


Si vous avez du matériel inutilisé, vous voudrez peut-être l'essayer.
Cette fois, l'appareil matériel dans votre main peut également faire travailler ses muscles dans le domaine de l'IA.
En combinant iPhone, iPad et Macbook, vous pouvez assembler une « solution d'inférence de cluster hétérogène » puis exécuter le modèle Llama3 en douceur.

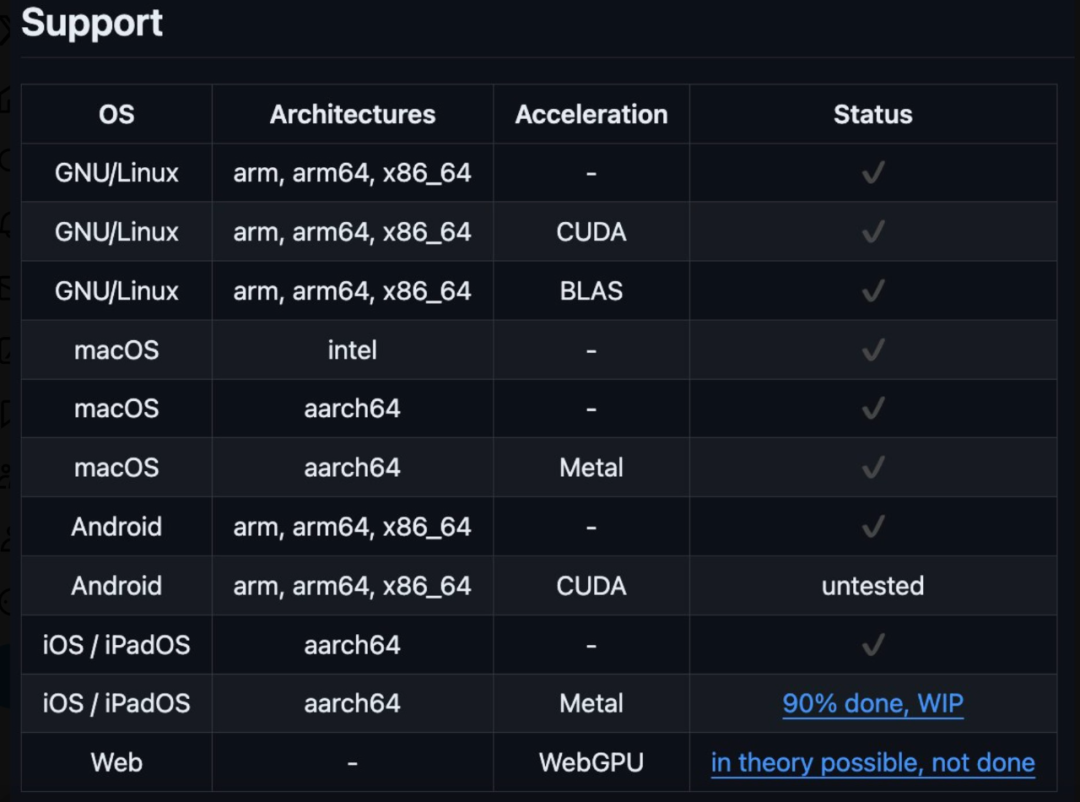
Il convient de mentionner que ce cluster hétérogène peut être un système Windows, Linux ou iOS, et que la prise en charge d'Android sera bientôt disponible. Le cluster hétérogène est en cours d'exécution.
 Selon l'auteur du projet @evilsocket, ce cluster hétérogène comprend l'iPhone 15 Pro Max, l'iPad Pro, le MacBook Pro (M1 Max), NVIDIA GeForce 3080, 2x NVIDIA Titan X Pascal. Tout le code a été téléchargé sur GitHub. Voyant cela, les internautes ont exprimé que ce vieil homme n'est effectivement pas simple.
Selon l'auteur du projet @evilsocket, ce cluster hétérogène comprend l'iPhone 15 Pro Max, l'iPad Pro, le MacBook Pro (M1 Max), NVIDIA GeForce 3080, 2x NVIDIA Titan X Pascal. Tout le code a été téléchargé sur GitHub. Voyant cela, les internautes ont exprimé que ce vieil homme n'est effectivement pas simple.
Cependant, certains internautes commencent à s'inquiéter de la consommation d'énergie, quelle que soit la vitesse, la facture d'électricité ne peut pas être payée. Le déplacement de données dans les deux sens entraîne trop de pertes.


