



Invité : Lu Mian
Compilé par : Mo Se
Les 6 et 7 août 2022, la AISummit Global Artificial Intelligence Technology Conference se tiendra comme prévu. Lors de la réunion, Lu Mian, architecte système 4Paradigm et responsable de la R&D d'OpenMLDB, a prononcé un discours intitulé « Base de données d'apprentissage automatique Open Source OpenMLDB : une plate-forme cohérente de fonctionnalités de production en ligne et hors ligne », en se concentrant sur les défis liés aux données et aux fonctionnalités des systèmes artificiels. mise en œuvre de l'ingénierie intelligente, la plate-forme de calcul de fonctionnalités au niveau de la production d'OpenMLDB qui est cohérente en ligne et hors ligne, OpenMLDB v0.5 : les améliorations en matière de performances, de coût et de facilité d'utilisation ont été partagées sous trois aspects.
Le contenu du discours est désormais organisé comme suit, j'espère qu'il pourra vous inspirer.
Aujourd'hui, selon les statistiques, 95 % du temps consacré à la mise en œuvre de l'intelligence artificielle est consacré aux données. Bien qu’il existe sur le marché différents outils de données tels que MySQL, ils sont loin de résoudre le problème de la mise en œuvre de l’intelligence artificielle. Examinons donc d’abord les problèmes de données.
Si vous avez participé au développement d'applications d'apprentissage automatique, vous devriez être profondément impressionné par MLOps, comme le montre la figure ci-dessous :
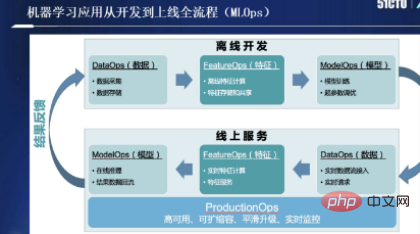
En fait, il n'existe actuellement pas de définition académique stricte du MLOps, et cela peut être divisé en développement hors ligne dans son ensemble et en deux processus de service en ligne. Le support d'informations dans chaque processus, des données aux fonctionnalités en passant par les modèles, passera par trois supports différents, du processus de développement hors ligne au processus de service en ligne.
Ensuite, nous nous concentrons sur le processus des fonctionnalités intermédiaires pour comprendre comment résoudre les défis rencontrés.
