


Trois niveaux d'intelligence artificielle :
Fonction informatique : capacités de stockage de données et de calcul, les machines sont bien meilleures que les humains.
Fonctions perceptuelles : vision, audition et autres capacités Les machines sont déjà comparables aux humains dans les domaines de la reconnaissance vocale et de la reconnaissance d'images.
Intelligence cognitive : pour des tâches telles que le traitement du langage naturel, la modélisation du bon sens et le raisonnement, les machines ont encore un long chemin à parcourir.
Le traitement du langage naturel appartient à la catégorie de l'intelligence cognitive. Parce que le langage naturel présente les caractéristiques d'abstraction, de combinaison, d'ambiguïté, de connaissance et d'évolution, il pose de grands défis au traitement automatique. Certaines personnes appellent le traitement du langage naturel le joyau de l'artificiel. intelligence. Ces dernières années, des modèles linguistiques pré-entraînés représentés par BERT ont émergé, faisant entrer le traitement du langage naturel dans une nouvelle ère : modèles linguistiques pré-entraînés + réglage fin pour des tâches spécifiques. Cet article tente de faire le point sur l'évolution de la technologie de pré-formation en langage naturel, en vue de communiquer et d'apprendre avec tous. Nous acceptons les critiques et la correction des lacunes et des erreurs.
utilise un vecteur de la taille d'un vocabulaire pour représenter un mot, dans lequel la valeur de la position correspondante du mot est 1 et les positions restantes sont 0. Inconvénients :
Hypothèse de sémantique distribuée : des mots similaires ont des contextes similaires, la signification sémantique d'un le mot peut être représenté par le contexte. Sur la base de cette idée, la distribution contextuelle de chaque mot peut être utilisée pour représenter des mots.
Basé sur le corpus, le contexte du mot est utilisé pour construire un tableau de fréquence de cooccurrence. Chaque ligne du tableau de mots représente la représentation vectorielle d'un mot. Différentes informations linguistiques peuvent être capturées grâce à différentes sélections de contexte. Par exemple, si les mots dans la fenêtre fixe autour du mot dans la phrase sont utilisés comme contexte, des informations plus locales sur le mot seront capturées : informations lexicales et syntaxiques. Le document est utilisé comme contexte. Capturez davantage d'informations sur le sujet représentées par le mot. Inconvénients :
Remplacez la valeur dans la représentation de la fréquence des mots par TF-IDF, ce qui atténue principalement le problème des mots à haute fréquence dans la représentation de la fréquence des mots.
atténue également le problème des mots à haute fréquence de la représentation de la fréquence des mots. La valeur dans la représentation de la fréquence des mots est remplacée par l'information mutuelle ponctuelle du mot :

En comparant la fréquence des mots La matrice est soumise à une décomposition en valeurs singulières (SVD) pour obtenir une représentation vectorielle de faible dimension, continue et dense de chaque mot, qui peut être considérée comme représentant la sémantique potentielle du mot Cette méthode est également appelée analyse sémantique latente (Latent Semantic Analysis, LSA).

LSA atténue les problèmes tels que les mots à haute fréquence, les relations d'ordre élevé, la rareté, etc., et l'effet est toujours bon dans les algorithmes d'apprentissage automatique traditionnels, mais il y a aussi quelques lacunes :
L'ordre du texte et la relation de cooccurrence entre les mots fournissent des signaux d'apprentissage naturels auto-supervisés pour le traitement du langage naturel, permettant au système de le faire sans annotation manuelle supplémentaire. Apprendre à partir du texte .
CBOW (Continous Bag-of-Words) utilise le contexte (fenêtre) pour prédire le mot cible, prend la moyenne arithmétique des vecteurs de mots des mots contextuels, puis prédit le probabilité du mot cible.

Skip-gram prédit le contexte par mot.

GloVe (Global Vectors for Word Representation) utilise des vecteurs de mots pour prédire la matrice de cooccurrence des mots et implémente une décomposition matricielle implicite. Tout d’abord, une matrice de cooccurrence X pondérée en fonction de la distance est construite sur la base de la fenêtre contextuelle du mot, puis le vecteur du mot et du contexte est utilisé pour ajuster la matrice de cooccurrence X :

La fonction de perte est :

L'apprentissage des vecteurs de mots utilise les informations de cooccurrence entre les mots du corpus, et l'idée sous-jacente est l'hypothèse sémantique distribuée. Qu'il s'agisse de Word2Vec basé sur le contexte local ou de GloVe basé sur des informations explicites de cooccurrence globale, l'essentiel est d'agréger les informations contextuelles de cooccurrence d'un mot dans l'ensemble du corpus dans la représentation vectorielle du mot, et d'obtenir de bons résultats. , la vitesse d'entraînement est également très rapide, mais le vecteur de lacunes est statique, c'est-à-dire qu'il n'a pas la capacité de changer avec les changements de contexte.
Modèle de langage autorégressif : calculez la probabilité conditionnelle du mot au moment actuel en fonction de l'historique de la séquence.

