

 développement back-end
Tutoriel Python
Dépannage automatique et système ITSM utilisant EventBridge et Lambda
développement back-end
Tutoriel Python
Dépannage automatique et système ITSM utilisant EventBridge et Lambda
Dépannage automatique et système ITSM utilisant EventBridge et Lambda

Introduction :
Mes amis, dans les opérations informatiques, c'est une tâche très générique de surveiller les métriques du serveur telles que l'utilisation du processeur/de la mémoire et du disque ou des systèmes de fichiers, mais au cas où l'une des métriques serait déclenchée pour être critique, alors des personnes dédiées doivent effectuer certaines tâches de base. dépannez en vous connectant au serveur et découvrez la cause initiale de l'utilisation que la personne doit effectuer plusieurs fois si elle reçoit plusieurs alertes identiques qui créent de l'ennui et ne sont pas productives du tout. Ainsi, comme solution de contournement, il peut y avoir un système développé qui réagira une fois l'alarme déclenchée et agira sur ces instances en exécutant quelques commandes de dépannage de base. Juste pour résumer l'énoncé du problème et les attentes -
Énoncé du problème :
Développer un système qui répondra en deçà des attentes -
- Chaque instance EC2 doit être surveillée par CloudWatch.
- Une fois l'alarme déclenchée, quelque chose doit être présent pour se connecter à l'instance EC2 concernée et exécuter certaines commandes de dépannage de base.
- Ensuite, créez un ticket JIRA pour documenter cet incident et ajoutez le résultat des commandes dans la section des commentaires.
- Ensuite, envoyez un e-mail automatique contenant tous les détails de l'alarme et les détails du problème JIRA.
Schéma architectural :
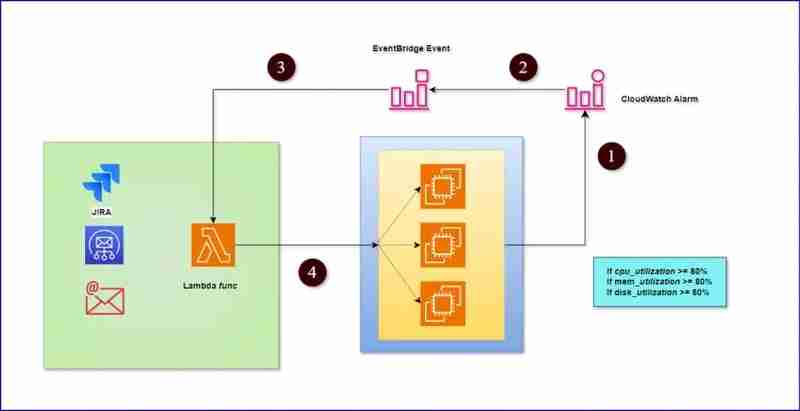
Pré-requis :
- Instances EC2
- Alarmes CloudWatch
- Règle EventBridge
- Fonction Lambda
- Compte JIRA
- Service de notification simple
Étapes de mise en œuvre :
A. Installation et configuration de l'agent CloudWatch :
Ouvrez la console Systems Manager et cliquez sur "Documents"
Recherchez le document « AWS-ConfigureAWSPackage » et exécutez-le en fournissant les détails requis.
Nom du package = AmazonCloudwatchAgent
Après l'installation, l'agent CloudWatch doit être configuré conformément au fichier de configuration. Pour cela, exécutez le document AmazonCloudWatch-ManageAgent. Assurez-vous également que le fichier de configuration JSON CloudWatch est stocké dans le paramètre SSM.
Une fois que vous voyez que les métriques sont transmises à la console CloudWatch, créez une alarme pour l'utilisation du processeur et de la mémoire, etc.B. Configurer la règle EventBridge :
Pour suivre les changements d'état d'alarme, nous avons ici un modèle légèrement personnalisé pour suivre les changements d'état d'alarme de OK à ALARME uniquement, et non inverser celui-ci. Ensuite, ajoutez cette règle à une fonction lambda comme déclencheur.
{
"source": ["aws.cloudwatch"],
"detail-type": ["CloudWatch Alarm State Change"],
"detail": {
"state": {
"value": ["ALARM"]
},
"previousState": {
"value": ["OK"]
}
}
}
- C. Créez une fonction Lambda pour l'envoi d'e-mails et la journalisation d'un incident dans JIRA : Cette fonction lambda est créée pour plusieurs activités déclenchées par la règle EventBridge et en tant que sujet SNS de destination, elle est ajoutée à l'aide du SDK AWS (Boto3). Une fois la règle EventBridge déclenchée, elle envoie le contenu de l'événement JSON à lambda grâce auquel la fonction capture plusieurs détails à traiter de différentes manières. Ici, nous avons travaillé sur deux types d'alarmes : i. Utilisation du processeur et ii. Utilisation de la mémoire. Une fois que l'une de ces deux alarmes est déclenchée et que l'état de l'alarme passe de OK à ALARM, EventBridge est déclenché, ce qui déclenche également la fonction Lambda pour effectuer les tâches mentionnées dans le code du formulaire.
