


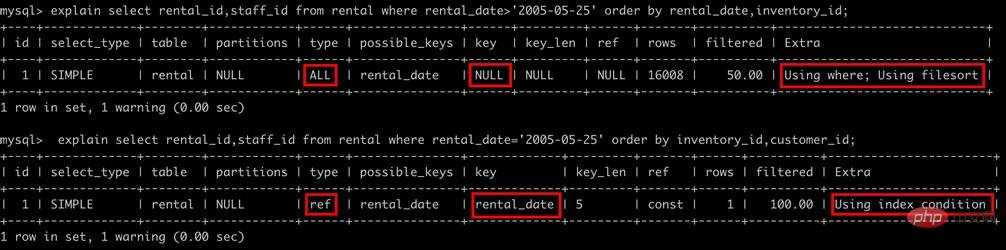
Dans MySQL, lors de la recherche de données, recherchez d'abord la valeur correspondante dans l'index, puis recherchez la ligne de données correspondante en fonction de l'enregistrement d'index correspondant si vous le souhaitez. exécutez l'instruction de requête suivante :
SELECT * FROM USER WHERE uid = 5;
S'il existe un index construit sur l'uid, MySQL utilisera l'index pour trouver d'abord la ligne avec l'uid 5, ce qui signifie que MySQL recherchera d'abord par valeur sur l'index, puis renverra toutes les données lignes contenant cette valeur.
Les index MySQL sont implémentés au niveau du moteur de stockage, pas sur le serveur. Par conséquent, il n’existe pas de norme d’indexation unifiée : les index des différents moteurs de stockage fonctionnent différemment.
La plupart des moteurs MySQL prennent en charge cet index B-Tree Même si plusieurs moteurs de stockage prennent en charge le même type d'index, leur implémentation sous-jacente peut être différente. Par exemple, InnoDB utilise B+Tree.
Les moteurs de stockage implémentent B-Tree de différentes manières, avec des performances et des avantages différents. Par exemple, MyISAM utilise la technologie de compression de préfixe pour réduire la taille des index, tandis qu'InnoDB stocke les données selon le format de données d'origine. Les index MyISAM font référence aux lignes indexées en fonction de l'emplacement physique des données, tandis qu'InnoDB applique les lignes indexées en fonction du composant. .
Toutes les valeurs de B-Tree sont stockées séquentiellement et la distance entre chaque page feuille et la racine est la même. La figure ci-dessous reflète approximativement le fonctionnement de l'index InnoDB. La structure utilisée par MyISAM est différente. Mais la mise en œuvre de base est similaire.
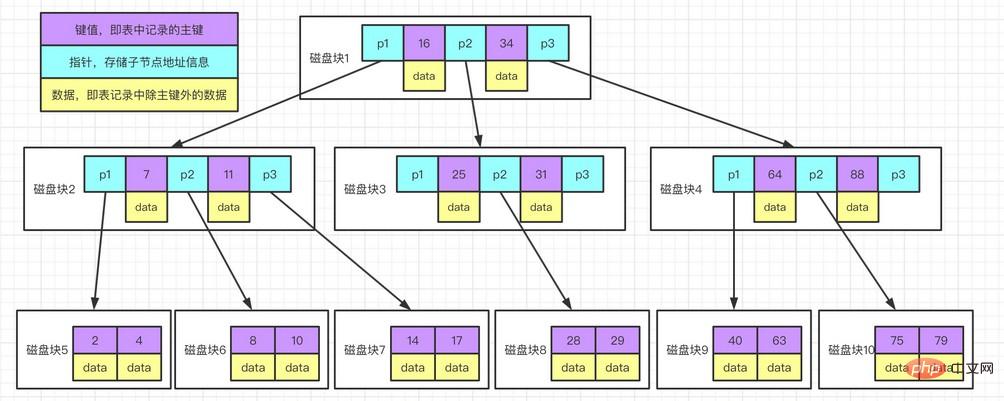
Explication du diagramme d'exemple :
Chaque nœud occupe un bloc de disque. Il y a deux clés de tri ascendant sur un nœud et trois pointeurs vers le nœud racine du sous-arbre. Les pointeurs stockent le bloc de disque où se trouve le nœud enfant. se trouve l'adresse. Les trois champs range divisés par les deux mots-clés correspondent aux champs range des données du sous-arbre pointé par les trois pointeurs. En prenant le nœud racine comme exemple, les mots-clés sont 16 et 34, la plage de données du sous-arbre pointé par le pointeur P1 est inférieure à 16, la plage de données du sous-arbre pointé par le pointeur P2 est de 16 à 34 et les données La plage du sous-arbre pointé par le pointeur P3 est supérieure à 34. Processus de recherche par mot clé :
Trouvez le bloc de disque 1 en fonction du nœud racine et lisez-le en mémoire. [Opération E/S disque 1ère fois]
Comparez le mot-clé 28 Dans l'intervalle (16,34), recherchez le pointeur P2 du bloc disque 1.
