



Il existe de nombreuses introductions au modèle de transaction MySQL sur Internet Avant d'écrire cet article, j'ai également lu de nombreuses informations à titre de référence, dans l'espoir d'approfondir ma compréhension. et complet. Après avoir lu la plupart des articles d'introduction, j'ai trouvé que certains d'entre eux étaient incomplets. Par exemple, certains ne présentent les performances de MySQL que sous plusieurs niveaux d'isolement et ne les expliquent pas d'un point de vue technique. Certains articles sont très complets, mais manquent d’organisation et ne sont pas faciles à comprendre. C'est ce que l'auteur espère vous apporter quelque chose de différent, l'expliquer d'un point de vue technique et faciliter la compréhension.
L'atomicité des transactions nécessite qu'une série d'opérations dans la transaction soit terminée dans son intégralité ou qu'aucune opération ne soit effectuée, et pas seulement la moitié de l'opération doit être effectuée. L'atomicité est facile à implémenter pour les opérations atomiques, tout comme l'implémentation de l'atomicité des transactions au niveau des lignes dans HBase est relativement simple. Mais pour une transaction composée de plusieurs instructions, si une exception se produit lors de l'exécution de la transaction, si l'atomicité doit être assurée, la seule option est de revenir à l'état avant le début de la transaction, comme si la transaction ne s'était jamais produite à tous. Comment y parvenir ?
L'implémentation de l'opération de restauration par MySQL repose entièrement sur le journal d'annulation. Encore une chose, le journal d'annulation est utilisé dans MySQL pour implémenter MVCC en plus d'obtenir la garantie d'atomicité, qui sera également abordée ci-dessous. Utilisez l'annulation pour obtenir l'atomicité. Avant d'exploiter des données, les données avant modification seront d'abord enregistrées dans le journal d'annulation, puis la modification réelle sera effectuée. Si une exception se produit et qu'une restauration est requise, le système peut utiliser la sauvegarde en annulation pour restaurer les données dans leur état avant le démarrage de la transaction. La figure suivante est la structure de données de base représentant les transactions dans MySQL. Les champs liés à l'annulation sont insert_undo et update_undo, qui pointent respectivement vers le journal d'annulation généré par cette transaction.
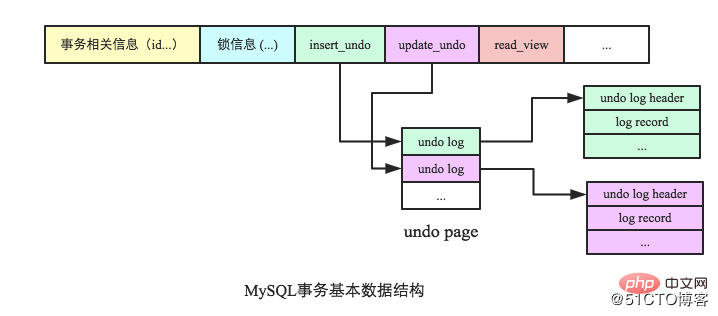
La restauration des transactions trouve le journal d'annulation correspondant en fonction de update_undo (ou insert_undo) et effectue l'opération inverse. Pour les données qui ont été marquées pour suppression, nettoyez et supprimez la marque, et annulez directement la mise à jour pour les données mises à jour ; l'opération d'insertion est légèrement plus compliquée, il faut non seulement supprimer les données, mais également supprimer les données associées ; enregistrements d'index groupés et d'index secondaires.
Le journal d'annulation est un élément de contenu très important dans le noyau MySQL. Il implique beaucoup de connaissances et est complexe, comme :
1. Le journal d'annulation doit être conservé avant les données. est modifié. La persistance du journal d'annulation nécessite Pas besoin d'enregistrer une restauration pour éviter les exceptions de panne ? Si nécessaire, cela impliquera une récupération des temps d'arrêt...
2. Comment implémenter MVCC via le journal d'annulation ?
3. Dans quels scénarios ces journaux annulés peuvent-ils être recyclés et nettoyés ? Comment le nettoyer ?
Le mécanisme d'implémentation de la concurrence d'écriture n'est pas différent de celui de HBase. Les deux sont implémentés à l'aide d'un protocole de verrouillage en deux phases pour ajouter des verrous de ligne aux enregistrements correspondants. Cependant, le mécanisme de verrouillage de ligne dans MySQL est relativement complexe. Il existe différentes situations de verrouillage selon que l'enregistrement de ligne est un index de clé primaire, un index unique, un index non unique ou aucun index.
