


Cet article vous apporte des connaissances pertinentes sur java, qui présente principalement des problèmes liés aux considérations de collection et aux structures sous-jacentes, y compris l'interface de carte, la classe HashMap, la classe HashTable, la classe Properties et la classe d'outils Collections, etc. Du contenu, j'espère que ce sera utile à tout le monde.

Apprentissage recommandé : "Tutoriel vidéo Java"
1. Notes (pratiques)
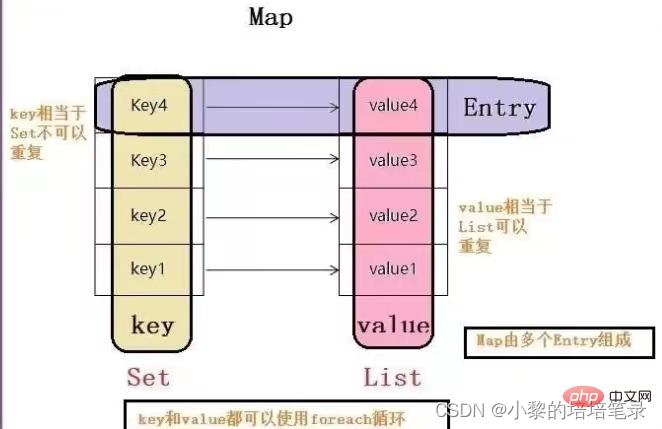
- Carte et Collection existent côte à côte. Utilisé pour enregistrer des données avec des relations de mappage : Clé-Valeur (éléments à double colonne)
- La clé et la valeur dans Map peuvent être n'importe quelle donnée de type référence, qui sera encapsulée dans l'objet HashMap$Node
- Map Le La clé ne peut pas être répétée pour la même raison que le HashSet. La valeur dans la carte peut être répétée. La clé de la carte peut être nulle et la valeur peut également être nulle. Cependant, notez qu'une seule clé nulle peut exister, alors que plusieurs valeurs nulles peuvent exister. La classe String est souvent utilisée comme clé de Map. Il existe une relation unidirectionnelle entre la clé et la valeur. c'est-à-dire que grâce à la clé spécifiée, vous pouvez toujours trouver la valeur correspondante
- 2. Diagramme clé-valeur
- 3. Méthodes courantes de l'interface Map
Map map = new HashMap(); map.put("第一", "节点1"); map.put("第二", "节点2"); map.put("第三", "节点3"); map.put("第四", "节点4");Copier après la connexion(1)supprimer : . Supprimer la relation de mappage en fonction de la cléget :
(2)map.remove("第二");Copier après la connexionCopier après la connexionObtenir la valeur en fonction de la clé
Object val = map.get("第三");Copier après la connexionCopier après la connexion(3)size :
Obtenir le nombre d'éléments
(4) estVide :System.out.println("key-value=" + map.size());Copier après la connexionCopier après la connexionDéterminez si le numéro est 0
System.out.println( map.isEmpty() ); //FalseCopier après la connexionCopier après la connexion(5)clear :
Effacervaleur-clé
Trouver si la clé existe(6)contientClé :map.clear();Copier après la connexionCopier après la connexion
4. Méthodes de traversée de carte (1) Quatre méthodes de traverséeSystem.out.println(map.containsKey("第四")); //trueCopier après la connexionCopier après la connexioncontainsKey : Rechercher si la clé existe
keySet : Obtenir toutes les clés
entrySet : Obtenez toutes les relations K-V values : Obtenez toutes les valeurs
- (2) méthode de parcours keySet
