

 Java
javaDidacticiel
Amélioration des performances grâce à l'analyse statique, à l'initialisation d'images et à la capture instantanée de tas
Java
javaDidacticiel
Amélioration des performances grâce à l'analyse statique, à l'initialisation d'images et à la capture instantanée de tas
Amélioration des performances grâce à l'analyse statique, à l'initialisation d'images et à la capture instantanée de tas

Des structures monolithiques au monde des systèmes distribués, le développement d'applications a parcouru un long chemin. L’adoption massive du cloud computing et de l’architecture des microservices a considérablement modifié l’approche de création et de déploiement des applications serveur. Au lieu de serveurs d'applications géants, nous disposons désormais de services indépendants, déployés individuellement, qui entrent en action
au fur et à mesure des besoins.
Cependant, un nouvel acteur susceptible d'avoir un impact sur ce bon fonctionnement pourrait être les 'démarrages à froid'. Les démarrages à froid surviennent lorsque la première requête est traitée sur un travailleur fraîchement généré. Cette situation nécessite l’initialisation du runtime du langage et de la configuration du service avant de traiter la demande réelle. L'imprévisibilité et la lenteur d'exécution associées aux démarrages à froid peuvent enfreindre les accords de niveau de service d'un service cloud. Alors, comment contrer cette inquiétude croissante ?
Image native : optimisation du temps de démarrage et de l'empreinte mémoire
Pour lutter contre les inefficacités des démarrages à froid, une nouvelle approche a été développée impliquant l'analyse des points d'accès, l'initialisation de l'application au moment de la construction, la capture instantanée du tas et la compilation (AOT) à l'avance. Cette méthode fonctionne dans le cadre d'un monde fermé, exigeant que toutes les classes Java soient prédéterminées et accessibles au moment de la construction. Au cours de cette phase, une analyse complète des points à atteindre détermine tous les éléments de programme accessibles (classes, méthodes, champs) pour garantir que seules les méthodes Java essentielles sont compilées.
Le code d'initialisation de l'application peut s'exécuter pendant le processus de construction plutôt qu'au moment de l'exécution. Cela permet la pré-allocation d'objets Java et la construction de structures de données complexes, qui sont ensuite mises à disposition au moment de l'exécution via un « tas d'images ». Ce tas d'images est intégré à l'exécutable, offrant une disponibilité immédiate au démarrage de l'application. Le
l'exécution itérative de l'analyse des points de destination et de la capture instantanée se poursuit jusqu'à ce qu'un état stable (point fixe) soit atteint, optimisant à la fois le temps de démarrage et la consommation des ressources.
Flux de travail détaillé
L'entrée de notre système est le bytecode Java, qui peut provenir de langages comme Java, Scala ou Kotlin. Le processus traite uniformément l'application, ses bibliothèques, le JDK et les composants de la machine virtuelle pour produire un exécutable natif spécifique à un système d'exploitation et à une architecture, appelé « image native ». Le processus de création comprend une analyse itérative des points d'accès et une capture instantanée du tas jusqu'à ce qu'un point fixe soit atteint, permettant à l'application de participer activement via des rappels enregistrés. Ces étapes sont collectivement connues sous le nom de processus de création d'image native (Figure 1)
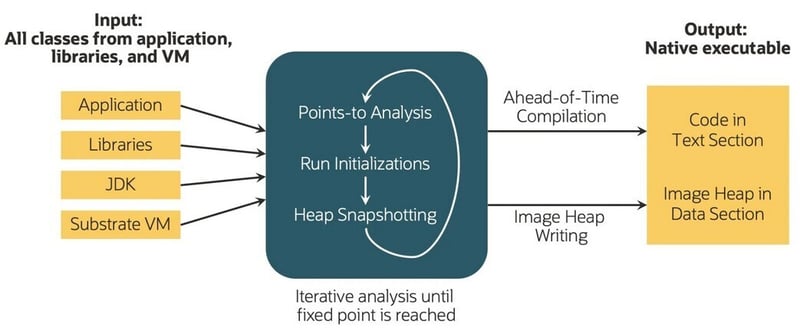
Figure 1 – Processus de création d'images natives (source : redhat.com)
Analyse des points à effectuer
Nous utilisons une analyse de points pour vérifier l'accessibilité des classes, des méthodes et des champs pendant l'exécution. L'analyse des points de destination commence par tous les points d'entrée, tels que la méthode principale de l'application, et traverse de manière itérative toutes les méthodes accessibles de manière transitive jusqu'à atteindre un point fixe (Figure 2).