1. Si la colonne id est un index de clé primaire, MySQL verrouillera uniquement les enregistrements d'index cluster.
2. Si la colonne id est le seul index secondaire, MySQL verrouillera les nœuds feuilles de l'index secondaire et les enregistrements d'index clusterisés.
3. Si la colonne id est un index non unique, MySQL verrouillera tous les nœuds feuilles d'index secondaire qui remplissent la condition (id = 15) et les enregistrements d'index cluster correspondants.
4. Si la colonne id n'est pas indexée, SQL effectuera une analyse complète de la table d'index cluster et chargera les résultats de l'analyse dans la couche SQL Server pour le filtrage. Par conséquent, InnoDB ajoutera d'abord Lock, si la couche SQL Server. le filtre ne remplit pas les conditions, InnoDB libérera le verrou. Par conséquent, InnoDB verrouillera tous les enregistrements analysés, ce qui fait peur !
Ensuite, qu'il s'agisse de RC, RR ou de sérialisation, le contrôle de concurrence d'écriture utilise le mécanisme ci-dessus, je n'entrerai donc pas dans les détails. Ensuite, nous nous concentrerons sur l’analyse des mécanismes de contrôle de concurrence de lecture et d’écriture dans les niveaux d’isolation RC et RR.
Avant d'introduire RC et RR en détail, il est nécessaire d'introduire d'abord le mécanisme MVCC dans MySQL, car RC et RR utilisent tous deux le mécanisme MVCC pour obtenir la concurrence de lecture et d'écriture entre les transactions. C'est juste qu'il existe quelques différences entre les deux dans les détails de mise en œuvre. Les différences spécifiques seront discutées ensuite.
MVCC dans MySQL
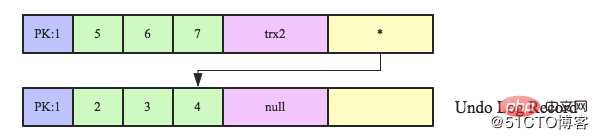
Les quatre premières colonnes sont les valeurs de colonne réelles enregistrées dans la ligne. Ce sur quoi il faut se concentrer, ce sont les deux colonnes cachées DB_TRX_ID et DB_ROLL_PTR (invisibles pour l'utilisateur). Parmi eux, DB_TRX_ID représente l'ID de transaction de la transaction qui modifie la ligne, et DB_ROLL_PTR représente le pointeur vers le segment d'annulation de la ligne. Toutes les données de version enregistrées sur cette ligne sont organisées sous la forme d'une liste chaînée en annulation. pointe en fait vers l'historique de la ligne dans la liste chaînée d'enregistrement.
En supposant maintenant qu'une transaction trx2 modifie la ligne de données, l'enregistrement de la ligne deviendra la figure suivante. DB_TRX_ID est l'ID de transaction (trx2) de la transaction qui a récemment modifié la ligne, et DB_ROLL_PTR pointe vers le. Liste chaînée des enregistrements de l'historique d'annulation :
Après avoir compris les enregistrements de lignes MySQL, examinons la structure de base des transactions. La figure suivante est la structure des données de transaction de MySQL, qui. nous l'avons mentionné ci-dessus. Une fois la transaction démarrée, une structure de données sera créée pour stocker les informations relatives à la transaction, les informations de verrouillage, le journal d'annulation et les informations read_view très importantes.
read_view enregistre la liste de toutes les transactions actives dans l'ensemble de MySQL lorsque la transaction en cours est démarrée, comme le montre la figure ci-dessous. Lorsque la transaction en cours est démarrée, les transactions actives dans le système incluent trx4, trx6, trx7 et trx10. De plus, up_trx_id représente le plus petit ID de transaction dans la liste des transactions en cours au démarrage de la transaction en cours ; low_trx_id représente le plus grand ID de transaction dans la liste des transactions en cours au démarrage de la transaction en cours.