Trouvez le bloc de disque 3 en fonction du pointeur P2 et lisez-le en mémoire. [Opération d'E/S disque 2ème fois]
Comparez le mot-clé 28 Dans l'intervalle (25,31), recherchez le pointeur P2 du bloc disque 3.
Trouvez le bloc de disque 8 basé sur le pointeur P2 et lisez-le en mémoire. [Opération d'E/S disque 3ème fois]
Mot-clé 28 trouvé dans la liste de mots-clés du bloc de disque 8.
Inconvénients :
Chaque nœud possède une clé et contient également des données, et l'espace de stockage de chaque page est limité si les données sont relativement volumineuses, le nombre de clés stockées dans chaque nœud deviendra plus petit. . ;
Lorsque la quantité de données stockées est importante, cela entraînera une grande profondeur, augmentera le nombre d'E/S disque pendant la requête et affectera ainsi les performances de la requête.
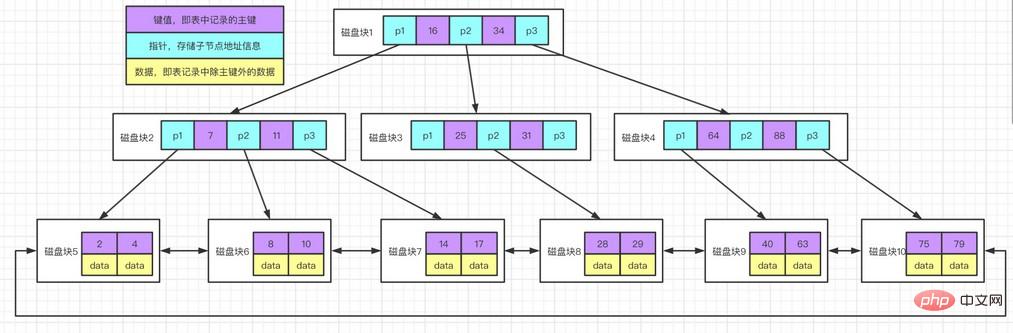
L'arbre B+ est une variante du B-tree. Différence avec l'arbre B : l'arbre B+ stocke uniquement les données dans les nœuds feuilles, et les nœuds non-feuilles ne stockent que les valeurs clés et les pointeurs.
Il y a deux pointeurs sur l'arbre B+, l'un pointe vers le nœud feuille racine et l'autre pointe vers le nœud feuille avec le plus petit mot-clé, et il y a une structure en anneau entre tous les nœuds feuille (c'est-à-dire les nœuds de données), donc B+ peut L'arborescence effectue deux opérations de recherche : l'une est une recherche par plage de composants et l'autre est une recherche aléatoire à partir du nœud racine.
L'arbre B* est similaire au nombre B+. La différence est que le nombre B* a également une structure en anneau de chaîne entre les nœuds non-feuilles.
L'index de hachage est implémenté sur la base d'une table de hachage Seules les requêtes qui correspondent avec précision à toutes les colonnes de l'index sont valides. Pour chaque ligne de données, le moteur de stockage calculera un code de hachage pour toutes les colonnes d'index. Le code de hachage est une valeur plus petite et les codes de hachage calculés pour les lignes avec des valeurs de clé différentes sont également différents. Un index de hachage stocke tous les codes de hachage dans l'index et un pointeur vers chaque ligne de données de la table de hachage.
