

Comparaison de l'efficacité de l'utilisation de la mémoire : si un simple stockage clé-valeur est utilisé, Memcached a une utilisation de la mémoire plus élevée. Si Redis utilise une structure de hachage pour le stockage clé-valeur, son utilisation de la mémoire sera supérieure à celle de Memcached en raison de sa compression combinée.
Comparaison des performances : étant donné que Redis n'utilise qu'un seul cœur, alors que Memcached peut utiliser plusieurs cœurs, Redis a en moyenne des performances plus élevées que Memcached lors du stockage de petites données sur chaque cœur. Pour les données de plus de 100 000 données, les performances de Memcached sont supérieures à celles de Redis. Bien que Redis ait récemment été optimisé pour les performances de stockage du Big Data, il est encore légèrement inférieur à Memcached.
Plus précisément pourquoi la conclusion ci-dessus s'est produite, voici les informations collectées :
Contrairement à Memcached, qui ne prend en charge que les enregistrements de données avec des structures clé-valeur simples, Redis prend en charge des types de données beaucoup plus riches. Il existe cinq types de données les plus couramment utilisés : chaîne, hachage, liste, ensemble et ensemble trié. Redis utilise un objet redisObject en interne pour représenter toutes les clés et valeurs. Les informations principales de redisObject sont présentées dans la figure :
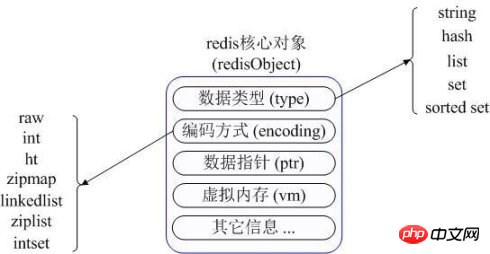
type représente le type de données spécifique d'un objet valeur, et l'encodage est la manière dont les différents types de données sont stockés dans redis. Par exemple : type=string représente que la valeur est stockée sous forme de chaîne ordinaire et l'encodage correspondant peut être brut ou entier. S'il s'agit d'un int, cela signifie que la chaîne est réellement stockée et représentée en interne dans Redis en tant que classe numérique. Bien entendu, le principe est que la chaîne elle-même peut être représentée par une valeur numérique, telle que : "123" "456". de telles cordes. Ce n'est que lorsque la fonction de mémoire virtuelle de Redis est activée que le champ vm alloue réellement de la mémoire. Cette fonction est désactivée par défaut.
1) Chaîne
Commandes couramment utilisées : set/get/decr/incr/mget, etc.
Scénarios d'application : la chaîne est le type de données le plus couramment utilisé, et le stockage clé/valeur ordinaire peut être classé dans cette catégorie
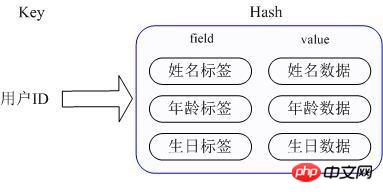
Méthode d'implémentation : le Hash de Redis stocke en fait la valeur en interne sous forme de HashMap et fournit une interface pour un accès direct aux membres de cette Map. Comme le montre la figure, Key est l'ID utilisateur et la valeur est une carte. La clé de cette carte est le nom d'attribut du membre et la valeur est la valeur de l'attribut. De cette manière, les données peuvent être modifiées et accessibles directement via la clé de leur carte interne (la clé de la carte interne est appelée champ dans Redis), c'est-à-dire que les données d'attribut correspondantes peuvent être manipulées via le champ clé (ID utilisateur). (étiquette d'attribut). Il existe actuellement deux façons d'implémenter HashMap : lorsqu'il y a relativement peu de membres de HashMap, Redis utilisera une méthode de type tableau unidimensionnel pour le stocker de manière compacte afin d'économiser de la mémoire, au lieu d'utiliser la véritable structure HashMap pour le moment. , l'encodage du redisObject de la valeur correspondante est zipmap, lorsque le nombre de membres augmente, il sera automatiquement converti en un véritable HashMap, et l'encodage est ht.
