



最近ChatGPT大火,boss也蠢蠢欲动要求我们把ChatGPT接入飞书,经过一上午的研究,终于注册成功并且实现了飞书机器人对接到ChatGPT。
下面给大家分享一下接入飞书的详细步骤。
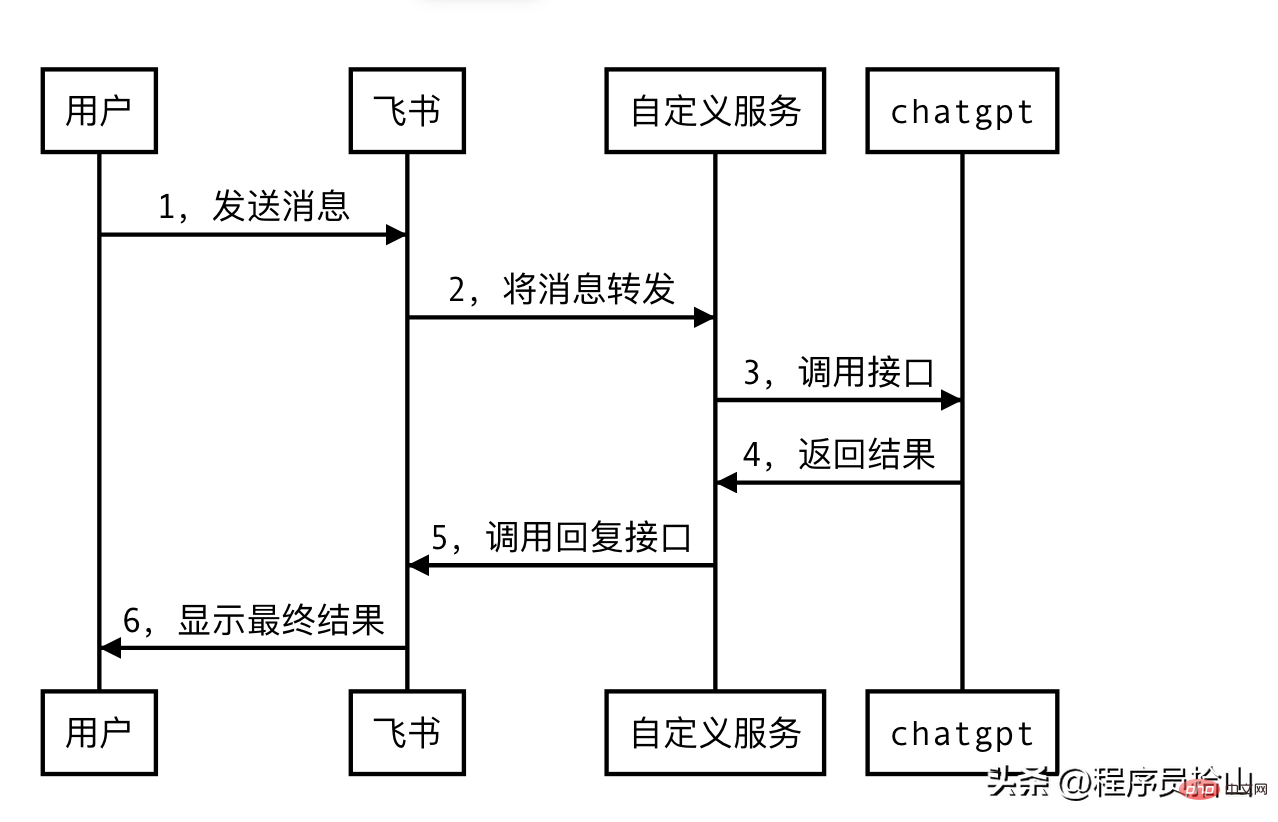
飞书与chatgpt的交互如下,我们的自定义服务就是充当一个中间人的角色,进行消息的转发。
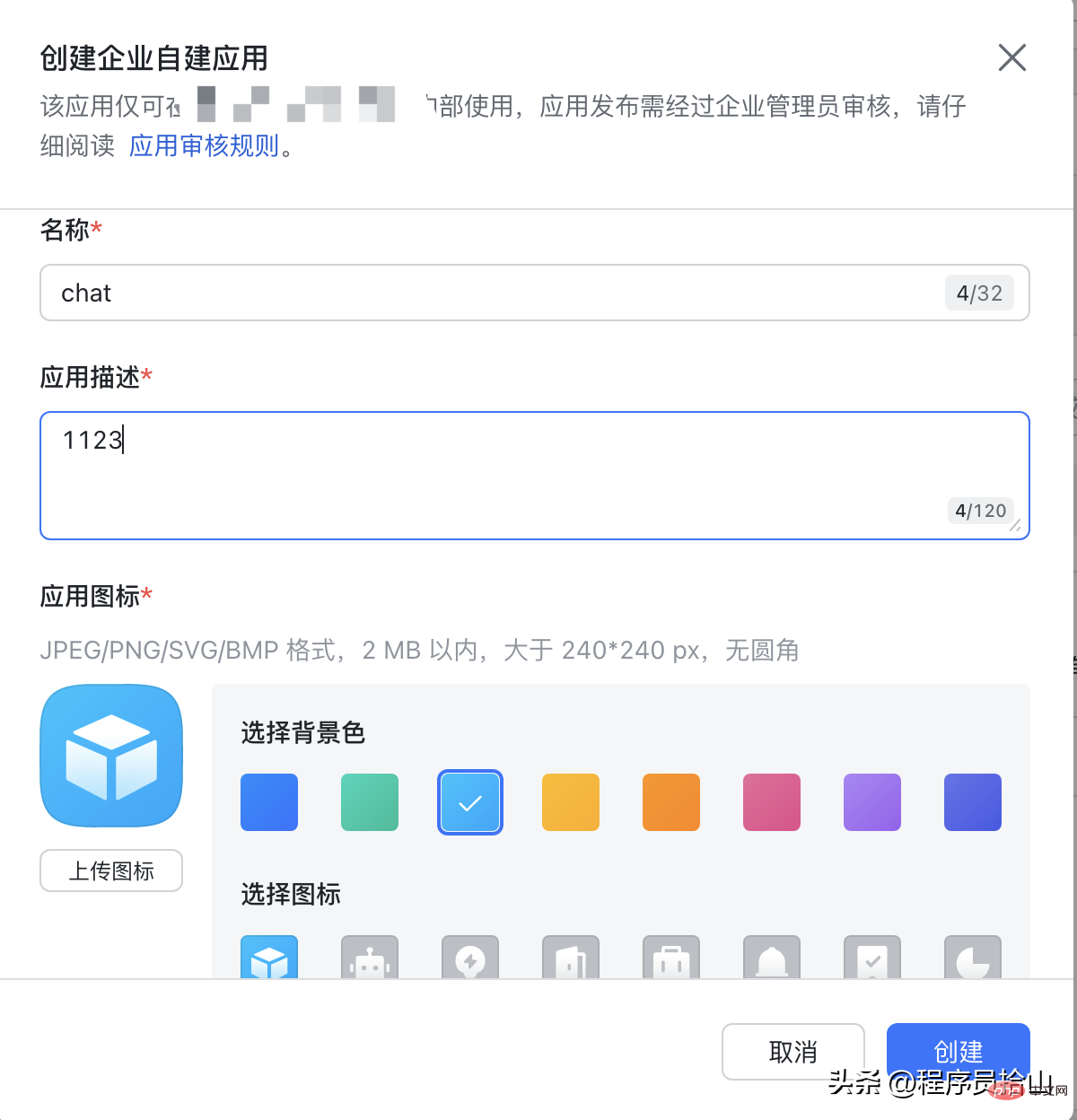
1,进入飞书开放平台,选择创建企业自建应用。
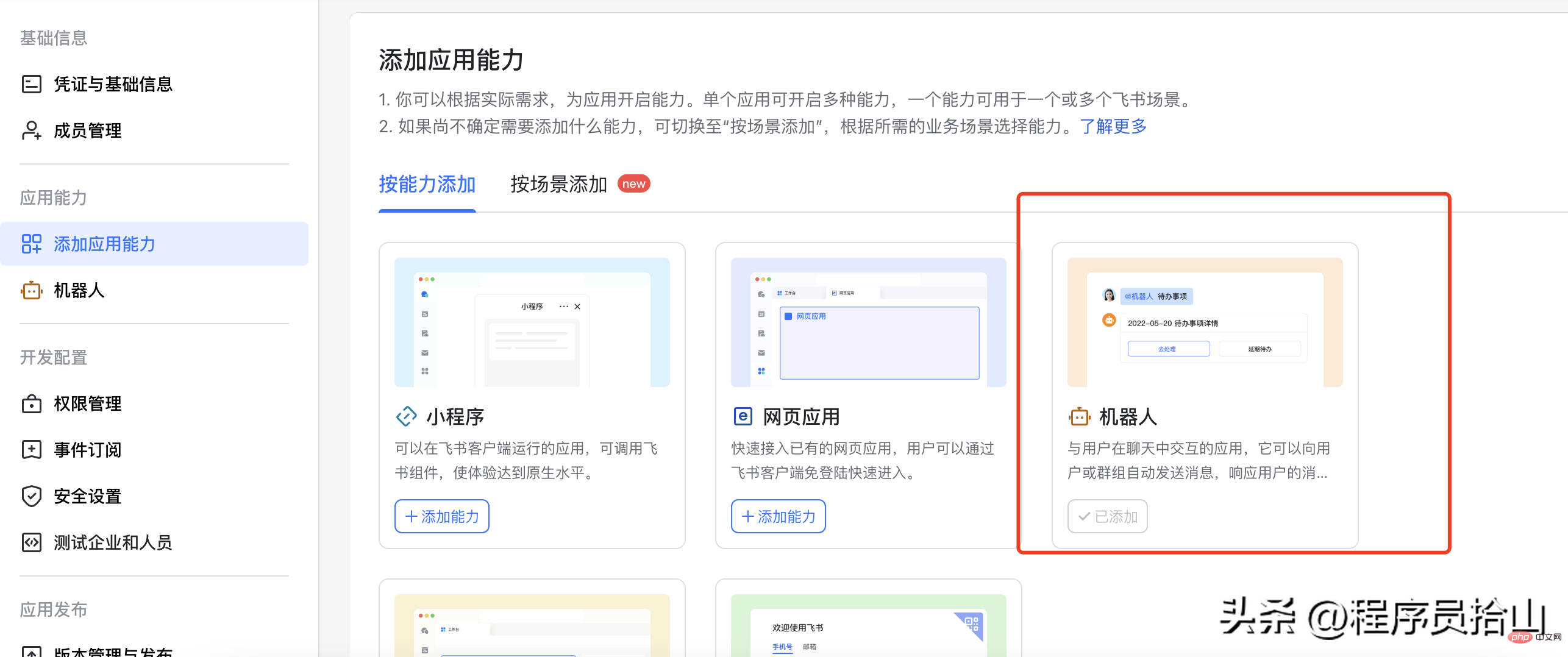
2,创建完应用以后,点击进入应用,添加机器人。
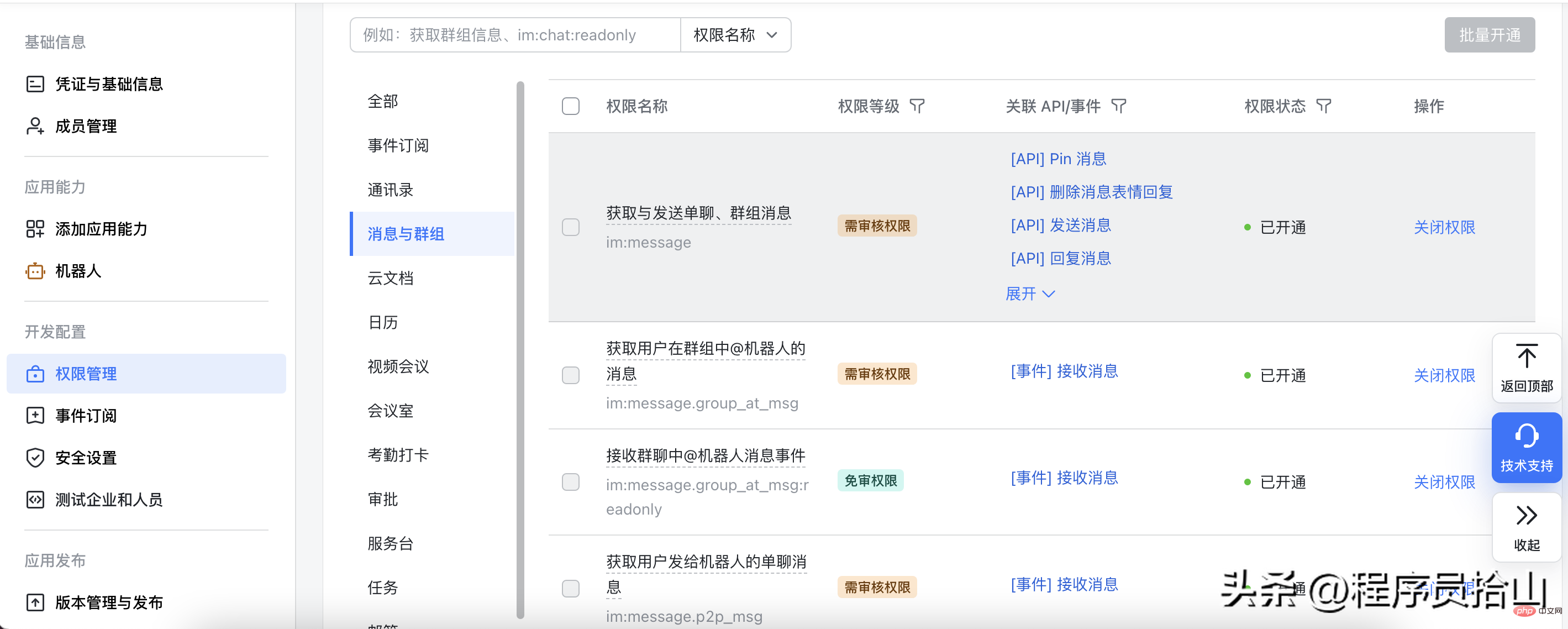
3,给机器人配置消息相关的权限,如果不确定需要什么权限,可以先全部开通。
4,配置事件订阅。事件订阅需要先开发一个接口供飞书验证。接口需要可以公网访问。
这个接口的代码可以参考如下:
@PostMapping(value = "/message") public FeishuEventDTO message(@RequestBody String body) { log.info("收到消息:{}", body); FeishuEventParams feishuEventParams = JSON.parseObject(body, FeishuEventParams.class); FeishuEventDTO eventDTO = new FeishuEventDTO(); eventDTO.setChallenge(feishuEventParams.getChallenge()); return eventDTO; } @Data public class FeishuEventParams { private String challenge; private String token; private String type; } @Data public class FeishuEventDTO { private String challenge; }
有一点需要注意的是,这个校验接口和下面接收飞书消息的接口是同一个地址,但是消息体不一样。
也就是说校验接口是一次性的,校验完之后需要对这个接口进行改造。
我们先将这个接口发布到一个可以公网访问的项目中,比如接口地址是
//m.sbmmt.com/link/4aee31b0ec9f7bb7885473d95961e9a6
OK,到这里飞书的配置基本搞定了,下面就是我们需要进行处理的逻辑了。
先说一下我司对接的大致逻辑,供大家参考。
