



Recommandations d'apprentissage associées : Tutoriel Python
C'est le sujet sur le traitement des données Pandas Dans le deuxième article, parlons de la structure de données la plus importante dans pandas-DataFrame.
Dans l'article précédent, nous avons présenté l'utilisation de Series et avons également mentionné que Series est équivalent à un tableau unidimensionnel, mais pandas encapsule de nombreuses API pratiques et faciles à utiliser pour nous. Le DataFrame peut être simplement compris comme un dict composé de Series, regroupant ainsi les données dans un tableau bidimensionnel. Il nous fournit également de nombreuses interfaces pour le traitement des données au niveau des tables et le traitement des données par lots, ce qui réduit considérablement la difficulté du traitement des données.
DataFrame est une structure de données tabulaire, qui a deux index, à savoir Index de ligne et l'index de colonne nous permettent d'obtenir facilement les lignes et colonnes correspondantes. Cela réduit considérablement la difficulté de trouver des données pour le traitement des données.
Tout d’abord, commençons par le plus simple, comment créer un DataFrame.
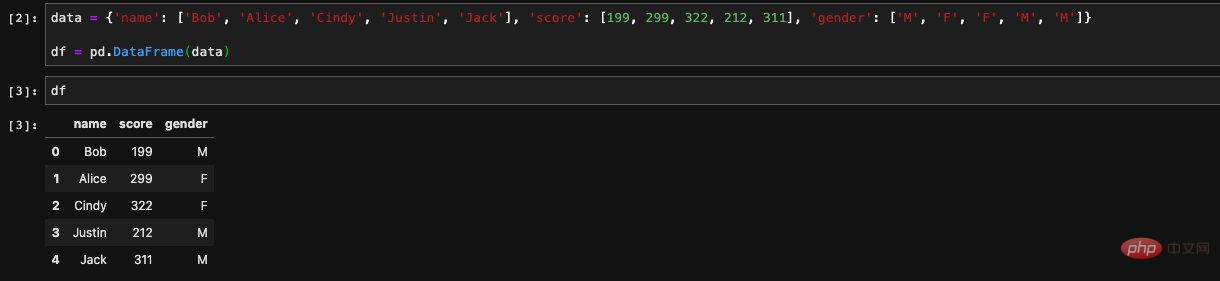
Nous créons un dict avec La clé est le nom de la colonne et la valeur est une liste. Lorsque nous passons ce dict dans le constructeur de DataFrame, il créera un DataFrame pour nous avec la clé comme nom de colonne et la valeur comme valeur correspondante .
Lorsque nous produisons dans jupyter, il affichera automatiquement le contenu du DataFrame sous forme de tableau pour nous.
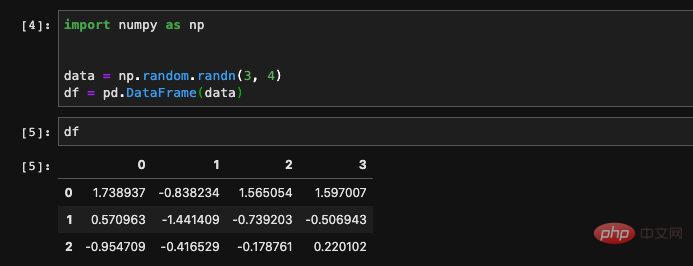
Nous pouvons également créer un DataFrame à partir d'un tableau bidimensionnel numpy, si si nous passons simplement le tableau numpy sans spécifier le nom de la colonne, puis pandas utilisera le numéro comme index pour créer la colonne pour nous :
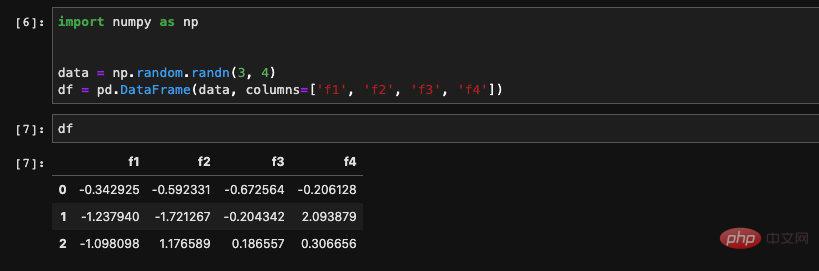
Nous sommes dans Lors de la création, transmettez une liste de chaînes pour le champ Colonnes afin de lui spécifier un nom de colonne :
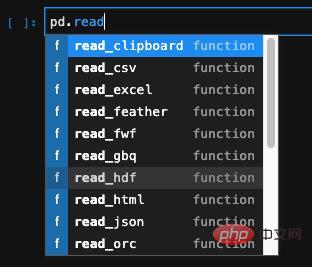
Une autre fonction très puissante des pandas est qu'ils peuventCréez un DataFrame en lisant les données de fichiers dans différents formats, tels que Excel, CSV ou même des bases de données couramment utilisés.