Prérequis Lambda :
Nous avons besoin des modules ci-dessous à importer pour faire fonctionner les codes -
- >> os
- >> système
- >> json
- >> boto3
- >> temps
- >> demandes
Remarque : À partir des modules ci-dessus, à l'exception du reste du module « requêtes », tous sont téléchargés par défaut dans une infrastructure sous-jacente lambda. L'importation directe du module « requêtes » ne sera pas prise en charge dans Lambda. Par conséquent, commencez par installer le module de requête dans un dossier de votre ordinateur local (ordinateur portable) en exécutant la commande ci-dessous -
pip3 install requests -t <directory path> --no-user
_Après cela, cela sera téléchargé dans le dossier à partir duquel vous exécutez la commande ci-dessus ou dans lequel vous souhaitez stocker les codes sources du module, ici j'espère que le code lambda est en cours de préparation sur votre machine locale. Si oui, créez un fichier zip de l'intégralité de ces codes sources lambda avec le module. Après cela, téléchargez le fichier zip dans la fonction lambda.
Donc, nous réalisons ici ci-dessous deux scénarios -
1. Utilisation du processeur - Si l'alarme d'utilisation du processeur est déclenchée, la fonction lambda doit récupérer l'instance, se connecter à cette instance et exécuter les 5 processus les plus gourmands. Ensuite, il créera un problème JIRA et ajoutera les détails du processus dans la section des commentaires. Simultanément, il enverra un e-mail avec les détails de l'alarme et les détails du problème Jira avec le résultat du processus.
2. Utilisation de la mémoire -Même approche que ci-dessus
Now, let me reframe the task details which lambda is supposed to perform -
- Login to Instance
- Perform Basic Troubleshooting Steps.
- Create a JIRA Issue
- Send Email to Recipient with all Details
Scenario 1: When alarm state has been changed from OK to ALARM
First Set (Define the cpu and memory function) :
################# Importing Required Modules ################
############################################################
import json
import boto3
import time
import os
import sys
sys.path.append('./python') ## This will add requests module along with all dependencies into this script
import requests
from requests.auth import HTTPBasicAuth
################## Calling AWS Services ###################
###########################################################
ssm = boto3.client('ssm')
sns_client = boto3.client('sns')
ec2 = boto3.client('ec2')
################## Defining Blank Variable ################
###########################################################
cpu_process_op = ''
mem_process_op = ''
issueid = ''
issuekey = ''
issuelink = ''
################# Function for CPU Utilization ################
###############################################################
def cpu_utilization(instanceid, metric_name, previous_state, current_state):
global cpu_process_op
if previous_state == 'OK' and current_state == 'ALARM':
command = 'ps -eo user,pid,ppid,cmd,%mem,%cpu --sort=-%cpu | head -5'
print(f'Impacted Instance ID is : {instanceid}, Metric Name: {metric_name}')
# Start a session
print(f'Starting session to {instanceid}')
response = ssm.send_command(InstanceIds = [instanceid], DocumentName="AWS-RunShellScript", Parameters={'commands': [command]})
command_id = response['Command']['CommandId']
print(f'Command ID: {command_id}')
# Retrieve the command output
time.sleep(4)
output = ssm.get_command_invocation(CommandId=command_id, InstanceId=instanceid)