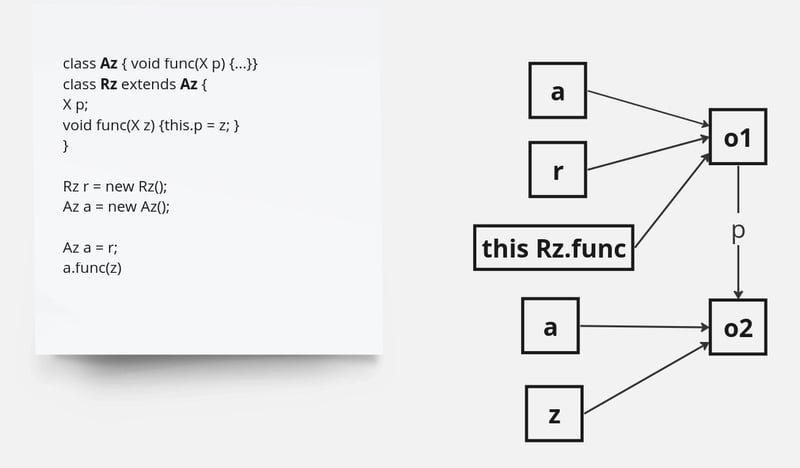
Figure 2 – Points d'analyse
Notre analyse des points d'accès exploite le frontal de notre compilateur pour analyser le bytecode Java dans la représentation intermédiaire de haut niveau du compilateur (IR). Par la suite, l'IR est transformé en un graphe de type-flux. Dans ce graphique, les nœuds représentent des instructions opérant sur des types d'objets, tandis que les arêtes désignent des arêtes d'utilisation dirigée entre les nœuds, pointant de la définition vers l'utilisation. Chaque nœud conserve un état de type, composé d'une liste de types pouvant atteindre le nœud et d'informations nulles. Les états de type se propagent à travers les bords d'utilisation ; si l'état de type d'un nœud change, ce changement est diffusé à tous les usages. Il est important de noter que les états de type ne peuvent que se développer ; de nouveaux types peuvent être ajoutés à un état de type, mais les types existants ne sont jamais supprimés. Ce mécanisme garantit que le
l'analyse converge finalement vers un point fixe, conduisant à la terminaison.
Exécuter le code d'initialisation
L'analyse des points d'arrivée guide l'exécution du code d'initialisation lorsqu'il atteint un point fixe local. Ce code trouve ses origines dans deux sources distinctes : les initialiseurs de classe et le lot de code personnalisé exécuté au moment de la construction via une interface de fonctionnalités :
Initialiseurs de classe : Chaque classe Java peut avoir un initialiseur de classe indiqué par une méthode
, qui initialise les champs statiques. Les développeurs peuvent choisir les classes à initialiser au moment de la construction ou au moment de l'exécution. Rappels explicites : Les développeurs peuvent implémenter du code personnalisé via des hooks fournis par notre système, s'exécutant avant, pendant ou après les étapes d'analyse.
Voici les API fournies pour l'intégration à notre système.