Pour les données structurées telles qu'excel, csv, json, etc., pandas fournit une API spéciale. Nous pouvons trouver l'API correspondante et l'utiliser :
et d'autres paramètres via . Par exemple, dans l'article précédent vérifiant l'effet de réduction de dimensionnalité de la PCA, nous lisons les données d'un fichier au format .data. Le délimiteur entre les colonnes de ce fichier est un espace, et non la virgule ou le caractère de tableau de csv. Nous passons le paramètre sep à et spécifions le séparateur pour terminer la lecture des données.

L'en-tête par défaut=0, c'est-à-dire la première. La ligne est utilisée comme nom de colonne. Si le nom de la colonne n'existe pas dans les données, header=None doit être spécifié, sinon des problèmes surviendront. Nous avons rarement besoin d'utiliser des noms de colonnes à plusieurs niveaux, donc généralement la méthode la plus couramment utilisée consiste à prendre la valeur par défaut ou à la définir égale à Aucun.
Parmi toutes cesfaçons de créer un DataFrame, la plus couramment utilisée est la dernière , la lecture à partir d'un fichier. Car lorsque nous faisons du machine learning ou participons à certains concours dans Kaggle, les données sont souvent toutes prêtes et nous sont fournies sous forme de fichiers. Il y a très peu de cas où nous devons créer nous-mêmes des données. S'il s'agit d'un scénario de travail réel, même si les données ne seront pas stockées dans des fichiers, il y aura une source, généralement stockée sur certaines plateformes Big Data, et le modèle obtiendra les données d'entraînement de ces plateformes.
Donc, en général, nous utilisons rarement d'autres méthodes de création de DataFrame. Nous avons une certaine compréhension et nous concentrons sur la maîtrise de la méthode de lecture à partir de fichiers.Ce qui suit présente quelques opérations courantes des pandas. Ces opérations ont été effectuées avant que j'apprenne à utiliser systématiquement les pandas. .Déjà compris. La raison pour le comprendre est également très simple, car ils sont si couramment utilisés qu'on peut dire qu'il s'agit de contenu de bon sens qui doit être connu.
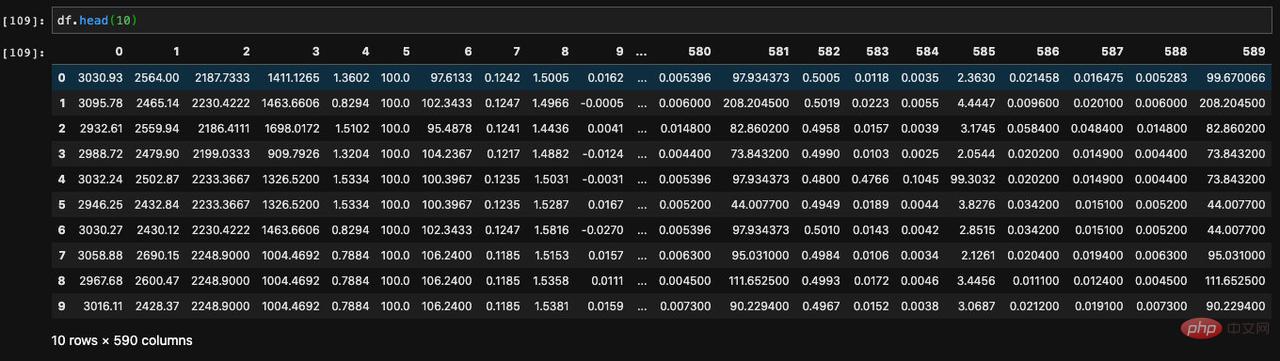
Lorsque nous exécutons l'instance DataFrame dans jupyter, toutes les données du DataFrame seront imprimées pour nous, s'il y a trop de lignes de données, la partie médiane sera omise sous forme d'ellipses. Pour un DataFrame avec une grande quantité de données, nous ne le sortons et ne l'affichons généralement pas directement comme ceci, mais choisissons d'afficher les premiers ou les derniers éléments de données. Deux API sont nécessaires ici.
La méthode d'affichage des premières données est appelée head Elle accepte un paramètre et nous permet de le spécifier pour afficher le nombre de données que nous spécifions depuis le début.