print('Please find below output -\n', output['StandardOutputContent'])
cpu_process_op = output['StandardOutputContent']
else:
print('None')
################# Function for Memory Utilization ################
###############################################################
def mem_utilization(instanceid, metric_name, previous_state, current_state):
global mem_process_op
if previous_state == 'OK' and current_state == 'ALARM':
command = 'ps -eo user,pid,ppid,cmd,%mem,%cpu --sort=-%mem | head -5'
print(f'Impacted Instance ID is : {instanceid}, Metric Name: {metric_name}')
# Start a session
print(f'Starting session to {instanceid}')
response = ssm.send_command(InstanceIds = [instanceid], DocumentName="AWS-RunShellScript", Parameters={'commands': [command]})
command_id = response['Command']['CommandId']
print(f'Command ID: {command_id}')
# Retrieve the command output
time.sleep(4)
output = ssm.get_command_invocation(CommandId=command_id, InstanceId=instanceid)
print('Please find below output -\n', output['StandardOutputContent'])
mem_process_op = output['StandardOutputContent']
else:
print('None')
Second Set (Create JIRA Issue) :
################## Create JIRA Issue ################
#####################################################
def create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val):
## Create Issue ##
url ='https://<your-user-name>.atlassian.net//rest/api/2/issue'
username = os.environ['username']
api_token = os.environ['token']
project = 'AnirbanSpace'
issue_type = 'Incident'
assignee = os.environ['username']
summ_metric = '%CPU Utilization' if 'CPU' in metric_name else '%Memory Utilization' if 'mem' in metric_name else '%Filesystem Utilization' if metric_name == 'disk_used_percent' else None
metric_val = metric_val
summary = f'Client | {account} | {instanceid} | {summ_metric} | Metric Value: {metric_val}'
description = f'Client: Company\nAccount: {account}\nRegion: {region}\nInstanceID = {instanceid}\nTimestamp = {timestamp}\nCurrent State: {current_state}\nPrevious State = {previous_state}\nMetric Value = {metric_val}'
issue_data = {
"fields": {
"project": {
"key": "SCRUM"
},
"summary": summary,
"description": description,
"issuetype": {
"name": issue_type
},
"assignee": {
"name": assignee
}
}
}
data = json.dumps(issue_data)
headers = {
"Accept": "application/json",
"Content-Type": "application/json"
}
auth = HTTPBasicAuth(username, api_token)
response = requests.post(url, headers=headers, auth=auth, data=data)
global issueid
global issuekey
global issuelink
issueid = response.json().get('id')
issuekey = response.json().get('key')
issuelink = response.json().get('self')
################ Add Comment To Above Created JIRA Issue ###################
output = cpu_process_op if metric_name == 'CPUUtilization' else mem_process_op if metric_name == 'mem_used_percent' else None
comment_api_url = f"{url}/{issuekey}/comment"
add_comment = requests.post(comment_api_url, headers=headers, auth=auth, data=json.dumps({"body": output}))
## Check the response
if response.status_code == 201:
print("Issue created successfully. Issue key:", response.json().get('key'))
else:
print(f"Failed to create issue. Status code: {response.status_code}, Response: {response.text}")
Third Set (Send an Email) :
################## Send An Email ################
#################################################
def send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink):
### Define a dictionary of custom input ###
metric_list = {'mem_used_percent': 'Memory', 'disk_used_percent': 'Disk', 'CPUUtilization': 'CPU'}
