Lors de la conférence mondiale des développeurs qui vient de se terminer, Apple a annoncé Apple Intelligence, un nouveau système d'intelligence personnalisée profondément intégré à iOS 18, iPadOS 18 et macOS Sequoia.

Apple+ Intelligence se compose d'une variété de modèles génératifs hautement intelligents conçus pour les tâches quotidiennes des utilisateurs. Dans le blog d'Apple récemment mis à jour, ils détaillent deux des modèles.
Ces deux modèles de base font partie de la famille de modèles génératifs d'Apple, et Apple annonce qu'ils partageront plus d'informations sur cette famille de modèles dans un avenir proche.
Dans ce blog, Apple passe beaucoup de temps à présenter comment ils développent des modèles hautes performances, rapides et économes en énergie ; comment former ces modèles ; comment affiner les adaptateurs pour les besoins spécifiques des utilisateurs et comment évaluer le modèle ; pour aider et éviter les performances en termes de blessures accidentelles.型 Présentation de la modélisation des modèles de base Apple Pré-formation
Les modèles de base sont formés sur le framework Axlearn Il s'agit d'Apple Un projet open source sorti en 2023. Le framework est construit sur JAX et XLA, permettant aux utilisateurs d'entraîner des modèles de manière efficace et évolutive sur une variété de plates-formes matérielles et cloud, y compris les TPU et les GPU dans le cloud et sur site. De plus, Apple utilise des techniques telles que le parallélisme des données, le parallélisme tensoriel, le parallélisme des séquences et FSDP pour faire évoluer la formation selon plusieurs dimensions telles que les données, le modèle et la longueur de la séquence.
Lors de la formation de son modèle de base, Apple utilise des données autorisées, qui incluent des données spécialement sélectionnées pour améliorer certaines fonctions, ainsi que des données collectées sur le réseau public par le robot d'exploration Web d'Apple, AppleBot. Les éditeurs de contenu Web peuvent choisir de ne pas utiliser leur contenu Web pour former Apple Intelligence en définissant des contrôles d'utilisation des données.
Apple n'utilise jamais les données privées des utilisateurs lors de la formation de son modèle de base. Pour protéger la confidentialité, ils utilisent des filtres pour supprimer les informations personnelles identifiables, telles que les numéros de carte de crédit, qui sont accessibles au public sur Internet. De plus, ils filtrent le langage vulgaire et tout autre contenu de mauvaise qualité avant qu'ils ne soient intégrés à l'ensemble de données de formation. En plus de ces mesures de filtrage, Apple effectue l'extraction et la déduplication des données et utilise des classificateurs basés sur des modèles pour identifier et sélectionner des documents de haute qualité à des fins de formation. Post-training
Apple a constaté que la qualité des données est cruciale pour le modèle, elle a donc adopté une stratégie de données hybrides dans le processus de formation, c'est-à-dire des données annotées manuellement et des données synthétiques, et mené des procédures complètes de gestion et de filtrage des données. Apple a développé deux nouveaux algorithmes dans la phase post-formation : (1) un algorithme de réglage fin de l'échantillonnage de rejet avec un « comité d'enseignants », (2) un renforcement à partir des commentaires humains à l'aide d'une optimisation de stratégie de descente en miroir et d'un laisser-un-dehors. Algorithme d’apprentissage de l’estimateur d’avantages (RLHF). Ces deux algorithmes améliorent considérablement la qualité du suivi des instructions du modèle. Optimisation
En plus d'assurer les hautes performances du modèle généré lui-même, Apple utilise également une variété de technologies innovantes pour optimiser le modèle sur l'appareil et le cloud privé afin d'améliorer la vitesse et efficacité . En particulier, ils ont apporté de nombreuses optimisations au processus de raisonnement du modèle en générant le premier jeton (l'unité de base d'un seul caractère ou mot) et les jetons suivants pour garantir une réponse rapide et un fonctionnement efficace du modèle.