Il existe principalement deux catégories d'applications dans le développement de l'intelligence artificielle. L'une est le type de perception. Par exemple, la reconnaissance des visages familiers et d'autres applications d'IA sont la perception. tapez Fondamentalement, il sera basé sur l’algorithme DNN. L’autre type concerne les scénarios d’IA décisionnels, tels que les recommandations personnalisées pour les achats Taobao. En outre, il existe certains scénarios tels que les scénarios de contrôle des risques et les scénarios antifraude dans lesquels l’IA est largement utilisée dans la prise de décision.
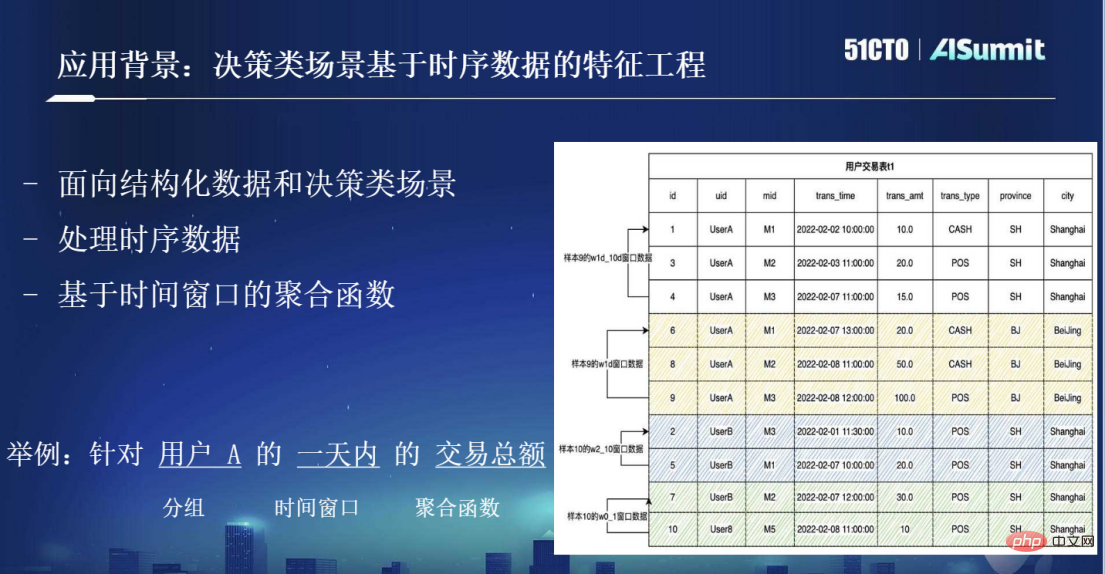
Par conséquent, le contexte d'application dont nous parlons maintenant est principalement destiné à ce type de scénario de prise de décision. L'une des caractéristiques les plus importantes est que ses données sont des données structurées dans un tableau bidimensionnel, et ce sont également des données de séries chronologiques. Comme le montre la figure ci-dessous, il y a un « trans_time » sur la table des transactions utilisateur, qui représente le moment auquel chaque enregistrement se produit. Lorsqu'il est connecté, il s'agit d'une série de données chronologiques. L'une des méthodes de traitement les plus courantes pour l'ingénierie de fonctionnalités basée sur des données de séries chronologiques est la fonction d'agrégation basée sur des fenêtres temporelles. Par exemple, cibler le montant total des transactions d'un utilisateur au cours d'une journée, etc. Il s'agit d'une opération courante d'ingénierie des fonctionnalités dans les scénarios de prise de décision.
Maintenant, pourquoi devrions-nous utiliser OpenMLDB ? Une très grande expérience consiste à utiliser un véritable calcul dur en temps réel pour répondre aux besoins de l'IA.
Qu’est-ce que l’informatique dure en temps réel ? Cela a deux significations. La première fait référence à l’utilisation des données en temps réel les plus récentes pour obtenir le plus grand effet décisionnel sur l’entreprise. Par exemple, vous devez utiliser le comportement de clic de l'utilisateur au cours des 10 dernières secondes ou 1 minute pour prendre des décisions commerciales, plutôt que les données de l'année écoulée ou de l'année précédente.
Un autre point très important est que pour le calcul en temps réel, une fois que l'utilisateur émet une requête comportementale, le calcul des caractéristiques doit être effectué en peu de temps, voire au niveau de la milliseconde.
Il existe actuellement de nombreux produits sur le marché pour le calcul par lots/le calcul en streaming, mais ils n'ont pas encore atteint les exigences de calcul en temps réel au niveau de la milliseconde.
