


En Java, tous les objets sont stockés dans le tas. Ils sont alloués via le mot-clé new, et la JVM vérifiera si tous les threads ne peuvent plus y accéder et les recyclera. La plupart du temps, les programmeurs n'en seront pas du tout conscients et ces tâches sont exécutées en silence. Cependant, il arrive parfois que le programme se bloque le dernier jour avant sa sortie.
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
OutOfMemoryError est une anomalie très déprimante. Cela signifie généralement que vous faites quelque chose de mal : sauvegarder des données inutiles pendant une durée inutile ou traiter trop de données en même temps. Parfois, ces problèmes ne sont pas nécessairement sous votre contrôle. Par exemple, certaines bibliothèques tierces mettent en cache certaines chaînes ou certains serveurs d'applications ne nettoient pas pendant le déploiement. De plus, nous n’avons souvent rien à voir avec des objets qui existent déjà dans le tas.
Cet article analyse les différentes causes de OutOfMemoryError et comment vous pouvez y faire face. L'analyse suivante est limitée à la machine virtuelle Sun Hotspot, mais la plupart des conclusions s'appliquent à toute autre implémentation JVM. La plupart d’entre eux sont basés sur des articles en ligne et sur ma propre expérience. Je n'ai pas directement effectué de travail de développement JVM, donc les conclusions ne représentent pas les auteurs de JVM. Mais j’ai rencontré et résolu de nombreux problèmes liés à la mémoire.
J'ai présenté le processus de collecte des ordures en détail dans cet article. En termes simples, l'algorithme de collecte par balayage utilise garbage collection roots comme point de départ de l'analyse, analyse l'intégralité du graphique d'objets et marque tous les objets accessibles. Les objets non marqués sont dépollués et recyclés.
Le processus d'algorithme de récupération de place de Java signifie que si un MOO se produit, cela signifie que vous ajoutez constamment des objets au graphique d'objets et que vous ne les supprimez pas. Cela est généralement dû au fait que vous ajoutez de nombreux objets à une classe de collection, telle que Map, et que l'objet de collection est statique. Ou bien, cette classe de collection est enregistrée dans l'objet <code><span class="wp_keywordlink">ThreadLocal</span>ThreadLocal
System.gc()Avant de plonger dans le vif du sujet, il y a une dernière chose que vous devez savoir sur le garbage collection : la JVM fera de son mieux pour libérer de la mémoire jusqu'à ce que le MOO se produise. Cela signifie que le MOO ne peut pas être résolu en appelant simplement
En fait, la machine virtuelle Sun Hotspot utilise un espace de tas de taille fixe et permet une croissance automatique entre l'espace minimum et l'espace maximum. Si vous ne spécifiez pas les valeurs minimale et maximale, alors pour le mode « client », 2 Mo seront utilisés comme valeur minimale et 64 Mo comme valeur maximale par défaut pour le mode « serveur », la JVM déterminera la valeur par défaut ; valeur basée sur la mémoire actuellement disponible
. Après 2000, la taille maximale par défaut du tas a été modifiée à 64 Mo, et elle était considérée comme suffisamment grande à l'époque (la valeur par défaut avant 2000 était de 16 Mo), mais elle peut facilement être utilisée pour les applications actuelles. Cela signifie que vous devez spécifier explicitement les valeurs minimales et maximales du tas via les paramètres JVM :java -Xms256m -Xmx512m MyClass
让你奇怪的时,设置合适的堆的最小值往往比设置合适的最大值更加重要。垃圾回收器会尽可能的保证当前的的堆大小,而不是不停的增长堆空间。这会导致应用程序不停的创建和回收大量的对象,而不是获取新的堆空间,相对于初始(最小)堆空间。Java堆会尽量保持这样的堆大小,并且会不停的运行GC以保持这样的容量。因此,我认为在生产环境中,我们最好是将堆的最小值和最大值设置成一样的。
你可能会困惑于为什么Java堆会有一个最大值上限:操作系统并不会分配真正的物理内存,除非他们真的被使用了。并且,实际使用的虚拟内存空间实际上会比Java堆空间要大。如果你运行在一个32位系统上,一个过大的堆空间可能会限制classpath中能够使用的jar的数量,或者你可以创建的线程数。
另外一个原因是,一个受限的最大堆空间可以让你及时发现潜在的内存泄露问题。在开发环境中,对应用程序的压力往往是不够的,如果你在开发环境中就拥有一个非常大得堆空间,那么你很有可能永远不会发现可能的内存泄露问题,直到进入产品环境。
所有的JVM实现都提供了-verbos:gc选项,它可以让垃圾回收器在工作的时候打印出日志信息:
java -verbose:gc com.kdgregory.example.memory.SimpleAllocator [GC 1201K->1127K(1984K), 0.0020460 secs] [Full GC 1127K->103K(1984K), 0.0196060 secs] [GC 1127K->1127K(1984K), 0.0006680 secs] [Full GC 1127K->103K(1984K), 0.0180800 secs] [GC 1127K->1127K(1984K), 0.0001970 secs] ...