Apple utilise un mécanisme d'attention aux requêtes de groupe à la fois dans le modèle côté appareil et dans le modèle serveur pour améliorer l'efficacité. Pour réduire les besoins en mémoire et les coûts d'inférence, ils utilisent des tables d'intégration de vocabulaire d'entrée et de sortie partagées qui ne sont pas dupliquées lors du mappage. Le modèle côté appareil a un vocabulaire de 49 000, tandis que le modèle serveur a un vocabulaire de 100 000.
Pour l'inférence côté appareil, Apple utilise la palettisation à bits faibles, qui est une technologie d'optimisation clé qui peut répondre aux exigences de mémoire, de consommation d'énergie et de performances nécessaires. Pour maintenir la qualité du modèle, Apple a également développé un nouveau framework utilisant l'adaptateur LoRA qui combine une stratégie de configuration hybride 2 bits et 4 bits (une moyenne de 3,5 bits par poids) pour obtenir la même précision que le modèle non compressé.
De plus, Apple a utilisé Talaria, un outil interactif d'analyse de la latence et de puissance des modèles, ainsi que la quantification d'activation et la quantification d'intégration, et a développé une méthode pour implémenter des mises à jour efficaces du cache clé-valeur (KV) sur le moteur neuronal.
Grâce à cette série d'optimisations, sur iPhone 15 Pro, lorsque le modèle reçoit un mot d'invite, le temps requis entre la réception du mot d'invite et la génération du premier jeton est d'environ 0,6 milliseconde. Ce délai est très court, ce qui indique que. le modèle génère des réponses très rapidement à un rythme de 30 jetons par seconde. Adaptation du modèle
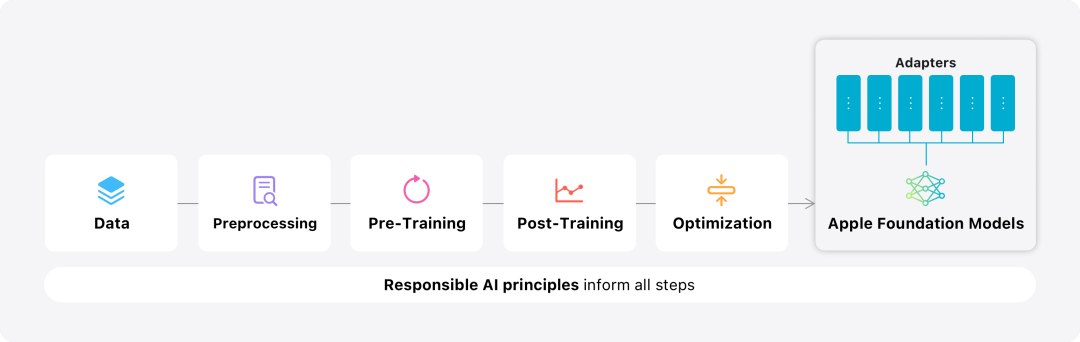
Apple ajuste le modèle de base aux activités quotidiennes de l'utilisateur et peut le spécialiser de manière dynamique pour la tâche à accomplir.L'équipe de recherche utilise des adaptateurs, de petits modules de réseau neuronal qui peuvent être branchés sur différentes couches d'un modèle pré-entraîné, pour affiner le modèle pour des tâches spécifiques. Plus précisément, l’équipe de recherche a ajusté la matrice d’attention, la matrice de projection d’attention et la couche entièrement connectée dans le réseau de rétroaction ponctuelle. En ajustant uniquement la couche adaptateur, les paramètres d'origine du modèle de base pré-entraîné restent inchangés, conservant les connaissances générales du modèle, tout en adaptant la couche adaptateur pour prendre en charge des tâches spécifiques.  Figure 2 : Les adaptateurs sont de petites collections de poids de modèle superposés sur un modèle de base commun. Ils peuvent être chargés et échangés dynamiquement, ce qui permet au modèle sous-jacent de se spécialiser dynamiquement dans la tâche à accomplir. Apple Intelligence comprend un ensemble complet d'adaptateurs, chacun étant optimisé pour des fonctionnalités spécifiques. C'est un moyen efficace d'étendre les fonctionnalités