用户发送消息到飞书之后,飞书会将消息转发到我们自己的服务上。
但是这里会存在一个问题,就是当多个用户并发发起会话时,或者一个大群里很多人都在@我们的机器人时,我们需要记住每一个人的回话,在chatgpt查询到结果后,准确的回复这个人。
由于我司目前也是用于内部测试不想实现太复杂,所以我们采用的思路是:每一个用户的会话转发到我们的服务上时,先将会话内容保存到一个全局的ConcurrentLinkedQueue队列中,然后启动一个线程,不停的消费这个队列。
队列的泛型是一个提前构造好的对象,这个对象保存着当前消息的消息id,发送人,提问内容等。
每消费一个对象,就将对象的提问内容发送到chatgpt,获取响应结果以后,调用飞书提供的会话回复接口去回复用户。(如果并发量比较大,这里可以搞成异步的)。
好了,大致思路就说到这,我们看一下具体的代码。
1,打开我们的项目,引入chatgpt提供的jar。
com.theokanning.openai-gpt3-java service 0.10.0
2,重写上面的校验接口,改造成接收飞书消息。(接口路径不要变)
@Slf4j @RestController @RequestMapping(value = "/query") public class QureyController { public static ConcurrentLinkedQueue consumer = new ConcurrentLinkedQueue<>(); @PostMapping(value = "/message") public String message(@RequestBody String body) { log.info("收到飞书消息:{}", body); JSONObject jsonObject = JSONObject.parseObject(body); JSONObject header = jsonObject.getJSONObject("header"); String eventType = header.getString("event_type"); if ("im.message.receive_v1".equals(eventType)) { JSONObject event = jsonObject.getJSONObject("event"); JSONObject message = event.getJSONObject("message"); String messageType = message.getString("message_type"); if ("text".equals(messageType)) { String messageId = message.getString("message_id"); String content = message.getString("content"); JSONObject contentJson = JSON.parseObject(content); String text = contentJson.getString("text"); FeishuResponse feishuResponse = new FeishuResponse(); feishuResponse.setMessageId(messageId); feishuResponse.setQuery(text); log.info("投递用户消息,{}", JSON.toJSON(feishuResponse)); consumer.add(feishuResponse); } else { log.info("非文本消息"); } } return "suc"; } }
FeishuResponse的结构如下。
@Data public class FeishuResponse { private String messageId; private String query; }
3,写一个任务线程。
@Slf4j public class AutoSendTask implements Runnable { //你的chatgpt的key public static final String token = ""; public static OpenAiService openAiService = null; static { openAiService = new OpenAiService(token, Duration.ofSeconds(60)); } @Override public void run() { while (true) { try { FeishuResponse poll = consumer.poll(); if (poll == null) { log.info("no query,sleep 2s"); TimeUnit.SECONDS.sleep(2); } else { String query = this.query(poll.getQuery()); this.reply(poll, query); } } catch (InterruptedException e) { log.error("Thread exception...", e); } } } private String query(String q) { log.info("开始提问:{}", q); CompletionRequest completionRequest = CompletionRequest.builder() .prompt(q) .model("text-davinci-003") .maxTokens(2048) .echo(false) .build(); StringBuilder sb = new StringBuilder(); CompletionResult completion = openAiService.createCompletion(completionRequest); log.info("q:{},获取响应:{}", q, JSON.toJSONString(completion)); completion.getChoices().forEach(v -> { sb.append(v.getText()); }); String rs = sb.toString(); if (rs.startsWith("?")) { rs = rs.replaceFirst("?", ""); } if (rs.startsWith("nn")) { rs = rs.replaceFirst("nn", ""); } log.info("格式化后的rs:{}", rs); return rs; } private String reply(FeishuResponse poll, String rs) { JSONObject params = new JSONObject(); params.put("uuid", RandomUtil.randomNumbers(10)); params.put("msg_type", "text"); JSONObject content = new JSONObject(); content.put("text", rs); params.put("content", content.toJSONString()); String url = String.format("https://open.feishu.cn/open-apis/im/v1/messages/%s/reply", poll.getMessageId()); String tenantAccessToken = FeishuUtils.getTenantAccessToken(); String body = null; try (HttpResponse authorization = HttpUtil.createPost(url) .header("Authorization", "Bearer " + tenantAccessToken) .body(params.toJSONString()) .execute()) { body = authorization.body(); } return body; } }