Sun的JVM提供了额外的两个参数来以内存带分类输出,并且会显示垃圾收集的开始时间:
java -XX:+PrintGCDetails -XX:+PrintGCTimeStamps com.kdgregory.example.memory.SimpleAllocator 0.095: [GC 0.095: [DefNew: 177K->64K(576K), 0.0020030 secs]0.097: [Tenured: 1063K->103K(1408K), 0.0178500 secs] 1201K->103K(1984K), 0.0201140 secs] 0.117: [GC 0.118: [DefNew: 0K->0K(576K), 0.0007670 secs]0.119: [Tenured: 1127K->103K(1408K), 0.0392040 secs] 1127K->103K(1984K), 0.0405130 secs] 0.164: [GC 0.164: [DefNew: 0K->0K(576K), 0.0001990 secs]0.164: [Tenured: 1127K->103K(1408K), 0.0173230 secs] 1127K->103K(1984K), 0.0177670 secs] 0.183: [GC 0.184: [DefNew: 0K->0K(576K), 0.0003400 secs]0.184: [Tenured: 1127K->103K(1408K), 0.0332370 secs] 1127K->103K(1984K), 0.0342840 secs] ...
从上面的输出我们可以看出什么?首先,前面的几次垃圾回收发生的非常频繁。每行的第一个字段显示了JVM启动后的时间,我们可以看到在一秒钟内有上百次的GC。并且,还加入了每次GC执行时间的开始时间(在每行的最后一个字段),可以看出垃圾搜集器是在不停的运行的。
但是在实时系统中,这会造成很大的问题,因为垃圾搜集器的执行会夺走很多的CPU周期。就像我之前提到的,这很可能是由于初始堆大小设置的太小了,并且GC日志显示了:每次堆的大小达到了1.1Mb,它就开始执行GC。如果你得系统也有类似的现象,请在改变自己的应用程序之前使用-Xms来增大初始堆大小。
对于GC日志还有一些很有趣的地方:除了第一次垃圾回收,没有任何对象是存放在了新生代(“DefNew”)。这说明了这个应用程序分配了包含大量数据的数组,在显示世界里这是很少出现的。如果在一个实时系统中出现这样的状况,我想到的第一个问题是“这些数组拿来干什么用?”。
一个堆转储可以显示你在应用程序说使用的所有对象。从基础上讲,它仅仅反映了对象实例的数量和类文件所占用的字节数。当然你也可以将分配这些内存的代码一起dump出来,并且对比历史存货对象。但是,如果你要dump的数据信息越多,JVM的负载就会越大,因此这些技术仅仅应该使用在开发环境中。
命令行参数-XX:+HeapDumpOnOutOfMemoryError是最简单的方式生成内存转储。就像它的名字所说的,它会在内存被用完的时候(发生OOM)进行转储,这在产品环境非常好用。但是由于这个是一种事后转储(已经发生了OOM),它只能提供一种历史性的数据。它会产生一个二进制文件,你可以使用jhat来操作该文件(这个工具在JDK1.6中已经提供,但是可以读取JDK1.5产生的文件)。
你可以使用jmap(JDK1.5之后就自带了)来为一个运行中得java程序产生堆转储,可以产生一个在jhat中使用的dump文件,或者是一个存文本的统计文件。统计图可以在进行分析时优先使用,特别是你要在一段时间内多次转储堆并进行分析和对比历史数据。
从转储内容和JVM的负荷的扩展性上考虑的话,可以使用profilers。Profiles使用JVM的调试接口(debuging interface)来搜集对象的内存分配信息,包括具体的代码行和方法调用栈。这个是非常有用的:不仅仅可以知道你分配了一个数GB的数组,你还可以知道你在一个特定的地方分配了950MB的对象,并且直接忽略其他的对象。当然,这些结果肯定会对JVM有开销,包括CPU的开销和内存的开销(保存一些原始数据)。你不应该在产品环境中使用profiles。
Java中的内存泄露是这样定义的:你在内存中分配了一些对象,但是并没有清除掉所有对它们的引用,也就是说垃圾搜集器不能回收它们。使用堆转储直方图可以很容易的查找这些泄露对象:它不仅仅可以告诉你在内存中分配了哪些对象,并且显示了这些对象在内存中所占用的大小。但是这种直方图最大的问题是:对于同一个类的所有对象都被聚合(group)在一起了,所以你还需要进一步做一些检测来确定这些内存在哪里被分配了。
使用jmap并且加上-histo参数可以为你产生一个直方图,它显示了从程序运行到现在所有对象的数量和内存消耗,并且包含了已经被回收的对象和内存。如果使用-histo:live参数会显示当前还在堆中得对象数量及其内存消耗,不论这些对象是否要被垃圾搜集器进行回收。
也就是说,如果你要得到一个当前时间下得准确信息,你需要在使用jmap之前强制执行一次垃圾回收。如果你的应用程序是运行在本地,最简单的方式是直接使用jconsole:在’Memory’标签下,有一个’Perform GC’的按钮。如果应用程序是运行在服务端环境,并且JMX beans被暴露了,MemoryMXBean有一个gc()操作。如果上述的两种方案都没办法满足你得要求,你就只有等待JVM自己触发一次垃圾搜集过程了。如果你有一个很严重的内存泄露问题,那么第一次major collection很可能预示着不久后就会OOM。
有两种方法使用jmap产生的直方图。其中最有效的方法,适用于长时间运行的程序,可以使用带live的命令行参数,并且在一段时间内多次使用该命令,检查哪些对象的数量在不断增长。但是,根据当前程序的负载,该过程可能会花费1个小时或者更多的时间。
另外一个更加快速的方式是直接比较当前存活的对象数量和总的对象数量。如果有些对象占据了总对象数量的大部分,那么这些对象很有可能发生内存泄露。这里有一个例子,这个应用程序已经连续几周为100多个用户提供了服务,结果列举了前12个数量最多的对象。据我所知,这个程序没有内存泄露的问题,但是像其他应用程序一样做了常规性的内存转储分析操作。
~, 510> jmap -histo 7626 | more num #instances #bytes class name ---------------------------------------------- 1: 339186 63440816 [C 2: 84847 18748496 [I 3: 69678 15370640 [Ljava.util.HashMap$Entry; 4: 381901 15276040 java.lang.String 5: 30508 13137904 [B 6: 182713 10231928 java.lang.ThreadLocal$ThreadLocalMap$Entry 7: 63450 8789976 <constMethodKlass> 8: 181133 8694384 java.lang.ref.WeakReference 9: 43675 7651848 [Ljava.lang.Object; 10: 63450 7621520 <methodKlass> 11: 6729 7040104 <constantPoolKlass> 12: 134146 6439008 java.util.HashMap$Entry ~, 511> jmap -histo:live 7626 | more num #instances #bytes class name ---------------------------------------------- 1: 200381 35692400 [C 2: 22804 12168040 [I 3: 15673 10506504 [Ljava.util.HashMap$Entry; 4: 17959 9848496 [B 5: 63208 8766744 <constMethodKlass> 6: 199878 7995120 java.lang.String 7: 63208 7592480 <methodKlass> 8: 6608 6920072 <constantPoolKlass> 9: 93830 5254480 java.lang.ThreadLocal$ThreadLocalMap$Entry 10: 107128 5142144 java.lang.ref.WeakReference 11: 93462 5135952 <symbolKlass> 12: 6608 4880592 <instanceKlassKlass>