### Conditions ###
if previous_state == 'OK' and current_state == 'ALARM' and metric_name in list(metric_list.keys()):
metric_msg = metric_list[metric_name]
output = cpu_process_op if metric_name == 'CPUUtilization' else mem_process_op if metric_name == 'mem_used_percent' else None
print('This is output', output)
email_body = f"Hi Team, \n\nPlease be informed that {metric_msg} utilization is high for the instanceid {instanceid}. Please find below more information \n\nAlarm Details:\nMetricName = {metric_name}, \nAccount = {account}, \nTimestamp = {timestamp}, \nRegion = {region}, \nInstanceID = {instanceid}, \nCurrentState = {current_state}, \nReason = {current_reason}, \nMetricValue = {metric_val}, \nThreshold = 80.00 \n\nProcessOutput: \n{output}\nIncident Deatils:\nIssueID = {issueid}, \nIssueKey = {issuekey}, \nLink = {issuelink}\n\nRegards,\nAnirban Das,\nGlobal Cloud Operations Team"
res = sns_client.publish(
TopicArn = os.environ['snsarn'],
Subject = f'High {metric_msg} Utilization Alert : {instanceid}',
Message = str(email_body)
)
print('Mail has been sent') if res else print('Email not sent')
else:
email_body = str(0)
Fourth Set (Calling Lambda Handler Function) :
################## Lambda Handler Function ################
###########################################################
def lambda_handler(event, context):
instanceid = event['detail']['configuration']['metrics'][0]['metricStat']['metric']['dimensions']['InstanceId']
metric_name = event['detail']['configuration']['metrics'][0]['metricStat']['metric']['name']
account = event['account']
timestamp = event['time']
region = event['region']
current_state = event['detail']['state']['value']
current_reason = event['detail']['state']['reason']
previous_state = event['detail']['previousState']['value']
previous_reason = event['detail']['previousState']['reason']
metric_val = json.loads(event['detail']['state']['reasonData'])['evaluatedDatapoints'][0]['value']
##### function calling #####
if metric_name == 'CPUUtilization':
cpu_utilization(instanceid, metric_name, previous_state, current_state)
create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val)
send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink)
elif metric_name == 'mem_used_percent':
mem_utilization(instanceid, metric_name, previous_state, current_state)
create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val)
send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink)
else:
None
Alarm Email Screenshot :
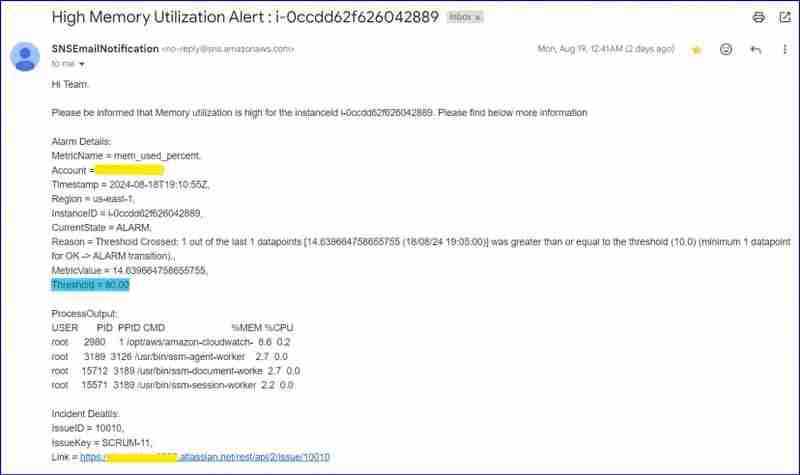
Note: In ideal scenario, threshold is 80%, but for testing I changed it to 10%. Please see the Reason.
Alarm JIRA Issue :
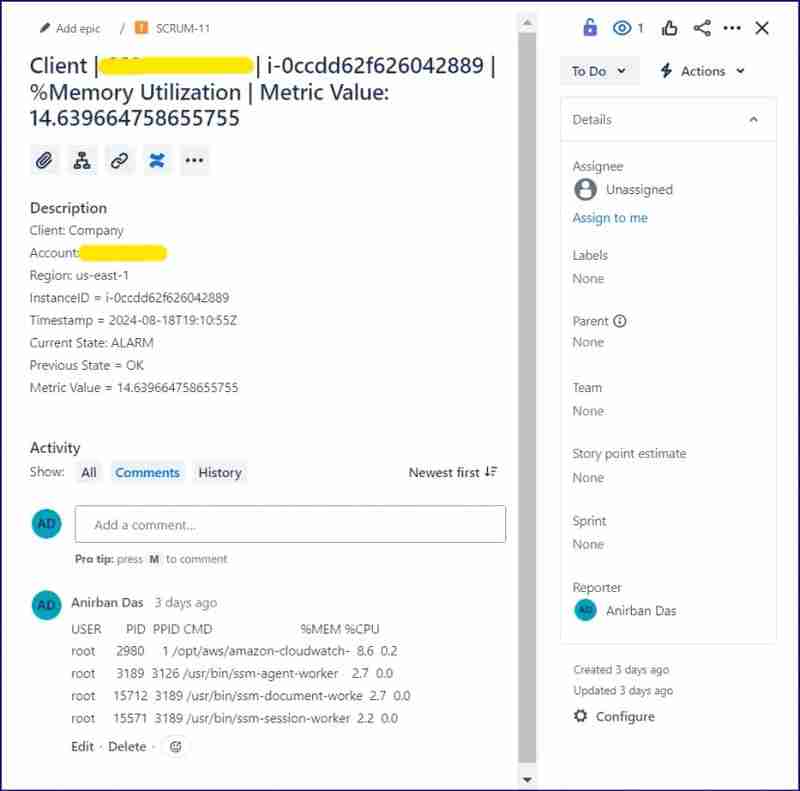
Scenario 2: When alarm state has been changed from OK to Insufficient data
In this scenario, if any server cpu or memory utilization metrics data are not captured, then alarm state gets changed from OK to INSUFFICIENT_DATA. This state can be achieved in two ways - a.) If server is in stopped state b.) If CloudWatch agent is not running or went in dead state.
So, as per below script, you'll be able to see that when cpu or memory utilization alarm status gets insufficient data, then lambda will first check if instance is in running status or not. If instance is in running state, then it will login and check CloudWatch agent status. Post that, it will create a JIRA issue and post the agent status in comment section of JIRA issue. After that, it will send an email with alarm details and agent status.
