


Article arXiv "Unifying Voxel-based Representation with Transformer for 3D Object Detection", 22 juin, Université chinoise de Hong Kong, Université de Hong Kong, Megvii Technology (à la mémoire du Dr Sun Jian) et Simou Technology, etc.

Cet article propose un cadre de détection d'objets 3D multimodal unifié appelé UVTR. Cette méthode vise à unifier les représentations multimodales de l’espace voxel et à permettre une détection 3D monomodale ou multimodale précise et robuste. À cette fin, les espaces spécifiques aux modalités sont d’abord conçus pour représenter différentes entrées dans l’espace des fonctionnalités du voxel. Préservez l’espace voxel sans compression de hauteur, atténuez l’ambiguïté sémantique et activez l’interaction spatiale. Sur la base de cette approche unifiée, une interaction intermodale est proposée pour utiliser pleinement les caractéristiques inhérentes des différents capteurs, notamment le transfert de connaissances et la fusion modale. De cette manière, les expressions de nuages de points tenant compte de la géométrie et les caractéristiques riches en contexte dans les images peuvent être bien exploitées, ce qui se traduit par de meilleures performances et robustesse.
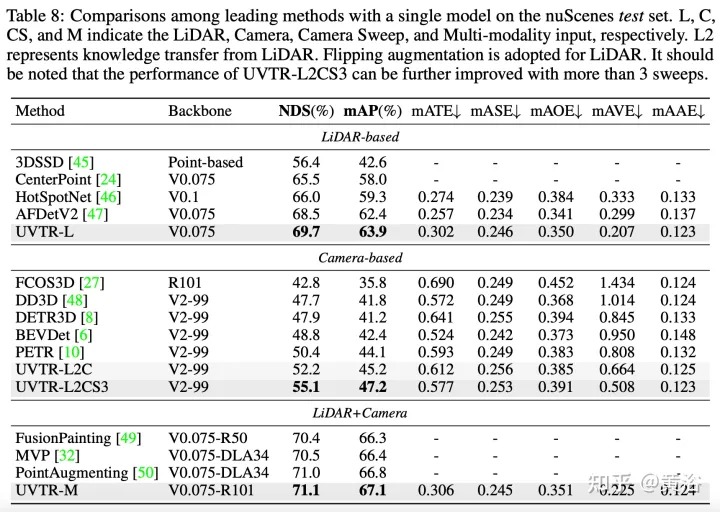
Le décodeur de transformateur est utilisé pour échantillonner efficacement les fonctionnalités d'un espace unifié avec des emplacements apprenables, ce qui facilite les interactions au niveau des objets. D'une manière générale, UVTR représente une première tentative de représentation de différentes modalités dans un cadre unifié, surpassant les travaux antérieurs sur les entrées monomodales et multimodales, atteignant des performances de pointe sur l'ensemble de test nuScenes, le lidar, la caméra et les NDS de sortie multimodale. 69,7%, 55,1% et 71,1% respectivement.
Code : https://github.com/dvlab-research/UVTR.