API passive (interroge l'état actuel de l'analyse)
boolean isReachable(Class<?> clazz); boolean isReachable(Field field); boolean isReachable(Executable method);
Pour plus d'informations, reportez-vous à QueryReachabilityAccess
API active (enregistre les rappels pour les changements de statut d'analyse) :
void registerReachabilityHandler(Consumer<DuringAnalysisAccess> callback, Object... elements); void registerSubtypeReachabilityHandler(BiConsumer<DuringAnalysisAccess, Class<?>> callback, Class<?> baseClass); void registerMethodOverrideReachabilityHandler(BiConsumer<DuringAnalysisAccess, Executable> callback, Executable baseMethod);
Pour plus d'informations, reportez-vous au BeforeAnalysisAccess
Au cours de cette phase, l'application peut exécuter du code personnalisé tel que l'allocation d'objets et l'initialisation de structures de données plus volumineuses. Il est important de noter que le code d'initialisation peut accéder à l'état actuel de l'analyse des points d'accès, permettant ainsi des requêtes concernant l'accessibilité des types, des méthodes ou des champs. Ceci est accompli à l'aide des différentes méthodes isReachable() fournies par DurantAnalysisAccess. En tirant parti de ces informations, l'application peut construire des structures de données optimisées pour les segments accessibles de l'application.
Instantané de tas
Enfin, la capture instantanée de tas construit un graphe d'objets en suivant des pointeurs racine comme des champs statiques pour créer une vue complète de tous les objets accessibles. Ce graphique remplit ensuite l'image native
tas d'images, garantissant que l'état initial de l'application est chargé efficacement au démarrage.
Pour générer la fermeture transitive des objets accessibles, l'algorithme parcourt les champs d'objets, lisant leurs valeurs par réflexion. Il est essentiel de noter que le générateur d'images fonctionne dans l'environnement Java. Seuls les champs d'instance marqués comme « lus » par l'analyse des points de destination sont pris en compte lors de ce parcours. Par exemple, si une classe a deux champs d'instance mais que l'un d'entre eux n'est pas marqué comme lu, l'objet accessible via le champ non marqué est exclu du tas d'images.
Lorsque vous rencontrez une valeur de champ dont la classe n'a pas été préalablement identifiée par l'analyse des points de destination, la classe est enregistrée en tant que type de champ. Cet enregistrement garantit que lors des itérations ultérieures de l'analyse des points à atteindre, le nouveau type est propagé à toutes les lectures de champs et utilisations transitives dans le graphe de flux de types.
L'extrait de code ci-dessous décrit l'algorithme de base pour la capture instantanée du tas :
Declare List worklist := []
Declare Set reachableObjects := []
Function BuildHeapSnapshot(PointsToState pointsToState)
For Each field in pointsToState.getReachableStaticObjectFields()
Call AddObjectToWorkList(field.readValue())
End For
For Each method in pointsToState.getReachableMethods()
For Each constant in method.embeddedConstants()
Call AddObjectToWorkList(constant)
End For
End For
While worklist.isNotEmpty
Object current := Pop from worklist
If current Object is an Array
For Each value in current
Call AddObjectToWorkList(value)
Add current.getClass() to pointsToState.getObjectArrayTypes()
End For
Else
For Each field in pointsToState.getReachableInstanceObjectFields(current.getClass())
Object value := field.read(current)
Call AddObjectToWorkList(value)
Add value.getClass() to pointsToState.getFieldValueTypes(field)
End For
End If
End While
Return reachableObjects
End Function
En résumé, l'algorithme de capture instantanée du tas construit efficacement un instantané du tas en parcourant systématiquement les objets accessibles et leurs champs. Cela garantit que seuls les objets pertinents sont inclus dans le tas d'images, optimisant ainsi les performances et l'empreinte mémoire de l'image native.
Conclusion
En conclusion, le processus de capture instantanée du tas joue un rôle essentiel dans la création d'images natives. En parcourant systématiquement les objets accessibles et leurs champs, l'algorithme de capture instantanée du tas construit un graphe d'objets qui représente la fermeture transitive des objets accessibles à partir de pointeurs racine tels que les champs statiques. Ce graphe d'objets est ensuite intégré dans l'image native en tant que tas d'images, servant de tas initial au démarrage de l'image native.
