; convertto() convertit la valeur du pixel en une valeur à virgule flottante simple précision ; normalize() normalise la valeur du pixel pour rendre la plage de valeurs plus adaptée ; le modèle.
L'utilisation de diverses opérations de prétraitement dans CV-CUDA ne sera pas très différente de celles d'OpenCV ou de Torchvision. Il s'agit simplement d'un simple ajustement de la méthode, et les calculs sont déjà effectués sur le GPU derrière.
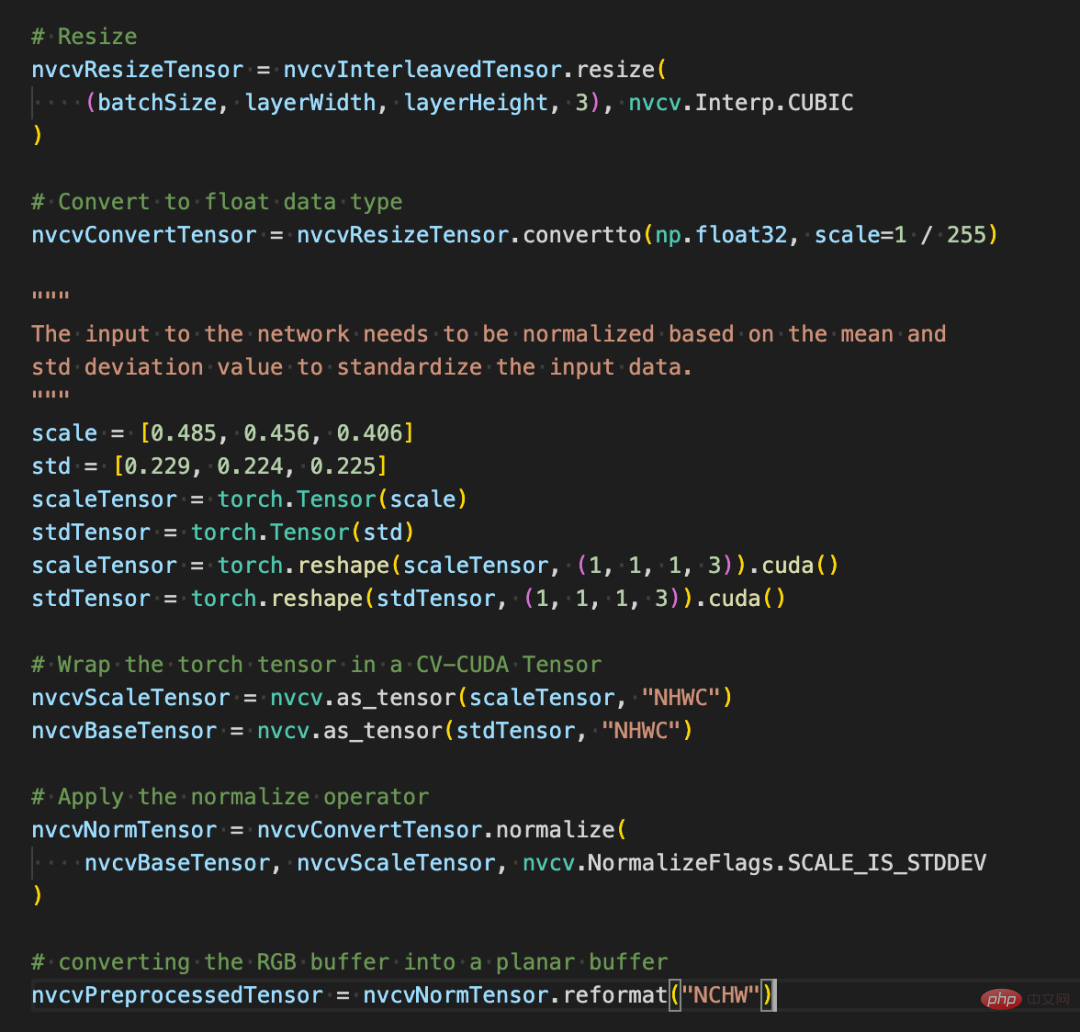
Maintenant, avec l'aide de diverses API de CV-CUDA, le prétraitement de la tâche de classification d'images a été terminé, ce qui peut effectuer efficacement le calcul parallèle sur le GPU et être facilement intégré dans PyTorch. processus de modélisation des cadres traditionnels d’apprentissage profond. Pour le reste, il vous suffit de convertir l'objet CV-CUDA nvcvPreprocessedTensor en type Torch Tensor pour le transmettre au modèle. Cette étape est également très simple. La conversion ne nécessite qu'une seule ligne de code :
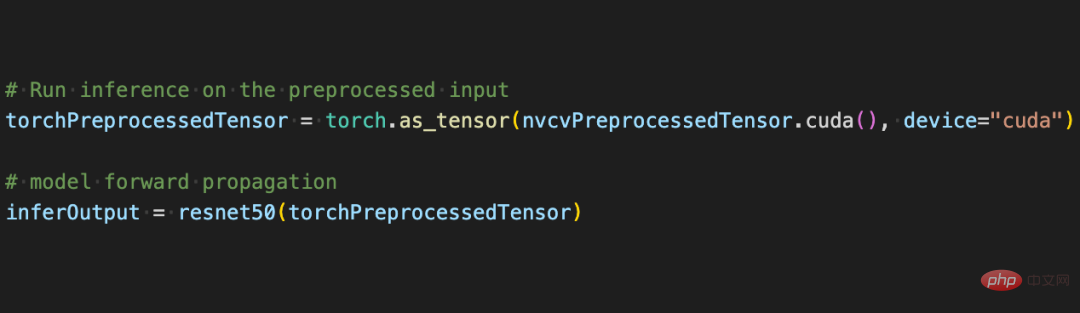
. Grâce à cet exemple simple, il est facile de constater que CV-CUDA s'intègre en effet facilement dans la logique normale de formation de modèles. Si les lecteurs souhaitent en savoir plus sur l'utilisation, ils peuvent toujours vérifier l'adresse open source de CV-CUDA mentionnée ci-dessus.
