


La science des données et l’apprentissage automatique deviennent de plus en plus populaires.
Le nombre de personnes entrant dans ce domaine augmente chaque jour.
Cela signifie que de nombreux data scientists n'ont pas une vaste expérience lors de la création de leur premier modèle d'apprentissage automatique, il est donc facile de commettre des erreurs.
Voici quelques-unes des erreurs les plus courantes des débutants dans les solutions d'apprentissage automatique.

Ne pas utiliser la normalisation des données lorsque cela est nécessaire
Pour les débutants, cela peut sembler une évidence de mettre des fonctionnalités dans un modèle et d'attendre qu'il donne des prédictions.
Mais dans certains cas, les résultats peuvent être décevants car vous avez raté une étape très importante.

Certains types de modèles nécessitent une normalisation des données, notamment la régression linéaire, les réseaux de neurones classiques, etc. Ces types de modèles utilisent des valeurs de caractéristiques multipliées par des poids entraînés. Si les caractéristiques ne sont pas normalisées, il peut arriver que la plage de valeurs possibles pour une caractéristique soit très différente de la plage de valeurs possibles pour une autre caractéristique.
Supposons que la valeur d'une caractéristique soit comprise dans la plage [0, 0,001] et que la valeur de l'autre caractéristique soit comprise dans la plage [100 000, 200 000]. Pour un modèle où deux fonctionnalités sont d'égale importance, le poids de la première fonctionnalité sera 100'000'000 fois le poids de la deuxième fonctionnalité. Des poids énormes peuvent causer de sérieux problèmes au modèle. Par exemple, il existe des valeurs aberrantes.
De plus, estimer l'importance de diverses caractéristiques peut devenir très difficile car un poids élevé peut signifier que la caractéristique est importante, ou simplement signifier qu'elle a une petite valeur.
Et après normalisation, toutes les caractéristiques sont dans la même plage de valeurs, généralement [0, 1] ou [-1, 1]. Dans ce cas, les pondérations seront dans une fourchette similaire et correspondront étroitement à la véritable importance de chaque caractéristique.
Dans l'ensemble, l'utilisation de la normalisation des données lorsque cela est nécessaire produira des prédictions meilleures et plus précises.
Certaines personnes peuvent penser que plus vous ajoutez de fonctionnalités, mieux c'est, de sorte que le modèle sélectionnera et utilisera automatiquement les meilleures fonctionnalités.
En pratique, ce n'est pas le cas. Dans la plupart des cas, un modèle doté de fonctionnalités soigneusement conçues et sélectionnées surpassera considérablement un modèle similaire doté de 10 fois plus de fonctionnalités.
Plus le modèle possède de fonctionnalités, plus le risque de surapprentissage est grand. Même dans des données complètement aléatoires, le modèle est capable de détecter certains signaux, parfois plus faibles, parfois plus forts.

Bien sûr, il n'y a pas de véritable signal dans le bruit aléatoire. Cependant, si nous disposons de suffisamment de colonnes de bruit, il est possible que le modèle en utilise certaines en fonction du signal d’erreur détecté. Lorsque cela se produit, la qualité des prédictions du modèle diminue car elles reposent en partie sur du bruit aléatoire.
Il est vrai qu'il existe diverses techniques de sélection de fonctionnalités qui peuvent aider dans ce cas. Mais cet article n’en parle pas.
N'oubliez pas que la chose la plus importante est que vous devez être capable d'expliquer chaque fonctionnalité dont vous disposez et de comprendre pourquoi cette fonctionnalité aidera votre modèle.
La principale raison pour laquelle les modèles d'arbres sont populaires n'est pas seulement en raison de leur solidité, mais aussi parce qu'ils sont faciles à utiliser.

Cependant, ce n'est pas toujours éprouvé. Dans certains cas, l’utilisation d’un modèle arborescent peut s’avérer une erreur.
Le modèle arborescent n'a aucune capacité d'inférence. Ces modèles ne donneront jamais une valeur prédite supérieure à la valeur maximale observée dans les données d'entraînement. Ils ne génèrent jamais non plus de prédictions inférieures au minimum de formation.
Mais dans certaines tâches, la capacité d'extrapolation peut jouer un rôle majeur. Par exemple, si ce modèle est utilisé pour prédire les cours des actions, il est possible que les futurs cours des actions soient plus élevés que jamais. Dans ce cas donc, les modèles arborescents ne seront plus adaptés car leurs prévisions se limiteront à des niveaux proches des prix les plus élevés de tous les temps.
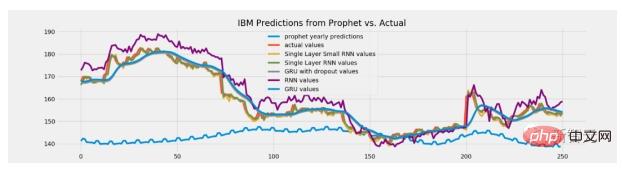