Tout au long du processus, l'algorithme s'appuie sur l'état de l'analyse des points à déterminer pour déterminer quels objets et champs sont pertinents pour être inclus dans le tas d'images. Les objets et les champs marqués comme « lus » par l'analyse des points de destination sont pris en compte, tandis que les entités non marquées sont exclues. De plus, lorsqu'il rencontre des types inédits, l'algorithme les enregistre pour propagation dans les itérations suivantes de l'analyse des points à atteindre.
Dans l'ensemble, la capture instantanée du tas optimise les performances et l'utilisation de la mémoire des images natives en garantissant que seuls les objets nécessaires sont inclus dans le tas d'images. Cette approche systématique améliore l'efficacité et la fiabilité de l'exécution des images natives.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment gérer les transactions en Java avec JDBC?
Aug 02, 2025 pm 12:29 PM
Comment gérer les transactions en Java avec JDBC?
Aug 02, 2025 pm 12:29 PM
Pour gérer correctement les transactions JDBC, vous devez d'abord désactiver le mode de validation automatique, puis effectuer plusieurs opérations, et enfin vous engager ou randonner en fonction des résultats; 1. Appelez Conn.SetAutoCommit (false) pour démarrer la transaction; 2. Exécuter plusieurs opérations SQL, telles que l'insertion et la mise à jour; 3. Appelez Conn.Commit () Si toutes les opérations sont réussies, et appelez Conn.Rollback () Si une exception se produit pour garantir la cohérence des données; Dans le même temps, les ressources TRY-With doivent être utilisées pour gérer les ressources, gérer correctement les exceptions et clôturer les connexions pour éviter la fuite de connexion; De plus, il est recommandé d'utiliser des pools de connexion et de définir des points de sauvegarde pour réaliser un retour en arrière partiel, et de maintenir les transactions aussi courtes que possible pour améliorer les performances.
 Java Virtual Threads Performance Benchmarking
Jul 21, 2025 am 03:17 AM
Java Virtual Threads Performance Benchmarking
Jul 21, 2025 am 03:17 AM
Les fils virtuels présentent des avantages de performances significatifs dans les scénarios très concurrencés et IO, mais l'attention doit être accordée aux méthodes de test et aux scénarios applicables. 1. Les tests corrects devraient simuler des affaires réelles, en particulier les scénarios de blocage IO, et utiliser des outils tels que JMH ou Gatling pour comparer les threads de plate-forme; 2. L'écart de débit est évident, et il peut être plusieurs fois à dix fois supérieur à 100 000 demandes simultanées, car elle est plus légère et efficace dans la planification; 3. Pendant le test, il est nécessaire d'éviter de poursuivre aveuglément des nombres de concurrence élevés, de s'adapter aux modèles IO non bloquants et de prêter attention aux indicateurs de surveillance tels que la latence et le GC; 4. Dans les applications réelles, elle convient au backend Web, au traitement des tâches asynchrones et à un grand nombre de scénarios IO simultanés, tandis que les tâches à forte intensité de processeur sont toujours adaptées aux threads de plate-forme ou à Forkjoinpool.
 Comment définir la variable d'environnement Java_Home dans Windows
Jul 18, 2025 am 04:05 AM
Comment définir la variable d'environnement Java_Home dans Windows
Jul 18, 2025 am 04:05 AM
Tosetjava_homeonwindows, firstlocatethejdkinstallationpath (par exemple, c: \ Programfiles \ java \ jdk-17), thencreateasystemenvironmentVaria Blenamedjava_homewiththatpath.next, UpdateThepathvariableByAdding% java \ _home% \ bin et verifythesetupusingjava-versionandjavac-v
 Java Microservices Service Mesh Intégration
Jul 21, 2025 am 03:16 AM
Java Microservices Service Mesh Intégration
Jul 21, 2025 am 03:16 AM
ServiceMesh est un choix inévitable pour l'évolution de l'architecture de microservice Java, et son cœur réside dans le découplage de la logique réseau et du code commercial. 1. ServiceMesh gère l'équilibrage de la charge, le fusible, la surveillance et d'autres fonctions par le biais d'agents side-car pour se concentrer sur les entreprises; 2. Istio Envoy convient aux projets moyens et grands, et Linkerd est plus léger et adapté aux essais à petite échelle; 3. Les microservices Java devraient fermer la feigne, le ruban et d'autres composants et les remettre à Istiod pour la découverte et la communication; 4. Assurer l'injection automatique de side-car pendant le déploiement, prêter attention à la configuration des règles de trafic, à la compatibilité du protocole et à la construction du système de suivi des journaux, et adoptez la planification incrémentielle de la migration et de la surveillance pré-contrôler.