Modèle de langage à encodage automatique : reconstruisez les mots masqués à travers le contexte.

représente la séquence masquée

Le modèle d'attention peut être compris comme un mécanisme de pondération d'une séquence vectorielle et le calcul du poids .

Le modèle d'attention utilisé dans Transformer peut être exprimé comme suit :

Lorsque Q, K, V proviennent de la même séquence vectorielle, il devient une auto-attention. modèle d’attention.
Auto-attention multi-têtes : configurez plusieurs groupes de modèles d'auto-attention, divisez leurs vecteurs de sortie et mappez-les à la taille des dimensions de la couche cachée du Transformer via un mappage linéaire. Le modèle d’auto-attention multi-têtes peut être compris comme un ensemble de plusieurs modèles d’auto-attention.


Étant donné que le modèle d'auto-attention ne prend pas en compte les informations de position du vecteur d'entrée, les informations de position sont cruciales pour la modélisation de séquence. Les informations de position peuvent être introduites via l'intégration de position ou le codage de position. Transformer utilise le codage de position.

De plus, la connexion résiduelle, la normalisation des couches et d'autres technologies sont également utilisées dans le bloc Transformateur.
Avantages :
Inconvénients :
ELMo : intégrations à partir de modèles de langage
Vous pouvez directement utiliser l'intégration de mots pour des mots, ou vous pouvez utiliser CNN pour des séquences de caractères dans des mots, ou autres Modèle.


ELMo modélise indépendamment les modèles de langage avant et arrière via LSTM Modèle de langage avant :

Modèle de langage arrière :

maximisation :
.
Une fois ELMo formé, les vecteurs suivants peuvent être obtenus pour être utilisés dans des tâches en aval.

est l'intégration de mots obtenue par la couche d'entrée et est le résultat de la concaténation des sorties LSTM avant et arrière.
Lorsqu'ils sont utilisés dans des tâches en aval, les vecteurs de chaque couche peuvent être pondérés pour obtenir une représentation vectorielle d'ELMo, et un poids peut être utilisé pour mettre à l'échelle le vecteur ELMo.

Différents niveaux de vecteurs de couches cachées contiennent des informations textuelles à différents niveaux ou granularités :
Structure du modèle
Dans GPT-1 (Generative Pre-Training), il s'agit d'un modèle de langage unidirectionnel qui utilise 12 structures de blocs de transformateur comme décodeurs, chaque bloc de transformateur est un auto-multi-tête -mécanisme d'attention, puis la distribution de probabilité de la sortie est obtenue grâce à une connexion complète.


Maximisation :

Applications en aval
Dans la tâche en aval, pour un ensemble de données étiqueté, chaque instance possède un jeton d'entrée :, qui consiste en l'étiquette. Tout d'abord, ces jetons sont entrés dans le modèle de pré-entraînement entraîné pour obtenir le vecteur de caractéristiques final. Ensuite, le résultat de la prédiction est obtenu via une couche entièrement connectée :

Le but de la tâche supervisée en aval est de maximiser :

Afin d'éviter le problème d'oubli catastrophique, un certain poids de prédiction peut être ajouté à la perte de réglage fin, perte de formation, généralement perte de pré-entraînement.


L'idée centrale de GPT-2 peut être résumée comme suit : toute tâche supervisée est un sous-ensemble du modèle de langage. Lorsque la capacité du modèle est très grande et que la quantité de données est suffisamment riche, elle est utilisée. peut être réalisé en entraînant simplement le modèle de langage. Effectuer d’autres tâches d’apprentissage supervisé. Par conséquent, GPT-2 n'a pas réalisé trop d'innovations et de conceptions structurelles sur le réseau GPT-1. Il a simplement utilisé plus de paramètres de réseau et un ensemble de données plus large. L'objectif était de former un vecteur de mots avec une capacité de généralisation plus forte.
Parmi les 8 tâches du modèle de langage, GPT-2 en a 7 surpassées les méthodes de pointe de l'époque grâce au seul apprentissage zéro-shot (bien sûr, certaines tâches ne sont toujours pas aussi bonnes que le modèle supervisé). La plus grande contribution de GPT-2 est de vérifier que les modèles vectoriels de mots formés avec des données massives et un grand nombre de paramètres peuvent être transférés vers d'autres catégories de tâches sans formation supplémentaire.
Dans le même temps, GPT-2 a montré qu'à mesure que la capacité du modèle et la quantité (qualité) des données d'entraînement augmentent, il est possible de développer davantage son potentiel. Sur la base de cette idée, GPT-3 est né.
La structure du modèle reste inchangée, mais la capacité du modèle, le volume et la qualité des données d'entraînement sont augmentés. Il est connu comme un géant, et l'effet est également très bon.