Puisqu'il existe une API pour afficher les éléments précédents, il existe également une API pour afficher les derniers éléments. Une telle API est appelée tail. Grâce à lui, nous pouvons visualiser le dernier nombre de données spécifié dans le DataFrame :

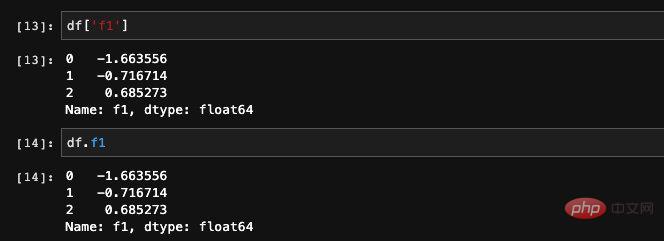
Nous l'avons évoqué précédemment pour DataFrame, c'est en fait équivalent à un dict composé de Series. Puisqu'il s'agit d'un dict, nous pouvons naturellement obtenir la série spécifiée en fonction de la valeur clé.
Il existe deux méthodes pour obtenir la colonne spécifiée dans DataFrame. Nous pouvons ajouter le nom de la colonne ou nous pouvons trouver l'élément via dict pour interroger :
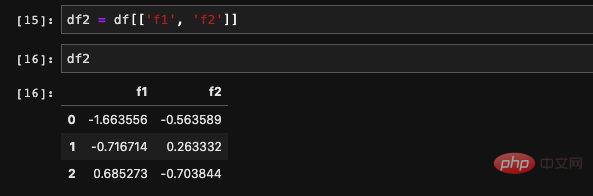
Nous pouvons également lire plusieurs colonnes en même temps S'il y a plusieurs colonnes, une seule méthode est prise en charge, qui consiste à interroger des éléments via dict. Il permet de recevoir une liste entrante et de retrouver les données correspondant aux colonnes de la liste. Le résultat renvoyé est un nouveau DataFrame composé de ces nouvelles colonnes.
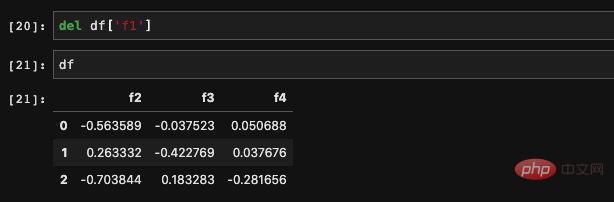
Nous pouvons supprimer une colonne dont nous n'avons pas besoin avec del :
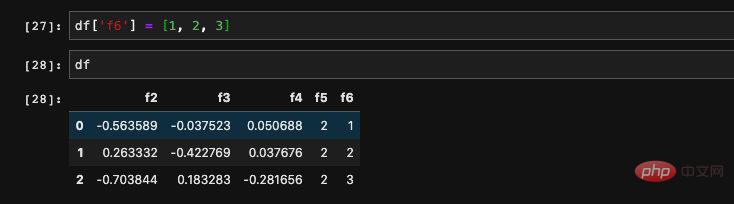
Nous voulons créer a new Les colonnes sont également très simples. Nous pouvons attribuer directement au DataFrame tout comme l'affectation dict :
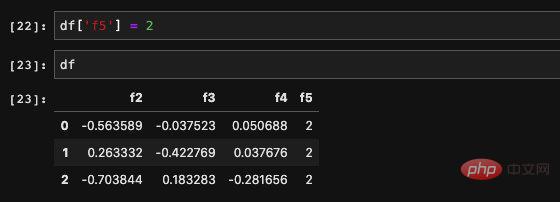
peut aussi être un tableau :
utiliser .values pour obtenir le tableau numpy correspondant au DataFrame :

chaque colonne du DataFrame a un type distinct , Après avoir été converties en un tableau numpy, toutes les données partagent le même type. Les pandas trouveront ensuite un type commun pour toutes les colonnes, c'est pourquoi vous obtenez souvent un type d'objet. Par conséquent, il est préférable de vérifier le type avant d'utiliser .values pour s'assurer qu'il n'y aura pas d'erreurs dues au type.
Les organisations professionnelles ont fait des statistiques. Pour un ingénieur en algorithmique, environ 70% du temps sera investi dans le traitement des données. Le temps consacré à l'écriture du modèle et à l'ajustement des paramètres peut être inférieur à 20 %. Nous pouvons donc voir la nécessité et l'importance du traitement des données. Dans le domaine de Python, pandas est le meilleur scalpel et la meilleure boîte à outils pour le traitement des données. J'espère que tout le monde pourra le maîtriser.
Si vous souhaitez en savoir plus sur la programmation, faites attention à la rubrique Formation php !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