Map map = new HashMap();Copier après la connexion//先取出 所有的 Key , 通过 Key 取出对应的 Value Set keyset = map.keySet(); //(1)第一种方式: 增强 for循环 for (Object key : keyset) { System.out.println(key + "-" + map.get(key)); } //(2)第二种方式:迭代器 Iterator iterator = keyset.iterator(); while (iterator.hasNext()) { Object key = iterator.next(); System.out.println(key + "-" + map.get(key)); }Copier après la connexion- (3) valeurs Méthode de parcours
- (4) méthode de traversée EntrySet
//把所有的 values 取出 Collection values = map.values(); //注意:这里可以使用所有的 Collections 使用的遍历方法 //(1)取出所有的 value 使用增强 for 循环 for (Object value : values) { System.out.println(value); } //(2)取出所有的 value 使用迭代器 Iterator iterator2 = values.iterator(); while (iterator2.hasNext()) { Object value = iterator2.next(); System.out.println(value); }Copier après la connexion
//通过 EntrySet 来获取 key-value Set entrySet = map.entrySet(); // EntrySet<Map.Entry<K,V>> //(1)使用 EntrySet 的 增强 for循环遍历方式 for (Object entry : entrySet) { //将 entry 转成 Map.Entry Map.Entry m = (Map.Entry) entry; System.out.println(m.getKey() + "-" + m.getValue()); } //(2)使用 EntrySet 的迭代器遍历方式 Iterator iterator3 = entrySet.iterator(); while (iterator3.hasNext()) { //HashMap$Node -实现-> Map.Entry (getKey,getValue) Object entry = iterator3.next(); //向下转型 Map.Entry Map.Entry m = (Map.Entry) entry; System.out.println(m.getKey() + "-" + m.getValue()); }Copier après la connexion
1、注意事项
- Map接口的常用实现类:HashMap、Hashtable 和 Properties
- HashMap是 Map 接口使用频率最高的实现类(重点掌握)
- HashMap 是以key-value 一对的方式来存储数据(HashMap$Node类型)
- key 不能重复, 但是value值可以重复,二者都允许使用null键。
- 如果添加相同的key,则会覆盖原来的key-value,等同于修改(key不会替换,value会替换)
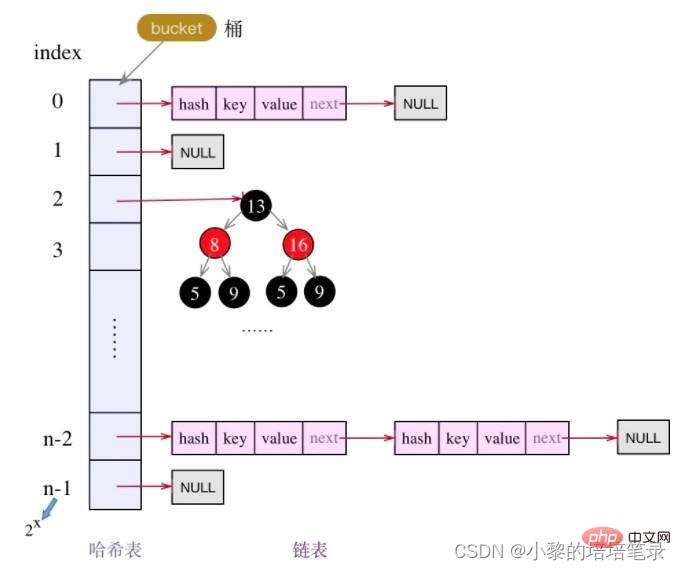
- 与HashSet一样, 不保证映射的顺序, 因为底层是以Hash表的方式来存储的(jdk8的HashMap 底层数组+链表+红黑树)
- HashMap没有实现同步,因此是线程不安全的,方法没有做同步互斥的操作,没有
synchronized 关键字2、底层机制
- HashMap底层维护了Node类型的数组table,默认为null
- 当创建对象时, 将加载因子(loadfactor)初始化为0.75
- 当添加key-value时,通过key的哈希值得到在table的素引。 然后判断该索引处是否有元素,如果没有元素直接添加。 如果该索引处有元素, 继续判断该元素的key和准备加入的key是否相等, 如果相等,则直接替换value; 如果不相等需要判断是树结构还是链表结构,做出相应处理。 如果添加时发现容量不够, 则需要扩容。
- 第1次添加, 则需要扩容table容量为16, 临界值(threshold)为12 (16*0.75)
- 以后再扩容, 则需要扩容table容量为原来的2倍(32). 临界值为原来的2倍,即24(32*0.75),依次类推
- 在Java8中,如果一条链表的元素个数超过 TREEIFY_THRESHOLD(默认是8),并且 table的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进行树化(红黑树)
3、底层原理图
1、基本介绍
- 存放的元素是键值对:即Key-Value
- HashTable 的键和值都不能为null
- HashTable 的使用方法基本上和HashMap一样
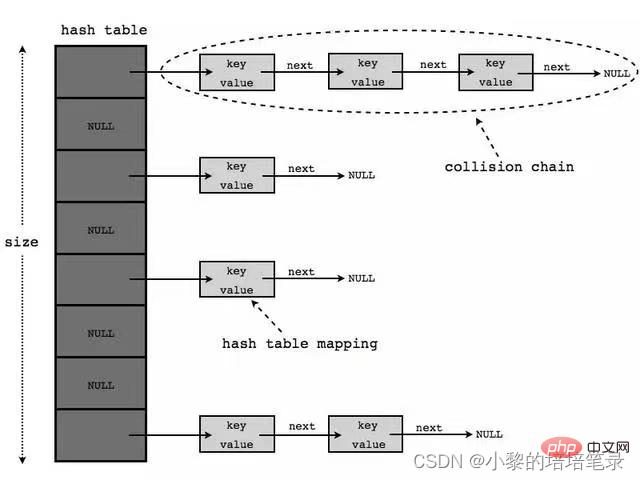
- HashTable 是线程安全的,HashMap 是线程不安全
- Hashtable 和 HashMap 的比较:
2、底层结构示意图
3、HashTable 常用方法