Scénarios d'application : il existe de nombreux scénarios d'application pour la liste Redis, et c'est également l'une des structures de données les plus importantes de Redis. Par exemple, la liste de suivi de Twitter, la liste de fans, etc. peuvent être implémentées en utilisant la structure de liste de Redis ; 🎜>
Méthode d'implémentation : L'implémentation interne de set est un HashMap dont la valeur est toujours nulle. En fait, elle est rapidement triée par calcul de hachage. C'est pourquoi set peut fournir un moyen de déterminer si un membre est dans l'ensemble.
5) Ensemble trié
Commandes couramment utilisées : zadd/zrange/zrem/zcard, etc.
Scénarios d'application : le scénario d'utilisation de l'ensemble trié Redis est similaire à celui de set. La différence est que l'ensemble n'est pas automatiquement trié, tandis que l'ensemble trié peut trier les membres en fournissant un paramètre de priorité (score) supplémentaire par l'utilisateur et est inséré dans. ordre, c'est-à-dire un tri automatique. Lorsque vous avez besoin d'une set list ordonnée et non dupliquée, vous pouvez choisir une structure de données d'ensemble triée. Par exemple, la chronologie publique de Twitter peut être stockée avec l'heure de publication comme score, de sorte qu'elle soit automatiquement triée par heure lors de sa récupération.
Méthode d'implémentation : l'ensemble trié Redis utilise en interne HashMap et la liste de sauts (SkipList) pour garantir le stockage et l'ordre des données. HashMap stocke le mappage des membres aux scores, tandis que la liste de sauts stocke tous les membres. La base de tri est Pour les scores stockés dans HashMap. , l'utilisation de la structure de table de saut peut atteindre une efficacité de recherche relativement élevée et est relativement simple à mettre en œuvre.
Dans Redis, toutes les données ne sont pas toujours stockées en mémoire. C'est la plus grande différence par rapport à Memcached. Lorsque la mémoire physique est épuisée, Redis peut échanger certaines valeurs qui n'ont pas été utilisées depuis longtemps sur le disque. Redis mettra uniquement en cache toutes les informations de clé. Si Redis constate que l'utilisation de la mémoire dépasse un certain seuil, l'opération d'échange sera déclenchée. Redis calcule quelles clés correspondent à la valeur requise en fonction de l'échange "swappability = age*log(size_in_memory)". disque. Ensuite, les valeurs correspondant à ces clés sont conservées sur le disque et effacées en mémoire. Cette fonctionnalité permet à Redis de conserver des données qui dépassent la taille de la mémoire de sa machine elle-même. Bien entendu, la mémoire de la machine elle-même doit pouvoir contenir toutes les clés, après tout, ces données ne seront pas échangées. Dans le même temps, lorsque Redis échange les données de la mémoire sur le disque, le thread principal qui fournit le service et le sous-thread qui effectue l'opération d'échange partageront cette partie de la mémoire, donc si les données qui doivent être swapped est mis à jour, Redis bloquera l'opération jusqu'à ce que les modifications du sous-thread ne puissent être apportées qu'après avoir terminé l'opération d'échange. Lors de la lecture de données depuis Redis, si la valeur correspondant à la clé de lecture n'est pas dans la mémoire, Redis doit alors charger les données correspondantes à partir du fichier d'échange, puis les renvoyer au demandeur. Il y a ici un problème de pool de threads d’E/S. Par défaut, Redis bloquera, c'est-à-dire qu'il ne répondra pas tant que tous les fichiers d'échange ne seront pas chargés. Cette stratégie est plus adaptée lorsque le nombre de clients est faible et que des opérations par lots sont effectuées. Mais si Redis est appliqué dans une grande application de site Web, cela ne peut évidemment pas répondre à la situation d'une grande concurrence. Ainsi, lorsque Redis s'exécute, nous définissons la taille du pool de threads d'E/S et effectuons des opérations simultanées sur les demandes de lecture qui doivent charger les données correspondantes à partir du fichier d'échange pour réduire le temps de blocage.
