


En conduite autonome, la détection de cibles via des images RVB ou des nuages de points lidar a été largement explorée. Cependant, comment rendre ces deux sources de données complémentaires et bénéfiques l’une à l’autre reste un défi. AutoAlignV1 et AutoAlignV2 sont principalement l'œuvre de l'Université des sciences et technologies de Chine, de l'Institut de technologie de Harbin et de SenseTime (comprenant initialement l'Université chinoise de Hong Kong et l'Université Tsinghua).
AutoAlignV1 est issu de l'article arXiv « AutoAlign : Pixel-Instance Feature Aggregation for Multi-Modal 3D Object Detection », mis en ligne en avril 2022.

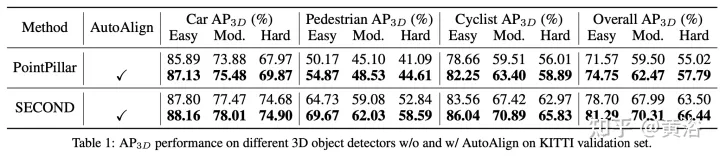
Cet article propose une stratégie de fusion automatique de fonctionnalités AutoAlign V1 pour la détection de cibles 3D. Utilisez une carte d'alignement apprenable pour modéliser la relation de cartographie entre l'image et le nuage de points, plutôt que d'établir une correspondance déterministe avec la matrice de projection de la caméra. Ce graphique permet au modèle d'aligner automatiquement les caractéristiques non homomorphes de manière dynamique et basée sur les données. Plus précisément, un module d'alignement de caractéristiques d'attention croisée est conçu pour regrouper de manière adaptative les caractéristiques d'image au niveau des pixels de chaque voxel. Afin d'améliorer la cohérence sémantique dans le processus d'alignement des fonctionnalités, un module d'interaction de fonctionnalités intermodales auto-supervisé est également conçu, grâce auquel le modèle peut apprendre l'agrégation de fonctionnalités guidée par des fonctionnalités au niveau de l'instance.
Les détecteurs d'objets 3D multimodaux peuvent être grossièrement divisés en deux catégories : la fusion au niveau de la décision et la fusion au niveau des fonctionnalités. Le premier détecte les objets dans leurs modes respectifs, puis rassemble les boîtes englobantes dans l'espace 3D. Contrairement à la fusion au niveau décisionnel, la fusion au niveau des fonctionnalités combine des fonctionnalités multimodales en une seule représentation pour détecter des objets. Par conséquent, le détecteur peut exploiter pleinement les fonctionnalités de différentes modalités pendant la phase d’inférence. Compte tenu de cela, davantage de méthodes de fusion au niveau des fonctionnalités ont été développées récemment.
Un travail projette chaque point sur le plan de l'image et obtient les caractéristiques de l'image correspondantes par interpolation bilinéaire. Bien que l'agrégation des caractéristiques soit effectuée avec précision au niveau des pixels, les motifs denses dans le domaine de l'image seront perdus en raison de la rareté des points de fusion, c'est-à-dire que la cohérence sémantique des caractéristiques de l'image est détruite.
Un autre travail utilise la solution initiale fournie par le détecteur 3D pour obtenir des caractéristiques RoI de différentes modalités et les connecter entre elles pour la fusion de caractéristiques. Il maintient la cohérence sémantique en effectuant une fusion au niveau de l'instance, mais souffre de problèmes tels qu'une agrégation approximative des fonctionnalités et des informations 2D manquantes lors de l'étape initiale de génération de proposition.
Pour utiliser pleinement ces deux méthodes, les auteurs proposent un cadre intégré de fusion de fonctionnalités multimodales pour la détection d'objets 3D, nommé AutoAlign. Il permet au détecteur d'agréger des caractéristiques intermodales de manière adaptative, ce qui s'avère efficace dans la modélisation des relations entre des représentations non homomorphes. Dans le même temps, il exploite l'agrégation fine de fonctionnalités au niveau des pixels tout en maintenant la cohérence sémantique grâce à l'interaction des fonctionnalités au niveau de l'instance.