Dans MySQL, seul le type d'index par défaut de Memory est l'index de hachage, et la mémoire prend également en charge les index B-Tree. Dans le même temps, le moteur de mémoire prend en charge les index de hachage non uniques. Si les valeurs de hachage de plusieurs colonnes sont identiques, l'index stockera plusieurs pointeurs dans la même entrée de hachage dans une liste chaînée. Similaire à HashMap.
Avantages :
L'index lui-même n'a besoin que de stocker la valeur de hachage correspondante, la structure de l'index est donc très compacte et la vitesse de recherche de hachage est très rapide.
Inconvénients :
Si vous utilisez le stockage de hachage, vous devez ajouter tous les fichiers de données à la mémoire, ce qui consomme plus d'espace mémoire ;
Les données d'index de hachage ne sont pas stockées dans l'ordre, elles ne peuvent donc pas être utilisées ; pour le tri ;
Si toutes les requêtes sont des requêtes équivalentes, alors le hachage est en effet très rapide, mais dans une entreprise ou un environnement de travail réel, il y a plus de données à rechercher dans une plage plutôt que dans des requêtes équivalentes, donc le hachage n'est pas approprié ;
S'il y a de nombreux conflits de hachage, le coût des opérations de maintenance de l'index sera également très élevé. C'est aussi le problème des conflits de hachage résolus par l'ajout d'arbres rouge-noir dans la phase ultérieure de HashMap
n'est pas un type d'index distinct, mais une méthode de stockage de données dans le moteur de stockage InnoDB, l'index clusterisé enregistre en fait les valeurs clés et les lignes de données dans le. même structure. Lorsqu'une table possède un index clusterisé, ses lignes de données sont en fait stockées dans les pages feuilles de l'index. Étant donné que les lignes de données ne peuvent pas être stockées simultanément à différents endroits, il ne peut y avoir qu'un seul index clusterisé dans une table (la couverture d'index peut simuler la situation de plusieurs index clusterisés).
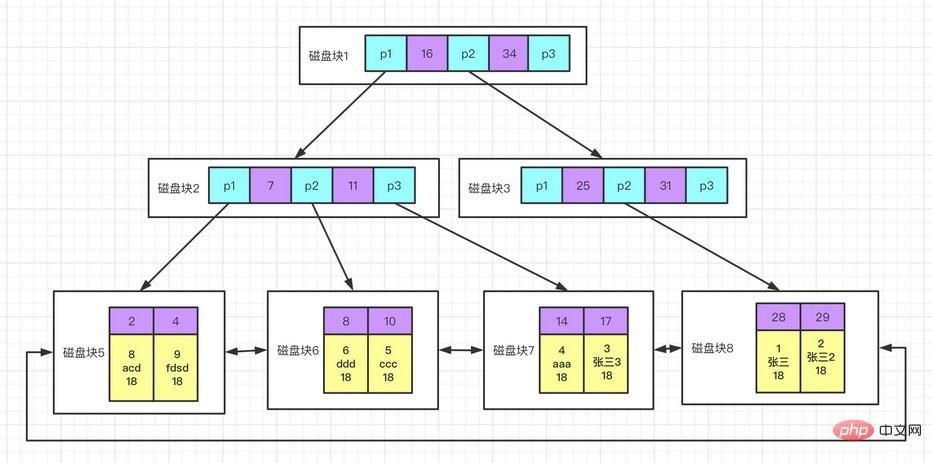
Avantages de l'index clusterisé :
peut enregistrer les données associées ensemble ; l'accès aux données est plus rapide car l'index et les données sont enregistrés dans la même arborescence ; les requêtes utilisant l'analyse d'index de couverture peuvent utiliser directement la valeur clé du nœud de la page principale ;
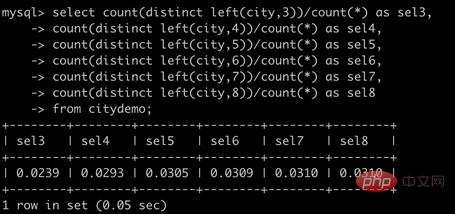
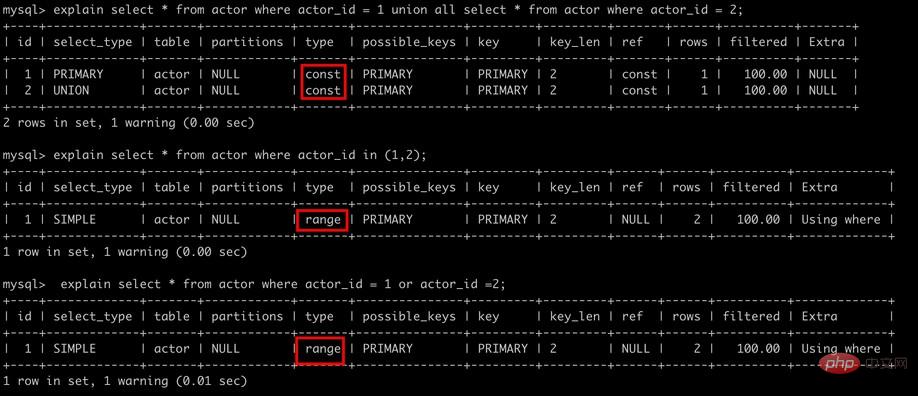