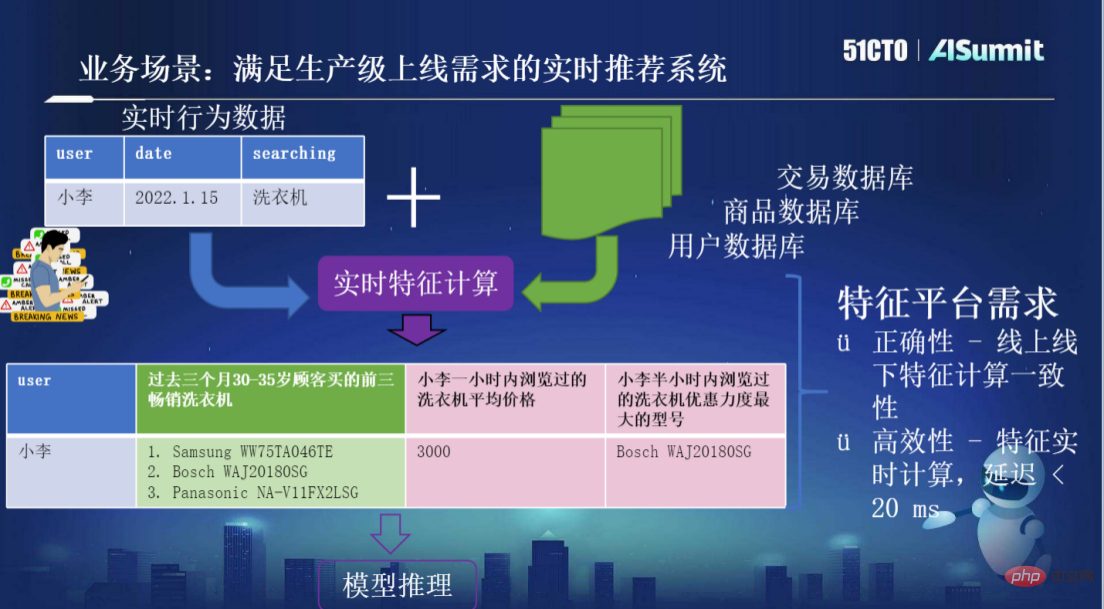
Par exemple, comme le montre la figure ci-dessous, pour créer un système de recommandation en temps réel qui répond aux exigences en ligne au niveau de la production, l'utilisateur Xiao Li effectue une recherche avec le mot-clé « machine à laver ». Il doit également saisir les données de la demande d'origine. en tant qu'utilisateur, produit, transaction et autres informations dans le système. Les données sont combinées pour le calcul des fonctionnalités en temps réel, puis des fonctionnalités plus significatives sont générées, ce qu'on appelle l'ingénierie des fonctionnalités, le processus de génération de fonctionnalités. Par exemple, le système générera « les trois machines à laver les plus vendues achetées par les clients d'un certain groupe d'âge au cours des trois derniers mois ». Ce type de fonctionnalité ne nécessite pas une grande rapidité et est calculé sur la base de données historiques plus longues. Cependant, le système peut également avoir besoin de données très sensibles au temps, telles que « parcourir les enregistrements au cours de la dernière heure/demi-heure », etc. Une fois que le système a obtenu les caractéristiques nouvellement calculées, il fournira le modèle pour l'inférence. Il existe deux exigences principales pour une telle plate-forme de fonctionnalités système : l'une est l'exactitude, c'est-à-dire la cohérence des calculs de fonctionnalités en ligne et hors ligne ; l'autre est l'efficacité, c'est-à-dire le calcul des fonctionnalités en temps réel, le retardement des fonctionnalités
Avant la méthodologie OpenMLDB, tout le monde utilisait principalement le processus illustré dans la figure ci-dessous pour le calcul et le développement de fonctionnalités.
Tout d'abord, nous devons créer un scénario. Les data scientists utiliseront les outils Python/SparkSQL pour l'extraction de fonctionnalités hors ligne. Le KPI d'un data scientist est de créer un modèle d'exigences métier qui répond à la précision. Lorsque la qualité du modèle atteint la norme, la tâche est terminée. Les défis d'ingénierie auxquels sont confrontés les scripts de fonctionnalités après leur mise en ligne, tels qu'une faible latence, une simultanéité élevée et une haute disponibilité, ne relèvent pas de la compétence des scientifiques.