Pour les systèmes de bases de données basés sur la mémoire comme Redis et Memcached, l'efficacité de la gestion de la mémoire est un facteur clé affectant les performances du système. La fonction malloc/free dans le langage C traditionnel est la méthode la plus couramment utilisée pour allouer et libérer de la mémoire, mais cette méthode présente des défauts majeurs : premièrement, pour les développeurs, une incompatibilité entre malloc et free peut facilement provoquer des fuites de mémoire. une grande quantité de fragments de mémoire qui ne peuvent pas être recyclés et réutilisés, réduisant ainsi l'utilisation de la mémoire, enfin, en tant qu'appel système, sa surcharge système est bien supérieure à celle des appels de fonction ordinaires ; Par conséquent, afin d'améliorer l'efficacité de la gestion de la mémoire, les solutions de gestion de mémoire efficaces n'utiliseront pas directement les appels malloc/free. Redis et Memcached utilisent tous deux leurs propres mécanismes de gestion de mémoire, mais leurs méthodes de mise en œuvre sont très différentes. Les mécanismes de gestion de mémoire des deux seront présentés séparément ci-dessous.
Memcached utilise le mécanisme d'allocation de dalle par défaut pour gérer la mémoire. L'idée principale est de diviser la mémoire allouée en blocs de longueurs spécifiques en fonction de la taille prédéterminée pour stocker des enregistrements de données clé-valeur de longueurs correspondantes afin de résoudre complètement le problème de fragmentation de la mémoire. Le mécanisme d'allocation de dalle est uniquement conçu pour stocker des données externes, ce qui signifie que toutes les données clé-valeur sont stockées dans le système d'allocation de dalle, tandis que les autres requêtes de mémoire pour Memcached sont demandées via malloc/free ordinaire, car le nombre de ces requêtes et La fréquence détermine qu'ils n'affecteront pas les performances de l'ensemble du système. Le principe de l'attribution des dalles est assez simple. Comme le montre la figure, il s'applique d'abord à un gros bloc de mémoire du système d'exploitation, le divise en morceaux de différentes tailles et divise les morceaux de même taille en groupes de classes de dalles. Parmi eux, Chunk est la plus petite unité utilisée pour stocker des données clé-valeur. La taille de chaque classe Slab peut être contrôlée en spécifiant le facteur de croissance au démarrage de Memcached. Supposons que la valeur du facteur de croissance dans la figure est de 1,25. Si la taille du premier groupe de fragments est de 88 octets, la taille du deuxième groupe de fragments est de 112 octets, et ainsi de suite.
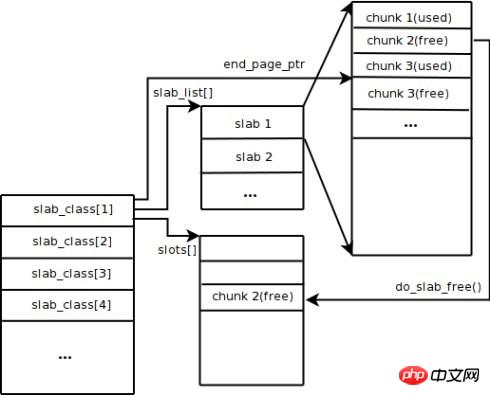
Lorsque Memcached reçoit les données envoyées par le client, il sélectionne d'abord la classe Slab la plus appropriée en fonction de la taille des données reçues, puis interroge la liste des morceaux libres dans la classe Slab enregistrée par Memcached pour trouver une classe Slab qui peut être utilisé pour stocker les données. Lorsqu'un enregistrement de base de données expire ou est supprimé, le morceau occupé par l'enregistrement peut être recyclé et réajouté à la liste libre. D'après le processus ci-dessus, nous pouvons voir que le système de gestion de la mémoire de Memcached est très efficace et ne provoquera pas de fragmentation de la mémoire, mais son plus grand inconvénient est qu'il entraîne un gaspillage d'espace. Étant donné que chaque morceau se voit attribuer une longueur spécifique d'espace mémoire, les données de longueur variable ne peuvent pas utiliser pleinement cet espace. Comme le montre la figure, 100 octets de données sont mis en cache dans un fragment de 128 octets et les 28 octets restants sont gaspillés.

