


La régression linéaire repose sur quatre hypothèses :
L'erreur résiduelle fait référence à l'erreur entre la valeur prédite et la valeur observée. Il mesure la distance entre les points de données et la ligne de régression. Il est calculé en soustrayant les valeurs prédites des valeurs observées.
Les tracés résiduels sont un excellent moyen d'évaluer les modèles de régression. C'est un graphique qui montre tous les résidus sur l'axe vertical et les caractéristiques sur l'axe des x. Si les points de données sont dispersés de manière aléatoire sur des lignes sans motif, alors un modèle de régression linéaire s'adapte bien aux données, sinon nous devrions utiliser un modèle non linéaire.

Les deux sont des types de problèmes de régression. La différence entre les deux réside dans les données sur lesquelles ils sont formés.
Le modèle de régression linéaire suppose une relation linéaire entre les caractéristiques et les étiquettes, ce qui signifie que si nous prenons tous les points de données et les traçons sur une ligne linéaire (droite), cela devrait correspondre aux données.
Les modèles de régression non linéaire supposent qu'il n'y a pas de relation linéaire entre les variables. Les lignes non linéaires (curvilignes) doivent séparer et ajuster correctement les données.
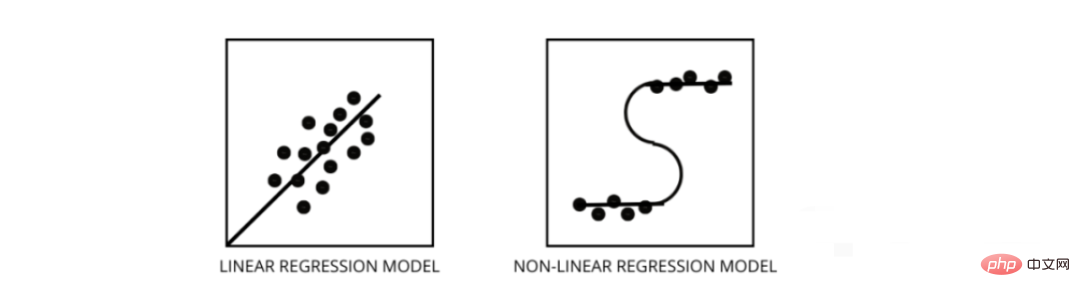
Trois meilleures façons de savoir si vos données sont linéaires ou non linéaires -
La multicolinéarité se produit lorsque certaines caractéristiques sont fortement corrélées les unes aux autres. La corrélation fait référence à une mesure qui indique comment une variable est affectée par les changements d'une autre variable.
Si une augmentation de la caractéristique a entraîne une augmentation de la caractéristique b, alors les deux caractéristiques sont positivement corrélées. Si une augmentation de a entraîne une diminution de la caractéristique b, alors les deux caractéristiques sont corrélées négativement. Avoir deux variables hautement corrélées sur les données d'entraînement entraînera une multicolinéarité car son modèle ne sera pas en mesure de trouver des modèles dans les données, ce qui entraînera de mauvaises performances du modèle. Par conséquent, avant d’entraîner le modèle, nous devons d’abord essayer d’éliminer la multicolinéarité.
Les valeurs aberrantes sont des points de données dont les valeurs diffèrent de la plage moyenne des points de données. Autrement dit, ces points sont différents des données ou hors du 3ème critère.
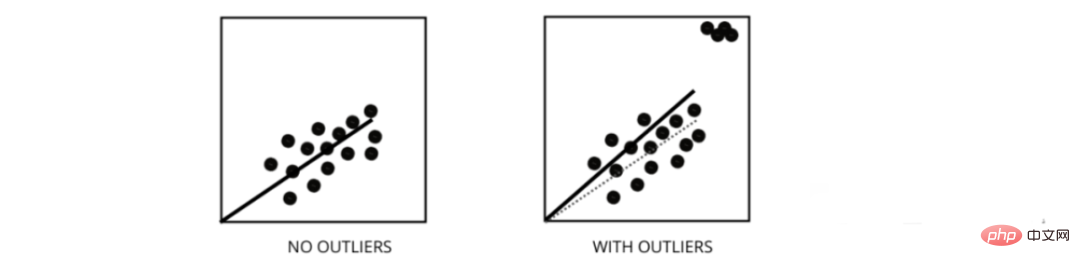
Le modèle de régression linéaire tente de trouver la ligne la mieux ajustée qui réduit les résidus. Si les données contiennent des valeurs aberrantes, la ligne de meilleur ajustement se déplacera un peu vers les valeurs aberrantes, ce qui augmentera le taux d'erreur et aboutira à un modèle avec une MSE très élevée.
MSE signifie erreur quadratique moyenne, qui est la différence au carré entre la valeur réelle et la valeur prédite. Et MAE est la différence absolue entre la valeur cible et la valeur prédite.
MSE pénalise les grosses erreurs, pas le MAE. À mesure que les valeurs de MSE et de MAE diminuent, le modèle tend vers une ligne mieux ajustée.
