


Les grands modèles peuvent former votre propre compréhension du monde réel !
Une étude du MIT a révélé qu'à mesure qu'un modèle devient plus performant, sa compréhension de la réalité peut aller au-delà de la simple imitation.
Par exemple, si le grand modèle n'a jamais senti d'odeur, cela veut-il dire qu'il ne peut pas comprendre les odeurs ?
Des recherches ont montré qu'il peut simuler spontanément certains concepts pour en faciliter la compréhension.
Cette recherche signifie que les grands modèles devraient avoir une compréhension plus profonde du langage et du monde à l'avenir. L'article a été accepté par la conférence ICML 24.

Les auteurs de cet article sont le doctorant chinois Charles Jin et son superviseur, le professeur Martin Rinard du Laboratoire d'informatique et d'intelligence artificielle du MIT (CSAIL).
Dans l'étude, l'auteur a demandé au grand modèle d'apprendre uniquement le texte du code et a constaté que le modèle en comprenait progressivement le sens.
Le professeur Rinard a déclaré que cette recherche aborde directement une question centrale de l'intelligence artificielle moderne :
La capacité des grands modèles est-elle simplement due à des corrélations statistiques à grande échelle, ou est-ce est-il vrai que cela génère une compréhension significative des problèmes du monde réel qu’ils abordent ?
△Source : site officiel du MIT
Dans le même temps, cette recherche a également déclenché de nombreuses discussions.
Certains internautes ont déclaré que même si les grands modèles peuvent comprendre le langage différemment des humains, cette étude montre au moins que le modèle fait plus que simplement mémoriser les données d'entraînement.

Laissez le grand modèle apprendre le code pur
Afin d'explorer si le grand modèle peut produire une compréhension au niveau sémantique, l'auteur a construit un ensemble de données synthétiques composé du code du programme et de ses entrées et sorties correspondantes.
Ces programmes de code sont écrits dans un langage pédagogique appelé Karel et sont principalement utilisés pour mettre en œuvre la tâche des robots naviguant dans un monde en grille 2D.
Ce monde en grille se compose de grilles 8x8, chaque grille peut contenir des obstacles, des marqueurs ou des espaces ouverts. Le robot peut se déplacer entre les grilles et effectuer des opérations telles que placer/ramasser des marqueurs.
Le langage Karel contient 5 opérations primitives - move (avancer d'un pas), turnLeft (tourner à gauche de 90 degrés), turnRight (tourner à droite de 90 degrés), pickMarker (ramasser des marqueurs), putMarker (placer des marqueurs) objets), un programme est constitué d’une séquence de ces opérations primitives.
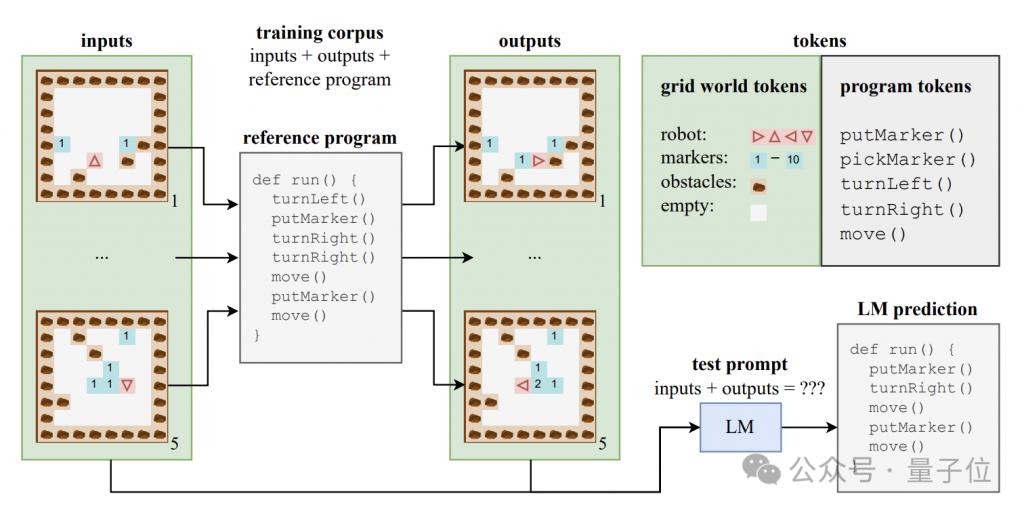
Les auteurs ont généré aléatoirement un ensemble de formation contenant 500 000 programmes Karel, chaque programme ayant une longueur comprise entre 6 et 10.