La gestion de la mémoire de Redis est principalement implémentée via les deux fichiers La différence entre Redis et Memcached.h et La différence entre Redis et Memcached.c dans le code source. Afin de faciliter la gestion de la mémoire, Redis va stocker la taille de cette mémoire dans la tête du bloc mémoire après avoir alloué un morceau de mémoire. Comme le montre la figure, real_ptr est le pointeur renvoyé par redis après avoir appelé malloc. Redis stocke la taille du bloc mémoire dans l'en-tête. La taille de la mémoire occupée par size est connue et correspond à la longueur du type size_t, puis renvoie ret_ptr. Lorsque de la mémoire doit être libérée, ret_ptr est transmis au gestionnaire de mémoire. Grâce à ret_ptr, le programme peut facilement calculer la valeur de real_ptr, puis transmettre real_ptr à free pour libérer de la mémoire.

Redis enregistre toutes les allocations de mémoire en définissant un tableau. La longueur de ce tableau est ZMALLOC_MAX_ALLOC_STAT. Chaque élément du tableau représente le nombre de blocs de mémoire alloués par le programme en cours, et la taille du bloc de mémoire est l'indice de l'élément. Dans le code source, ce tableau est La différence entre Redis et Memcached_allocations. La différence entre Redis et Memcached_allocations[16] représente le nombre de blocs de mémoire alloués d'une longueur de 16 octets. Il existe une variable statique used_memory dans La différence entre Redis et Memcached.c pour enregistrer la taille totale de la mémoire actuellement allouée. Par conséquent, en général, Redis utilise le package mallc/free, qui est beaucoup plus simple que la méthode de gestion de la mémoire de Memcached.
Bien que Redis soit un système de stockage basé sur la mémoire, il prend lui-même en charge la persistance des données en mémoire et propose deux stratégies de persistance principales : les instantanés RDB et les journaux AOF. Memcached ne prend pas en charge les opérations de persistance des données.
1) Instantané RDB
Redis prend en charge un mécanisme de persistance qui enregistre un instantané des données actuelles dans un fichier de données, c'est-à-dire un instantané RDB. Mais comment une base de données en écriture continue génère-t-elle des instantanés ? Redis utilise le mécanisme de copie en écriture de la commande fork. Lors de la génération d'un instantané, le processus actuel est transféré dans un processus enfant, puis toutes les données circulent dans le processus enfant et les données sont écrites dans un fichier RDB. Nous pouvons configurer le moment de la génération de l'instantané RDB via la commande save de Redis. Par exemple, nous pouvons configurer l'instantané pour qu'il soit généré en 10 minutes, ou nous pouvons le configurer pour générer un instantané après 1 000 écritures, ou nous pouvons implémenter plusieurs règles ensemble. La définition de ces règles se trouve dans le fichier de configuration Redis. Vous pouvez également définir les règles pendant l'exécution de Redis via la commande Redis CONFIG SET sans redémarrer Redis.
Le fichier RDB de Redis ne sera pas endommagé car son opération d'écriture est effectuée dans un nouveau processus. Lorsqu'un nouveau fichier RDB est généré, le processus enfant généré par Redis écrira d'abord les données dans un fichier temporaire, puis utilisera le système de renommage atomique. call renomme le fichier temporaire en fichier RDB, de sorte que si une panne se produit à tout moment, le fichier Redis RDB est toujours disponible. Dans le même temps, le fichier RDB de Redis fait également partie de l'implémentation interne de la synchronisation maître-esclave Redis. RDB a ses défauts, c'est-à-dire qu'en cas de problème avec la base de données, les données enregistrées dans notre fichier RDB ne sont pas toutes neuves. Toutes les données de la dernière génération de fichier RDB jusqu'à l'arrêt de Redis seront perdues. Dans certaines entreprises, cela est tolérable.