De GPT-1 à GPT-3, à mesure que la capacité du modèle et la quantité de données de formation augmentent, les connaissances linguistiques apprises par le modèle s'enrichissent et le paradigme du traitement du langage naturel change également de " modèle de pré-entraînement + réglage fin » se transforme progressivement en « modèle de pré-entraînement + apprentissage zéro-coup/quelques-coups ». L'inconvénient de GPT est qu'il utilise un modèle de langage unidirectionnel. BERT a prouvé qu'un modèle de langage bidirectionnel peut améliorer les performances du modèle.
XLNet introduit des informations contextuelles bidirectionnelles via le modèle de langage de permutation sans introduire de balises spéciales, évitant ainsi le problème de distribution incohérente des jetons dans les étapes de pré-formation et de réglage fin. Dans le même temps, Transformer-XL est utilisé comme structure principale du modèle, ce qui a de meilleurs effets sur les textes longs.
Le but du modèle de langage de permutation est :

est l'ensemble de toutes les permutations possibles de la séquence de texte.


Cette méthode utilise les informations de position du mot prédit.
Lors de l'application de tâches en aval, aucune représentation de requête n'est requise et aucun masque n'est requis.
Le modèle de langage masqué (MLM) masque aléatoirement certains mots et utilise ensuite des informations contextuelles pour la prédiction. Il y a un problème avec MLM, il y a une inadéquation entre la pré-formation et le réglage fin, car le jeton [MASK] n'est jamais vu lors du réglage fin. Pour résoudre ce problème, BERT ne remplace pas toujours le jeton de mot « masqué » par le jeton [MASK] réel. Le générateur de données d'entraînement sélectionne aléatoirement 15 % des tokens puis :
Le jeton est masqué en BERT natif, et des mots ou phrases entiers (N-Gram) peuvent être masqués.
Prédiction de la phrase suivante (NSP) : lorsque les phrases A et B sont sélectionnées comme échantillons de pré-entraînement, B a 50 % de chances d'être la phrase suivante de A et 50 % de chances d'être aléatoire. phrase du corpus.


Le paradigme classique "modèle pré-entraîné + réglage fin", la structure du thème est un transformateur multicouche empilé.
RoBERTa (approche de pré-entraînement BERT robustement optimisée) n'améliore pas considérablement le BERT, mais mène uniquement des expériences détaillées sur chaque détail de conception du BERT pour trouver des possibilités d'amélioration du BERT.
BERT a un nombre relativement grand de paramètres. L'objectif principal d'ALBERT (A Lite BERT) est de réduire les paramètres : la dimension vectorielle du mot de
ELECTRA (Apprentissage efficace d'un encodeur qui classe les remplacements de jetons avec précision) présente le modèle de générateur et de discriminateur, et modifie la tâche de pré-entraînement générative du modèle de langage masqué (MLM) en détection discriminante de jeton remplacé ( RTD), qui détermine si le jeton actuel a été remplacé par le modèle de langage, est similaire à l'idée du GAN.

Le générateur prédit le jeton à la position du masque dans le texte d'entrée :


L'entrée du discriminateur est la sortie du générateur, et le discriminateur prédit si le mot à chaque position a a été remplacé :

De plus, quelques optimisations ont été apportées :
Utilisez uniquement le discriminateur et non le générateur dans les tâches en aval.
Transformer Une stratégie courante pour traiter un texte long consiste à diviser le texte en morceaux de longueur fixe et à encoder chaque morceau indépendamment, sans interaction d'informations entre les morceaux.

Afin d'optimiser la modélisation du texte long, Transformer-XL utilise deux technologies : la récurrence au niveau du segment avec réutilisation d'état et les encodages de position relative.
Transformer-XL est également saisi sous la forme de segments de longueur fixe pendant la formation. La différence est que l'état du segment précédent de Transformer-XL sera mis en cache puis. La réutilisation de l'état caché de la tranche de temps précédente lors du calcul du segment actuel donne à Transformer-XL la possibilité de modéliser des dépendances à plus long terme.
Deux segments consécutifs de longueur L et. L'état du nœud de couche caché est exprimé par, où d est la dimension du nœud de couche caché. Le processus de calcul de l'état du nœud de la couche cachée est :

Un autre avantage de la récursivité des fragments est l'amélioration de la vitesse de raisonnement. Par rapport à l'architecture autorégressive de Transformer, qui ne peut avancer qu'une seule tranche de temps à la fois, le processus de raisonnement de Transformer-XL réutilise directement la représentation du fragment précédent au lieu de le calculer à partir de zéro. , ce qui améliore le processus de raisonnement jusqu'au raisonnement par fragments.