Full Code :
################# Importing Required Modules ################
############################################################
import json
import boto3
import time
import os
import sys
sys.path.append('./python') ## This will add requests module along with all dependencies into this script
import requests
from requests.auth import HTTPBasicAuth
################## Calling AWS Services ###################
###########################################################
ssm = boto3.client('ssm')
sns_client = boto3.client('sns')
ec2 = boto3.client('ec2')
################## Defining Blank Variable ################
###########################################################
cpu_process_op = ''
mem_process_op = ''
issueid = ''
issuekey = ''
issuelink = ''
################# Function for CPU Utilization ################
###############################################################
def cpu_utilization(instanceid, metric_name, previous_state, current_state):
global cpu_process_op
if previous_state == 'OK' and current_state == 'INSUFFICIENT_DATA':
ec2_status = ec2.describe_instance_status(InstanceIds=[instanceid,])['InstanceStatuses'][0]['InstanceState']['Name']
if ec2_status == 'running':
command = 'systemctl status amazon-cloudwatch-agent;sleep 3;systemctl restart amazon-cloudwatch-agent'
print(f'Impacted Instance ID is : {instanceid}, Metric Name: {metric_name}')
# Start a session
print(f'Starting session to {instanceid}')
response = ssm.send_command(InstanceIds = [instanceid], DocumentName="AWS-RunShellScript", Parameters={'commands': [command]})
command_id = response['Command']['CommandId']
print(f'Command ID: {command_id}')
# Retrieve the command output
time.sleep(4)
output = ssm.get_command_invocation(CommandId=command_id, InstanceId=instanceid)
print('Please find below output -\n', output['StandardOutputContent'])
cpu_process_op = output['StandardOutputContent']
else:
cpu_process_op = f'Instance current status is {ec2_status}. Not able to reach out!!'
print(f'Instance current status is {ec2_status}. Not able to reach out!!')
else:
print('None')
################# Function for Memory Utilization ################
###############################################################
def mem_utilization(instanceid, metric_name, previous_state, current_state):
global mem_process_op
if previous_state == 'OK' and current_state == 'INSUFFICIENT_DATA':
ec2_status = ec2.describe_instance_status(InstanceIds=[instanceid,])['InstanceStatuses'][0]['InstanceState']['Name']
if ec2_status == 'running':
command = 'systemctl status amazon-cloudwatch-agent'
print(f'Impacted Instance ID is : {instanceid}, Metric Name: {metric_name}')
# Start a session
print(f'Starting session to {instanceid}')
response = ssm.send_command(InstanceIds = [instanceid], DocumentName="AWS-RunShellScript", Parameters={'commands': [command]})
command_id = response['Command']['CommandId']
print(f'Command ID: {command_id}')
# Retrieve the command output
time.sleep(4)
output = ssm.get_command_invocation(CommandId=command_id, InstanceId=instanceid)
print('Please find below output -\n', output['StandardOutputContent'])
mem_process_op = output['StandardOutputContent']
print(mem_process_op)
else:
mem_process_op = f'Instance current status is {ec2_status}. Not able to reach out!!'
print(f'Instance current status is {ec2_status}. Not able to reach out!!')
else:
print('None')
################## Create JIRA Issue ################
#####################################################
def create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val):
## Create Issue ##
url ='https://<your-user-name>.atlassian.net//rest/api/2/issue'
username = os.environ['username']
api_token = os.environ['token']
project = 'AnirbanSpace'
issue_type = 'Incident'
assignee = os.environ['username']
summ_metric = '%CPU Utilization' if 'CPU' in metric_name else '%Memory Utilization' if 'mem' in metric_name else '%Filesystem Utilization' if metric_name == 'disk_used_percent' else None