Dans l'apprentissage automatique, notre objectif principal est de créer un modèle général capable de mieux fonctionner sur les données d'entraînement et de test, mais lorsqu'il y a très peu de données, les modèles de régression linéaire de base ont tendance à surajuster, nous utiliserons donc la régularisation l1 et l2. .
La régularisation L1 ou régression lasso fonctionne en ajoutant la valeur absolue de la pente comme terme de pénalité dans la fonction de coût. Aide à supprimer les valeurs aberrantes en supprimant tous les points de données dont les valeurs de pente sont inférieures à un seuil.
La régularisation L2 ou régression de crête ajoute un terme de pénalité égal au carré de la taille du coefficient. Cela pénalise les entités ayant des valeurs de pente plus élevées.
l1 et l2 sont utiles lorsque les données d'entraînement sont petites, que la variance est élevée, que les caractéristiques prédites sont plus grandes que les valeurs observées et que les données souffrent de multicolinéarité.
Il fait référence à la situation dans laquelle les variances des points de données autour de la ligne la mieux ajustée sont différentes dans une plage. Il en résulte une dispersion inégale des résidus. S'il est présent dans les données, le modèle a tendance à prédire une sortie invalide. L’une des meilleures façons de tester l’hétéroscédasticité est de tracer les résidus.
L'une des principales causes de l'hétéroscédasticité au sein des données réside dans les grandes différences entre les caractéristiques des plages. Par exemple, si nous avons une colonne de 1 à 100 000, augmenter les valeurs de 10 % ne modifiera pas les valeurs inférieures, mais entraînera une très grande différence aux valeurs les plus élevées, produisant ainsi une grande différence de points de données. .
Le facteur d'inflation de la variance (vif) est utilisé pour déterminer dans quelle mesure une variable indépendante peut être prédite à l'aide d'autres variables indépendantes.
Prenons des exemples de données avec les fonctionnalités v1, v2, v3, v4, v5 et v6. Maintenant, pour calculer le vif de v1, considérez-le comme une variable prédictive et essayez de le prédire en utilisant toutes les autres variables prédictives.
Si la valeur de VIF est petite, alors il est préférable de supprimer la variable des données. Parce que des valeurs plus petites indiquent une corrélation élevée entre les variables.
La régression pas à pas est une méthode de création d'un modèle de régression en supprimant ou en ajoutant des variables prédictives à l'aide de tests d'hypothèse. Il prédit la variable dépendante en testant de manière itérative la signification de chaque variable indépendante et en supprimant ou en ajoutant certaines fonctionnalités après chaque itération. Il s'exécute n fois et tente de trouver la meilleure combinaison de paramètres qui prédit la variable dépendante avec la plus petite erreur entre les valeurs observées et prédites.
Il peut gérer de grandes quantités de données de manière très efficace et résoudre des problèmes de grande dimension.

