



La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Le premier auteur de cet article est Yang Yuchen, étudiant en deuxième année de maîtrise à l'École de statistique et de science des données de l'Université de Nankai, et son conseiller. est professeur agrégé Xu Jun à l'École de statistique et de science des données de l'Université de Nankai. Les recherches de l’équipe du professeur Xu Jun portent sur la vision par ordinateur, l’IA générative et l’apprentissage automatique efficace. Elle a publié de nombreux articles dans des conférences et revues de premier plan, avec plus de 4 700 citations de Google Scholar.
Étant donné que les modèles Transformer à grande échelle sont progressivement devenus une architecture unifiée dans divers domaines, le réglage fin est devenu un moyen important d'appliquer de grands modèles pré-entraînés aux tâches en aval. Cependant, à mesure que la taille du modèle augmente de jour en jour, la mémoire vidéo requise pour le réglage fin augmente également progressivement. Comment réduire efficacement la mémoire vidéo pour le réglage fin est devenu un problème important. Auparavant, lors du réglage fin du modèle Transformer, afin d'économiser la mémoire graphique, l'approche habituelle consistait à utiliser des points de contrôle de gradient (également appelés recalculs d'activation) pour réduire le temps requis dans le processus de rétropropagation (BP) au détriment de la vitesse d'entraînement. . Activez l'utilisation de la mémoire vidéo.
Récemment, l'article "Réduire les frais généraux de mémoire de réglage fin par rétropropagation approximative et de partage de mémoire" publié à l'ICML 2024 par l'équipe du professeur Xu Jun de l'École de statistique et de science des données de l'Université de Nankai a proposé qu'en modifiant la rétropropagation ( BP), sans augmenter la quantité de calcul, l'utilisation maximale de la mémoire d'activation est considérablement réduite.

Article : Réduire la surcharge de mémoire de réglage fin par rétropropagation approximative et par partage de mémoire
Lien article : https://arxiv.org/abs/2406.16282
Lien du projet : https:/ / /github.com/yyyyychen/LowMemoryBP
L'article propose deux stratégies d'amélioration de la rétropropagation, à savoir la rétropropagation approximative (Approx-BP) et la rétropropagation de partage de mémoire (MS-BP). Approx-BP et MS-BP représentent respectivement deux solutions pour améliorer l'efficacité de la mémoire lors de la rétropropagation, qui peuvent être collectivement appelées LowMemoryBP. Que ce soit dans un sens théorique ou pratique, l'article fournit des conseils révolutionnaires pour une formation plus efficace en matière de rétropropagation.
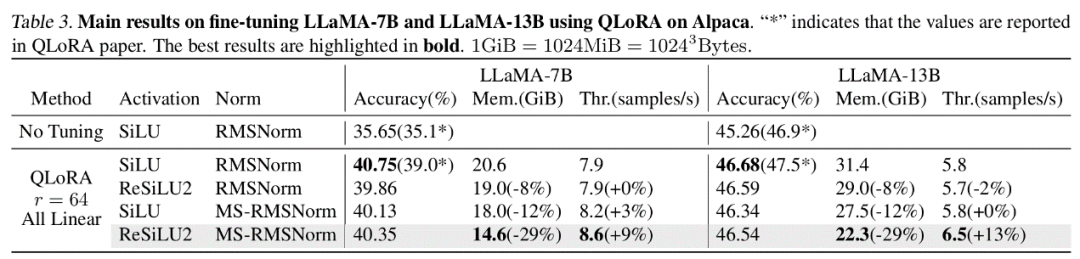
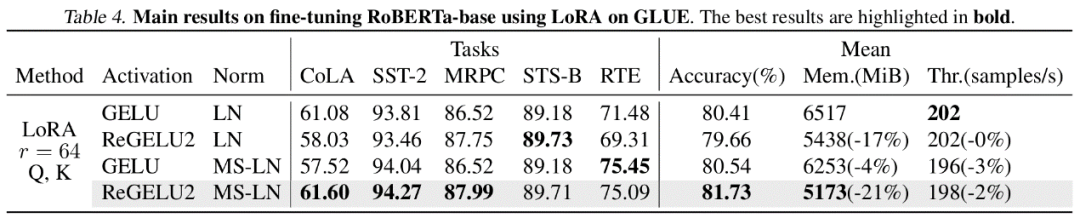
Dans l'analyse théorique de la mémoire, LowMemoryBP peut réduire considérablement l'utilisation de la mémoire d'activation des fonctions d'activation et des couches de normalisation en prenant ViT et LLaMA comme exemples, un réglage fin de ViT peut réduire la mémoire d'activation de 39,47 %, et un réglage fin de LLaMA peut réduire l'activation de. 29,19 % de mémoire vidéo.