metric_val = metric_val
summary = f'Client | {account} | {instanceid} | {summ_metric} | Metric Value: {metric_val}'
description = f'Client: Company\nAccount: {account}\nRegion: {region}\nInstanceID = {instanceid}\nTimestamp = {timestamp}\nCurrent State: {current_state}\nPrevious State = {previous_state}\nMetric Value = {metric_val}'
issue_data = {
"fields": {
"project": {
"key": "SCRUM"
},
"summary": summary,
"description": description,
"issuetype": {
"name": issue_type
},
"assignee": {
"name": assignee
}
}
}
data = json.dumps(issue_data)
headers = {
"Accept": "application/json",
"Content-Type": "application/json"
}
auth = HTTPBasicAuth(username, api_token)
response = requests.post(url, headers=headers, auth=auth, data=data)
global issueid
global issuekey
global issuelink
issueid = response.json().get('id')
issuekey = response.json().get('key')
issuelink = response.json().get('self')
################ Add Comment To Above Created JIRA Issue ###################
output = cpu_process_op if metric_name == 'CPUUtilization' else mem_process_op if metric_name == 'mem_used_percent' else None
comment_api_url = f"{url}/{issuekey}/comment"
add_comment = requests.post(comment_api_url, headers=headers, auth=auth, data=json.dumps({"body": output}))
## Check the response
if response.status_code == 201:
print("Issue created successfully. Issue key:", response.json().get('key'))
else:
print(f"Failed to create issue. Status code: {response.status_code}, Response: {response.text}")
################## Send An Email ################
#################################################
def send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink):
### Define a dictionary of custom input ###
metric_list = {'mem_used_percent': 'Memory', 'disk_used_percent': 'Disk', 'CPUUtilization': 'CPU'}
### Conditions ###
if previous_state == 'OK' and current_state == 'INSUFFICIENT_DATA' and metric_name in list(metric_list.keys()):
metric_msg = metric_list[metric_name]
output = cpu_process_op if metric_name == 'CPUUtilization' else mem_process_op if metric_name == 'mem_used_percent' else None
email_body = f"Hi Team, \n\nPlease be informed that {metric_msg} utilization alarm state has been changed to {current_state} for the instanceid {instanceid}. Please find below more information \n\nAlarm Details:\nMetricName = {metric_name}, \n Account = {account}, \nTimestamp = {timestamp}, \nRegion = {region}, \nInstanceID = {instanceid}, \nCurrentState = {current_state}, \nReason = {current_reason}, \nMetricValue = {metric_val}, \nThreshold = 80.00 \n\nProcessOutput = \n{output}\nIncident Deatils:\nIssueID = {issueid}, \nIssueKey = {issuekey}, \nLink = {issuelink}\n\nRegards,\nAnirban Das,\nGlobal Cloud Operations Team"
res = sns_client.publish(
TopicArn = os.environ['snsarn'],
Subject = f'Insufficient {metric_msg} Utilization Alarm : {instanceid}',
Message = str(email_body)
)
print('Mail has been sent') if res else print('Email not sent')
else:
email_body = str(0)
################## Lambda Handler Function ################
###########################################################
def lambda_handler(event, context):
instanceid = event['detail']['configuration']['metrics'][0]['metricStat']['metric']['dimensions']['InstanceId']
metric_name = event['detail']['configuration']['metrics'][0]['metricStat']['metric']['name']
account = event['account']
timestamp = event['time']
region = event['region']
current_state = event['detail']['state']['value']
current_reason = event['detail']['state']['reason']
previous_state = event['detail']['previousState']['value']
previous_reason = event['detail']['previousState']['reason']
metric_val = 'NA'
##### function calling #####
if metric_name == 'CPUUtilization':
cpu_utilization(instanceid, metric_name, previous_state, current_state)
create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val)
send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink)
elif metric_name == 'mem_used_percent':