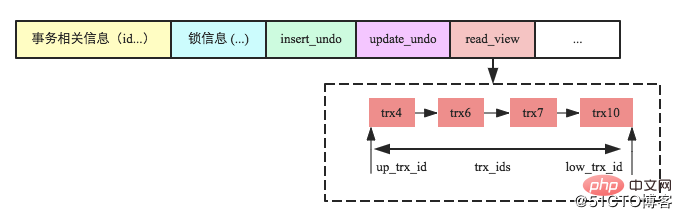
read_view est un point clé dans la mise en œuvre de MVCC. Il est utilisé pour déterminer quelle version de l'enregistrement est visible pour la transaction en cours. Si la transaction en cours veut lire une certaine ligne d'enregistrements et que le numéro de version (ID de transaction) de l'enregistrement de ligne est trxid, alors :
1 Si trxid
2. Si trxid > low_trx_id, cela signifie que la transaction dans laquelle se trouve la ligne a été ouverte après la création de la transaction en cours, donc l'enregistrement de la ligne n'est pas visible pour la transaction en cours.
3. Si up_trx_id
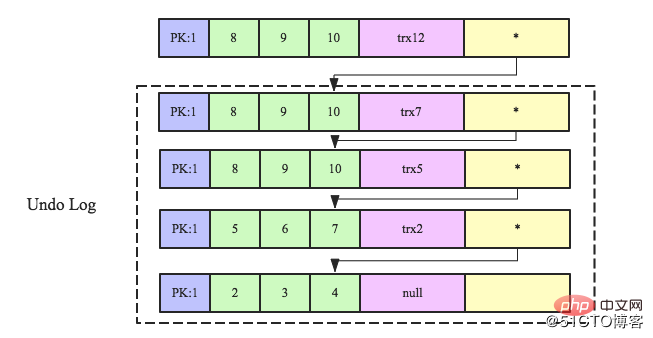
Prenons l'exemple de l'enregistrement de ligne suivant. Cet enregistrement de ligne a plusieurs versions (trx2, trx5, trx7 et trx12), parmi lesquelles trx12 est la dernière version. Découvrez quelle version de la ligne est visible pour la transaction en cours.
1. La dernière version enregistrée dans cette ligne est trx12. En la comparant avec la transaction read_view actuelle, il s'avère que trx12 est supérieure à la plus grande transaction trx10 dans la liste des transactions actives actuelles, indiquant que trx12 a été ouverte. après la création de la transaction en cours, donc Invisible.
2. Vérifiez que la deuxième version la plus récente de l'enregistrement de ligne est trx7. Par rapport à la transaction read_view actuelle, il s'avère que trx7 se situe entre l'ID de transaction minimum et l'ID de transaction maximum de la liste de transactions active actuelle. , indiquant que l'enregistrement de ligne La transaction était active lors de la création de la transaction en cours. Le parcours de la liste active a révélé que trx7 existe, indiquant que la transaction n'a pas encore été soumise, elle n'est donc pas visible pour la transaction en cours.
3. Continuez à afficher la troisième version la plus récente de l'enregistrement, trx5, qui se situe également entre l'ID de transaction minimum et l'ID de transaction maximum de la liste de transactions active actuelle, indiquant que la transaction dans laquelle l'enregistrement de ligne se trouvait dans la transaction en cours lorsque la transaction en cours a été créée. État actif, mais le parcours a détecté que cette version ne figure pas dans la liste des transactions actives, indiquant que la transaction correspondant à trx5 a été soumise (Remarque : il n'y a pas de corrélation entre les transactions. l'heure de soumission et le numéro de transaction. Il est possible que les transactions avec des numéros de transaction plus grands soient soumises en premier, et que les transactions avec des numéros de transaction plus petits soient soumises plus tard), de sorte que l'enregistrement de ligne de la version trx5 soit visible pour la transaction en cours et soit renvoyé directement.
Introduit ci-dessus Le mécanisme de mise en œuvre de la technologie MVCC dans MySQL, mais pour comprendre la visibilité des transactions sous le niveau d'isolement RC, vous devez également comprendre un point essentiel : les transactions sous le niveau d'isolement RC généreront une dernière read_view pour remplacer la read_view d'origine à chaque fois. select est exécuté.

Comme le montre la figure ci-dessus, le côté gauche est la transaction n°1, et l'enregistrement avec id=1 a été interrogé trois fois à différents moments. À droite se trouve la transaction n°2, qui met à jour l'enregistrement avec id=1. Avant la mise à jour, il n’existait qu’une seule version du dossier, mais après la mise à jour, il y en a eu deux versions.