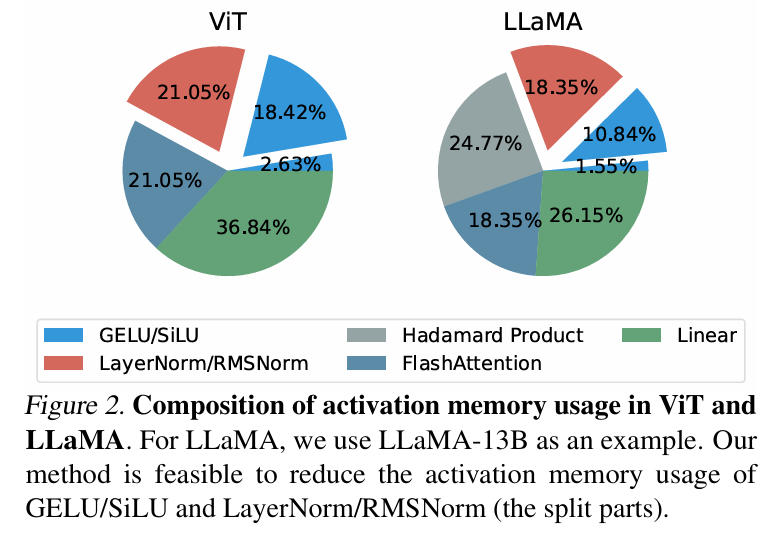
Dans des expériences réelles, LowMemoryBP peut réduire efficacement l'utilisation maximale de la mémoire lors du réglage fin du modèle Transformer, notamment ViT, LLaMA, RoBERTa, BERT et Swin, de 20 à 30 %, et n'augmentera pas le débit ni la perte d'entraînement. de la précision des tests.
Approx-BP
Dans la formation de rétropropagation traditionnelle, la rétropropagation du gradient de la fonction d'activation correspond strictement à sa fonction dérivée. Pour les fonctions GELU et SiLU couramment utilisées dans le modèle Transformer, cela signifie que l'entrée doit. be Le tenseur de fonctionnalités est entièrement stocké dans la mémoire vidéo active. L'auteur de cet article a proposé un ensemble de théories d'approximation de rétropropagation, à savoir la théorie Approx-BP. Guidé par cette théorie, l'auteur utilise une fonction linéaire par morceaux pour approximer la fonction d'activation, et remplace la rétropropagation du gradient GELU/SiLU par la dérivée de la fonction linéaire par morceaux (fonction d'étape). Cette approche conduit à deux fonctions d'activation asymétriques économes en mémoire : ReGELU2 et ReSiLU2. Ce type de fonction d'activation utilise une fonction pas à pas en 4 étapes pour le passback inverse, de sorte que le stockage d'activation n'a besoin que d'utiliser un type de données de 2 bits.
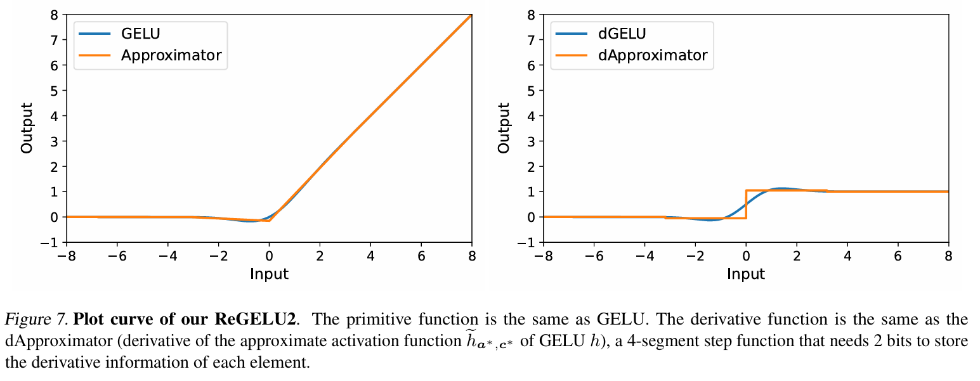
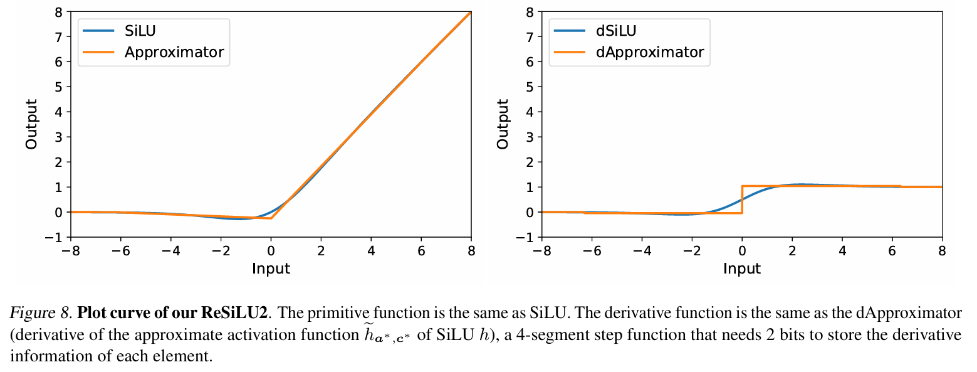
MS-BP
BP Chaque couche du réseau stocke généralement le tenseur d'entrée dans la mémoire d'activation pour le calcul de rétropropagation. L'auteur souligne que si la rétropropagation d'une certaine couche peut être réécrite sous une forme dépendante de la sortie, alors cette couche et la couche suivante peuvent partager le même tenseur d'activation, réduisant ainsi la redondance du stockage d'activation.