Adresse du projet : https://github.com/evilsocket/cake
L'idée principale de Cake est de partager des blocs de transformateur sur plusieurs appareils pour pouvoir exécuter des inférences sur des modèles qui ne rentrent généralement pas dans la mémoire GPU d'un seul appareil. L'inférence sur des blocs de transformateur consécutifs sur le même thread de travail est groupée pour minimiser les retards causés par le transfert de données. 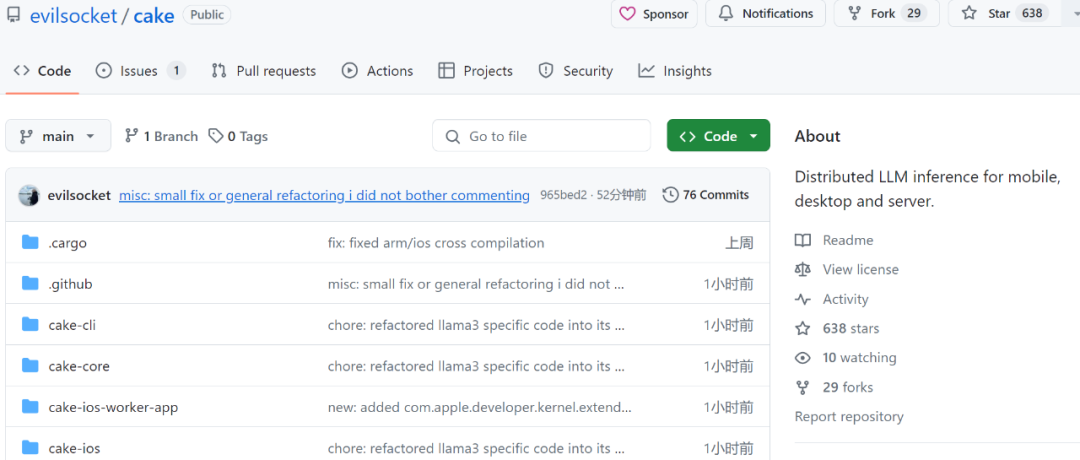
cargo build --release
Copier après la connexion
make ios
Utilisez
pour exécuter le nœud de travail :cake-cli --model /path/to/Meta-Llama-3-8B \ # model path, read below on how to optimize model size for workers --mode worker \# run as worker --name worker0 \ # worker name in topology file --topology topology.yml \# topology --address 0.0.0.0:10128 # bind address
Copier après la connexion
cake-cli --model /path/to/Meta-Llama-3-8B \ --topology topology.yml
linux_server_1:host: 'linux_server.host:10128'description: 'NVIDIA Titan X Pascal (12GB)'layers:- 'model.layers.0-5'linux_server_2:host: 'linux_server2.host:10128'description: 'NVIDIA GeForce 3080 (10GB)'layers:- 'model.layers.6-16'iphone:host: 'iphone.host:10128'description: 'iPhone 15 Pro Max'layers:- 'model.layers.17'ipad:host: 'ipad.host:10128'description: 'iPad'layers:- 'model.layers.18-19'macbook:host: 'macbook.host:10128'description: 'M1 Max'layers: - 'model.layers.20-31'
cake-split-model --model-path path/to/Meta-Llama-3-8B \ # source model to split --topology path/to/topology.yml \# topology file --output output-folder-name
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 méthode de recherche de fichier pycharm
méthode de recherche de fichier pycharm
 point de symbole spécial
point de symbole spécial
 Comment changer l'adresse IP sous Linux
Comment changer l'adresse IP sous Linux
 Introduction aux indicateurs de performances du disque dur
Introduction aux indicateurs de performances du disque dur
 Tendance du marché des devises
Tendance du marché des devises
 Une liste complète des DNS publics couramment utilisés
Une liste complète des DNS publics couramment utilisés
 Quelles sont les vulnérabilités courantes de Tomcat ?
Quelles sont les vulnérabilités courantes de Tomcat ?
 Application de trading de devises numériques
Application de trading de devises numériques





















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