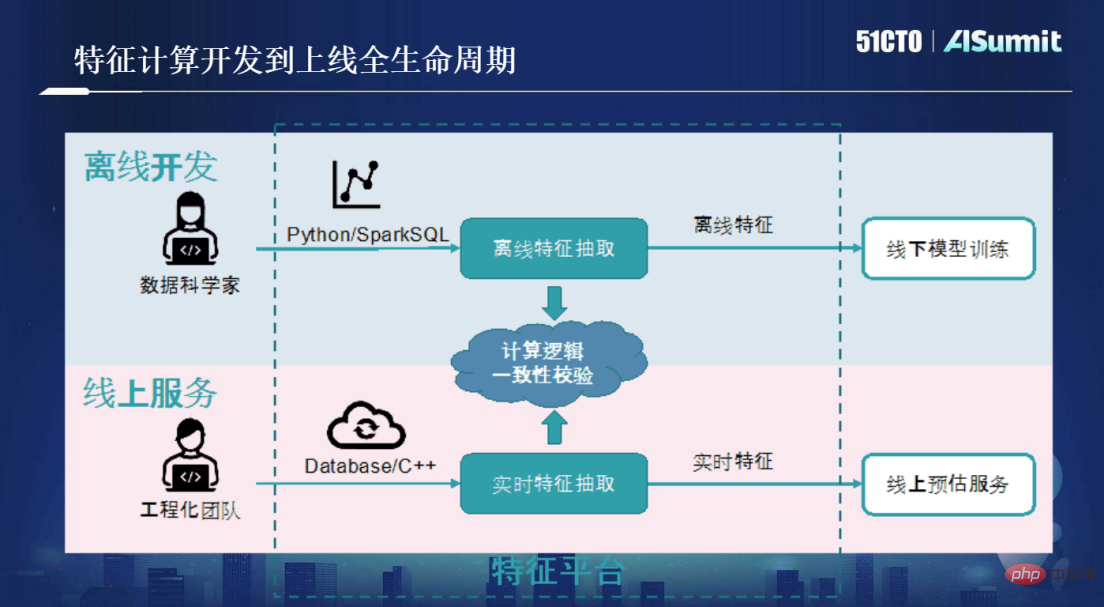
Afin de mettre en ligne le script Python écrit par le data scientist, l'équipe d'ingénierie doit intervenir, c'est reconstruire et optimiser le script hors ligne écrit par le data scientist, et. utilisez C++/Database pour effectuer un service d'extraction de fonctionnalités en temps réel. Cela répond à une série d'exigences techniques en matière de faible latence, de simultanéité élevée et de haute disponibilité, permettant aux scripts de fonctionnalités d'être véritablement mis en ligne pour les services en ligne.
Ce processus est très coûteux et nécessite l'intervention de deux équipes de compétences, et les outils qu'elles utilisent sont différents. Une fois les deux ensembles de processus terminés, la cohérence de la logique de calcul doit être vérifiée. Autrement dit, la logique de calcul du script de fonctionnalités développé par le data scientist doit être totalement cohérente avec la logique de l'extraction finale des fonctionnalités en temps réel. . Cette exigence semble claire et simple, mais elle entraînera de nombreux coûts de communication, de tests et de développement itératif lors du processus de vérification de cohérence. D’après l’expérience passée, plus le projet est vaste, plus la vérification de cohérence prendra du temps et plus le coût sera très élevé.
De manière générale, la principale raison de l'incohérence entre en ligne et hors ligne lors du processus de vérification de la cohérence est que les outils de développement sont incohérents. Par exemple, les scientifiques utilisent Python et les équipes d'ingénierie utilisent des bases de données. capacités des outils. Il existe des compromis fonctionnels et des incohérences ; il existe également des lacunes dans la définition des données, de l’algorithme et de la cognition.
En bref, le coût de développement basé sur les deux ensembles de processus traditionnels est très élevé. Il nécessite deux ensembles de développeurs de postes de compétences différents, le développement et l'exploitation de deux ensembles de systèmes, et il y en a. aussi des tas de vérification et de vérification au milieu.
Et OpenMLDB fournit une solution open source à faible coût.
En juin de l'année dernière, OpenMLDB était officiellement open source. Il s'agit d'un jeune projet dans la communauté open source, mais il a été implémenté. dans plus de 100 scénarios, couvrant plus de 300 nœuds multiples.
OpenMLDB est une base de données d'apprentissage automatique open source. Sa fonction principale est de fournir une plate-forme de fonctionnalités cohérente en ligne et hors ligne. Alors, comment OpenMLDB répond-il aux besoins de haute performance et d’exactitude ?