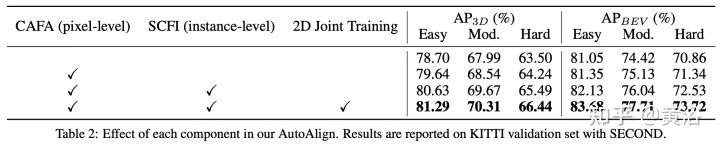
Comme le montre la figure : l'interaction des fonctionnalités fonctionne à deux niveaux : (i) l'agrégation des fonctionnalités au niveau des pixels ; (ii) l'interaction des fonctionnalités au niveau de l'instance ;
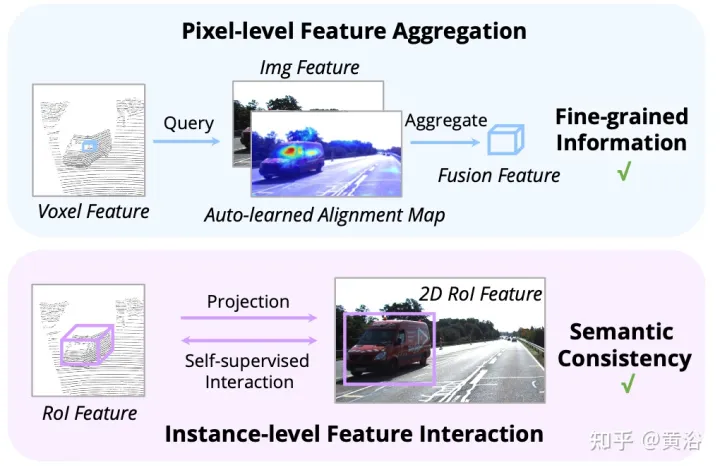
Les travaux précédents utilisent principalement des matrices de projection de caméra pour aligner les images et les caractéristiques ponctuelles de manière déterministe. Cette approche est efficace, mais peut introduire deux problèmes potentiels : 1) le point ne peut pas obtenir une vue plus large des données d'image, et 2) seule la cohérence de position est maintenue, tandis que la corrélation sémantique est ignorée. Par conséquent, AutoAlign a conçu le module Cross Attention Feature Alignment (CAFA) pour aligner de manière adaptative les caractéristiques entre les représentations non homomorphes. CAFA (Cross-Attention Feature Alignment)Le module n'utilise pas de mode de correspondance un-à-un, mais rend chaque voxel conscient de l'ensemble de l'image et se concentre dynamiquement sur les fonctionnalités 2D au niveau des pixels sur la base d'une carte d'alignement apprenable.
Comme le montre la figure : AutoAlign se compose de deux composants principaux. CAFA effectue l'agrégation de fonctionnalités sur le plan de l'image et extrait des informations fines au niveau des pixels de chaque fonctionnalité de voxel SCFI (Interaction de fonctionnalités intermodales auto-supervisée). effectue une interaction intermodale entre les fonctionnalités. L'auto-supervision modale utilise des conseils au niveau de l'instance pour améliorer la cohérence sémantique du module CAFA.
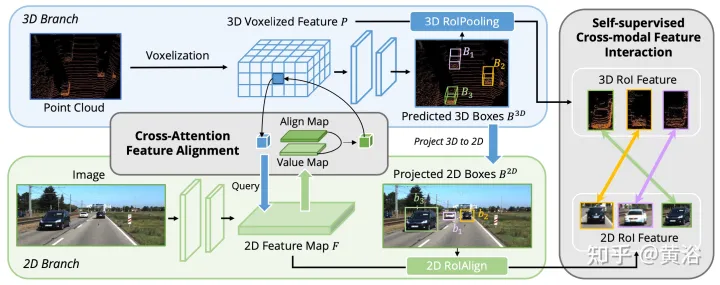
CAFA est un paradigme précis pour l'agrégation de caractéristiques d'image. Cependant, il ne peut pas capturer les informations au niveau de l'instance. En revanche, la fusion de fonctionnalités basée sur le RoI maintient l'intégrité de l'objet tout en souffrant d'une agrégation grossière des fonctionnalités et d'informations 2D manquantes lors de la phase de génération de proposition.
