

 développement back-end
Tutoriel Python
Présentez brièvement l'exemple de téléchargement automatique d'emails en Python
développement back-end
Tutoriel Python
Présentez brièvement l'exemple de téléchargement automatique d'emails en Python
Présentez brièvement l'exemple de téléchargement automatique d'emails en Python

Cet article vous apporte des connaissances pertinentes sur Python. Il présente en détail comment utiliser le langage Python pour réaliser des fonctions de téléchargement automatique d'e-mails et d'analyse des pièces jointes. L'exemple de code dans l'article est expliqué en détail. J'espère que cela sera utile à tout le monde.

[Recommandation associée : Tutoriel vidéo Python3 ]
Avant de commencer à coder, comprenons d'abord les trois protocoles du service de messagerie :
1. Protocole SMTP
SMTP (Simple Mail Transfer Protocol), le Protocole de transfert de courrier simple. Elle équivaut à une station de transfert et envoie des emails au client.
2. Protocole POP3
POP3 (Post Office Protocol 3), la troisième version du protocole du bureau de poste, est la première norme de protocole hors ligne pour le courrier électronique. Ce protocole télécharge les e-mails sur l'ordinateur local et ne se synchronise pas avec le serveur. L'inconvénient est qu'il est plus susceptible de perdre des e-mails ou de télécharger les mêmes e-mails plusieurs fois.
3. Protocole IMAP
IMAP (Internet Mail Access Protocol), qui est le protocole d'accès au courrier interactif. Ce protocole se connecte aux boîtes aux lettres distantes pour un fonctionnement direct et synchronise le contenu avec le serveur.
Présentons ensuite le package de messagerie
Le composant central de ce package est le « modèle objet » qui représente les messages électroniques. Les applications interagissent avec ce package principalement via l'interface de modèle objet définie dans le sous-module de message. Les applications peuvent utiliser cette API pour poser des questions sur les e-mails existants, créer de nouveaux e-mails ou ajouter ou supprimer des sous-composants d'e-mail qui utilisent eux-mêmes la même interface de modèle objet. Autrement dit, selon la nature des messages électroniques et de leurs sous-composants MIME, le modèle objet de courrier électronique est une structure arborescente de tous les objets qui fournissent l'API EmailMessage.
Ensuite, nous utilisons un code spécifique pour implémenter les fonctions de connexion au client de messagerie, de téléchargement d'e-mails et d'analyse du contenu des pièces jointes aux e-mails.
Nous devons d'abord définir une classe d'analyse d'e-mail, qui nécessite trois variables :
1. L'adresse du service imap à laquelle appartient l'e-mail ;
3. nécessitent une politique de sécurité différente, par exemple, la boîte aux lettres qq nécessite une vérification par SMS et obtient le code d'autorisation de connexion au lieu du mot de passe en texte brut pour se connecter au client distant】
class Email_parse:
def __init__(self,remote_server_url,email_url,password):
# imap服务地址
self.remote_server_url = remote_server_url
# 邮箱账号
self.email_url = email_url
# 邮箱密码
self.password = passwordDéfinissez ensuite la fonction d'entrée dans la classe, connectez-vous au client distant , et recevez tous les e-mails sur la première page par défaut. Nous récupérons le sujet de l'e-mail et l'imprimons [L'encodage des différents sujets d'e-mail peut être différent, et le binaire doit être transcodé pour s'afficher correctement]
def main_parse_Email(self):
"""入口函数,登录imap服务"""
server = imaplib.IMAP4_SSL(self.remote_server_url, 993)
server.login(self.email_url, self.password)
server.select('INBOX')
status,data = server.search(None,"ALL")
if status != 'OK':
raise Exception('read email error')
emailids = data[0].split()
mail_counts = len(emailids)
print("count:",mail_counts)
# 邮件的遍历是按时间从后往前,这里我们选择最新的一封邮件
for i in range(mail_counts - 1, mail_counts - 2, -1):
status, edata = server.fetch(emailids[i], '(RFC822)')
msg = email.message_from_bytes(edata[0][1])
#获取邮件主题title
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)Parmi elles, la variable msg enregistre le corps de l'e-mail, car msg et tilt seront réutilisés, nous construirons une fonction de classe pour renvoyer msg et title.
def get_email_title(msg):
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)
return titleLors de l'analyse de l'e-mail, nous le divisons en deux parties, le corps de l'e-mail [HTML] et la pièce jointe [xlsx, etc.]. S'il y a une pièce jointe, nous la sauvegarderons dans un chemin fixe. L'analyse de la table ne sera pas décrite en détail. Des packages tels que pandas suffisent pour la gérer.
def get_att(msg):
"""获取附件并下载"""
filename = Email_parse.get_email_name(msg)
for part in msg.walk():
file_name = part.get_param("name")
if file_name:
data = part.get_payload(decode=True)
if data != None:
att_file = open('./src/' + filename, 'wb')
att_file.write(data)
att_file.close()
else:
passPour le contenu du corps de l'e-mail, nous analysons directement le code HTML et enregistrons le contenu du texte directement dans un fichier .txt pour une lecture facile.