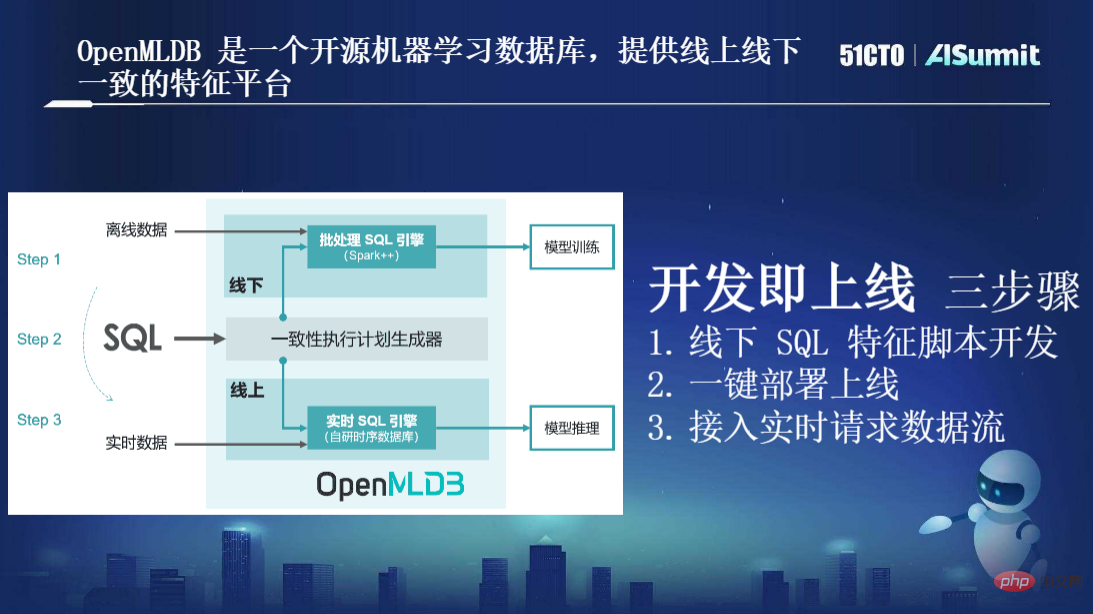
Comme le montre l'image ci-dessus, tout d'abord, le seul langage de programmation utilisé par OpenMLDB est SQL. Il n'y a plus deux ensembles de chaînes d'outils. Les data scientists et les développeurs utilisent SQL pour exprimer les fonctionnalités. .
Deuxièmement, deux ensembles de moteurs sont séparés au sein d'OpenMLDB. L'un est le « moteur SQL par lots », qui est optimisé au niveau du code source basé sur Spark++, fournit une méthode de calcul plus performante et permet l'expansion de la syntaxe ; Il s'agit d'un "moteur SQL temps réel". Cet ensemble est une base de données de séries temporelles de ressources développée par notre équipe. La base de données par défaut est une base de données de séries temporelles basée sur un moteur de stockage mémoire. Sur la base du « moteur SQL en temps réel », nous pouvons réaliser des calculs en temps réel efficaces au niveau de la milliseconde, tout en garantissant une haute disponibilité, une faible latence et une simultanéité élevée.
Il existe également un important « générateur de plan d'exécution cohérent » entre ces deux moteurs, conçu pour assurer la cohérence de la logique du plan d'exécution en ligne et hors ligne. Grâce à lui, la cohérence en ligne et hors ligne peut être naturellement garantie sans avoir recours à une relecture manuelle.
En bref, sur la base de cette architecture, notre objectif ultime est d'atteindre l'objectif d'optimisation du « développement et en ligne », qui comprend principalement trois étapes : le développement de scripts de fonctionnalités SQL hors ligne et l'accès en ligne au réel ; -flux de données de demande de temps.
On peut voir que par rapport aux deux ensembles de processus précédents, aux deux ensembles de chaînes d'outils et aux deux ensembles d'investissements des développeurs, le plus grand avantage de cet ensemble de moteurs est qu'il permet d'économiser beaucoup de coûts d'ingénierie, ce qui c'est-à-dire que tant que les data scientists utilisent SQL pour développer le script de fonctionnalité, il ne nécessite plus que l'équipe d'ingénierie effectue un deuxième cycle d'optimisation avant de pouvoir être directement mis en ligne, et il ne nécessite plus l'opération manuelle de vérification de la cohérence en ligne et hors ligne, économisant beaucoup de temps et d’argent.