Pour combler le fossé entre la fusion au niveau des pixels et au niveau des instances, le module Interaction de fonctionnalités intermodales auto-supervisées (SCFI) est introduit pour guider l'apprentissage de CAFA. Il utilise directement les prédictions finales du détecteur 3D comme propositions, exploitant les caractéristiques des images et des points pour générer des propositions précises. De plus, au lieu de concaténer les fonctionnalités intermodales pour une optimisation plus poussée du cadre de délimitation, des contraintes de similarité sont ajoutées aux paires de fonctionnalités intermodales en tant que conseils au niveau de l'instance pour l'alignement des fonctionnalités.
Étant donné une carte de caractéristiques 2D et les caractéristiques voxélisées 3D correspondantes, N images de détection 3D régionales sont échantillonnées de manière aléatoire, puis projetées sur le plan 2D à l'aide de la matrice de projection de la caméra, générant ainsi un ensemble de paires d'images 2D. Une fois les boîtes appariées obtenues, 2DRoIAlign et 3DRoIPooling sont utilisés dans les espaces de fonctionnalités 2D et 3D pour obtenir les fonctionnalités RoI respectives.
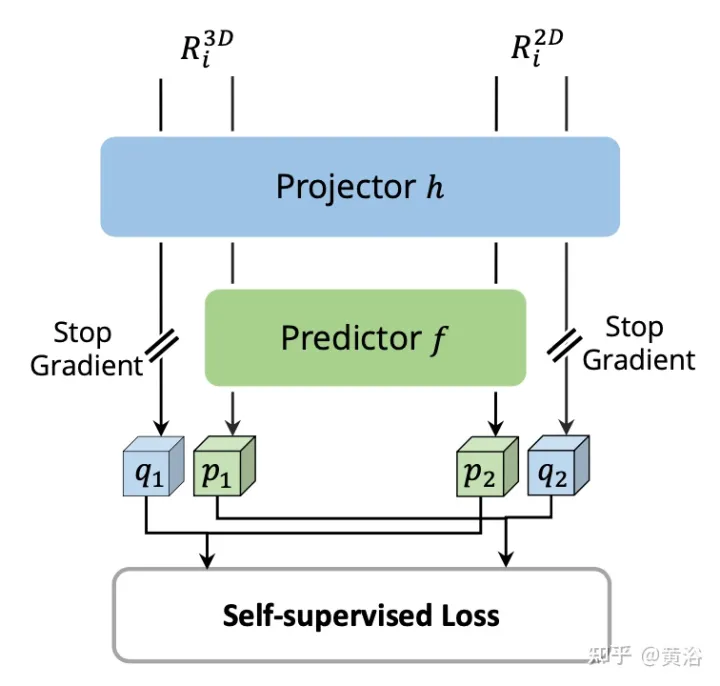
Pour chaque paire de fonctionnalités RoI 2D et 3D, effectuez une Interaction de fonctionnalités intermodales auto-supervisées (SCFI) sur les fonctionnalités de la branche image et les fonctionnalités voxélisées de la branche ponctuelle. Les deux fonctionnalités sont introduites dans une tête de projection, qui transforme la sortie d'une modalité pour qu'elle corresponde à l'autre. Introduisez une tête de prédiction avec deux couches entièrement connectées. Comme le montre la figure :
Bien que l'apprentissage multitâche soit très efficace, peu de travaux discutent de la détection conjointe du domaine d'image et du domaine de points. Dans la plupart des méthodes précédentes, le squelette de l'image est directement initialisé avec des poids pré-entraînés à partir d'un ensemble de données externe. Pendant la phase d'apprentissage, la seule surveillance est la perte de détection 3D propagée à partir des branches ponctuelles. Compte tenu du grand nombre de paramètres du squelette de l’image, la branche 2D est plus susceptible de réaliser un surajustement sous supervision implicite. Pour régulariser les représentations extraites des images, la branche image est étendue à Faster R-CNN et supervisée avec une perte de détection 2D.
AutoAlignV2 vient de "AutoAlignV2: Deformable Feature Aggregation for Dynamic Multi-Modal 3D Object Detection", mis en ligne en juillet 2022.