 Implémentez une liste liée dans Java
Jul 20, 2025 am 03:31 AM
Implémentez une liste liée dans Java
Jul 20, 2025 am 03:31 AM
La clé pour implémenter une liste liée est de définir des classes de nœuds et d'implémenter les opérations de base. ① premier créez la classe de nœud, y compris les données et les références au nœud suivant; ② Créez ensuite la classe LinkedList en implémentant les fonctions d'insertion, de suppression et d'impression; ③ La méthode d'ajout est utilisée pour ajouter des nœuds à la queue; ④ La méthode Printlist est utilisée pour produire le contenu de la liste liée; ⑤ La méthode DeleteWithValue est utilisée pour supprimer les nœuds avec des valeurs spécifiées et gérer différentes situations du nœud de tête et du nœud intermédiaire.
 Sécurité Java pour l'injection de modèle côté serveur
Jul 16, 2025 am 01:15 AM
Sécurité Java pour l'injection de modèle côté serveur
Jul 16, 2025 am 01:15 AM
La prévention de l'injection de modèle côté serveur (SSTI) nécessite quatre aspects: 1. Utilisez des configurations de sécurité, telles que la désactivation des appels de méthode et la restriction de la charge de classe; 2. Évitez l'entrée de l'utilisateur comme contenu de modèle, seul remplacement variable et vérifiez strictement l'entrée; 3. Adopter des environnements de bac à sable, tels que le galet, la moustache ou l'isolement du contexte de rendu; 4. Mettez régulièrement à jour la version dépendante et examinez la logique de code pour vous assurer que le moteur de modèle est configuré raisonnablement et empêcher le système d'être attaqué en raison de modèles contrôlables par l'utilisateur.
 Optimisations du cadre avancé de la collection Java
Jul 20, 2025 am 03:48 AM
Optimisations du cadre avancé de la collection Java
Jul 20, 2025 am 03:48 AM
Pour améliorer les performances de Java Collection Framework, nous pouvons optimiser à partir des quatre points suivants: 1. Choisissez le type approprié en fonction du scénario, tel que l'accès aléatoire fréquent à ArrayList, la recherche rapide vers HashSet et le concurrenthashmap pour les environnements simultanés; 2. Réglez les facteurs de capacité et de charge raisonnablement lors de l'initialisation pour réduire les frais généraux d'expansion de la capacité, mais éviter les déchets de mémoire; 3. Utilisez des ensembles immuables (tels que List.of ()) pour améliorer la sécurité et les performances, adaptés aux données constantes ou en lecture seule; 4. Empêcher les fuites de mémoire et utiliser des références faibles ou des bibliothèques de cache professionnelles pour gérer les ensembles de survie à long terme. Ces détails affectent considérablement la stabilité et l'efficacité du programme.
 Construire des API RESTful à Java avec Jakarta EE
Jul 30, 2025 am 03:05 AM
Construire des API RESTful à Java avec Jakarta EE
Jul 30, 2025 am 03:05 AM
Setupamaven / gradleprojectwithjax-rsDependces likejersey; 2.CreateArestResourceUsingannotationsSuchas @ pathand @ get; 3.ConfigureTheApplicationViaApplicationsUbclassorweb.xml; 4.AddjacksonforjsonBindingByCludingJersey-Media-Json-Jackson; 5.DeploEp