当我们要尝试寻找内存泄露问题,可以从消耗内存最多的对象着手。这听上去很明显,但是往往它们并不是内存泄露的根源。但是,它们任然是应该最先下手的地方,在这个例子中,最占用内存的是一些char[]的数组对象(总大小是60MB,基本上没有任何问题)。但是很奇怪的是当前存货(live)的对象竟然占了历史分配的总对象大小的三分之二。
一般来说,一个应用程序会分配对象,并且在不久之后就会释放它们。如果保存一些对象的应用过长的时间,就很有可能会导致内存泄露。但是虽然是这么说的,实际上还是要具体情况具体分析,主要还是要看这个程序到底在做什么事情。字符数组对象(char[])往往和字符串对象(String)同时存在,大部分的应用程序都会在整个运行过程中一直保持着一些字符串对象的引用。例如,基于JSP的web应用程序在JSP页面中定义了很多HTML字符串表达式。这种特殊的应用程序提供HTML服务,但是它们需要保持字符串引用的需求却不一定那么清晰:它们提供的是目录服务,并不是静态文本。如果我遇到了OOM,我就会尝试找到这些字符串在哪里被分配,为什么没有被释放。
另一个需要关注的是字节数组([B)。在JDK中有很多类都会使用它们(比如BufferedInputStream),但是却很少在应用程序代码中直接看到它们。通常它们会被用作缓存(buffer),但是缓存的生命周期不会很长。在这个例子中我们看到,有一半的字节数组任然保持存活。这个是令人担忧的,并且它凸显了直方图的一个问题:所有的对象都按照它的类型被分组聚合了。对于应用程序对象(非JDK类型或者原始类型,在应用程序代码中定义的类),这不是一个问题,因为它们会在程序的一个部分被集中分配。但是字节数组有可能会在任何地方被定义,并且在大多数应用程序中都被隐藏在一些库中。我们是否应当搜索调用了new byte[]或者new ByteArrayOutputStream()的代码?
为了找到导致内存泄露的最终原因,仅仅考虑按照类别(class)的分组的内存占用字节数是不够的。你还需要将应用程序分配的对象和内存泄露的对象关联起来考虑。一个方法是更加深入查看对象的数量,以便将具有关联性的对象找出来。下面是一个具有严重内存问题的程序的转储信息:
num #instances #bytes class name ---------------------------------------------- 1: 1362278 140032936 [Ljava.lang.Object; 2: 12624 135469922 [B ... 5: 352166 45077248 com.example.ItemDetails ... 9: 1360742 21771872 java.util.ArrayList ... 41: 6254 200128 java.net.DatagramPacket
如果你仅仅去看信息的前几行,你可能会去定位Object[]或者byte[],这些都是徒劳的。真正的问题出在ItemDetails和DatagramPacket上:前者分配了大量的ArrayList,进而又分配了大量的Object[];后者使用了大量的byte[]来保存从网络上接收到的数据。
第一个问题,分配了大量的数组,实际上不是内存泄露。ArrayList的默认构造函数会分配容量是10的数组,但是程序本身一般只使用1个或者2个槽位,这对于64位JVM来说会浪费62个字节的内存空间。一个更好的涉及方案是仅仅在有需要的时候才使用List,这样对每个实例来说可以节约额外的48个字节。但是,对于这种问题也可以很轻易的通过加内存来解决,因为现在的内存非常便宜。
但是对于datagram的泄露就比较麻烦(如同定位这个问题一样困难):这表明接收到的数据没有被尽快的处理掉。
为了跟踪问题的原因和影响,你需要知道你的程序是怎样在使用这些对象。不多的程序才会直接使用Object[]:如果确实要使用数组,程序员一般都会使用带类型的数组。但是,ArrayList会在内部使用。但是仅仅知道ArrayList的内存分配是不够的,你还需要顺着调用链往上走,看看谁分配了这些ArrayList。
其中一个方法是对比相关的对象数量。在上面的例子中,byte[]和DatagramPackage的关系是很明显的:其中一个基本上是另外一个的两倍。但是ArrayList和ItemDetails的关系就不那么明显了。(实际上一个ItemDetails中会包含多个ArrayList)
这往往是个陷阱,让你去关注那么数量最多的一些对象。我们有数百万的ArrayList对象,并且它们分布在不同的class中,也有可能集中在一小部分class中。尽管如此,数百万的对象引用是很容易被定位的。就算有10来个class可能会包含ArrayList,那么每个class的实体对象也会有十万个,这个是很容易被定位的。
从直方图中跟踪这种引用关系链是需要花费大量精力的,幸运的是,jmap不仅仅可以提供直方图,它还可以提供可以浏览的堆转储信息。
浏览堆转储引用链具有两个步骤:首先需要使用-dump参数来使用jmap,然后需要用jhat来使用转储文件。如果你确定要使用这种方法,请一定要保证有足够多的内存:一个转储文件通常都有数百M,jhat需要好几个G的内存来处理这些转储文件。
tmp, 517> jmap -dump:live,file=heapdump.06180803 7626 Dumping heap to /home/kgregory/tmp/heapdump.06180803 ... Heap dump file created tmp, 518> jhat -J-Xmx8192m heapdump.06180803 Reading from heapdump.06180803... Dump file created Sat Jun 18 08:04:22 EDT 2011 Snapshot read, resolving... Resolving 335643 objects... Chasing references, expect 67 dots................................................................... Eliminating duplicate references................................................................... Snapshot resolved. Started HTTP server on port 7000 Server is ready.