获取飞书token的工具类如下:
@Slf4j public class FeishuUtils { public static final String tokenUrl = "https://open.feishu.cn/open-apis/auth/v3/app_access_token/internal/"; //构建一个cache 缓存飞书的token static Cache tokenCache = CacheBuilder.newBuilder().expireAfterWrite(Duration.ofSeconds(3500)).build(); //这个是飞书应用的appid和key,可以在创建的飞书应用中找到 public static final String appId = ""; public static final String appKey = ""; public static String getTenantAccessToken() { String token = null; try { token = tokenCache.get("token", () -> { JSONObject params = new JSONObject(); params.put("app_id", appId); params.put("app_secret", appKey); String body; try (HttpResponse execute = HttpUtil.createPost(tokenUrl) .body(params.toJSONString()).execute()) { body = execute.body(); } log.info("获取飞书token:{}", body); if (StrUtil.isNotBlank(body)) { String tenantAccessToken = JSON.parseObject(body).getString("tenant_access_token"); tokenCache.put("token", tenantAccessToken); return tenantAccessToken; } return null; }); } catch (ExecutionException e) { throw new RuntimeException(e); } return token; } }
4,启动线程类即可。

最后,出于隐私,chatgpt群会话的效果就不展示了,展示一下直接对话机器人的效果吧。
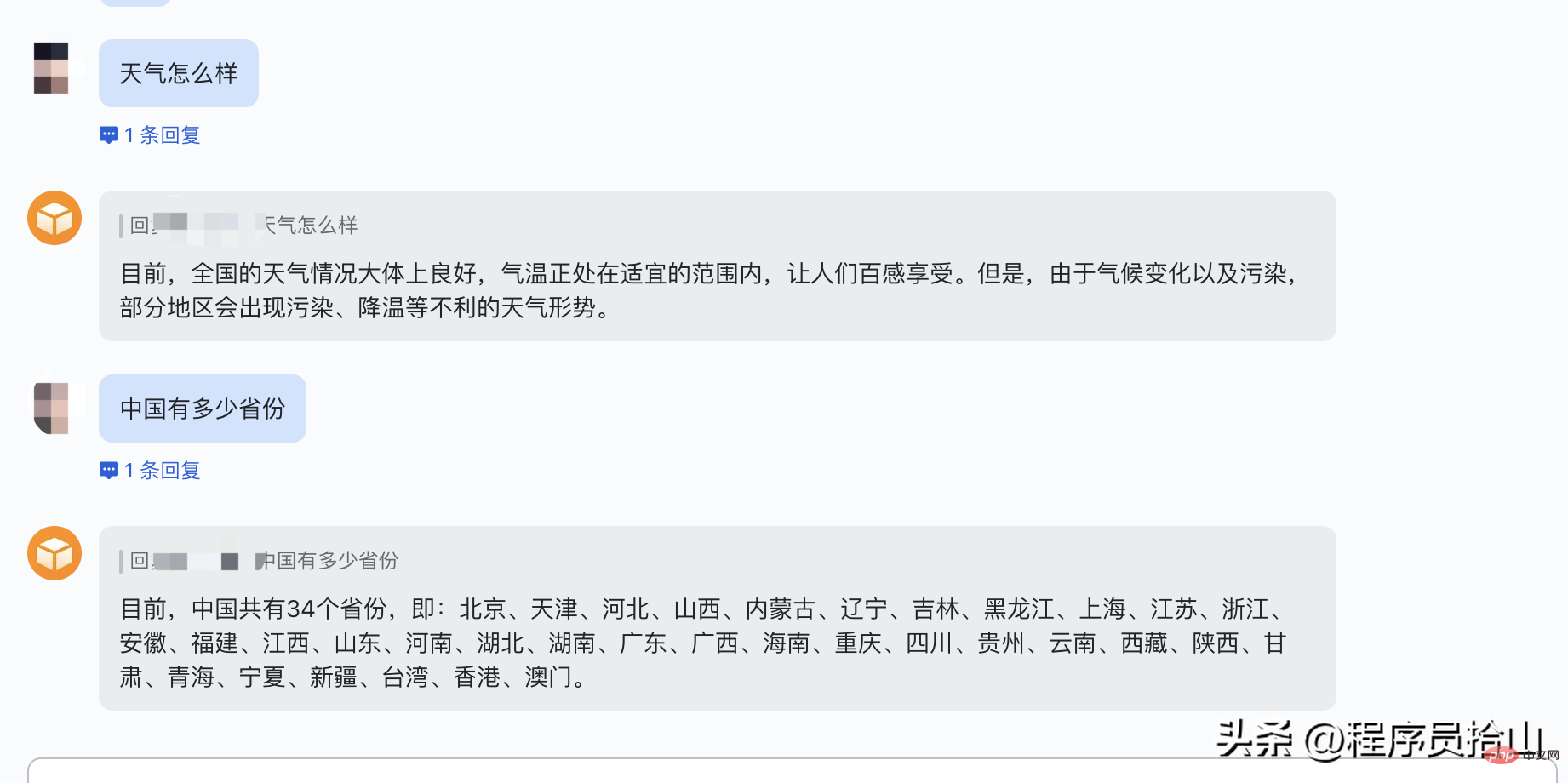
由于我们引入chatgpt也只是抱着尝试的态度,所以代码相对也比较粗糙,如果有哪里写的不好的地方,还望大家海涵。
文中代码还额外引入的jar有:guava、hutool-all、fastjson。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Inscription ChatGPT
Inscription ChatGPT Encyclopédie ChatGPT nationale gratuite
Encyclopédie ChatGPT nationale gratuite Comment installer chatgpt sur un téléphone mobile
Comment installer chatgpt sur un téléphone mobile Chatgpt peut-il être utilisé en Chine ?
Chatgpt peut-il être utilisé en Chine ? Quelle est la différence entre passer par valeur et passer par référence en Java
Quelle est la différence entre passer par valeur et passer par référence en Java Erreur de connexion au serveur d'identifiant Apple
Erreur de connexion au serveur d'identifiant Apple Pourquoi Webstorm ne peut pas exécuter le fichier
Pourquoi Webstorm ne peut pas exécuter le fichier Comment fermer la bibliothèque de ressources d'application
Comment fermer la bibliothèque de ressources d'application




















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