2) Journal AOF
Le nom complet du journal AOF est fichier d'ajout uniquement, qui est un fichier journal écrit en ajout. Différent du binlog des bases de données générales, les fichiers AOF sont du texte brut identifiable et leur contenu est constitué de commandes standard Redis une par une. Seules les commandes qui entraîneront une modification des données seront ajoutées au fichier AOF. Chaque commande pour modifier les données génère un journal et le fichier AOF deviendra de plus en plus gros, donc Redis fournit une autre fonction appelée réécriture AOF. Sa fonction est de régénérer un fichier AOF. Il n'y aura qu'une seule opération sur un enregistrement dans le nouveau fichier AOF, contrairement à un ancien fichier qui peut enregistrer plusieurs opérations sur la même valeur. Le processus de génération est similaire à RDB. Il crée également un processus, parcourt directement les données et écrit un nouveau fichier temporaire AOF. Pendant le processus d'écriture d'un nouveau fichier, tous les journaux des opérations d'écriture seront toujours écrits dans l'ancien fichier AOF d'origine et seront également enregistrés dans la mémoire tampon. Une fois l'opération de redondance terminée, tous les journaux du tampon seront écrits simultanément dans le fichier temporaire. Appelez ensuite la commande atomic rename pour remplacer l’ancien fichier AOF par le nouveau fichier AOF.
AOF est une opération d'écriture de fichier. Son but est d'écrire le journal des opérations sur le disque, il rencontrera donc également le processus d'opération d'écriture que nous avons mentionné ci-dessus. Après avoir appelé write sur AOF dans Redis, utilisez l'option appendfsync pour contrôler le temps nécessaire pour appeler fsync pour l'écrire sur le disque. Le niveau de sécurité des trois paramètres de appendfsync ci-dessous devient progressivement renforcé.
appendfsync no Lorsque appendfsync est défini sur no, Redis n'appellera pas activement fsync pour synchroniser le contenu du journal AOF sur le disque, donc tout cela dépend entièrement du débogage du système d'exploitation. Pour la plupart des systèmes d'exploitation Linux, fsync est effectué toutes les 30 secondes pour écrire les données du tampon sur le disque.
appendfsync Everysec Lorsque appendfsync est défini sur Everysec, Redis effectuera un appel fsync toutes les secondes par défaut pour écrire les données du tampon sur le disque. Mais lorsque cet appel fsync dure plus d'une seconde. Redis adoptera la stratégie consistant à retarder fsync et attendra encore une seconde. C'est-à-dire que fsync sera exécuté après deux secondes. Cette fois, fsync sera exécuté quel que soit le temps d'exécution. À ce stade, comme le descripteur de fichier sera bloqué pendant fsync, l'opération d'écriture en cours sera bloquée. La conclusion est donc que dans la plupart des cas, Redis effectuera fsync toutes les secondes. Dans le pire des cas, une opération fsync se produit toutes les deux secondes. Cette opération est appelée validation de groupe dans la plupart des systèmes de bases de données. Elle combine les données de plusieurs opérations d'écriture et écrit le journal sur le disque en une seule fois.
appednfsync toujours Lorsque appendfsync est défini sur toujours, fsync sera appelé une fois pour chaque opération d'écriture. À ce stade, les données sont les plus sécurisées. Bien sûr, puisque fsync sera exécuté à chaque fois, ses performances seront également affectées.
Pour les besoins généraux de l'entreprise, il est recommandé d'utiliser RDB pour la persistance. La raison en est que la surcharge de RDB est bien inférieure à celle des journaux AOF. Pour les applications qui ne peuvent pas tolérer la perte de données, il est recommandé d'utiliser les journaux AOF.
