


Les algorithmes d'apprentissage automatique n'acceptent que les entrées numériques, donc si nous rencontrons des caractéristiques catégorielles, nous coderons les caractéristiques catégorielles. Cet article résume 11 méthodes courantes d'encodage de variables catégorielles.

La méthode d'encodage la plus populaire et la plus couramment utilisée est One Hot Enoding. Une unique variable à n observations et d valeurs distinctes est convertie en d variables binaires à n observations, chaque variable binaire est identifiée par un bit (0, 1).
Par exemple :
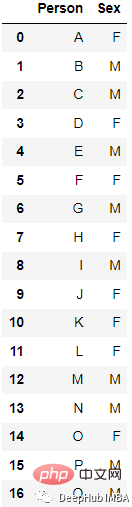
Après l'encodage

L'implémentation la plus simple consiste à utiliser les get_dummies
new_df=pd.get_dummies(columns=[‘Sex’], data=df)
Attribuez un entier d'identification unique à la variable de données catégorielle. Cette méthode est très simple, mais peut poser des problèmes pour les variables catégorielles qui représentent des données non ordonnées. Par exemple : les balises avec des valeurs élevées peuvent avoir une priorité plus élevée que les balises avec des valeurs faibles.
Par exemple, dans les données ci-dessus, nous avons obtenu les résultats suivants après encodage :

Le LabelEncoder de sklearn peut être directement converti :
from sklearn.preprocessing import LabelEncoder le=LabelEncoder() df[‘Sex’]=le.fit_transform(df[‘Sex’])
LabelBinarizer est un outil utilisé pour créer une matrice d'étiquettes à partir de. une classe utilitaire de liste multi-catégories qui convertit une liste en une matrice avec exactement le même nombre de colonnes que les valeurs uniques dans l'ensemble d'entrée.
Par exemple, ces données
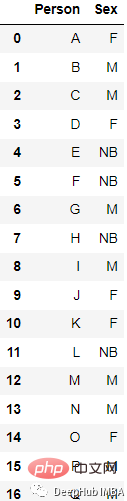
Le résultat converti est

from sklearn.preprocessing import LabelBinarizer lb = LabelBinarizer() new_df[‘Sex’]=lb.fit_transform(df[‘Sex’])
Lorsque vous omettez un encodage, tous les enregistrements avec la même valeur pour la variable de caractéristique catégorielle cible seront. moyenné pour déterminer la moyenne de la variable cible. L'algorithme d'encodage diffère légèrement entre les ensembles de données d'entraînement et de test. Étant donné que les enregistrements de caractéristiques pris en compte pour la classification sont exclus de l'ensemble de données d'entraînement, celui-ci est appelé « Laisser un de côté ».
Le codage de valeurs spécifiques de variables catégorielles spécifiques est le suivant.
ci = (Σj != i tj / (n — 1 + R)) x (1 + εi) where ci = encoded value for ith record tj = target variable value for jth record n = number of records with the same categorical variable value R = regularization factor εi = zero mean random variable with normal distribution N(0, s)
Par exemple, les données suivantes :

Après l'encodage :

Pour démontrer ce processus d'encodage, nous créons l'ensemble de données :
import pandas as pd; data = [[‘1’, 120], [‘2’, 120], [‘3’, 140], [‘2’, 100], [‘3’, 70], [‘1’, 100],[‘2’, 60], [‘3’, 110], [‘1’, 100],[‘3’, 70] ] df = pd.DataFrame(data, columns = [‘Dept’,’Yearly Salary’])
puis l'encodons :
import category_encoders as ce
tenc=ce.TargetEncoder()
df_dep=tenc.fit_transform(df[‘Dept’],df[‘Yearly Salary’])
df_dep=df_dep.rename({‘Dept’:’Value’}, axis=1)
df_new = df.join(df_dep)De cette façon, nous obtenons le résultat ci-dessus.
Lors de l'utilisation de la fonction de hachage, la chaîne sera convertie en une valeur de hachage unique. Parce qu'il utilise très peu de mémoire et peut gérer davantage de données catégorielles. Le hachage de fonctionnalités est une méthode efficace pour gérer les fonctionnalités clairsemées de grande dimension dans l’apprentissage automatique. Il convient aux scénarios d'apprentissage en ligne et présente les caractéristiques d'être rapide, simple, efficace et rapide.
Par exemple, les données suivantes :
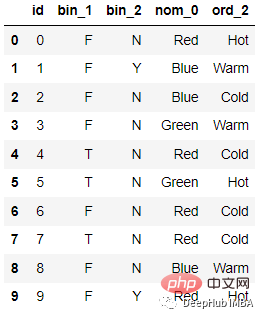
Après l'encodage
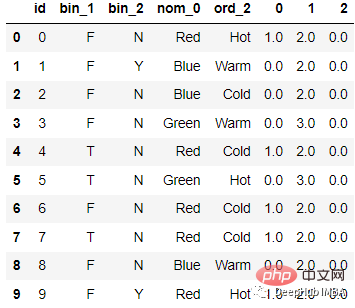
le code est le suivant :
from sklearn.feature_extraction import FeatureHasher # n_features contains the number of bits you want in your hash value. h = FeatureHasher(n_features = 3, input_type =’string’) # transforming the column after fitting hashed_Feature = h.fit_transform(df[‘nom_0’]) hashed_Feature = hashed_Feature.toarray() df = pd.concat([df, pd.DataFrame(hashed_Feature)], axis = 1) df.head(10)
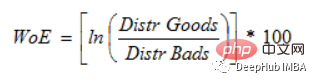 Si P(Goods) / P(Bads) = 1, alors WoE est 0. Si le résultat pour ce groupe est aléatoire, alors P(Mauvais) > P(Bons), le rapport de cotes est de 1 et le poids de la preuve (WoE) est de 0. Si P(Goods) > P(bad) dans un groupe, alors WoE est supérieur à 0.
Si P(Goods) / P(Bads) = 1, alors WoE est 0. Si le résultat pour ce groupe est aléatoire, alors P(Mauvais) > P(Bons), le rapport de cotes est de 1 et le poids de la preuve (WoE) est de 0. Si P(Goods) > P(bad) dans un groupe, alors WoE est supérieur à 0.
因为Logit转换只是概率的对数,或ln(P(Goods)/P(bad)),所以WoE非常适合于逻辑回归。当在逻辑回归中使用wo编码的预测因子时,预测因子被处理成与编码到相同的尺度,这样可以直接比较线性逻辑回归方程中的变量。
例如下面的数据