mem_utilization(instanceid, metric_name, previous_state, current_state)
create_issues(instanceid, metric_name, account, timestamp, region, current_state, previous_state, cpu_process_op, mem_process_op, metric_val)
send_email(instanceid, metric_name, account, region, timestamp, current_state, current_reason, previous_state, previous_reason, cpu_process_op, mem_process_op, metric_val, issueid, issuekey, issuelink)
else:
None
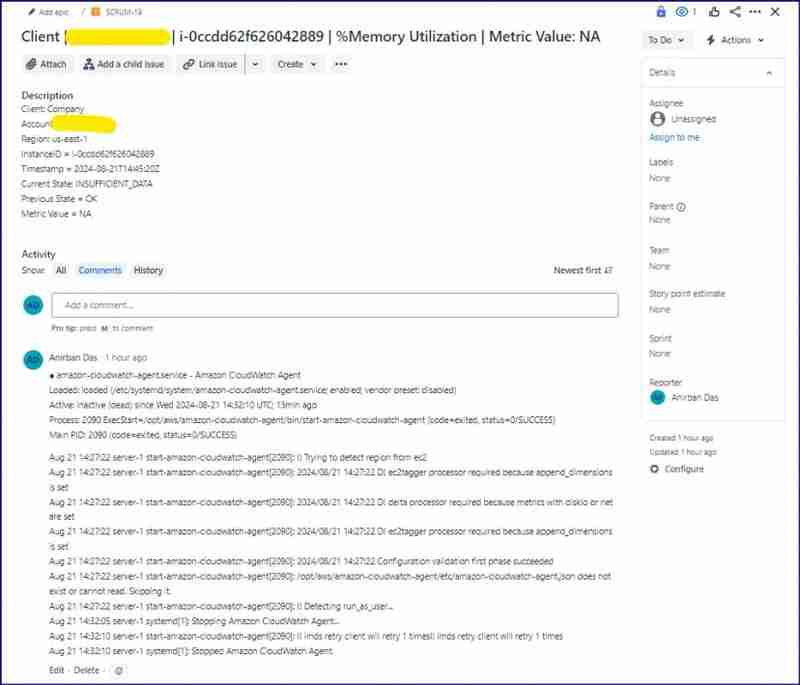
Insufficient Data Email Screenshot :
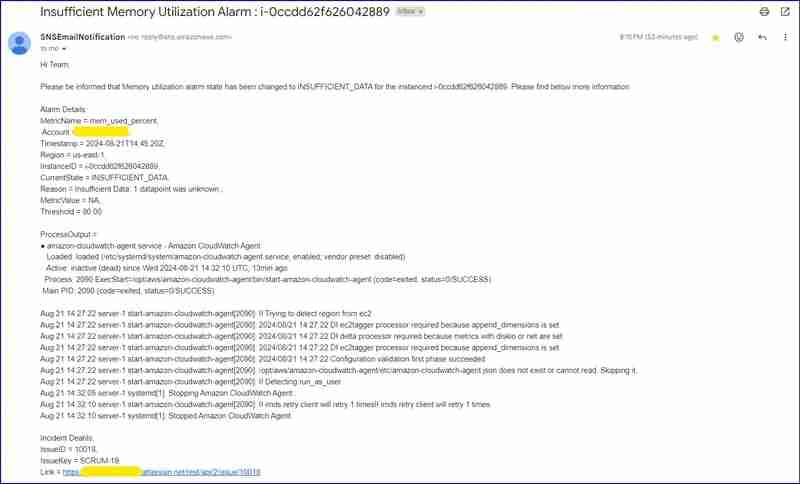
Insufficient data JIRA Issue :
Conclusion :
In this article, we have tested scenarios on both cpu and memory utilization, but there can be lots of metrics on which we can configure auto-incident and auto-email functionality which will reduce significant efforts in terms of monitoring and creating incidents and all. This solution has given a initial approach how we can proceed further, but for sure there can be other possibilities to achieve this goal. I believe you all will understand the way we tried to make this relatable. Please like and comment if you love this article or have any other suggestions, so that we can populate in coming articles. ??
Thanks!!
Anirban Das
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Blockbuster Python terminé Affichage de l'entrée Python Collection de site Web fini gratuit
Jul 23, 2025 pm 12:36 PM
Blockbuster Python terminé Affichage de l'entrée Python Collection de site Web fini gratuit
Jul 23, 2025 pm 12:36 PM
Cet article a sélectionné plusieurs sites Web de projet "finis" Python et des portails de ressources d'apprentissage "Blockbuster" de haut niveau pour vous. Que vous recherchiez l'inspiration de développement, l'observation et l'apprentissage du code source au niveau de la maîtrise ou que vous amélioriez systématiquement vos capacités pratiques, ces plateformes ne sont pas manquées et peuvent vous aider à devenir un maître Python rapidement.
 Python pour l'apprentissage automatique quantique
Jul 21, 2025 am 02:48 AM
Python pour l'apprentissage automatique quantique
Jul 21, 2025 am 02:48 AM
Pour commencer avec Quantum Machine Learning (QML), l'outil préféré est Python et des bibliothèques telles que Pennylane, Qiskit, Tensorflowquantum ou Pytorchquantum doivent être installées; Familiarisez-vous ensuite avec le processus en exécutant des exemples, tels que l'utilisation de Pennylane pour construire un réseau neuronal quantique; Ensuite, implémentez le modèle en fonction des étapes de la préparation des ensembles de données, du codage des données, de la construction de circuits quantiques paramétriques, de la formation Classic Optimizer, etc.; Dans le combat réel, vous devez éviter de poursuivre des modèles complexes depuis le début, en faisant attention aux limitations matérielles, en adoptant des structures de modèles hybrides et en se référant continuellement aux derniers documents et documents officiels à suivre le développement.
 Exemple de commande de Shell Run Shell
Jul 26, 2025 am 07:50 AM
Exemple de commande de Shell Run Shell
Jul 26, 2025 am 07:50 AM
Utilisez Sub-Process.run () pour exécuter en toute sécurité les commandes de shell et la sortie de capture. Il est recommandé de transmettre des paramètres dans les listes pour éviter les risques d'injection; 2. Lorsque les caractéristiques du shell sont nécessaires, vous pouvez définir Shell = True, mais méfiez-vous de l'injection de commande; 3. Utilisez un sous-processus.popen pour réaliser le traitement de sortie en temps réel; 4. SET CHECK = TRUE pour lancer des exceptions lorsque la commande échoue; 5. Vous pouvez appeler directement des chaînes pour obtenir la sortie dans un scénario simple; Vous devez donner la priorité à Sub-Process.run () dans la vie quotidienne pour éviter d'utiliser OS.System () ou les modules obsolètes. Les méthodes ci-dessus remplacent l'utilisation du noyau de l'exécution des commandes shell dans Python.