AutoAlign souffre d'un coût de calcul élevé introduit par le mécanisme d'attention global. À cette fin, construit sur AutoAlign, l'auteur propose AutoAlignV2, un framework de détection 3D multimodale plus rapide et plus puissant. Afin de résoudre le problème du coût de calcul, cet article propose le module Cross-Attention Feature Alignment). Il se concentre sur des points d'échantillonnage clairsemés et apprenables pour les modèles de relations intermodales, ce qui améliore la tolérance aux erreurs d'étalonnage et accélère considérablement l'agrégation de fonctionnalités entre les modalités. Afin de surmonter le complexe GT-AUG dans des contextes multimodaux, une stratégie d'amélioration multimodale simple et efficace est conçue pour une combinaison convexe basée sur des patchs d'image étant donné des informations de profondeur. De plus, grâce à un schéma de formation aux abandons au niveau de l’image, le modèle est capable d’effectuer des inférences de manière dynamique.
Le code sera open source :https://github.com/zehuichen123/AutoAlignV2.
Remarque : GT-AUG ("DEUXIÈME : Détection convolutive peu intégrée". Capteurs, 2018 ), Une méthode d'augmentation des données
Contexte Comment combiner efficacement les représentations hétérogènes du lidar et des caméras pour la détection d'objets 3D n'a pas été entièrement exploré. La difficulté actuelle de formation des détecteurs multimodaux est attribuée à deux aspects. D’une part, les stratégies de fusion combinant images et informations spatiales sont encore sous-optimales. En raison de la représentation hétérogène entre les images RVB et les nuages de points, un alignement minutieux est nécessaire avant que les entités ne soient regroupées. AutoAlign propose un module d'alignement global apprenable pour l'enregistrement automatique et obtient de bonnes performances. Cependant, il doit être entraîné à l'aide du module CSFI pour obtenir la relation de correspondance de position interne entre les points et les pixels de l'image.Notez également que la complexité opérationnelle du style est quadratique en termes de taille d'image, il n'est donc pas pratique d'appliquer une requête sur des cartes de fonctionnalités haute résolution. Cette limitation peut conduire à des informations d'image grossières et inexactes, ainsi qu'à la perte de représentation hiérarchique provoquée par FPN. D’un autre côté, l’augmentation des données, notamment GT-AUG, est une étape clé pour que les détecteurs 3D obtiennent des résultats compétitifs. En termes d’approches multimodales, une question importante est de savoir comment maintenir la synchronisation entre les images et les nuages de points lors des opérations de couper-coller. MoCa utilise une annotation de masque à forte intensité de main-d'œuvre dans le domaine 2D pour obtenir des caractéristiques d'image précises. Les annotations au niveau des bordures conviennent également, mais nécessitent un filtrage de points sophistiqué.
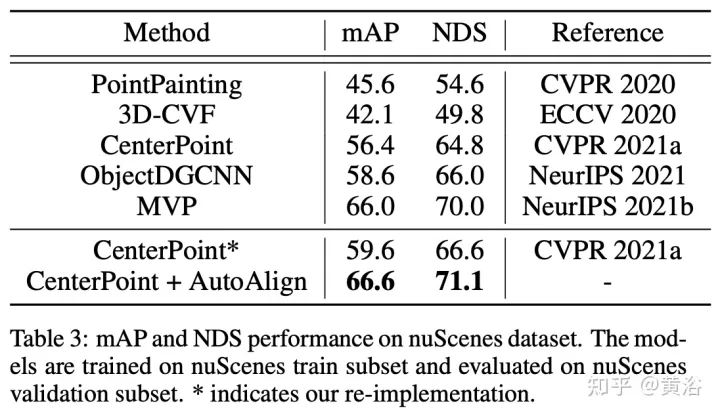
AutoAlignV2 vise à agréger efficacement les caractéristiques de l'image pour améliorer encore les performances des détecteurs d'objets 3D. À partir de l'architecture de base d'AutoAlign : saisissez les images appariées dans un réseau fédérateur léger ResNet, puis saisissez-les dans FPN pour obtenir la carte des caractéristiques. Ensuite, les informations d'image pertinentes sont agrégées via une carte d'alignement apprenable pour enrichir la représentation 3D des voxels non vides lors de l'étape de voxélisation. Enfin, les fonctionnalités améliorées sont intégrées au pipeline de détection 3D ultérieur pour générer des prédictions d'instance.