de son modèle de base. L'équipe de recherche utilise 16 bits pour caractériser les valeurs des paramètres de l'adaptateur. Pour un modèle d'appareil avec environ 3 milliards de paramètres, les paramètres de 16 adaptateurs nécessitent généralement 10 mégaoctets. Les modèles d'adaptateur peuvent être chargés dynamiquement, temporairement mis en cache en mémoire et échangés. Cela permet au modèle sous-jacent de se spécialiser dynamiquement dans la tâche en cours tout en gérant efficacement la mémoire et en garantissant la réactivité du système d'exploitation. Pour faciliter la formation des adaptateurs, Apple a créé une infrastructure efficace pour recycler, tester et déployer rapidement les adaptateurs lorsque le modèle sous-jacent ou les données de formation sont mis à jour. Évaluation des performancesApple se concentre sur l'évaluation humaine lors de l'analyse comparative du modèle, car les résultats de l'évaluation humaine sont fortement corrélés à l'expérience utilisateur du produit. Pour évaluer les capacités de synthèse spécifiques au produit, l'équipe de recherche a utilisé un ensemble de 750 réponses soigneusement échantillonnées pour chaque cas d'utilisation. L'ensemble de données d'évaluation met l'accent sur la variété des entrées auxquelles une fonctionnalité de produit peut être confrontée en production et comprend un mélange en couches de documents simples et empilés de différents types de contenu et de longueurs. Les résultats expérimentaux ont montré que les modèles dotés d'adaptateurs étaient capables de générer de meilleurs résumés que des modèles similaires. Dans le cadre du développement responsable, Apple identifie et évalue les risques spécifiques inhérents aux résumés. Par exemple, les résumés suppriment parfois des nuances importantes ou d’autres détails. Cependant, l’équipe de recherche a constaté que l’adaptateur digest n’amplifiait pas le contenu sensible dans plus de 99 % des échantillons contradictoires ciblés.用 Figure 3 : La proportion de « bon » et de « différence » dans le cas d'utilisation abstrait.
Figure 2 : Les adaptateurs sont de petites collections de poids de modèle superposés sur un modèle de base commun. Ils peuvent être chargés et échangés dynamiquement, ce qui permet au modèle sous-jacent de se spécialiser dynamiquement dans la tâche à accomplir. Apple Intelligence comprend un ensemble complet d'adaptateurs, chacun étant optimisé pour des fonctionnalités spécifiques. C'est un moyen efficace d'étendre les fonctionnalités de son modèle de base. L'équipe de recherche utilise 16 bits pour caractériser les valeurs des paramètres de l'adaptateur. Pour un modèle d'appareil avec environ 3 milliards de paramètres, les paramètres de 16 adaptateurs nécessitent généralement 10 mégaoctets. Les modèles d'adaptateur peuvent être chargés dynamiquement, temporairement mis en cache en mémoire et échangés. Cela permet au modèle