Inconvénients : Les données clusterisées maximisent les performances des applications gourmandes en E/S. Si les données sont toutes en mémoire, alors l'index clusterisé n'a aucun avantage ; la vitesse d'insertion dépend fortement de l'ordre d'insertion, selon la clé primaire. L'insertion séquentielle est. le moyen le plus rapide ; la mise à jour des colonnes d'index clusterisé est coûteuse car elle oblige chaque ligne mise à jour à se déplacer vers un nouvel emplacement ; les tables basées sur des index clusterisés peuvent causer des problèmes lorsque de nouvelles lignes sont insérées ou que la clé primaire est mise à jour. vous pouvez être confronté au problème des fractionnements de pages ; les index clusterisés peuvent ralentir les analyses de tables complètes, en particulier lorsque les lignes sont clairsemées, ou que le stockage des données est discontinu en raison des fractionnements de pages Index non clusterisé Les fichiers de données et les fichiers d'index sont stocké séparément2.2 Index de préfixeParfois, il est nécessaire d'indexer des chaînes très longues, ce qui rendra l'index volumineux et lent. Habituellement, vous pouvez utiliser une partie de la chaîne au début d'une colonne, ce qui économise considérablement de l'espace d'indexation. améliorant ainsi l'efficacité de l'index, mais cela réduira la sélectivité de l'index. La sélectivité de l'index fait référence : au rapport des valeurs d'index uniques (également appelées cardinalité) au nombre total d'enregistrements de la table de données, allant de 1/# entre T et 1. Plus la sélectivité de l'index est élevée, plus l'efficacité des requêtes est élevée, car un index plus sélectif permet à MySQL de filtrer davantage de lignes lors de la recherche. Généralement, la sélectivité d'un certain préfixe de colonne est suffisamment élevée pour répondre aux performances de la requête. Cependant, pour les colonnes de types BLOB, TEXT et VARCHAR, des index de préfixe doivent être utilisés car MySQL ne permet pas d'indexer toute la longueur de. ces colonnes. , l'astuce de cette méthode est de choisir un préfixe suffisamment long pour garantir une sélectivité élevée, mais pas trop long. ExempleStructure de table et téléchargement de données depuis le site officiel de MySQL ou GitHub. Colonnes du tableau de la villecountry_id
Country ID
| Heure de création ou de dernière mise à jour | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
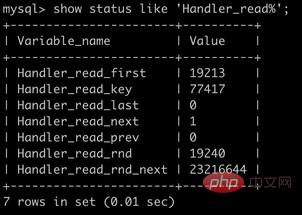
| 参数 | 说明 |
|---|---|
| Handler_read_first | 读取索引第一个条目的次数 |
| Handler_read_key | 通过index获取数据的次数 |
| Handler_read_last | 读取索引最后一个条目的次数 |
| Handler_read_next | 通过索引读取下一条数据的次数 |
| Handler_read_prev | 通过索引读取上一条数据的次数 |
| Handler_read_rnd | 从固定位置读取数据的次数 |
| Handler_read_rnd_next | 从数据节点读取下一条数据的次数 |
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