Map map = new HashTable(); map.put("第一", "节点1"); map.put("第二", "节点2"); map.put("第三", "节点3"); map.put("第四", "节点4");Copier après la connexion(1)remove : 根据键删除映射关系
map.remove("第二");Copier après la connexionCopier après la connexion(2)get :根据键获取值
Object val = map.get("第三");Copier après la connexionCopier après la connexion(3)size : 获取元素个数
System.out.println("key-value=" + map.size());Copier après la connexionCopier après la connexion(4)isEmpty : 判断个数是否为 0
System.out.println( map.isEmpty() ); //FalseCopier après la connexionCopier après la connexion(5)clear : 清除 key-value
map.clear();Copier après la connexionCopier après la connexion(6)containsKey : 查找键是否存在
System.out.println(map.containsKey("第四")); //trueCopier après la connexionCopier après la connexion
1、基本介绍
- Properties 类继承自HashTable类并且实现了Map接口,也是使用一种键值对的形
式来保存数据。(可以通过 key-value 存放数据,当然 key 和 value 也不能为 null)- 它的使用特点和Hashtable类似
- Properties 还可以用于从xx.properties文件中,加载数据到Properties类对象,并进行读取和修改(在IO流中会详细介绍)
2、常用方法
Properties properties = new Properties();Copier après la connexion(1)put 方法
properties.put(null, "abc");//抛出 空指针异常 properties.put("abc", null); //抛出 空指针异常 properties.put("lic", 100); properties.put("lic", 88);//如果有相同的 key , value 被替换Copier après la connexion(2)get 方法
System.out.println(properties.get("lic"));Copier après la connexion(3)remove 方法
properties.remove("lic");Copier après la connexion
1、基本介绍
- Collections 是一个操作Set. List 和 Map等集合的工具类
- Collections中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作排序
2、排序操作(均为static方法)
方法 作用 reverse(List) 反转 List 中元素的顺序 shuffle(List) 对 List集合元素进行随机排序 sort(List) 根据元素的自然顺序对指定List集合元素按升序排序 sort(List,Comparator) 根据指定的Comparator 产生的顺序对 List集合元素进行排序 swap(List, int i, int j) 将指定list 集合中的 i 处元素和 j 处元素进行交换 List list = new ArrayList(); list.add("第一个"); list.add("第二个"); list.add("第三个");Copier après la connexion(1)reverse(List): 反转 List 中元素的顺序
Collections.reverse(list);Copier après la connexion(2)shuffle(List):对 List 集合元素进行随机排序
for (int i = 0; i < 5; i++) { Collections.shuffle(list); System.out.println("list=" + list); }Copier après la connexion(3)sort(List): 根据元素的自然顺序对指定 List 集合元素按升序排序
Collections.sort(list);Copier après la connexion(4)sort(List,Comparator): 根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
//匿名内部类 Collections.sort(list, new Comparator() { @Override public int compare(Object o1, Object o2) { return ((String) o2).length() - ((String) o1).length(); } });Copier après la connexion(5)swap(List,int, int): 将指定 list 集合中的 i 处元素和 j 处元素进行交换
Collections.swap(list, 0, 1);Copier après la connexion.......................................................