sous-jacent de se spécialiser dynamiquement dans la tâche en cours tout en gérant efficacement la mémoire et en garantissant la réactivité du système d'exploitation. Pour faciliter la formation des adaptateurs, Apple a créé une infrastructure efficace pour recycler, tester et déployer rapidement les adaptateurs lorsque le modèle sous-jacent ou les données de formation sont mis à jour. Évaluation des performancesApple se concentre sur l'évaluation humaine lors de l'analyse comparative du modèle, car les résultats de l'évaluation humaine sont fortement corrélés à l'expérience utilisateur du produit. Pour évaluer les capacités de synthèse spécifiques au produit, l'équipe de recherche a utilisé un ensemble de 750 réponses soigneusement échantillonnées pour chaque cas d'utilisation. L'ensemble de données d'évaluation met l'accent sur la variété des entrées auxquelles une fonctionnalité de produit peut être confrontée en production et comprend un mélange en couches de documents simples et empilés de différents types de contenu et de longueurs. Les résultats expérimentaux ont montré que les modèles dotés d'adaptateurs étaient capables de générer de meilleurs résumés que des modèles similaires. Dans le cadre du développement responsable, Apple identifie et évalue les risques spécifiques inhérents aux résumés. Par exemple, les résumés suppriment parfois des nuances importantes ou d’autres détails. Cependant, l’équipe de recherche a constaté que l’adaptateur digest n’amplifiait pas le contenu sensible dans plus de 99 % des échantillons contradictoires ciblés.用 Figure 3 : La proportion de « bon » et de « différence » dans le cas d'utilisation abstrait. 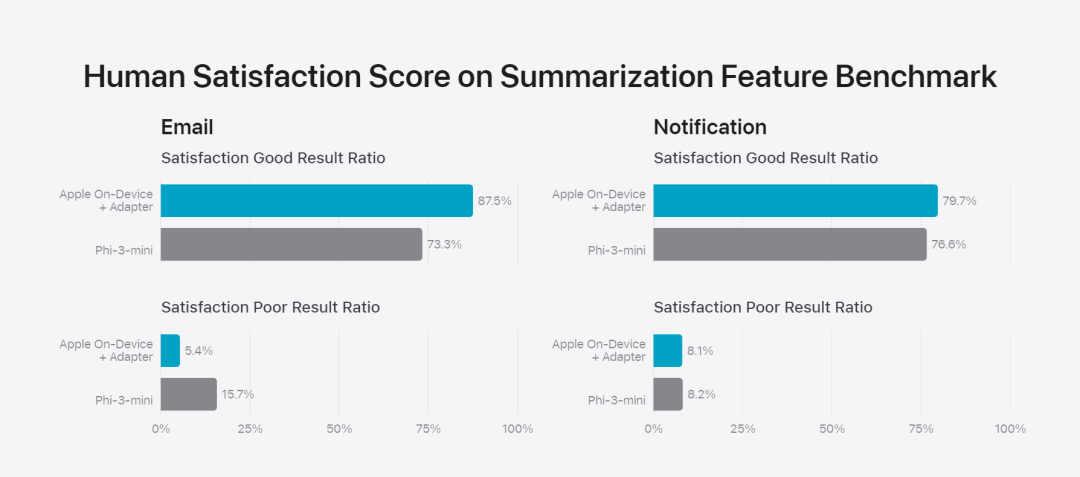 En plus d'évaluer les fonctionnalités spécifiques prises en charge par le modèle de base et les adaptateurs, l'équipe de recherche a également évalué la fonctionnalité générale des modèles sur appareil et des modèles basés sur serveur. Plus précisément, l'équipe de recherche a utilisé un ensemble complet d'invites du monde réel pour tester les fonctionnalités du modèle, couvrant le brainstorming, la classification, les questions-réponses fermées, le codage, l'extraction, le raisonnement mathématique, les questions-réponses ouvertes, la réécriture, la sécurité, le résumé et la tâche d'écriture.
En plus d'évaluer les fonctionnalités spécifiques prises en charge par le modèle de base et les adaptateurs, l'équipe de recherche a également évalué la fonctionnalité générale des modèles sur appareil et des modèles basés sur serveur. Plus précisément, l'équipe de recherche a utilisé un ensemble complet d'invites du monde réel pour tester les fonctionnalités du modèle, couvrant le brainstorming, la classification, les questions-réponses fermées, le codage, l'extraction, le raisonnement mathématique, les questions-réponses ouvertes, la réécriture, la sécurité, le résumé et la tâche d'écriture.