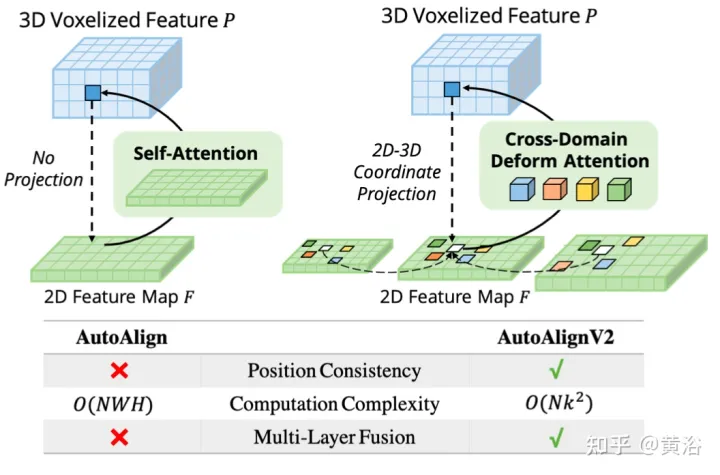
L'image montre la comparaison entre AutoAlignV1 et AutoAlignV2 : AutoAlignV2 invite le module d'alignement à avoir une relation de cartographie générale garantie par une matrice de projection déterministe, tout en conservant la possibilité d'ajuster automatiquement la position d'agrégation des fonctionnalités. En raison de son faible coût de calcul, AutoAlignV2 est capable d'agréger les caractéristiques multicouches des informations d'image hiérarchiques.
Ce paradigme peut regrouper des fonctionnalités hétérogènes de manière basée sur les données. Cependant, deux goulots d’étranglement majeurs freinent encore les performances. Le premier est l’agrégation de fonctionnalités inefficace. Bien que les cartes d’attention globale réalisent automatiquement l’alignement des caractéristiques entre les images RVB et les points lidar, le coût de calcul est élevé. La seconde est une synchronisation complexe améliorée des données entre les images et les points. GT-AUG est une étape clé pour les détecteurs d'objets 3D hautes performances, mais comment maintenir la cohérence sémantique entre les points et les images pendant la formation reste un problème complexe.
Comme le montre la figure, AutoAlignV2 se compose de deux parties : le module Cross-domain DeformCAFA et la Stratégie d'amélioration des données GT-AUG sensible à la profondeur. Une stratégie de formation d'abandon au niveau de l'image est également proposée pour permettre au modèle d'être. façon plus dynamique de raisonner.
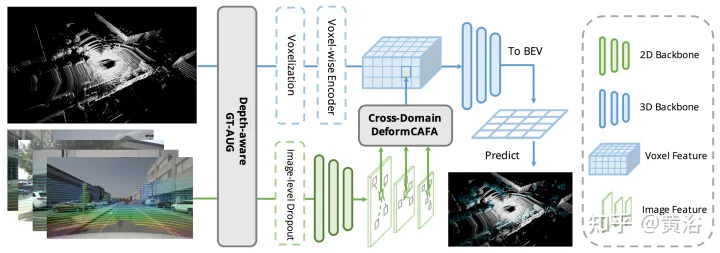
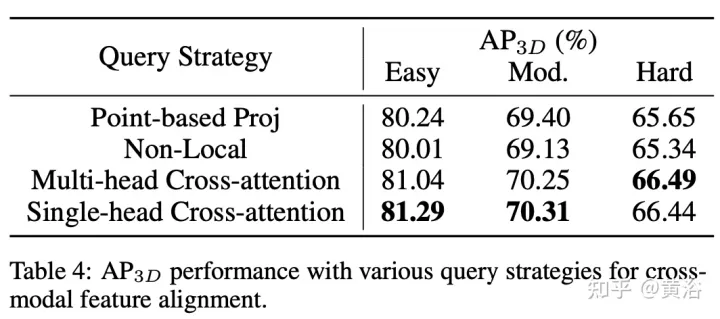
Le goulot d'étranglement de CAFA est de traiter tous les pixels comme des emplacements spatiaux possibles. Sur la base des propriétés des images 2D, les informations les plus pertinentes se trouvent principalement dans des emplacements géométriquement adjacents. Il n’est donc pas nécessaire de considérer tous les emplacements, mais seulement quelques points clés. Comme le montre la figure, une nouvelle opération inter-domaines DeformCAFA est introduite ici, qui réduit considérablement l'échantillonnage des candidats et détermine dynamiquement les zones de points clés du plan d'image pour chaque fonctionnalité de requête de voxel.