Comme le montre la figure :
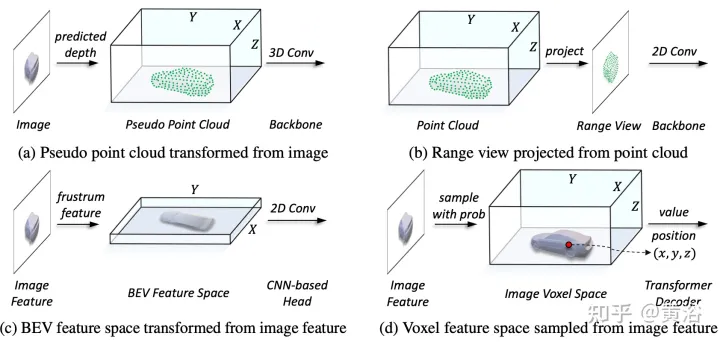
Dans le processus d'unification de la représentation, l'entrée peut être grossièrement divisé en représentation du débit de niveau et débit de niveau caractéristique. Pour la première approche, les données multimodales sont alignées au début du réseau. En particulier, le pseudo-nuage de points dans (a) est converti à partir de l'image assistée en profondeur prédite, tandis que l'image de distance dans (b) est projetée à partir du nuage de points. En raison des imprécisions de profondeur dans les pseudo-nuages de points et de l'effondrement géométrique 3D dans les images à distance, la structure spatiale des données est détruite, conduisant à de mauvais résultats. Pour les méthodes au niveau des fonctionnalités, la méthode typique consiste à convertir les fonctionnalités de l'image en frustum, puis à les compresser dans l'espace BEV, comme le montre la figure (c). Cependant, en raison de sa trajectoire semblable à un rayon, la compression des informations de hauteur (hauteur) à chaque position regroupe les caractéristiques de diverses cibles, introduisant ainsi une ambiguïté sémantique. Dans le même temps, son approche implicite est difficile à prendre en charge l’interaction explicite des fonctionnalités dans l’espace 3D et limite le transfert de connaissances ultérieur. Par conséquent, une représentation plus unifiée est nécessaire pour combler les écarts modaux et faciliter les interactions multiformes.
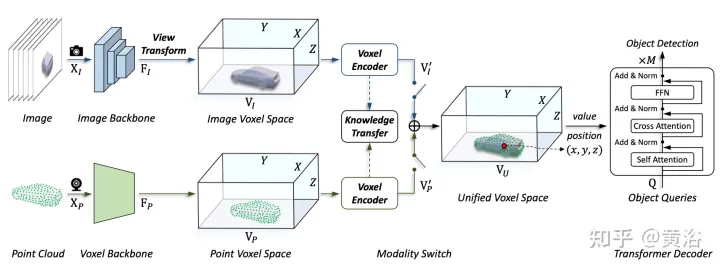
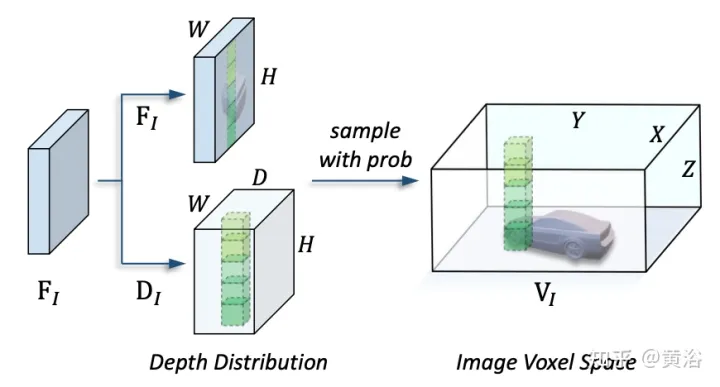
Le framework proposé dans cet article unifie la représentation basée sur les voxels et le transformateur. En particulier, la représentation et l'interaction des images et des nuages de points dans un espace explicite basé sur des voxels. Pour les images, l'espace voxel est construit en échantillonnant les caractéristiques du plan image en fonction de la profondeur prévue et des contraintes géométriques, comme le montre la figure (d). Pour les nuages de points, des emplacements précis permettent naturellement d'associer les entités aux voxels. Ensuite, un encodeur voxel est introduit pour l'interaction spatiale afin d'établir la relation entre les entités adjacentes. De cette manière, les interactions multimodales se déroulent naturellement avec les caractéristiques de chaque espace voxel. Pour les interactions au niveau de la cible, un transformateur déformable est utilisé comme décodeur pour échantillonner les caractéristiques spécifiques à la requête cible à chaque position (x, y, z) dans l'espace voxel unifié, comme le montre la figure (d). Dans le même temps, l’introduction de positions de requête 3D atténue efficacement l’ambiguïté sémantique provoquée par la compression des informations de hauteur (hauteur) dans l’espace BEV.