3、查找、替换操作
方法 作用 Object max(Collection) 根据元素的自然顺序,返回给定集合中的最大元素 Object max(Collection, Comparator) 根据 Comparator 指定的顺序,返回给定集合中的最大元素 Object min(Collection) 根据元素的自然顺序,返回给定集合中的最小元素 Object min(Collection, Comparator) 根据 Comparator 指定的顺序,返回给定集合中的最小元素 int frequency(Collection, Object) 返回指定集合中指定元素的出现的次数 void copy(List dest,List src) 将src中的内容复制到dest中 boolean replaceAll(List list, Object oldVal, Object newVal) 使用新值替换 List对象的所有旧值 (1)Object max(Collection): 根据元素的自然顺序,返回给定集合中的最大元素
System.out.println("自然顺序最大元素=" + Collections.max(list))Copier après la connexion(2)Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
//匿名内部类 Object maxObject = Collections.max(list, new Comparator() { @Override public int compare(Object o1, Object o2) { return ((String)o1).length() - ((String)o2).length(); } })Copier après la connexion(3)int frequency(Collection,Object): 返回指定集合中指定元素的出现次数
System.out.println("第一个 出现的次数=" + Collections.frequency(list, "第一个"));Copier après la connexion(4)void copy(List dest,List src): 将 src 中的内容复制到 dest 中
ArrayList dest = new ArrayList(); //为了完成一个完整拷贝,我们需要先给 dest 赋值,大小和 list.size()一样 for(int i = 0; i < list.size(); i++) { dest.add(""); } //拷贝 Collections.copy(dest, list);Copier après la connexion(5)boolean replaceAll(List list,Object oldVal,Object newVal): 使用新值替换 List 对象的所有旧值
//如果 list 中,有 “第一个” 就替换成 “0” Collections.replaceAll(list, "第一个", "0");Copier après la connexion
1、开发中如何选择集合来使用?
(1)第一步:先判断存储的类型:是一组对象?还是一组键值对?
(2)一组对象: Collection接口
List允许重复:
增删多 : LinkedList [底层维护了一个双向链表]
改查多 : ArrayList 底层维护Object类型的可变数组]
Set不允许重复:
无序 : HashSet {底层是HashMap,维护了一个哈希表即(数组+链表+红黑树)}
排序 : TreeSet
插入和取出顺序一致 : LinkedHashSet , 维护数组+双向链表
(3)一组键值对: Map 接口
键无序 : HashMap [底层是:哈希表 jdk7:数组+链表,jdk8:数组+链表+红黑树]
键排序 : TreeMap
键插入和取出顺序一致 : LinkedHashMap读取文件 :Properties
2. Comment HashSet et TreeSet parviennent-ils respectivement à supprimer les doublons ?
Le mécanisme de déduplication de HashSet : hashCode() + equals(). La couche inférieure stocke d'abord l'objet et effectue des opérations pour obtenir une valeur de hachage. L'index correspondant est obtenu via la valeur de hachage. que l'index de la table n'est pas localisé. Les données sont stockées directement ; s'il y a des données, une comparaison égale [comparaison transversale] est effectuée. S'ils ne sont pas identiques après comparaison, ajoutez-les ; sinon, ne les ajoutez pas.
Mécanisme de déduplication de TreeSet : Si vous transmettez un objet anonyme Comparator, utilisez la comparaison implémentée pour dédupliquer. Si la méthode renvoie 0, il est considéré comme le même élément ou la même donnée et ne sera pas ajouté. ; Si vous ne transmettez pas d'objet anonyme Comparator, le compareTo de l'interface Compareable implémentée par l'objet que vous avez ajouté sera utilisé pour supprimer les doublons.
Apprentissage recommandé : "Tutoriel vidéo Java"
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!











![Tutoriel de base JavaScript [Opérations DOM BOM que JS doit connaître]](https://img.php.cn/upload/course/000/000/041/61c56ae28d02a390.jpg)
![Analyse approfondie de JavaScript [Le front-end Web doit connaître les compétences de base]](https://img.php.cn/upload/course/000/000/041/61d3ff1c83b43350.jpg)
![Vidéo d'introduction à TypeScript [peut être comprise même sans apprendre JavaScript]](https://img.php.cn/upload/course/000/000/068/6242c0fc4be39373.png)






![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