La figure suivante montre le processus complet d'OpenMLDB, du développement hors ligne aux services en ligne :
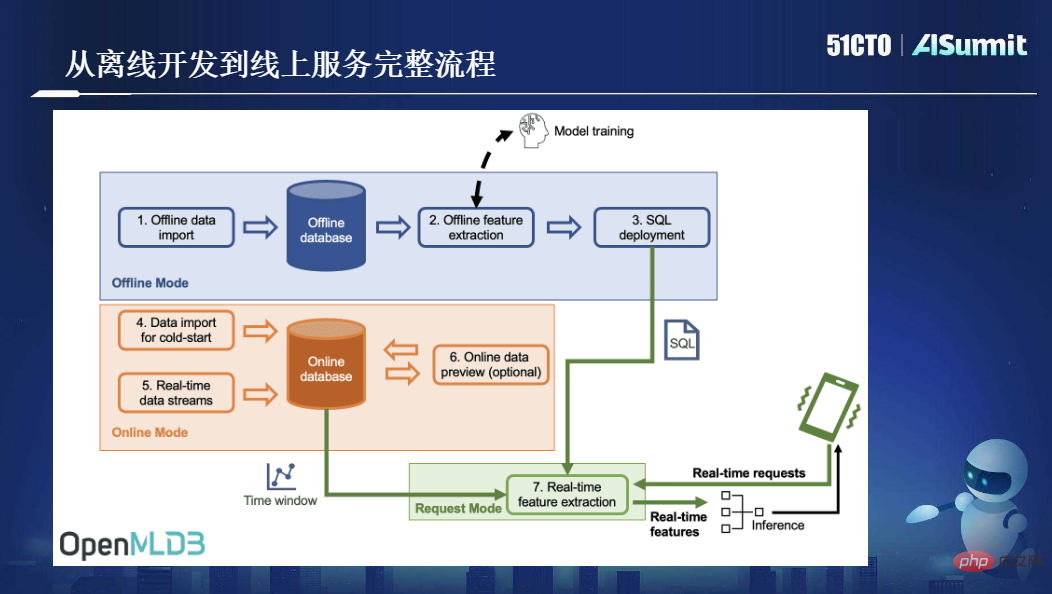
Dans l'ensemble, OpenMLDB résout un problème principal : l'apprentissage automatique en ligne et la cohérence hors ligne fournissent une fonctionnalité principale : la milliseconde ; calcul de caractéristiques en temps réel au niveau. Ces deux points sont les valeurs fondamentales apportées par OpenMLDB.
Étant donné qu'OpenMLDB dispose de deux ensembles de moteurs, en ligne et hors ligne, les méthodes de candidature sont également différentes. La figure suivante montre notre méthode recommandée à titre de référence :

Ensuite, nous présenterons quelques composants ou fonctionnalités de base dans OpenMLDB :
Fonction 1, moteur d'exécution cohérent en ligne et hors ligne, basé sur un moteur d'exécution cohérent en ligne et hors ligne, basé sur un système unifié. fonction informatique sous-jacente, les modes d'exécution en ligne et hors ligne, des plans logiques aux plans physiques, sont ajustés de manière adaptative, garantissant ainsi la cohérence en ligne et hors ligne.
Comprend deux moteurs de calcul de caractéristiques en ligne hautes performances, comprenant une structure de données d'index de mémoire de table de saut à double couche hautes performances ; une stratégie d'optimisation hybride de calcul en temps réel + une technologie de pré-agrégation fournit deux moteurs de stockage mémoire/disque ; pour répondre à différentes exigences de performances et de coûts.
Fonctionnalité trois, moteur de calcul hors ligne optimisé pour le calcul de caractéristiques, y compris l'optimisation du calcul parallèle multi-fenêtres ; l'optimisation du calcul de l'asymétrie des données ; l'extension de la syntaxe SQL optimisée pour le calcul de caractéristiques, etc. Tout cela se traduit par une amélioration significative des performances par rapport à la version communautaire.