Chaque échantillon de formation se compose de trois parties : 5 états d'entrée, 5 états de sortie et le code complet du programme. Les états d'entrée et de sortie sont codés dans des chaînes dans un format spécifique.
À l'aide de ces données, les auteurs ont formé une variante du modèle CodeGen de l'architecture standard de Transformer.
Pendant le processus de formation, le modèle peut accéder aux informations d'entrée et de sortie et au préfixe du programme dans chaque échantillon, mais ne peut pas voir la trajectoire complète et les états intermédiaires d'exécution du programme.
En plus de l'ensemble de formation, l'auteur a également construit un ensemble de tests contenant 10 000 échantillons pour évaluer les performances de généralisation du modèle.
Afin d'étudier si le modèle de langage a saisi la sémantique derrière le code, et en même temps d'avoir une compréhension approfondie du « processus de réflexion » du modèle, l'auteur a conçu un ensemble de détecteurs combinaisons comprenant des classificateurs linéaires et des MLP à couche cachée simple/double.
L'entrée du détecteur est l'état caché du modèle de langage dans le processus de génération de jetons de programme, et la cible de prédiction est l'état intermédiaire d'exécution du programme, y compris l'orientation et l'écart du robot par rapport au position initiale. Les trois caractéristiques sont le déplacement (position) et le fait que l'avant soit face à l'obstacle (obstacle).
Pendant le processus de formation du modèle génératif, l'auteur a enregistré les trois caractéristiques ci-dessus toutes les 4000 étapes, et a également enregistré l'état caché du modèle génératif pour former un ensemble de données de formation pour le détecteur.
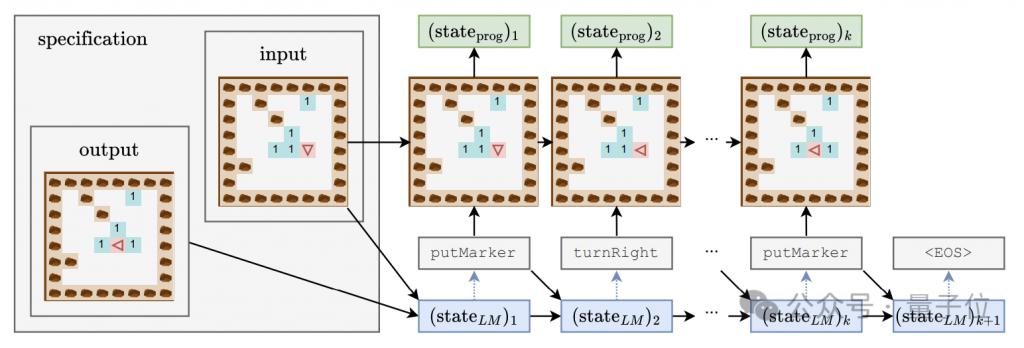
Trois étapes de l'apprentissage du grand modèle
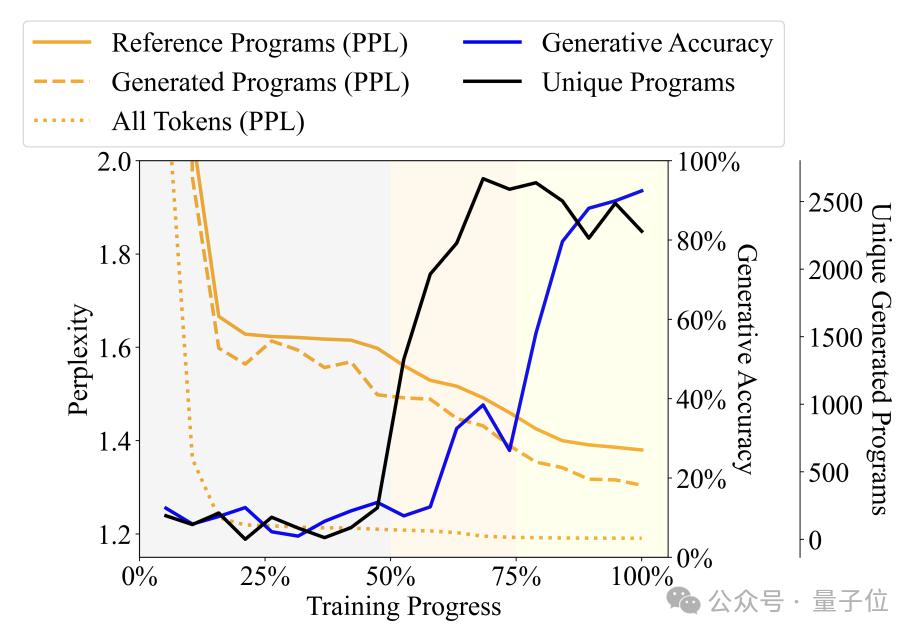
En observant la diversité, la perplexité et autres indicateurs du programme générés par le langage modèle À mesure que le processus de formation change, l'auteur divise le processus de formation en trois étapes -
Étape du babillage (non-sens) : le programme de sortie est très répétitif et la précision du détecteur est instable.