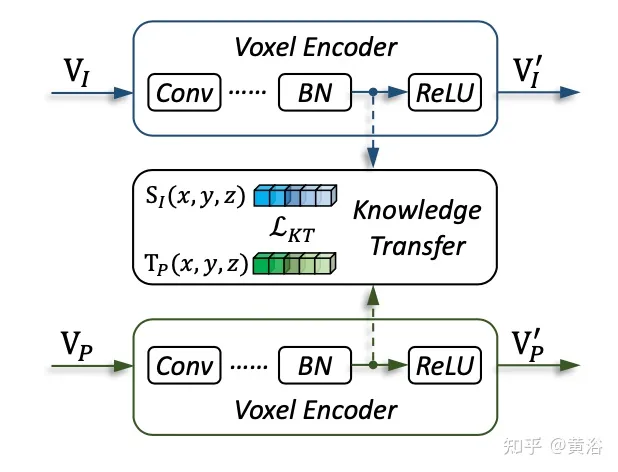
Comme le montre la figure, l'architecture UVTR d'entrée multimodale : étant donné une image à image unique ou multi-images et un nuage de points, elle est d'abord traitée dans un seul squelette et convertie en VI et VP spatiaux spécifiques à la modalité, où la transformation de la vue se fait vers l'image. Dans les encodeurs voxels, les fonctionnalités interagissent spatialement et le transfert de connaissances est facile à prendre en charge pendant la formation. En fonction des paramètres, sélectionnez les fonctionnalités monomodales ou multimodales via le commutateur modal. Enfin, les caractéristiques sont échantillonnées à partir du VU spatial unifié avec des emplacements apprenables et prédites à l'aide du décodeur de transformateur.
L'image montre les détails de la transformation de la vue :
L'image montre les détails du transfert de connaissances :
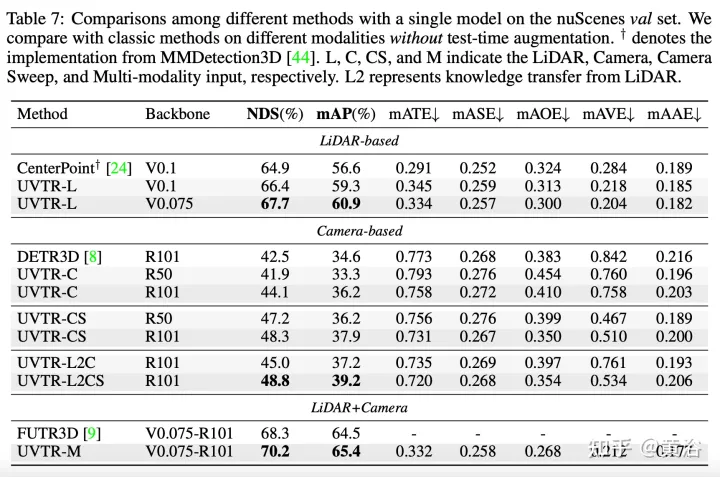
Les résultats expérimentaux sont les suivants :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Introduction au framework utilisé par vscode
Introduction au framework utilisé par vscode
 numéro de série et clé cad2012
numéro de série et clé cad2012
 Les pièces d'inscription Sols reviendront-elles à zéro ?
Les pièces d'inscription Sols reviendront-elles à zéro ?
 Le rôle de l'index
Le rôle de l'index
 Explication détaillée de la configuration de nginx
Explication détaillée de la configuration de nginx
 Quelle est la raison de l'échec de la résolution DNS ?
Quelle est la raison de l'échec de la résolution DNS ?
 Comment résoudre l'impossibilité de se connecter à NVIDIA
Comment résoudre l'impossibilité de se connecter à NVIDIA
 Représentation binaire des nombres négatifs
Représentation binaire des nombres négatifs








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