L'article souligne que LayerNorm et RMSNorm, qui sont couramment utilisés dans les modèles Transformer, peuvent bien répondre aux exigences de la stratégie MS-BP après avoir fusionné les paramètres affines dans la couche linéaire de cette dernière couche. Les MS-LayerNorm et MS-RMSNorm repensés ne génèrent plus de mémoire graphique active indépendante.

Résultats expérimentaux
L'auteur a mené des expériences de mise au point sur plusieurs modèles représentatifs dans les domaines de la vision par ordinateur et du traitement du langage naturel. Parmi eux, dans les expériences de réglage fin de ViT, LLaMA et RoBERTa, la méthode proposée dans l'article a réduit l'utilisation maximale de la mémoire de 27 %, 29 % et 21 % respectivement, sans entraîner de perte d'effet d'entraînement ni de vitesse d'entraînement. A noter que la comparaison Mesa (une méthode d'Activation Compressed Training 8 bits) réduit la vitesse d'entraînement d'environ 20 %, tandis que la méthode LowMemoryBP proposée dans l'article maintient complètement la vitesse d'entraînement.
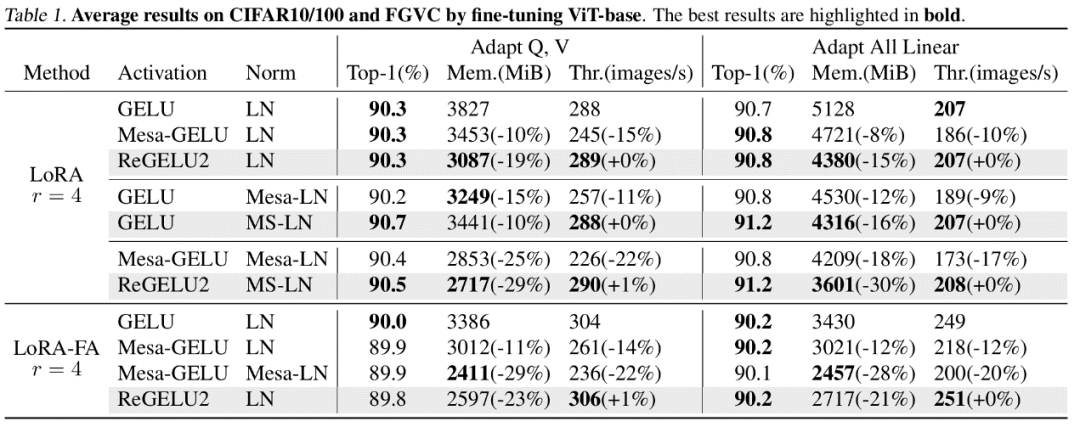
Conclusion et signification
Les deux stratégies d'amélioration de la pression artérielle proposées dans l'article, Approx-BP et MS-BP, permettent toutes deux d'activer la mémoire vidéo tout en maintenant l'effet d'entraînement et l'entraînement. rapidité. Cela signifie que l'optimisation basée sur le principe BP est une solution très prometteuse pour économiser la mémoire. De plus, la théorie Approx-BP proposée dans l'article brise le cadre d'optimisation des réseaux de neurones traditionnels et fournit une faisabilité théorique pour l'utilisation de dérivées non appariées. Ses dérivés ReGELU2 et ReSiLU2 démontrent la valeur pratique importante de cette approche.
Vous êtes invités à lire l'article ou le code pour comprendre les détails de l'algorithme. Les modules pertinents ont été open source sur le référentiel github du projet LowMemoryBP.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Le rôle de la fonction float() en python
Le rôle de la fonction float() en python
 pilote universel de périphérique PCI
pilote universel de périphérique PCI
 Plateforme de trading personnelle Bitcoin
Plateforme de trading personnelle Bitcoin
 Requête blockchain du navigateur Ethereum
Requête blockchain du navigateur Ethereum
 Qu'est-ce que le fichier ESD ?
Qu'est-ce que le fichier ESD ?
 Livre de a5 et b5
Livre de a5 et b5
 À quelle devise appartient l'USDT ?
À quelle devise appartient l'USDT ?
 Comment transformer deux pages en un seul document Word
Comment transformer deux pages en un seul document Word








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