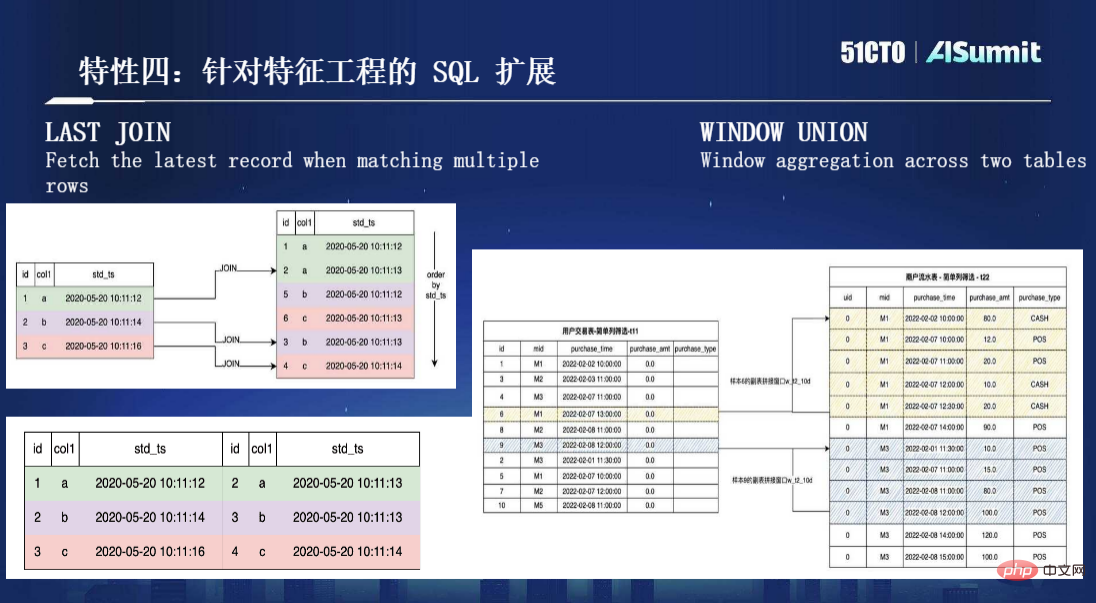
Fonction 4, extension SQL pour l'ingénierie des fonctionnalités. Comme mentionné précédemment, nous utilisons SQL pour la définition des fonctionnalités, mais en fait, SQL n'est pas conçu pour le calcul des fonctionnalités. Par conséquent, après avoir étudié un grand nombre de cas et accumulé une expérience d'utilisation, nous avons constaté qu'il était nécessaire d'apporter certaines extensions à la syntaxe SQL. pour mieux gérer le calcul des fonctionnalités. Il existe deux extensions importantes ici, l'une est LAST JOIN et l'autre est la WINDOW UNION la plus couramment utilisée, comme le montre la figure ci-dessous :
Fonctionnalité cinq, prise en charge des fonctionnalités au niveau de l'entreprise. En tant que base de données distribuée, OpenMLDB présente les caractéristiques d'une haute disponibilité, d'une expansion et d'une contraction transparentes et d'une mise à niveau fluide, et a été implémentée dans de nombreux cas d'entreprise.
Fonctionnalité six, développement et gestion avec SQL comme noyau, OpenMLDB est également une gestion de base de données, similaire aux bases de données traditionnelles. Par exemple, si une CLI est fournie, OpenMLDB peut implémenter l'intégralité du processus dans l'ensemble de la CLI, à partir des fonctionnalités hors ligne Des calculs et solutions SQL aux requêtes en ligne, il peut fournir une expérience de développement complète basée sur SQL et CLI.