提供给你的默认URL显示了所有加载进系统的class,但是我觉得并不是很有用。相反,我直接使用http://localhost:7000/histo/,这个地址是一个直方图的视角来进行显示,并且是按照对象数量和占用的内存空间进行排序了的。
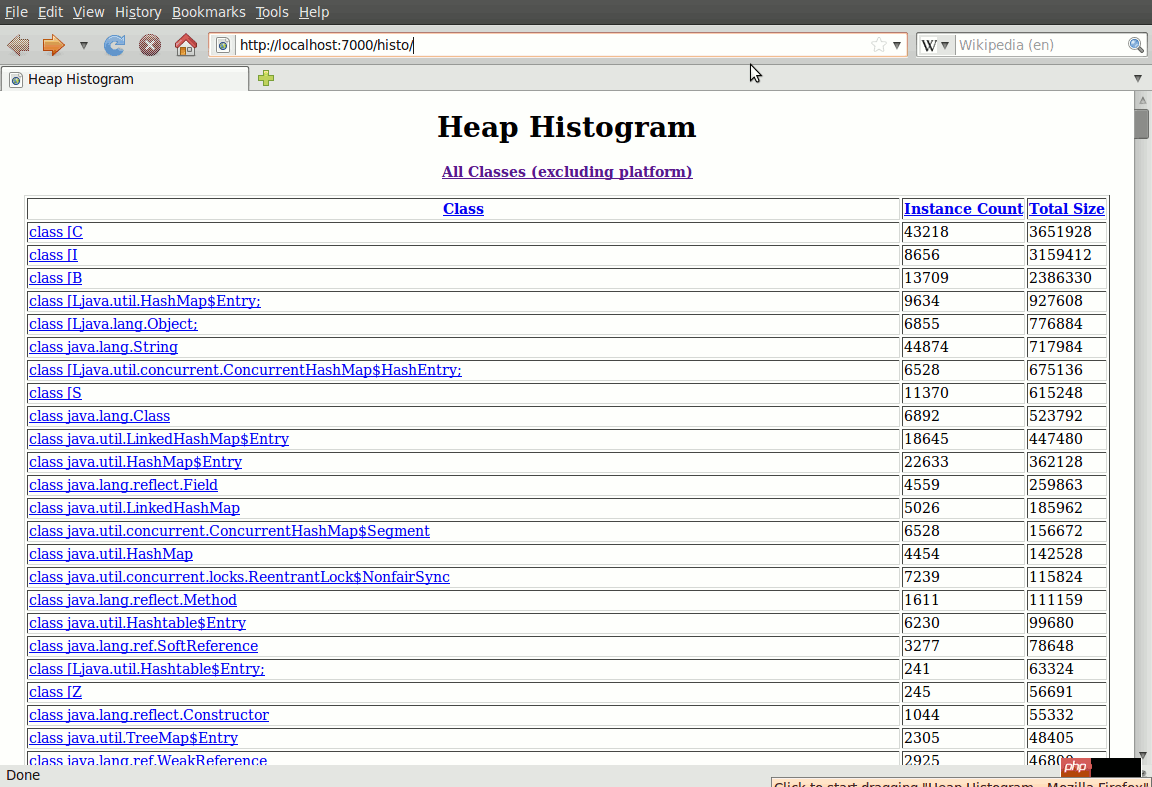
这个直方图里的每个class的名称都是一个链接,点击这个链接可以查看关于这个类型的详细信息。你可以在其中看到这个类的继承关系,它的成员变量,以及很多指向这个类的实体变量信息的链接。我不认为这个详细信息页面非常有用,而且实体变量的链接列表很占用很多的浏览器内存。
为了能够跟踪你的内存问题,最有用的页面是’Reference by Type’。这个页面含有两个表格:入引用和出引用,他们都被引用的数量进行排序了。点击一个类的名字可以看到这个引用的信息。
你可以在类的详细信息(class details)页面中找到这个页面的链接。
在大多数情况下,知道了是哪些对象消耗了大量的内存往往就可以知道它们为什么会发生内存泄露。你可以使用jhat来找到所有引用了他们的对象,并且你还可以看到使用了这些对象的引用的代码。但是在有些时候,这样还是不够的。
比如说你有关于字符串对象的内存泄露问题,那么就很有可能会花费你好几天的时间去检查所有和字符串相关的代码。要解决这种问题,你就需要能够显示内存在哪里被分配的堆转储。但是需要注意的是,这种类型的堆转储会对你的应用程序产生更多的负载,因为负责转储的代理需要记录每一个new操作符。
有许多交互式的程序可以做到这种级别的数据记录,但是我找到了一个更简单的方法,那就是使用内置的hprof代理来启动JVM。
java -Xrunhprof:heap=sites,depth=2 com.kdgregory.example.memory.Gobbler
hprof有许多选项:不仅仅可以用多种方式输出内存使用情况,它还可以跟踪CPU的使用情况。当它运行的时候,我指定了一个事后的内存转储,它记录了哪些对象被分配,以及分配的位置。它的输出被记录在了java.hprof.txt文件中,其中关于堆转储的部分如下:
SITES BEGIN (ordered by live bytes) Tue Sep 29 10:43:34 2009
percent live alloc'ed stack class
rank self accum bytes objs bytes objs trace name
1 99.77% 99.77% 66497808 2059 66497808 2059 300157 byte[]
2 0.01% 99.78% 9192 1 27512 13 300158 java.lang.Object[]
3 0.01% 99.80% 8520 1 8520 1 300085 byte[]
SITES END这个应用程序没有分配多种不同类型的对象,也没有将它们分配到很多不同的地方。一般的转储有成百上千行的信息,显示了每一种类型的对象被分配到了哪里。幸运的是,大多数问题都会出现在开头的几行。在这个例子中,最突出的是64M的存活着的字节数组,并且每一个平均32K。
大多数程序中都不会一直持有这么大得数据,这就表明这个程序没有很好的抽取和处理这些数据。你会发现这常常发生在读取一些大的字符串,并且保存了substring之后的字符串:很少有人知道String.substring()后会共享原始字符串对象的字节数组。如果你按照一行一行地读取了一个文件,但是却使用了每行的前五个字符,实际上你任然保存的是整个文件在内存中。