Dans Transformer, le modèle d'auto-attention peut être exprimé comme suit :

L'expression complète est :


L'encodage de position de chaque fragment est le même, ce qui signifie que le codage de position du Transformer est un codage de position absolu par rapport au fragment et n'a rien à voir avec la position relative du contenu actuel dans la phrase originale.
Transfomer-XL a apporté plusieurs modifications basées sur la formule ci-dessus et a obtenu la méthode de calcul suivante :

Technologie de distillation des connaissances (KD) : Elle se compose généralement d'un modèle d'enseignant et d'un modèle d'étudiant. Elle transfère les connaissances du modèle d'enseignant au modèle d'étudiant afin que le modèle d'étudiant soit aussi proche. autant que possible au modèle d'enseignant. , dans les applications pratiques, le modèle d'étudiant doit souvent être plus petit que le modèle d'enseignant et conserver fondamentalement l'effet du modèle d'origine.
Modèle étudiant de DistillBert :
Modèle enseignant : BERT-base :
Fonction de perte :
Perte MLM supervisée : Perte d'entropie croisée obtenue par entraînement avec langage masqué modèle :
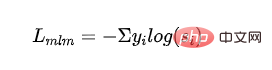
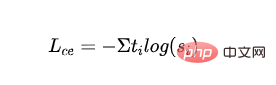
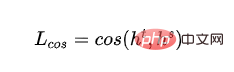
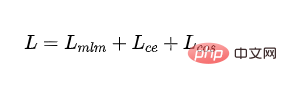
//m.sbmmt.com/link/6e2290dbf1e11f39d246e7ce5ac50a1e
https://www.php. cn/link/664c7298d2b73b3c7fe2d1e8d1781c06
//m.sbmmt.com/link/67b878df6cd42d142f2924f3ace85c78
https:// www.php.c n/lien/f6a673f09493afcd8b129a0bcf1cd5bc
//m.sbmmt.com/link/82599a4ec94aca066873c99b4c741ed8
//m.sbmmt.com/link/2e64da0bae6a7533021c760d4ba5d621
https :/ /m.sbmmt.com/link/56d33021e640f5d64a611a71b5dc30a3
//m.sbmmt.com/link/4e38d30e656da5ae9d3a425109ce9e04
//m.sbmmt.com/link /c055dcc749c2632fd4dd806301f05ba6
//m.sbmmt.com/link/a749e38f556d5eb1dc13b9221d1f994f
//m.sbmmt.com /link/ 8ab9bb97ce35080338be74dc6375e0ed
//m.sbmmt.com/link/4f0bf7b7b1aca9ad15317a0b4efdca14
//m.sbmmt.com/link/b81132591828d622fc335860bffec150
https://www. php.cn/link/fca758e52635df5a640f7063ddb9cdcb
//m.sbmmt.com/link/5112277ea658f7138694f079042cc3bb
https://www. cn/lien/257deb66f5366aab34a23d5fd0571da4
//m.sbmmt.com/link/b18e8fb514012229891cf024b6436526
//m.sbmmt.com/link /836a0dcbf5d22652569dc3a708274c1 6
https //m.sbmmt.com/link/a3de03cb426b5e36f5c7167b21395323
//m.sbmmt.com/link/831b342d8a83408e5960e9b0c5f31f0c
https://www.php .cn /link/6b27e88fdd7269394bca4968b48d8df4
//m.sbmmt.com/link/682e0e796084e163c5ca053dd8573b0c
https://www.php .cn /lien/9739efc4f01292e764c86caa59af353e
//m.sbmmt.com/link/b93e78c67fd4ae3ee626d8ec0c412dec
//m.sbmmt.com/link/c8cc6e90ccbff44c9cee23611711cdc4
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Que signifient les faces B et C ?
Que signifient les faces B et C ?
 le bios ne peut pas détecter le disque SSD
le bios ne peut pas détecter le disque SSD
 Comment utiliser la bibliothèque Python
Comment utiliser la bibliothèque Python
 Renommez le logiciel apk
Renommez le logiciel apk
 Solution à l'échec de la connexion entre wsus et le serveur Microsoft
Solution à l'échec de la connexion entre wsus et le serveur Microsoft
 La fonction principale de l'unité arithmétique dans un micro-ordinateur est d'effectuer
La fonction principale de l'unité arithmétique dans un micro-ordinateur est d'effectuer
 Comment résoudre le problème lorsque la température du processeur de l'ordinateur est trop élevée
Comment résoudre le problème lorsque la température du processeur de l'ordinateur est trop élevée
 Java exporter Excel
Java exporter Excel








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