Alors comment résoudre ce problème ?
En fait, tous les chemins mènent à Rome !
Une option consiste à prédire les changements ou les différences au lieu de prédire directement les valeurs.
Une autre solution consiste à utiliser un type de modèle différent pour de telles tâches, comme la régression linéaire ou les réseaux de neurones capables d'extrapolation.
Tout le monde doit être conscient de l'importance de la normalisation des données. Cependant, différentes tâches nécessitent différentes méthodes de normalisation. Si vous appuyez sur le mauvais type, vous perdrez plus que vous ne gagnerez !

Les modèles basés sur des arbres ne nécessitent pas de normalisation des données car les valeurs brutes des fonctionnalités ne sont pas utilisées comme multiplicateurs et les valeurs aberrantes ne les affectent pas.
Les réseaux de neurones peuvent également ne pas nécessiter de normalisation - par exemple, si le réseau contient déjà des couches qui gèrent la normalisation en interne (comme la BatchNormalization de la bibliothèque Keras).

Dans certains cas, la régression linéaire peut également ne pas nécessiter de normalisation des données. Cela signifie que toutes les caractéristiques se situent dans une plage de valeurs similaire et ont la même signification. Par exemple, si le modèle est appliqué à des données de séries chronologiques et que toutes les caractéristiques sont des valeurs historiques du même paramètre.
En pratique, appliquer une normalisation inutile des données ne nuit pas nécessairement au modèle. La plupart du temps, les résultats dans ces cas seront très similaires à ceux d’une normalisation ignorée. Cependant, effectuer des transformations de données supplémentaires inutiles complique la solution et augmente le risque d'introduire certaines erreurs.
Alors, que vous l'utilisiez ou non, la pratique vous dira la vérité !
La violation de données est plus facile qu'on ne le pense.
Veuillez consulter l'extrait de code suivant :

En fait, les deux fonctionnalités "sum_feature" et "diff_feature" sont incorrectes.
Il s'agit de "fuites" d'informations car après avoir été divisées en ensembles d'entraînement/test, la partie contenant les données d'entraînement contiendra certaines informations des lignes de test. Même si cela entraînera de meilleurs résultats de validation, lorsqu’il sera appliqué à des modèles de données réels, les performances chuteront.
La bonne approche est de faire d'abord une répartition train/test. Ce n'est qu'alors que la fonction de génération de fonctionnalités est appliquée. D'une manière générale, c'est un bon modèle d'ingénierie de fonctionnalités de traiter séparément l'ensemble de formation et l'ensemble de test.
Dans certains cas, certaines informations doivent être transmises entre les deux - par exemple, nous pourrions souhaiter que l'ensemble de test utilise le même StandardScaler que celui utilisé pour l'ensemble de formation et qui a été formé sur celui-ci. Mais il ne s’agit que d’un cas individuel, nous devons donc encore analyser des problèmes spécifiques en détail !

C'est bien d'apprendre de ses erreurs. Mais il est préférable d’apprendre des erreurs des autres – j’espère que les exemples d’erreurs fournis dans cet article vous aideront.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelle est la valeur de retour de la fonction
Quelle est la valeur de retour de la fonction
 point de symbole spécial
point de symbole spécial
 Méthodes de chiffrement courantes pour le stockage de données chiffrées
Méthodes de chiffrement courantes pour le stockage de données chiffrées
 Introduction aux commandes pour créer de nouveaux fichiers sous Linux
Introduction aux commandes pour créer de nouveaux fichiers sous Linux
 Les dernières nouvelles officielles d'aujourd'hui concernant PaiCoin sont vraies
Les dernières nouvelles officielles d'aujourd'hui concernant PaiCoin sont vraies
 le bios ne peut pas détecter le disque SSD
le bios ne peut pas détecter le disque SSD
 emplacement.recherche
emplacement.recherche
 Barre oblique du tableau Excel divisée en deux
Barre oblique du tableau Excel divisée en deux








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