转储文件也显示出这些数组被分配的数量和现在存活的数量完全相等。这是一种典型的泄露,并且我们可以通过搜索’trace’号来找到真正的代码:
TRACE 300157:
com.kdgregory.example.memory.Gobbler.main(Gobbler.java:22)好了,这下就足够简单了:当我在代码中找到指定的代码行时,我发现这些数组被存放在了ArrayList中,并且它也一直没有出作用域。但是有时候,堆栈的跟踪并没有直接关联到你写的代码上:
TRACE 300085:
java.util.zip.InflaterInputStream.<init>(InflaterInputStream.java:71)
java.util.zip.ZipFile$2.<init>(ZipFile.java:348)在这个例子中,你需要增加堆栈跟踪的深度,并且重新运行你的程序。但是这里有一个需要平衡的地方:当你获取到了更多的堆栈信息,你也同时增加了profile的负载。默认地,如果你没有指定depth参数,那么默认值就会是4。我发现当堆栈深度为2的时候就可以发现和定位我程序中得大部分问题了,当然我也使用过深度为12的参数来运行程序。
另外一个增大堆栈深度的好处是,最后的报告结果会更加细粒度:你可能会发现你泄露的对象来自两到三个地方,并且它们都使用了相同的方法。
当很多对象在分配的不久后就被丢弃时,分代垃圾搜集器就会开始运行。你可以使用同样的原则来找发现内存泄露:使用调试器,在对象被分配的地方打上断点,并且运行这段代码。在大多数时候,当它们被分配不久后就会加入到长时间存活(long-live)的集合中。
除了JVM中的新生代和老年代外,JVM还管理着一片叫‘永久代’的区域,它存储了class信息和字符串表达式等对象。通常,你不会观察到永久代中的垃圾回收;大多数的垃圾回收发生在应用程序堆中。但是不像它的名字,在永久代中的对象不会是永久不变的。举个例子,被应用程序classloader加载的class,当不再被classloader引用时就会被清理掉。当应用程序服务被频繁的热部署时就可能会发生:
Exception in thread "main" java.lang.OutOfMemoryError: PermGen space
这一这个信息:这个不管应用程序堆的事。当应用程序堆中还有很多空间时,也有可能用完永久代的空间。通常,这发生在重新部署EAR和WAR文件时,并且永久代还不够大到可以同时容纳新的class信息和老的class信息(老的class会一直被保存着直到所有的请求在使用完它们)。当在运行处于开发状态的应用时更容易发生。
解决永久代错误的第一个方法就是增大永久大的空间,你可以使用-XX:MaxPermSize命令行参数。默认是64M,但是web应用程序或者IDE一般都需要256M。
java -XX:MaxPermSize=256m
但是在通常情况下并不是这么简单的。永久代的内存泄露一般都和在应用堆中的内存泄露原因一样:在一些地方的对象引用了并不该再引用的对象。以我的经验,很有可能有些对象直接引用了一些Class对象,或者在java.lang.reflect包下面的对象,而不是某些类的实例对象。正式因为web引用的classloader的组织方式,通常罪魁祸首都出现在服务的配置当中。
例如,你使用了Tomcat,并且有一个目录里面有很多共享的jars:shared/lib。如果你在一个容器里同时运行好几个web应用,将一些公用的jar放在这个目录是很有道理的,因为这样的话这些class仅仅被加载一次,可以减少内存的使用量。但是,如果其中的一些库具有对象缓存的话,会发生什么事情呢?