 Python Seaborn JointPlot Exemple
Jul 26, 2025 am 08:11 AM
Python Seaborn JointPlot Exemple
Jul 26, 2025 am 08:11 AM
Utilisez le plot conjoint de Seaborn pour visualiser rapidement la relation et la distribution entre deux variables; 2. Le tracé de diffusion de base est implémenté par sn.jointplot (data = pointes, x = "total_bill", y = "Tip", kind = "dispers"), le centre est un tracé de dispersion et l'histogramme est affiché sur les côtés supérieur et inférieur et droit; 3. Ajouter des lignes de régression et des informations de densité à un kind = "reg" et combiner marginal_kws pour définir le style de tracé de bord; 4. Lorsque le volume de données est important, il est recommandé d'utiliser "Hex"
 Tutoriel de grattement Web Python
Jul 21, 2025 am 02:39 AM
Tutoriel de grattement Web Python
Jul 21, 2025 am 02:39 AM
Pour maîtriser Python Web Crawlers, vous devez saisir trois étapes de base: 1. Utilisez les demandes pour lancer une demande, obtenir du contenu de la page Web via la méthode GET, faire attention à la définition d'en-têtes, gérer les exceptions et se conformer à robots.txt; 2. Utilisez BeautifulSoup ou XPath pour extraire les données. Le premier convient à l'analyse simple, tandis que le second est plus flexible et adapté aux structures complexes; 3. Utilisez du sélénium pour simuler les opérations du navigateur pour le contenu de chargement dynamique. Bien que la vitesse soit lente, elle peut faire face à des pages complexes. Vous pouvez également essayer de trouver une interface API de site Web pour améliorer l'efficacité.
 Python List to String Conversion Exemple
Jul 26, 2025 am 08:00 AM
Python List to String Conversion Exemple
Jul 26, 2025 am 08:00 AM
Les listes de chaînes peuvent être fusionnées avec la méthode join (), telles que '' .join (mots) pour obtenir "HelloworldFrompython"; 2. Les listes de nombres doivent être converties en chaînes avec MAP (STR, nombres) ou [STR (x) Forxinnumbers] avant de rejoindre; 3. Toute liste de types peut être directement convertie en chaînes avec des supports et des devis, adaptées au débogage; 4. Les formats personnalisés peuvent être implémentés par des expressions de générateur combinées avec join (), telles que '|' .join (f "[{item}]" ForIteminitems)
 Python Connexion à SQL Server PyoDBC Exemple
Jul 30, 2025 am 02:53 AM
Python Connexion à SQL Server PyoDBC Exemple
Jul 30, 2025 am 02:53 AM
Installez PYODBC: utilisez la commande PiPInstallpyodbc pour installer la bibliothèque; 2. Connectez SQLServer: utilisez la chaîne de connexion contenant le pilote, le serveur, la base de données, l'UID / PWD ou TrustEd_Connection via la méthode pyoDBC.Connect () et prendre en charge l'authentification SQL ou l'authentification Windows respectivement; 3. Vérifiez le pilote installé: exécutez pyodbc.Drivers () et filtrez le nom du pilote contenant «SQLServer» pour vous assurer que le nom du pilote correct est utilisé tel que «ODBCDriver17 pour SQLServer»; 4. Paramètres clés de la chaîne de connexion
 Python Httpx Async Client Exemple
Jul 29, 2025 am 01:08 AM
Python Httpx Async Client Exemple
Jul 29, 2025 am 01:08 AM
Utilisez httpx.asyncclient pour initier efficacement les demandes HTTP asynchrones. 1. 2. Combiner asyncio.gather à se combiner avec Asyncio.gather peut considérablement améliorer les performances, et le temps total est égal à la demande la plus lente; 3. Prise en charge des en-têtes personnalisés, des paramètres d'authentification, de base_url et de délai d'expiration; 4. Peut envoyer des demandes de poste et transporter des données JSON; 5. Faites attention pour éviter de mélanger le code asynchrone synchrone. Le support proxy doit prêter attention à la compatibilité back-end, ce qui convient aux robots ou à l'agrégation API et à d'autres scénarios.