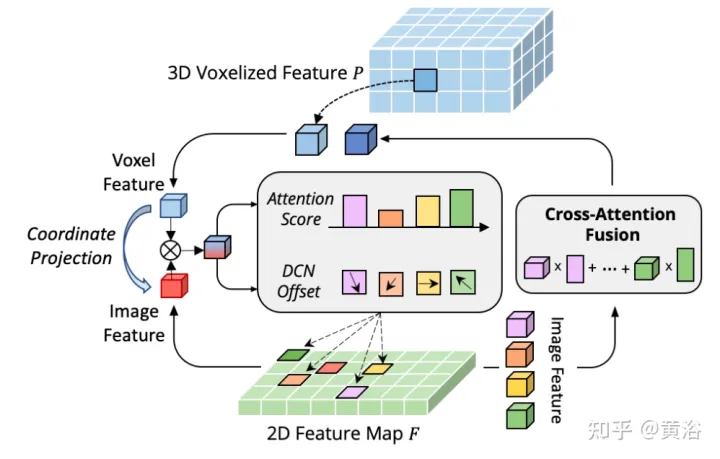
Avec l'aide de décalages d'échantillonnage générés dynamiquement, DeformCAFA est capable de modéliser les relations inter-domaines plus rapidement que les opérations ordinaires. Capable d'effectuer une agrégation de fonctionnalités multicouches, c'est-à-dire d'utiliser pleinement les informations hiérarchiques fournies par la couche FPN. Un autre avantage de DeformCAFA est qu'il maintient explicitement une cohérence de position avec la matrice de projection de la caméra pour obtenir des points de référence. Par conséquent, DeformCAFA peut produire des alignements sémantiquement et positionnellement cohérents même sans adopter le module CFSI proposé dans AutoAlign.
Par rapport aux opérations non locales ordinaires, DeformCAFA de style clairsemé améliore considérablement l'efficacité. Cependant, lorsque les caractéristiques de voxel sont directement appliquées en tant que jetons pour générer des poids d’attention et des décalages déformables, les performances de détection sont à peine comparables, voire pires, à l’interpolation bilinéaire. Après une analyse minutieuse, il existe un problème d'application des connaissances entre domaines dans le processus de génération de jetons. Contrairement à l’opération de déformation originale, qui est généralement réalisée dans un cadre unimodal, l’attention inter-domaines nécessite des informations provenant des deux modalités. Cependant, les caractéristiques des voxels consistent uniquement en représentations du domaine spatial et il est difficile de percevoir les informations dans le domaine de l’image. Il est donc important de réduire l’interaction entre les différentes modalités.
Supposons que la représentation de chaque cible puisse être décomposée sans ambiguïté en deux composants : les informations spécifiques au domaine et les informations spécifiques à l'instance. Le premier fait référence aux données liées à la représentation elle-même, y compris les attributs intégrés des caractéristiques du domaine, tandis que le second représente les informations d'identification de la cible, quel que soit le domaine dans lequel la cible est codée.