会被编码为:

代码如下:
from category_encoders import WOEEncoder
df = pd.DataFrame({‘cat’: [‘a’, ‘b’, ‘a’, ‘b’, ‘a’, ‘a’, ‘b’, ‘c’, ‘c’], ‘target’: [1, 0, 0, 1, 0, 0, 1, 1, 0]})
woe = WOEEncoder(cols=[‘cat’], random_state=42)
X = df[‘cat’]
y = df.target
encoded_df = woe.fit_transform(X, y)Helmert Encoding将一个级别的因变量的平均值与该编码中所有先前水平的因变量的平均值进行比较。
反向 Helmert 编码是类别编码器中变体的另一个名称。它将因变量的特定水平平均值与其所有先前水平的水平的平均值进行比较。

会被编码为

代码如下:
import category_encoders as ce encoder=ce.HelmertEncoder(cols=’Dept’) new_df=encoder.fit_transform(df[‘Dept’]) new_hdf=pd.concat([df,new_df], axis=1) new_hdf
是CatBoost编码器试图解决的是目标泄漏问题,除了目标编码外,还使用了一个排序概念。它的工作原理与时间序列数据验证类似。当前特征的目标概率仅从它之前的行(观测值)计算,这意味着目标统计值依赖于观测历史。

TargetCount:某个类别特性的目标值的总和(到当前为止)。
Prior:它的值是恒定的,用(数据集中的观察总数(即行))/(整个数据集中的目标值之和)表示。
featucalculate:到目前为止已经看到的、具有与此相同值的分类特征的总数。

编码后的结果如下:

代码:
import category_encoders category_encoders.cat_boost.CatBoostEncoder(verbose=0, cols=None, drop_invariant=False, return_df=True, handle_unknown=’value’, handle_missing=’value’, random_state=None, sigma=None, a=1) target = df[[‘target’]] train = df.drop(‘target’, axis = 1) # Define catboost encoder cbe_encoder = ce.cat_boost.CatBoostEncoder() # Fit encoder and transform the features cbe_encoder.fit(train, target) train_cbe = cbe_encoder.transform(train)
James-Stein 为特征值提供以下加权平均值:
James-Stein 编码器将平均值缩小到全局的平均值。该编码器是基于目标的。但是James-Stein 估计器有缺点:它只支持正态分布。
它只能在给定正态分布的情况下定义(实时情况并非如此)。为了防止这种情况,我们可以使用 beta 分布或使用对数-比值比转换二元目标,就像在 WOE 编码器中所做的那样(默认使用它,因为它很简单)。
Target Encoder的一个更直接的变体是M Estimator Encoding。它只包含一个超参数m,它代表正则化幂。m值越大收缩越强。建议m的取值范围为1 ~ 100。
Sum Encoder将类别列的特定级别的因变量(目标)的平均值与目标的总体平均值进行比较。在线性回归(LR)的模型中,Sum Encoder和ONE HOT ENCODING都是常用的方法。两种模型对LR系数的解释是不同的,Sum Encoder模型的截距代表了总体平均值(在所有条件下),而系数很容易被理解为主要效应。在OHE模型中,截距代表基线条件的平均值,系数代表简单效应(一个特定条件与基线之间的差)。
最后,在编码中我们用到了一个非常好用的Python包 “category-encoders”它还提供了其他的编码方法,如果你对他感兴趣,请查看它的官方文档:
http://contrib.scikit-learn.org/category_encoders/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Algorithme de remplacement de page
Algorithme de remplacement de page
 Méthodes de codage courantes
Méthodes de codage courantes
 Win11 ignore le didacticiel pour se connecter au compte Microsoft
Win11 ignore le didacticiel pour se connecter au compte Microsoft
 Touche de raccourci d'arrêt rapide
Touche de raccourci d'arrêt rapide
 Quels sont les niveaux de notation par étoiles des utilisateurs mobiles ?
Quels sont les niveaux de notation par étoiles des utilisateurs mobiles ?
 Que dois-je faire si mon iPad ne peut pas être chargé ?
Que dois-je faire si mon iPad ne peut pas être chargé ?
 Le système d'exploitation Hongmeng de Huawei est-il Android ?
Le système d'exploitation Hongmeng de Huawei est-il Android ?
 commande telnet
commande telnet








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