答案是这些被缓存了的对象的类永远不会被卸载,直到缓存释放了这些对象。解决方案就是将这些库移动到WAR或者EAR中。但是在某些时候情况也不会像这么简单:JDKs bean introspector会缓存住由root classloader加载的BeanInfo对象。并且任何使用了反射的库也会缓存这些对象,这样就导致你不能直到真正的问题所在。
解决永久代的问题通常都是比较痛苦的。一般可以先考虑加上-XX:+TraceClassLoading和-XX:+TraceClassUnloading命令行选项以便找出那些被加载了但是没有被卸载的类。如果你加上了-XX:+TraceClassResolution命令行选项,你还可以看到哪些类访问了其他类,但是没有被正常卸载。
这里有针对这三个选项的一个实例。第一行显示了MyClassLoader类从classpath中被加载了。因为它又从URLClassLoader继承,因此我们看到了接下来的’RESOLVE’消息,紧跟着又是一条’RESOLVE’消息,说明Class类也被解析了。
[Loaded com.kdgregory.example.memory.PermgenExhaustion$MyClassLoader from file:/home/kgregory/Workspace/Website/programming/examples/bin/] RESOLVE com.kdgregory.example.memory.PermgenExhaustion$MyClassLoader java.net.URLClassLoader RESOLVE java.net.URLClassLoader java.lang.Class URLClassLoader.java:188
所有的信息都在这里的,但是通常情况下将一些共享库移动到WAR/EAR中往往可以很快速的解决问题。
就像你刚才看到的关于永久代的消息,也许应用程序堆中还有空闲空间,但是也任然可能会发生OOM。这里有几个例子:
当我描述分代的堆空间时,我一般会说对象会首先被分配在新生代,然后最终会被移动到老年代。但这不是绝对正确的:如果你的对象足够大,那么它就会直接被分配在老年代。一般用户自己定义的对象是不会(也不应该)达到这个临界值,但是数组却却有可能:在JDK1.5中,当数组的对象超过0.5M的时候就会被直接分配到老年代。
在32位机器上,0.5M换算成Object[]数组的话就可以包含131,072个元素。这已经是很大的了,但是在企业级的应用中这是很有可能的。特别是当使用了HashMap时,它经常需要重新resize自己(里面的数组数据结构)。一些应用程序可能还需要更大的数组。
当没有连续的堆空间来存放这些数组对象时(就算在垃圾回收并且对内存进行了紧凑之后),问题就产生了。这很少见,但是如果当前的程序已经很接近堆空间的上限时,这就变得很有可能了。增大堆空间上限是最好的解决方案,但是你也许可以试试事先分配好你的容器的大小。(后面的小对象可以不需要连续的内存空间)
JavaDoc中对OOM的描述是,当垃圾搜集器不能在释放更多的内存空间时,JVM会抛出OOM。这里只对了一半:当JVM的内部代码收到来自操作系统的ENOMEM错误时,JVM也会抛出OOM。Unix程序员一般都知道,这里有很多地方可以收到ENOMEN错误,创建线程的过程是其中之一:
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
在我的32位Linux系统中,使用JDK1.5,我可以最多开启5,550个线程直到抛出异常。但是实际上在堆中任然有很多空闲空间,这是怎么回事呢?
在这个场景的背后,线程实际上是被操作系统所管理,而不是JVM,创建线程失败的可能原因有很多很多。在我的例子中,每一个线程都需要占用大概0.5M的虚拟内存作为它的栈空间,在5000个线程被创建之后,大约就有2G的内存空间被占用。有些操作系统就强制制定了一个进程所能创建的线程数的上限。
最后,针对这个问题没有一个解决方案,除非更换你的应用程序。大多数程序是不需要创建这么多得线程的,它们会将大部分的时间都浪费在等待操作系统调度上。但是有些服务程序需要创建数千个线程去处理请求,但是它们中得大多数都是在等待数据。针对这种场景,NIO和selector就是一个不错的解决方案。
从JDK1.4之后Java允许程序程序使用bytebuffers来访问堆外的内存空间(受限)。虽然ByteBuffer对象本身很小,但是堆外的内存可不一定很小:
Exception in thread "main" java.lang.OutOfMemoryError: Direct buffer memory
这里有多个原因会导致bytebuffer分配失败。通常情况下,你可能超过了最多的虚拟内存上限(仅限于32位系统),或者超过了所有物理内存和交换区内存的上限。除非你是在以很简单的方式处理超过你的机器内存上限的数据,否则你在使用direct buffer产生OOM的原因和你使用堆的原因基本上是一样的:你保持着一些你不该引用的数据。前面介绍的堆分析技术可以帮助你找到泄露点。
就像我前面提到的,你在启动一个JVM时,你需要指定堆的最小值和最大值。这就意味着,JVM会在运行期动态改变它对虚拟内存的需求。在一个内存受限的机器上,你可以同时运行多个JVM,甚至它们所有指定的最大值之和大于了物理内存和交换区的大小。当然,这就有可能会导致OOM,就算你的程序中存活的对象大小小于你指定的堆空间也是一样的。
这种情况和跑多个C++程序使用完所有的物理内存的原因是一样的。使用JVM可能会让你产生一种假象,以为不会出现这种问题。唯一的解决方案是购买更多的内存,或者不要同时跑那么多程序。没有办法让JVM可以’快速失败’;但是在Linux上你可以申请比总内存更多的内存。
最后一个需要注意的问题是:Java中得堆仅仅是所占用内存的一部分。JVM还会为它所创建的线程、内部代码、工作空间、共享库、direct buffer、内存映射文件分配内存。在32位的JVM中,这所有的内存都需要被映射到2G的虚拟内存空间中,这是非常有限的(特别是对于服务端或者后端应用程序)。在64位的JVM中,虚拟内存基本没存在什么限制,但是实际的物理内存(含交换区)可能会很稀缺。
一般来说,虚拟内存不会造成什么大问题;操作系统和JVM可以很好的管理它们。通常情况下,你需要查看虚拟内存的映射情况主要是为了direct buffer所使用的大块的内存或者是内存映射文件。但是你还是很有必要知道什么是虚拟内存的映射。
要查看在Linux上的虚拟内存映射情况可以使用pmap;在Windows中可以使用VMMap。下面是使用pmap来dump的一个Tomcat应用。实际的dump文件有好几百行,所展示的部分仅仅是比较有意思的部分:
08048000 60K r-x-- /usr/local/java/jdk-1.5/bin/java 08057000 8K rwx-- /usr/local/java/jdk-1.5/bin/java 081e5000 6268K rwx-- [ anon ] 889b0000 896K rwx-- [ anon ] 88a90000 4096K rwx-- [ anon ] 88e90000 10056K rwx-- [ anon ] 89862000 50488K rwx-- [ anon ] 8c9b0000 9216K rwx-- [ anon ] 8d2b0000 56320K rwx-- [ anon ] ... afd70000 504K rwx-- [ anon ] afdee000 12K ----- [ anon ] afdf1000 504K rwx-- [ anon ] afe6f000 12K ----- [ anon ] afe72000 504K rwx-- [ anon ] ... b0cba000 24K r-xs- /usr/local/java/netbeans-5.5/enterprise3/apache-tomcat-5.5.17/server/lib/catalina-ant-jmx.jar b0cc0000 64K r-xs- /usr/local/java/netbeans-5.5/enterprise3/apache-tomcat-5.5.17/server/lib/catalina-storeconfig.jar b0cd0000 632K r-xs- /usr/local/java/netbeans-5.5/enterprise3/apache-tomcat-5.5.17/server/lib/catalina.jar b0d6e000 164K r-xs- /usr/local/java/netbeans-5.5/enterprise3/apache-tomcat-5.5.17/server/lib/tomcat-ajp.jar b0d97000 88K r-xs- /usr/local/java/netbeans-5.5/enterprise3/apache-tomcat-5.5.17/server/lib/tomcat-http.jar ... b6ee3000 3520K r-x-- /usr/local/java/jdk-1.5/jre/lib/i386/client/libjvm.so b7253000 120K rwx-- /usr/local/java/jdk-1.5/jre/lib/i386/client/libjvm.so b7271000 4192K rwx-- [ anon ] b7689000 1356K r-x-- /lib/tls/i686/cmov/libc-2.11.1.so ...
dump文件展示给你了关于虚拟内存映射的4个部分:虚拟内存地址,大小,权限,源(从文件加载的部分)。最有意思的部分是它的权限部分,它表示了该内存段是否是只读的(r-)还是读写的(rw)。
我会从读写段开始分析。所有的段都具有名字”[ anon ]“,它在Linux中说明了该段不是由文件加载而来。这里还有很多被命名的读写段,它们和共享库关联。我相信这些库都具有每个进程的地址表。
因为所有的读写段都具有相同的名字,一次要找出出问题的部分需要花费一点时间。对于Java堆,有4个相关的大块内存被分配(新生代有2个,老年代1个,永久代1个),他们的大小由GC和堆配置来决定。
这部分的内容并不是对所有地方都适用。大部分都是我解决问题的过程中总结的实际经验。
有很多抱怨说Java是’memory hog’,经常被top命令的’VIRT’部分和Windows任务管理器的’Mem Usage’列所证实。需要澄清的是,有太多的东西都不会算进这个统计信息中,有些还是与其他程序共享的(比如说C的库)。实际上也有很多‘空’的区域在虚拟内存映射空间中:如果你适用-Xms1000m来启动JVM,就算你还没有开始分配对象,虚拟内存的大小也会超过1000m。
Une meilleure mesure consiste à utiliser la taille de l'ensemble résident : le nombre de pages de mémoire physique que votre application utilise réellement, sans compter les pages partagées. Il s'agit de la colonne 'RES' dans la commande top. Cependant, l'ensemble résident n'est pas la meilleure mesure de la mémoire totale que votre programme doit utiliser. Le système d'exploitation ne les placera dans l'espace mémoire du processus que lorsque votre programme en aura réellement besoin. De manière générale, cela se produira lorsque votre système sera soumis à une charge élevée, ce qui prendra beaucoup de temps.
Enfin : utilisez toujours des outils qui fournissent les détails requis pour analyser les problèmes de mémoire en Java. Et n’envisagez de tirer des conclusions que lorsque le MOO se produit.
Les fuites de mémoire se produisent généralement peu de temps après l'allocation de la mémoire. Une conclusion similaire est que la cause première du MOO est généralement très proche de son point de lancement et que la technologie de traçage du tas peut être utilisée pour l'analyser en premier. Le principe de base est que les fuites de mémoire sont généralement associées à la génération de grandes quantités de mémoire. Cela montre que le code qui provoque des fuites présente un risque d'échec plus élevé, que ce soit parce que son code d'allocation de mémoire est appelé trop fréquemment ou parce qu'il alloue trop de mémoire à chaque appel. Par conséquent, la priorité peut être donnée à l’utilisation des traces de pile pour localiser le problème.