def get_text_from_HTML(msg):
"""获取邮件中的html"""
filename = Email_parse.get_email_name(msg)
current_title = Email_parse.get_email_title(msg)
print("filename:",filename,type(filename))
for part in msg.walk():
if not part.is_multipart():
result = part.get_payload(decode=True)
result = result.decode('gbk')
f = open(f'./src/{current_title}.txt','w')
f.write(result)
f.close()
return resultLe code complet est le suivant :
import email
import imaplib
from email.header import decode_header
import pandas as pd
import datetime
class Email_parse:
def __init__(self,remote_server_url,email_url,password):
self.remote_server_url = remote_server_url
self.email_url = email_url
self.password = password
def get_att(msg):
filename = Email_parse.get_email_name(msg)
for part in msg.walk():
file_name = part.get_param("name")
if file_name:
data = part.get_payload(decode=True)
if data != None:
att_file = open('./src/' + filename, 'wb')
att_file.write(data)
att_file.close()
else:
pass
def get_email_title(msg):
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)
return title
def get_email_name(msg):
for part in msg.walk():
file_name = part.get_param("name")
if file_name:
h = email.header.Header(file_name)
dh = email.header.decode_header(h)
filename = dh[0][0]
if dh[0][1]:
value, charset = decode_header(str(filename, dh[0][1]))[0]
if charset:
filename = value.decode(charset)
print("附件名称:", filename)
return filename
def main_parse_Email(self):
server = imaplib.IMAP4_SSL(self.remote_server_url, 993)
server.login(self.email_url, self.password)
server.select('INBOX')
status,data = server.search(None,"ALL")
if status != 'OK':
raise Exception('read email error')
emailids = data[0].split()
mail_counts = len(emailids)
print("count:",mail_counts)
for i in range(mail_counts - 1, mail_counts - 2, -1):
status, edata = server.fetch(emailids[i], '(RFC822)')
msg = email.message_from_bytes(edata[0][1])
subject = email.header.decode_header(msg.get('subject'))
if type(subject[-1][0]) == bytes:
title = subject[-1][0].decode(str(subject[-1][1]))
elif type(subject[-1][0]) == str:
title = subject[-1][0]
print("title:", title)
Email_parse.get_att(msg)
Email_parse.get_text_from_HTML(msg)
def get_text_from_HTML(msg):
filename = Email_parse.get_email_name(msg)
current_title = Email_parse.get_email_title(msg)
print("filename:",filename,type(filename))
for part in msg.walk():
if not part.is_multipart():
result = part.get_payload(decode=True)
result = result.decode('gbk')
f = open(f'./src/{current_title}.txt','w')
f.write(result)
f.close()
return result
if __name__ == "__main__":
remote_server_url = 'imap.qq.com'
email_url = "*********@qq.com"
password = "**********"
demo = Email_parse(remote_server_url,email_url,password)
demo.main_parse_Email()Résultats d'exécution :
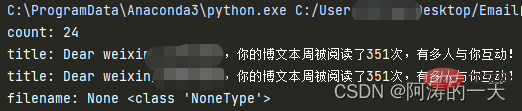 [Recommandations associées :
[Recommandations associées :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Une classe Python peut-elle avoir plusieurs constructeurs?
Jul 15, 2025 am 02:54 AM
Une classe Python peut-elle avoir plusieurs constructeurs?
Jul 15, 2025 am 02:54 AM
Oui, apythonclasscanhavemultipleconstructorshroughalterativetechniques.1.UseaultArgumentsInthe__Init__MethodtoallowflexibleInitializationwithVaryingNumbersofParameters.2.DefineclassMethodsAnterveConstructorForCeleArandScalableableBjectCraturé
 Python pour la gamme de boucle
Jul 14, 2025 am 02:47 AM
Python pour la gamme de boucle
Jul 14, 2025 am 02:47 AM
Dans Python, l'utilisation d'une boucle pour la fonction avec la plage () est un moyen courant de contrôler le nombre de boucles. 1. Utilisez lorsque vous connaissez le nombre de boucles ou avez besoin d'accès aux éléments par index; 2. Plage (arrêt) de 0 à l'arrêt-1, plage (démarrage, arrêt) du début à l'arrêt-1, plage (démarrage, arrêt) ajoute la taille de l'étape; 3. Notez que la plage ne contient pas la valeur finale et renvoie des objets itérables au lieu de listes dans Python 3; 4. Vous pouvez vous convertir en liste via la liste (plage ()) et utiliser la taille de pas négative dans l'ordre inverse.