Étape d'acquisition de la grammaire : la diversité des programmes augmente rapidement, la précision de la génération augmente légèrement et la confusion diminue, indiquant que le modèle de langage a appris la structure syntaxique du programme.
Étape d'acquisition sémantique : le degré de diversité du programme et la maîtrise de la structure syntaxique sont stables, mais la précision de la génération et les performances du détecteur sont grandement améliorées, indiquant que le modèle de langage a appris la sémantique du programme.
Plus précisément, l'étape Babbling occupe les premiers 50 % de l'ensemble du processus de formation. Par exemple, lorsque la formation atteint environ 20 %, quelle que soit la spécification saisie, le modèle générera uniquement un programme fixe - "pickMarker". Répétez 9 fois.
L'étape d'acquisition de la grammaire se situe entre 50% et 75% du processus d'apprentissage. La perplexité du modèle sur le programme Karel a considérablement diminué, indiquant que le modèle linguistique a commencé à mieux s'adapter aux caractéristiques statistiques de le programme Karel, mais la précision générée du programme ne s'est pas beaucoup améliorée (d'environ 10 % à environ 25 %), et il ne peut toujours pas accomplir la tâche avec précision.
L'étape d'acquisition sémantique représente les 25 % finaux, et la précision du programme s'est considérablement améliorée, d'environ 25 % à plus de 90 %, et le programme généré peut accomplir avec précision la tâche donnée.
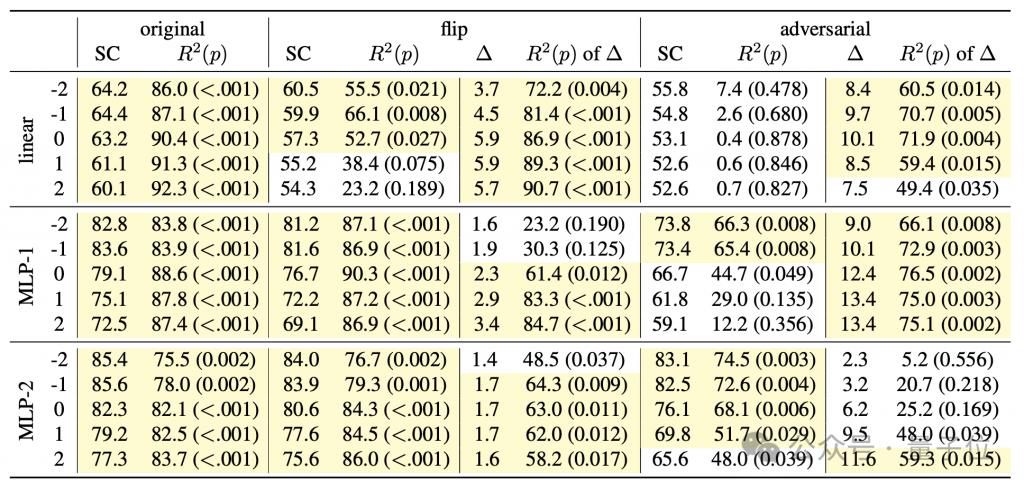
D'autres expériences ont montré que le détecteur peut non seulement prédire le pas de temps synchronisé à l'instant t, mais également prédire l'état d'exécution du programme des pas de temps suivants.
Par exemple, supposons que le modèle génératif génère un jeton "move" au temps t et génère "turnLeft" au temps t+1.