La transaction n°1 générera une dernière read_view à chaque fois qu'elle exécute une requête de sélection sous le niveau d'isolation RC. La liste active des transactions globales générée par les deux premières requêtes contient trx2, donc l'enregistrement trouvé est ancien selon. Réglementation MVCC. Version : le moment de la dernière requête est postérieur à la soumission de la transaction n° 2, donc la liste globale des transactions actives générée n'inclut pas trx2. À l'heure actuelle, l'enregistrement trouvé selon la réglementation MVCC est la dernière version. enregistrer.
Différent du mode RC, transactions en mode RR La dernière read_view ne sera pas générée à chaque fois qu'une sélection est exécutée, mais la read_view sera générée lorsque la transaction est sélectionnée pour la première fois, et ne sera plus modifiée jusqu'à ce que le mode actuel la transaction se termine. Cela peut efficacement éviter les lectures non répétables et rendre les données lues par la transaction en cours cohérentes tout au long du processus de transaction. Le diagramme schématique est le suivant :

Ceci est facile à comprendre. La liste globale des transactions actives utilisée par les trois requêtes est la même, et elles sont toutes générées par read_view pour la. la première fois. Après cela, les enregistrements trouvés doivent être cohérents avec les enregistrements trouvés pour la première fois.
Si vous ne connaissez pas la lecture fantôme, vous pouvez vous référer au premier article de cette série. Comme le montre la figure ci-dessous, la transaction n° 1 a effectué trois requêtes sur la condition de filtre pour id>1, et la transaction n° 2 a effectué une insertion. L'enregistrement inséré vient de remplir la condition id>1. On peut voir que les données obtenues par les trois requêtes sont cohérentes, ce qui est garanti par le mécanisme MVCC du niveau d'isolement RR. De ce point de vue, la lecture fantôme est évitée. Cependant, lorsque la dernière transaction n°1 insère un enregistrement à id=2, MySQL renverra une erreur d'entrée en double. On voit qu'éviter la lecture fantôme est une illusion.

Pour toutes les instructions de sélection de niveau RR mentionnées précédemment, Nous avons appelé la lecture d'instantané, la lecture d'instantané peut garantir des lectures non répétables, mais elle ne peut pas éviter les lectures fantômes. MySQL a donc proposé le concept de « lecture actuelle ». Les instructions de lecture actuelles courantes sont :
1. sélectionnez pour la mise à jour
2.
3. mettre à jour / supprimer
et stipule que l'instruction de lecture actuelle au niveau RR ajoutera un verrou spécial à l'enregistrement - Gap lock. lock ne verrouille pas un enregistrement spécifique, mais verrouille l'intervalle entre les enregistrements pour garantir qu'aucun nouvel enregistrement ne sera inséré dans cet intervalle. La figure suivante est un diagramme schématique :
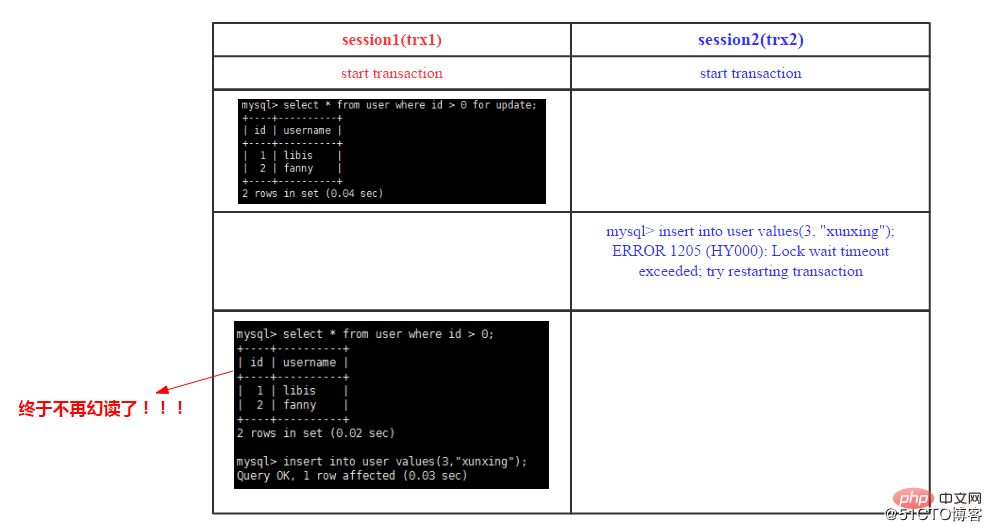
Dans la figure ci-dessus, la transaction n° 1 exécute d'abord une instruction select actuellement lue. Cette instruction ajoutera tous les intervalles avec l'identifiant > 0. Gap lock, lorsque la transaction n° 2 exécute l'insertion à id = 3, le système renvoie une exception Lock wait timeout execcded. Bien sûr, d'autres transactions peuvent être insérées avec succès sous la condition d'un identifiant