 Accéder aux données à partir d'une API Web dans Python
Jul 16, 2025 am 04:52 AM
Accéder aux données à partir d'une API Web dans Python
Jul 16, 2025 am 04:52 AM
La clé de l'utilisation de Python pour appeler WebAPI pour obtenir des données est de maîtriser les processus de base et les outils communs. 1. L'utilisation des demandes pour lancer des demandes HTTP est le moyen le plus direct. Utilisez la méthode GET pour obtenir la réponse et utilisez JSON () pour analyser les données; 2. Pour les API qui nécessitent une authentification, vous pouvez ajouter des jetons ou des clés via des en-têtes; 3. Vous devez vérifier le code d'état de réponse, il est recommandé d'utiliser Response.RAISE_FOR_STATUS () pour gérer automatiquement les exceptions; 4. Face à l'interface de pagination, vous pouvez demander différentes pages et ajouter des retards pour éviter les limitations de fréquence; 5. Lors du traitement des données JSON renvoyées, vous devez extraire des informations en fonction de la structure et les données complexes peuvent être converties en données
 python une ligne si d'autre
Jul 15, 2025 am 01:38 AM
python une ligne si d'autre
Jul 15, 2025 am 01:38 AM
Python's Onelineifelse est un opérateur ternaire, écrit comme XifConditionelSey, qui est utilisé pour simplifier le jugement conditionnel simple. Il peut être utilisé pour une affectation variable, tel que status = "adulte" ifage> = 18Else "mineur"; Il peut également être utilisé pour renvoyer directement les résultats dans des fonctions, telles que Deget_Status (âge): renvoyer "adulte" ifage> = 18else "mineur"; Bien que l'utilisation imbriquée soit prise en charge, comme le résultat = "A" i
 Comment lire un fichier JSON dans Python?
Jul 14, 2025 am 02:42 AM
Comment lire un fichier JSON dans Python?
Jul 14, 2025 am 02:42 AM
La lecture des fichiers JSON peut être implémentée dans Python via le module JSON. Les étapes spécifiques sont les suivantes: utilisez la fonction Open () pour ouvrir le fichier, utilisez json.load () pour charger le contenu, et les données seront renvoyées dans un formulaire de dictionnaire ou de liste; Si vous traitez les chaînes JSON, vous devez utiliser JSON.loads (). Les problèmes communs incluent les erreurs de chemin de fichier, le format JSON incorrect, les problèmes de codage et les différences de conversion du type de données. Faites attention à la précision du chemin, à la légalité du format, aux paramètres d'encodage et à la cartographie des valeurs booléennes et null.
 Python pour Loop pour lire la file ligne par ligne
Jul 14, 2025 am 02:47 AM
Python pour Loop pour lire la file ligne par ligne
Jul 14, 2025 am 02:47 AM
L'utilisation d'une boucle pour lire les fichiers ligne par ligne est un moyen efficace de traiter les fichiers volumineux. 1. L'utilisation de base consiste à ouvrir le fichier via Openn () et à gérer automatiquement la fermeture. Combiné avec ForLineInfile pour traverser chaque ligne. line.strip () peut supprimer les ruptures de ligne et les espaces; 2. Si vous avez besoin d'enregistrer le numéro de ligne, vous pouvez utiliser l'énumération (fichier, start = 1) pour permettre au numéro de ligne de démarrer à partir de 1; 3. Lors du traitement des fichiers non ASCII, vous devez spécifier des paramètres d'encodage tels que UTF-8 pour éviter les erreurs de codage. Ces méthodes sont concises et pratiques, et conviennent à la plupart des scénarios de traitement de texte.
 chaîne de cas de cas Python Comparez si
Jul 14, 2025 am 02:53 AM
chaîne de cas de cas Python Comparez si
Jul 14, 2025 am 02:53 AM
Le moyen le plus direct de faire des comparaisons de chaînes insensibles à des cas dans Python est d'utiliser .Lower () ou .upper () à comparer. Par exemple: str1.lower () == str2.lower () peut déterminer s'il est égal; Deuxièmement, pour le texte multilingue, il est recommandé d'utiliser une méthode Casefold () plus approfondie, telle que "Straß" .Casefold () sera converti en "strasse", tandis que .Lower () peut conserver des caractères spécifiques; De plus, il doit être évité d'utiliser directement == Comparaison directement, à moins que le cas ne soit confirmé comme cohérent, il est facile de provoquer des erreurs logiques; Enfin, lors du traitement de la saisie, de la base de données ou de la correspondance des utilisateurs
 Comment utiliser la fonction de carte dans Python
Jul 15, 2025 am 02:52 AM
Comment utiliser la fonction de carte dans Python
Jul 15, 2025 am 02:52 AM
La fonction MAP () de Python implémente une conversion de données efficace en agissant comme fonctions spécifiées sur chaque élément de l'objet itérable à son tour. 1. Son utilisation de base est la carte (fonction, itérable), qui renvoie un objet MAP "Loot Lazy", qui est souvent converti en List () pour afficher les résultats; 2. Il est souvent utilisé avec Lambda, qui convient à une logique simple, comme la conversion des chaînes en majuscules; 3. Il peut être transmis dans plusieurs objets itérables, à condition que le nombre de paramètres de fonction correspond, tels que le calcul du prix actualisé et de la remise; 4. Les techniques d'utilisation comprennent la combinaison de fonctions intégrées pour taper rapidement la conversion, la gestion des situations similaires à Zip () et d'éviter la nidification excessive pour affecter la lisibilité. Masterring Map () peut rendre le code plus concis et professionnel