Nous utilisons un problème de régression pour introduire ces indicateurs, où notre entrée est l'expérience professionnelle et le résultat est le salaire. Le graphique ci-dessous montre une ligne de régression linéaire tracée pour prédire le salaire.


L'erreur absolue moyenne (MAE) est la métrique de régression la plus simple. Il ajoute la différence entre chaque valeur réelle et prédite et la divise par le nombre d'observations. Pour qu’un modèle de régression soit considéré comme un bon modèle, le MAE doit être aussi petit que possible.
Simple et facile à comprendre. Le résultat aura les mêmes unités que la sortie. Par exemple : si l'unité de la colonne de sortie est LPA, alors si le MAE est de 1,2, alors nous pouvons interpréter le résultat comme +1,2 LPA ou -1,2 LPA, le MAE est relativement stable par rapport aux valeurs aberrantes (par rapport à certains autres indicateurs de régression, MAE est affecté par les valeurs aberrantes (moins d’impact). Les inconvénients de
MAE utilise une fonction modulaire, mais la fonction modulaire n'est pas différentiable en tout point, elle ne peut donc pas être utilisée comme fonction de perte dans de nombreux cas.

MSE prend la différence entre chaque valeur réelle et la valeur prédite, puis met la différence au carré et les additionne, enfin en la divisant par le nombre d'observations. Pour qu’un modèle de régression soit considéré comme un bon modèle, la MSE doit être aussi petite que possible.
Avantages du MSE : La fonction carré est dérivable en tous points, elle peut donc être utilisée comme fonction de perte.
Inconvénients de MSE : Étant donné que MSE utilise la fonction carré, l'unité du résultat est le carré de la sortie. Il est donc difficile d'interpréter les résultats. Puisqu'il utilise une fonction carrée, s'il y a des valeurs aberrantes dans les données, les différences seront également au carré et, par conséquent, le MSE n'est pas stable pour les valeurs aberrantes.

L'erreur quadratique moyenne (RMSE) prend la différence entre chaque valeur réelle et la valeur prédite, puis met la différence au carré et les additionne, et enfin divise par le nombre d'observations. Prenez ensuite la racine carrée du résultat. Par conséquent, RMSE est la racine carrée de MSE. Pour qu’un modèle de régression soit considéré comme un bon modèle, le RMSE doit être aussi petit que possible.
RMSE résout le problème du MSE, les unités seront les mêmes que celles de la sortie puisqu'il prend la racine carrée, mais est quand même moins stable aux valeurs aberrantes.
Les indicateurs ci-dessus dépendent du contexte du problème que nous résolvons. Nous ne pouvons pas juger de la qualité du modèle en regardant simplement les valeurs de MAE, MSE et RMSE sans comprendre le problème réel.

Si nous n'avons aucune donnée d'entrée, mais que nous voulons savoir combien de salaire il gagne dans cette entreprise, alors la meilleure chose que nous puissions faire est de leur donner la moyenne de tous les employés 'valeur des salaires.

Le score R2 donne une valeur comprise entre 0 et 1 et peut être interprété pour n'importe quel contexte. Cela peut être compris comme la qualité de l’ajustement.
SSR est la somme des carrés des erreurs de la droite de régression, et SSM est la somme des carrés des erreurs de la moyenne mobile. Nous comparons la droite de régression à la droite moyenne.

Si notre modèle a un score R2 de 0,8, cela signifie que nous pouvons dire que le modèle est capable d'expliquer 80 % de la variance de sortie. Autrement dit, 80 % de la variation des salaires peut s’expliquer par l’intrant (années de travail), mais les 20 % restants sont inconnus.
Si notre modèle comporte 2 fonctionnalités, les années de travail et les scores d'entretien, alors notre modèle peut expliquer 80 % des changements de salaire en utilisant ces deux fonctionnalités d'entrée.
À mesure que le nombre de fonctionnalités en entrée augmente, R2 aura tendance à augmenter en conséquence ou à rester le même, mais ne diminuera jamais, même si les fonctionnalités en entrée ne sont pas importantes pour notre modèle (par exemple, en ajoutant le nombre des caractéristiques d'entrée le jour de l'entretien) En ajoutant la température de l'air à notre exemple, R2 ne baissera pas même si la température n'est pas importante pour la sortie).
Dans la formule ci-dessus, R2 est R2, n est le nombre d'observations (lignes) et p est le nombre de caractéristiques indépendantes. R2 ajusté résout les problèmes de R2.
Lorsque nous ajoutons des fonctionnalités moins importantes pour notre modèle, comme l'ajout de température pour prédire le salaire.....

Lors de l'ajout de fonctionnalités importantes pour le modèle, telles que l'ajout de scores d'entretien pour prédire le salaire...

Ce qui précède présente les points de connaissance importants des problèmes de régression et l'introduction de divers indicateurs importants utilisés pour résoudre problèmes de régression. Avantages et inconvénients, j'espère que cela vous aidera.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Algorithme de remplacement de page
Algorithme de remplacement de page
 Que sont les cloud privés ?
Que sont les cloud privés ?
 Plateforme formelle de trading de devises numériques
Plateforme formelle de trading de devises numériques
 Comment enregistrer un nom de domaine permanent pour un site Web
Comment enregistrer un nom de domaine permanent pour un site Web
 Que signifie la fréquence d'images ?
Que signifie la fréquence d'images ?
 Comment restaurer des amis après avoir été bloqué sur TikTok
Comment restaurer des amis après avoir été bloqué sur TikTok
 Comment enregistrer un e-mail professionnel
Comment enregistrer un e-mail professionnel
 Utilisation des tâches C#
Utilisation des tâches C#








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