CV-CUDA a en fait été testé dans des affaires réelles. Dans les tâches visuelles, en particulier les tâches comportant des processus de prétraitement d'image relativement complexes, l'utilisation de l'énorme puissance de calcul du GPU pour le prétraitement peut améliorer efficacement l'efficacité de la formation et de l'inférence des modèles. CV-CUDA est actuellement utilisé dans plusieurs scénarios en ligne et hors ligne au sein du groupe Douyin, tels que la recherche multimodale, la classification d'images, etc.
L'équipe d'apprentissage automatique de ByteDance a déclaré que l'utilisation interne de CV-CUDA peut améliorer considérablement les performances de formation et d'inférence. Par exemple, en termes de formation, Bytedance est une tâche multimodale liée à la vidéo. La partie pré-traitement comprend le décodage de vidéos multi-images et de nombreuses améliorations de données, ce qui rend cette partie de la logique très compliquée. La logique de prétraitement complexe empêche les performances multicœurs du processeur de suivre pendant l'entraînement. Par conséquent, CV-CUDA est utilisé pour migrer toute la logique de prétraitement du processeur vers le GPU, obtenant ainsi une accélération de 90 % de la vitesse globale d'entraînement. . Notez qu'il s'agit d'une augmentation de la vitesse globale d'entraînement, pas seulement dans la partie prétraitement.
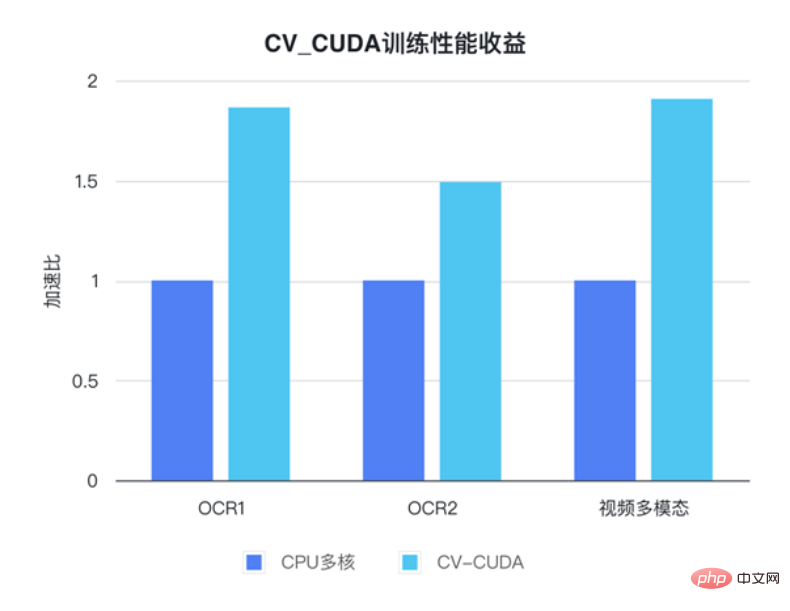
Dans les tâches multimodales Bytedance OCR et vidéo, en utilisant CV-CUDA, la vitesse globale d'entraînement peut être augmentée de 1 à 2 fois (remarque : il s'agit d'une augmentation de la vitesse globale d'entraînement de le modèle)
La même chose est vraie dans le processus d'inférence. L'équipe d'apprentissage automatique de ByteDance a déclaré qu'après avoir utilisé CV-CUDA dans une tâche de recherche multimodale, le débit global en ligne était 2 fois plus élevé que lors de l'utilisation du CPU. pour le prétraitement. Beaucoup d’amélioration. Il convient de noter que les résultats de base du processeur ici sont déjà hautement optimisés pour le multicœur et que la logique de prétraitement impliquée dans cette tâche est relativement simple, mais l'effet d'accélération est toujours très évident après l'utilisation de CV-CUDA.
Il est suffisamment efficace en termes de vitesse pour éliminer le goulot d'étranglement du prétraitement dans les tâches visuelles, et il est également simple et flexible à utiliser. CV-CUDA a prouvé qu'il peut considérablement améliorer le raisonnement des modèles et les effets de formation dans des scénarios d'application réels. donc si les tâches visuelles des lecteurs sont également limitées par l'efficacité du prétraitement, alors essayez le dernier CV-CUDA open source.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