Memcached est un système de mise en mémoire tampon de données à mémoire complète. Bien que Redis prenne en charge la persistance des données, la mémoire complète est l'essence même de ses hautes performances. En tant que système de stockage basé sur la mémoire, la taille de la mémoire physique de la machine correspond à la quantité maximale de données que le système peut accueillir. Si la quantité de données à traiter dépasse la taille de la mémoire physique d'une seule machine, un cluster distribué doit être créé pour étendre les capacités de stockage.
Memcached lui-même ne prend pas en charge la distribution, le stockage distribué de Memcached ne peut donc être implémenté sur le client que via des algorithmes distribués tels que le hachage cohérent. La figure ci-dessous montre l'architecture de mise en œuvre du stockage distribué de Memcached. Avant que le client n'envoie des données au cluster Memcached, le nœud cible des données sera d'abord calculé via l'algorithme distribué intégré, puis les données seront envoyées directement au nœud pour stockage. Mais lorsque le client interroge des données, il doit également calculer le nœud où se trouvent les données de la requête, puis envoyer directement une requête de requête au nœud pour obtenir les données.
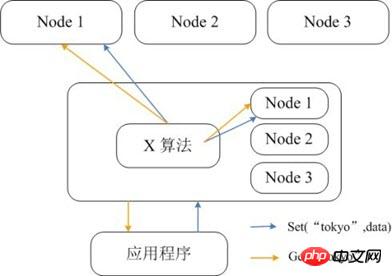
Par rapport à Memcached, qui ne peut utiliser le client que pour implémenter le stockage distribué, Redis préfère créer un stockage distribué côté serveur. La dernière version de Redis prend déjà en charge les fonctions de stockage distribué. Redis Cluster est une version avancée de Redis qui implémente la distribution et autorise des points de défaillance uniques. Il n'a pas de nœud central et a une évolutivité linéaire. La figure ci-dessous montre l'architecture de stockage distribuée de Redis Cluster, dans laquelle les nœuds communiquent entre eux via le protocole binaire, et entre les nœuds et les clients via le protocole ascii. En termes de stratégie de placement des données, Redis Cluster divise l'ensemble du champ de valeur de clé en 4 096 emplacements de hachage, et chaque nœud peut stocker un ou plusieurs emplacements de hachage, c'est-à-dire que le nombre maximum de nœuds actuellement pris en charge par Redis Cluster est de 4 096. L'algorithme distribué utilisé par Redis Cluster est également très simple : crc16(key) % HASH_SLOTS_NUMBER.
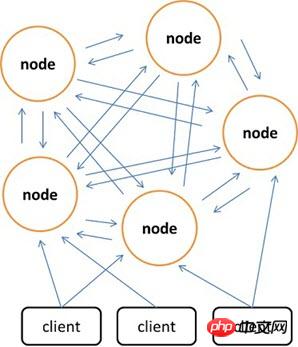
Afin de garantir la disponibilité des données sous un point de défaillance unique, Redis Cluster introduit le nœud maître et le nœud esclave. Dans Redis Cluster, chaque nœud maître possède deux nœuds esclaves correspondants pour la redondance. De cette manière, dans l'ensemble du cluster, le temps d'arrêt de deux nœuds quelconques n'entraînera pas d'indisponibilité des données. Lorsque le nœud maître se ferme, le cluster sélectionnera automatiquement un nœud esclave pour devenir le nouveau nœud maître.
Références :
http://www.redisdoc.com/fr/latest/
http://memcached.org/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment utiliser la fonction choisir
Comment utiliser la fonction choisir
 La différence entre ancrer et viser
La différence entre ancrer et viser
 Qu'est-ce que la rigidité de l'utilisateur
Qu'est-ce que la rigidité de l'utilisateur
 Comment prendre des captures d'écran sur un ordinateur
Comment prendre des captures d'écran sur un ordinateur
 Comment activer le système de version professionnelle Win7
Comment activer le système de version professionnelle Win7
 Connexion Internet impossible
Connexion Internet impossible
 analyses statistiques
analyses statistiques
 Comment créer un clone WeChat sur un téléphone mobile Huawei
Comment créer un clone WeChat sur un téléphone mobile Huawei








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