Pour la plupart des modèles d'apprentissage profond, l'augmentation des données est un élément essentiel pour obtenir des résultats compétitifs. Cependant, en termes de détection d'objets 3D multimodale, lors de la combinaison de nuages de points et d'images dans l'augmentation des données, il est difficile de maintenir la synchronisation entre les deux, principalement en raison de l'occlusion des objets ou des changements de point de vue. Pour résoudre ce problème, un algorithme d'augmentation de données multimodal simple et efficace nommé GT-AUG sensible à la profondeur est conçu. Cette méthode abandonne l’exigence de processus complexes de filtrage de nuages de points ou d’annotation fine de masque du domaine d’image. Au lieu de cela, les informations de profondeur sont introduites à partir des annotations d'objets 3D jusqu'aux régions d'images mélangées.
Plus précisément, étant donné une cible virtuelle P à coller, suivez la même implémentation 3D de GT-AUG. Quant au domaine de l’image, il est d’abord trié du lointain au proche. Pour chaque cible à coller, la même zone est recadrée de l'image d'origine et combinée sur l'image cible avec un rapport de fusion de α. La mise en œuvre détaillée est présentée dans l’algorithme 1 ci-dessous.

GT-AUG, sensible à la profondeur, suit la stratégie d'augmentation uniquement dans le domaine 3D, mais maintient en même temps les plans d'image synchronisés grâce à un copier-coller basé sur une confusion. Le point clé est qu'après avoir collé des correctifs améliorés sur l'image 2D d'origine, la technologie MixUp ne supprimera pas complètement les informations correspondantes. Au lieu de cela, il atténue la compacité de ces informations par rapport à la profondeur pour garantir que les caractéristiques des points correspondants existent. Plus précisément, si une cible est obstruée n fois par d'autres instances, la transparence de la zone cible diminue d'un facteur (1− α)^n en fonction de son ordre de profondeur.
Comme le montre la figure, voici quelques exemples améliorés :

En fait, les images sont généralement une option de saisie que tous les systèmes de détection 3D ne prennent pas en charge. Par conséquent, une solution de détection multimodale plus réaliste et applicable devrait adopter une approche de fusion dynamique : lorsque l'image n'est pas disponible, le modèle détecte la cible sur la base du nuage de points d'origine lorsque l'image est disponible, le modèle effectue une fusion de caractéristiques et ; produit de meilleures prédictions. Pour atteindre cet objectif, une stratégie de formation par suppression au niveau de l'image est proposée pour supprimer de manière aléatoire les caractéristiques de l'image regroupées au niveau de l'image et les remplir de zéros pendant la formation. Comme le montre la figure : (a) fusion d’images (b) fusion d’abandon au niveau de l’image ;
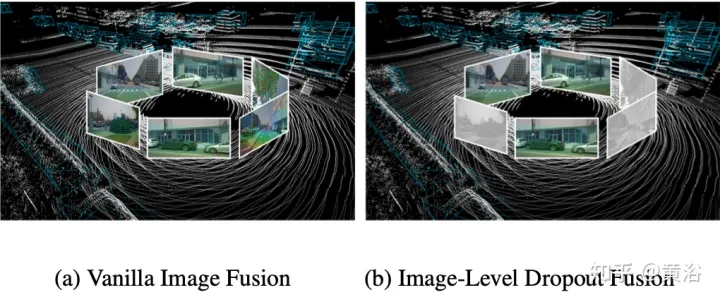
En raison de la perte intermittente des informations sur l'image, le modèle devrait progressivement apprendre à utiliser les fonctionnalités 2D comme entrée alternative.



Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Introduction au framework utilisé par vscode
Introduction au framework utilisé par vscode
 Comment configurer l'actualisation automatique d'une page Web
Comment configurer l'actualisation automatique d'une page Web
 Type de vulnérabilité du système
Type de vulnérabilité du système
 Comment trier dans Excel
Comment trier dans Excel
 Méthode de robot d'exploration Python pour obtenir des données
Méthode de robot d'exploration Python pour obtenir des données
 Solution aux caractères tronqués lors de l'ouverture d'Excel
Solution aux caractères tronqués lors de l'ouverture d'Excel
 Quels serveurs y a-t-il sur le Web ?
Quels serveurs y a-t-il sur le Web ?
 Mot de passe WiFi
Mot de passe WiFi





















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