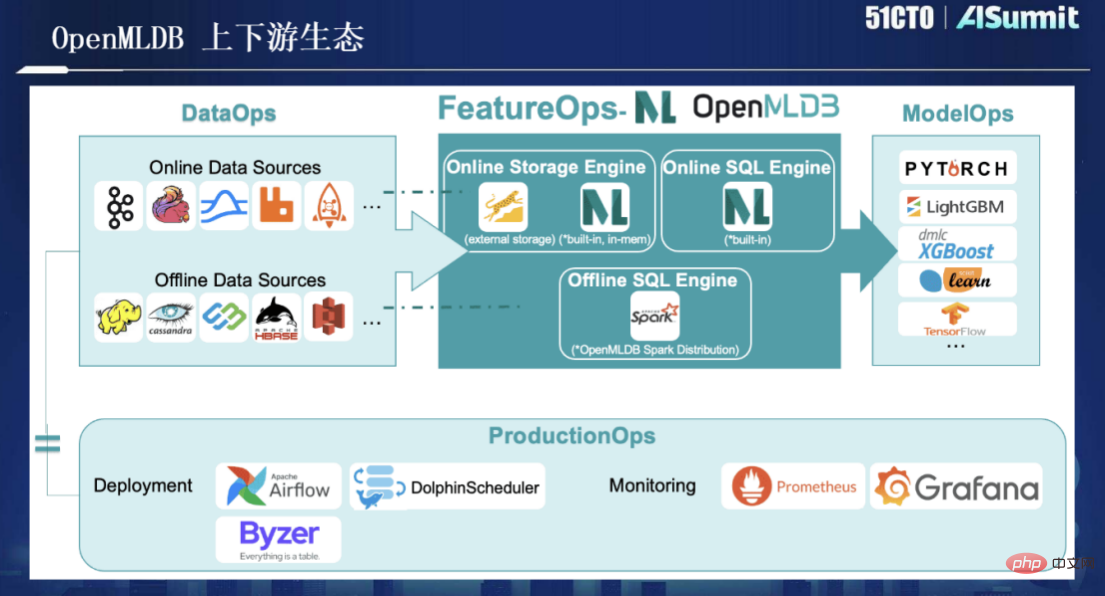
De plus, OpenMLDB est désormais open source, et l'expansion de son écologie en amont et en aval est comme le montre la figure ci-dessous :
Présentons ensuite une nouvelle version de OpenMLDB v0.5 Nous avons apporté quelques améliorations sous trois aspects.
Tout d’abord, jetons un coup d’œil à l’historique du développement d’OpenMLDB. En juin 2021, OpenMLDB était open source. En fait, il avait déjà de nombreux clients avant cela, et il avait commencé à développer la première ligne de code en 2017. Cela fait quatre ou cinq ans d'accumulation technologique.
Lors du premier anniversaire après l'open source, nous avons itéré environ cinq versions. Par rapport aux versions précédentes, la v0.5.0 présente les caractéristiques notables suivantes :
Améliorations des performances, la technologie d'agrégation peut améliorer considérablement les performances des longues fenêtres. L'optimisation de pré-agrégation améliore les performances de deux ordres de grandeur en termes de latence et de débit pour les requêtes à fenêtre longue.
Réduction des coûts, à partir de la version v0.5.0, le moteur en ligne propose deux options de moteur basées sur la mémoire et la mémoire externe. Basé sur la mémoire, une faible latence et une concurrence élevée ; fournissant une réponse de latence de l’ordre de la milliseconde à des coûts d’utilisation plus élevés. Basé sur une mémoire externe, il est moins sensible aux performances ; le coût peut être réduit de 75 % dans le cadre d'une utilisation à faible coût et d'une configuration typique basée sur SSD. Les codes métier de couche supérieure des deux moteurs sont imperceptibles et peuvent être commutés sans frais.
Facilité d'utilisation améliorée. Nous avons introduit les fonctions définies par l'utilisateur (UDF) dans la version v0.5.0, ce qui signifie que si SQL ne peut pas répondre à votre expression logique d'extraction de fonctionnalités, les fonctions définies par l'utilisateur, telles que l'UDF C/C++, l'enregistrement dynamique UDF, etc., sont prises en charge pour faciliter les utilisateurs. Élargir la logique informatique et améliorer la couverture des applications.
Enfin, merci à tous les développeurs OpenMLDB. Depuis le début de l'open source, près de 100 contributeurs ont contribué au code de notre communauté. En même temps, nous invitons également davantage de développeurs à rejoindre la communauté et à contribuer par leurs propres efforts. . Faites quelque chose de plus significatif.
Les rediffusions des discours de la conférence et les PPT sont maintenant en ligne. Accédez au site officiel pour voir le contenu passionnant.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Que signifie le clonage WeChat ?
Que signifie le clonage WeChat ?
 Qu'est-ce qu'un élément caché dans jquery
Qu'est-ce qu'un élément caché dans jquery
 Comment résoudre l'exception de lecture de fichiers volumineux Java
Comment résoudre l'exception de lecture de fichiers volumineux Java
 Site officiel d'Okex
Site officiel d'Okex
 Comment définir le numéro de page ppt
Comment définir le numéro de page ppt
 police de définition du bloc-notes
police de définition du bloc-notes








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