En fait, l'écriture réelle des données de MySQL est divisée en deux écritures, l'une écrite dans un fichier appelé DoubleWrite place, après l'écriture. réussit, les données sont effectivement écrites sur le disque où elles se trouvent. Pourquoi l'écrire deux fois ? En effet, la taille de la page de données MySQL n'est pas cohérente avec la taille d'une opération atomique sur le disque et des écritures partielles peuvent se produire. Par exemple, la taille par défaut de la page de données InnoDB est de 16 Ko et la taille d'une écriture atomique sur le disque est de 16 Ko. 512 octets (taille du secteur), l'écriture d'une page de données nécessite plusieurs E/S, donc si une exception se produit au milieu, les données seront perdues. De plus, il convient de noter que les performances de DoubleWrite n'auront pas un grand impact, car l'écriture sur DoubleWrite est une écriture séquentielle, ce qui n'a pas un grand impact sur les performances.
2. stratégie de persistance redolog (innodb_flush_log_at_trx_commit)redolog est le WAL d'InnoDB Les données sont d'abord écrites sur redolog et déposées sur le disque, puis mises à jour sur le. pool tampon. La stratégie de persistance de redolog est cohérente avec la stratégie de persistance de hlog dans HBase. La valeur par défaut est 1, ce qui signifie que le journal sera conservé sur le disque après la soumission de chaque transaction ; sur le disque toutes les secondes environ, dans ce cas, MySQL peut être en panne et certaines données peuvent être perdues. La valeur 2 signifie qu'après la soumission de chaque transaction, le journal sera vidé dans le tampon du système d'exploitation, puis le système d'exploitation le videra sur le disque de manière asynchrone. Dans ce cas, MySQL ne perdra pas de données en cas de panne. mais certaines données peuvent être perdues si la machine tombe en panne.
3. Stratégie de persistance Binlog (sync_binlog)Binlog, en tant que système de journalisation au niveau du serveur, enregistre principalement diverses opérations de la base de données de manière séquentielle sous forme d'événements, et peut également enregistrer le temps passé sur chaque opération. La documentation officielle de MySQL présente principalement les deux fonctions principales les plus élémentaires de Binlog : la sauvegarde et la réplication. Par conséquent, la persistance de Binlog affectera dans une certaine mesure l'intégrité de la sauvegarde et de la réplication des données. Identique à la stratégie de restauration de persistance, les valeurs possibles sont 0, 1, N. La valeur par défaut est 0, ce qui signifie écrire dans le tampon du système d'exploitation et vider le disque de manière asynchrone. Une valeur de 1 indique des écritures synchrones sur le disque. Si c'est N, cela signifie qu'une opération de rafraîchissement est effectuée toutes les N fois que le tampon du système d'exploitation est écrit. Pour résumer, cet article est le troisième d'une série d'articles sur les transactions de base de données. Il présente le cœur du modèle de transaction multi-lignes sur une seule machine de MySQL et fournit une explication plus détaillée de la technologie de verrouillage et du mécanisme MVCC. impliqués dans l’isolement. Les caractéristiques associées telles que l’atomicité et la durabilité des transactions sont également brièvement analysées et expliquées. Ensuite, l'auteur vous amènera à parler du modèle de transaction distribuée et à voir en quoi il diffère du modèle de transaction autonome. Apprentissage recommandé : Tutoriel MySQL
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié























![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