J'ai mentionné la mise en cache à plusieurs reprises dans cet article : Au cours de mes décennies d'expérience professionnelle en Java, j'ai découvert que les fuites de mémoire sont liées à The l'entrée des classes est liée à la mise en cache. La mise en cache est en réalité très difficile à écrire.
Il existe de très nombreuses bonnes raisons d'utiliser la mise en cache, et il existe de nombreuses bonnes raisons d'utiliser votre propre cache. Si vous décidez d'utiliser la mise en cache, veuillez d'abord répondre aux questions suivantes :
Quels objets seront mis dans le cache ? Si les objets que vous souhaitez mettre en cache sont tous du même type (ou ont une relation d'héritage), il est préférable de suivre le problème que si vous disposez d'un cache pouvant accueillir différents types.
Combien d'objets seront mis dans le cache en même temps ? Si vous laissez ProductCache mettre en cache 1 000 objets, mais que 10 000 objets sont trouvés dans les résultats de l'analyse de la mémoire, alors la relation entre eux est plus facile à localiser. Si vous spécifiez la limite de capacité maximale de ce cache, vous pouvez facilement calculer la quantité de mémoire maximale requise par ce cache.
Quelle est la politique d'expiration et de purge ? Chaque cache nécessite une politique d'expulsion explicite afin de contrôler le cycle d'inventaire des objets qui y résident. Si vous ne spécifiez pas de stratégie d'expulsion explicite, certains objets risquent de vivre plus longtemps que nécessaire, d'occuper plus de mémoire et d'augmenter la charge du garbage collector (rappelez-vous : le temps requis dans la phase de marquage et proportionnel à la nombre d'objets survivants). Est-ce que
contiendra des références à ces objets vivants en dehors du cache ? Le meilleur scénario d’application pour la mise en cache est lorsque les appels sont fréquents, que la durée de l’appel est courte et que l’objet mis en cache est coûteux à obtenir. Si vous devez créer un objet et référencer cet objet tout au long de la durée de vie de l'application, il n'est alors pas nécessaire de mettre l'objet dans le cache (peut-être en utilisant une technique de pooling pour afficher le nombre total d'objets). objets).
De manière générale, les objets peuvent être divisés en deux catégories : un type survit avec le cycle de vie de l'ensemble du programme ; l’autre n’est vivant et ne répond qu’à une seule demande. Il est important de comprendre que vous ne devez vous soucier que des objets dont vous pensez qu'ils survivront longtemps.
Une solution consiste à initialiser tous les objets à longue durée de vie au démarrage du programme, qu'ils soient ou non utilisés immédiatement. Une autre méthode consiste à utiliser un framework d'injection de dépendances , tel que Spring. Cela permet non seulement de trouver facilement tous les objets de longue durée dans le fichier de configuration du bean (sans analyser l'intégralité du chemin de classe), mais indique également clairement où ces objets sont utilisés.
Dans la plupart des scénarios, les objets alloués dans une méthode seront nettoyés à la sortie de la méthode (sauf ceux qui sont renvoyés comme objet). Cette règle est facile à suivre lorsque vous utilisez des variables locales pour stocker ces objets. Cependant, parfois des variables d'entité sont encore utilisées pour sauvegarder ces objets, en particulier lorsqu'un grand nombre d'autres méthodes sont appelées dans la méthode, principalement pour éviter un passage de paramètres de méthode excessif et gênant.
Cela ne provoque pas nécessairement une fuite. Les appels de méthode ultérieurs réaffecteront ces variables, permettant ainsi le recyclage des objets créés précédemment. Mais cela entraîne une surcharge de mémoire inutile et rend le débogage plus difficile. Mais du point de vue de la conception, lorsque je vois du code comme celui-ci, j'envisagerai de séparer cette méthode pour former une classe indépendante.
L'objet session est utilisé pour enregistrer et partager des données relatives à l'utilisateur entre plusieurs requêtes, principalement parce que le protocole HTTP est sans état. Parfois, cela devient une solution temporaire pour la mise en cache.
Cela ne signifie pas que des fuites se produiront définitivement, car le conteneur Web invalidera la session de l'utilisateur après un certain temps. Mais cela augmente considérablement l’empreinte mémoire de l’ensemble du programme, ce qui est mauvais. Et c'est très difficile à déboguer : comme je l'ai déjà mentionné, il est difficile de voir quels autres objets l'objet contient.
Bien que le MOO soit mauvais, si vous continuez à effectuer le garbage collection, ce sera encore pire : cela volera du temps CPU qui devrait appartenir à votre programme.
Comme je l'ai dit au début, la JVM est la seule qui vous permet de spécifier la taille maximale de vos données (limite supérieure de mémoire) dans un environnement de programmation moderne. Par conséquent, vous penserez souvent à une fuite de mémoire, mais en fait, il vous suffit d'augmenter la taille de votre tas. La meilleure première étape pour résoudre les problèmes de mémoire consiste à augmenter votre limite de mémoire. Si vous rencontrez un problème de fuite de mémoire, quelle que soit la quantité de mémoire que vous ajoutez, vous finirez toujours par obtenir des erreurs MOO.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!





























![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