En même temps, l'état du programme à l'instant t est que le robot est face au nord et se situe aux coordonnées (0,0), tandis que le robot à l'instant t+1 sera celui du robot sera orienté vers l'ouest, avec la position inchangée.
Si le détecteur peut prédire avec succès à partir de l'état caché du modèle de langage à l'instant t que le robot fera face à l'ouest à l'instant t+1, cela signifie que l'état caché est déjà inclus avant de générer " turnLeft" Les informations de changement d'état apportées par cette opération.
Ce phénomène montre que le modèle n'a pas seulement une compréhension sémantique de la partie de programme générée, mais qu'à chaque étape de génération, il a déjà anticipé et planifié le contenu à générer ensuite, montrant que Développer capacités préliminaires de raisonnement prospectif.
Mais cette découverte a posé de nouvelles questions à cette recherche-
L'amélioration de la précision observée dans l'expérience est-elle vraiment une amélioration du modèle génératif, ou est-ce le résultat de ? la propre inférence du détecteur ?
Afin de résoudre ce doute, l'auteur a ajouté une expérience d'intervention de détection sémantique.
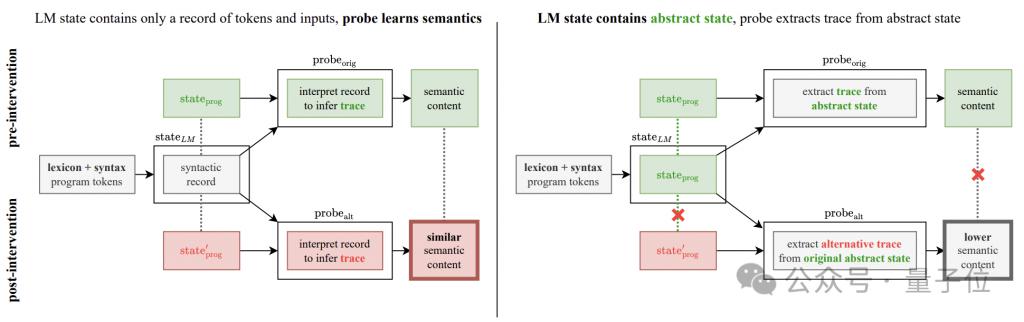
L'idée de base de l'expérience est de changer les règles d'interprétation sémantique des opérations du programme, qui sont divisées en deux méthodes : "flip" et « contradictoire ».
"flip" est une inversion forcée du sens de l'instruction. Par exemple, "turnRight" est interprété de force comme "turn left". Cependant, seuls "turnLeft" et "turnRight" peuvent effectuer cette opération. sorte d'inversion ; # #
"adversarial" brouille aléatoirement la sémantique correspondant à toutes les instructions. La méthode spécifique est celle indiquée dans le tableau ci-dessous.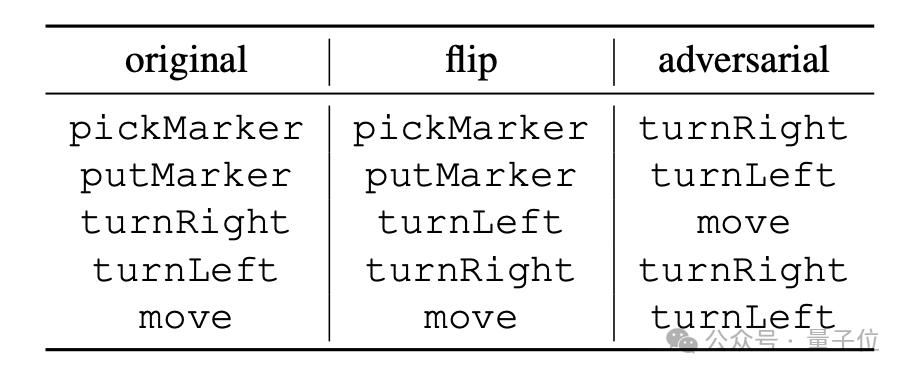
# # [ 1 ] https://news.mit.edu/2024/llms-develop-own-understanding-of-reality-as-lingual-abilities-improve-0814
[ 2 ] https://www.reddit.com/r/LocalLLaMA/comments/1esxkin/llms_develop_their_own_understanding_of_reality/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!





























![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