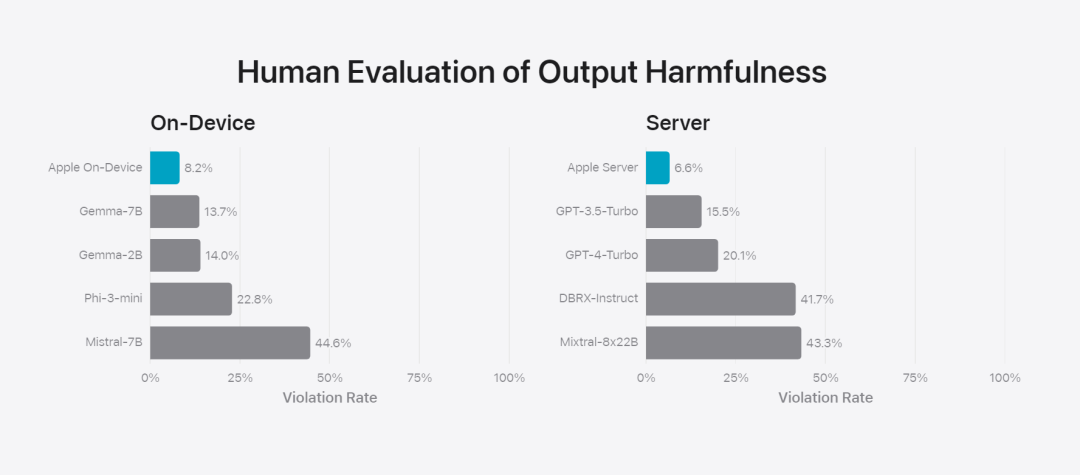
L'équipe de recherche a comparé le modèle avec des modèles open source (Phi-3, Gemma, Mistral, DBRX) et des modèles commerciaux d'échelle comparable (GPT-3.5-Turbo, GPT-4-Turbo). Il a été constaté que le modèle d'Apple était favorisé par les évaluateurs humains par rapport à la plupart des modèles concurrents. Par exemple, le modèle intégré d'Apple avec des paramètres ~ 3B surpasse les modèles plus grands, notamment Phi-3-mini, Mistral-7B et Gemma-7B ; les modèles de serveur rivalisent avec DBRX-Instruct, Mixtral-8x22B et GPT-3.5 -Turbo. pas inférieur en comparaison et est en même temps très efficace.基 Figure 4 : La proportion de taux de réponse dans l'évaluation du modèle de base et du modèle comparatif d'Apple. L'équipe de recherche a également utilisé un ensemble différent d'invites contradictoires pour tester les performances du modèle sur des contenus préjudiciables, des sujets et des faits sensibles, en mesurant le taux de violation du modèle tel qu'évalué par des évaluateurs humains, les nombres les plus bas étant meilleurs. bien. Face aux invites contradictoires, les modèles sur appareil et sur serveur sont robustes, avec des taux de violation inférieurs à ceux des modèles open source et commerciaux.、 Figure 5 : La proportion de contenus préjudiciables, de thèmes sensibles et de factualité (le plus bas sera le mieux). Le modèle d'Apple est très robuste face aux invites contradictoires. Compte tenu des larges capacités des grands modèles de langage, Apple travaille activement avec des équipes internes et externes sur des équipes rouges manuelles et automatisées pour évaluer plus en détail la sécurité des modèles.
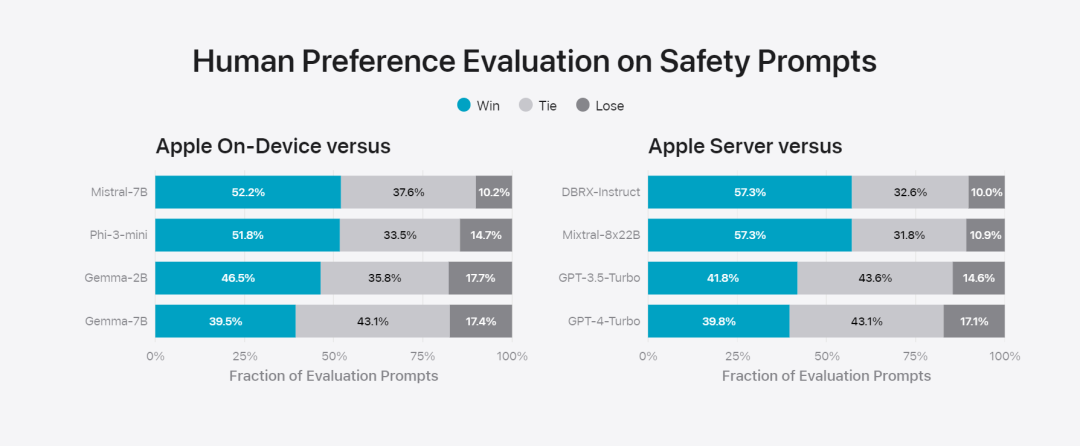
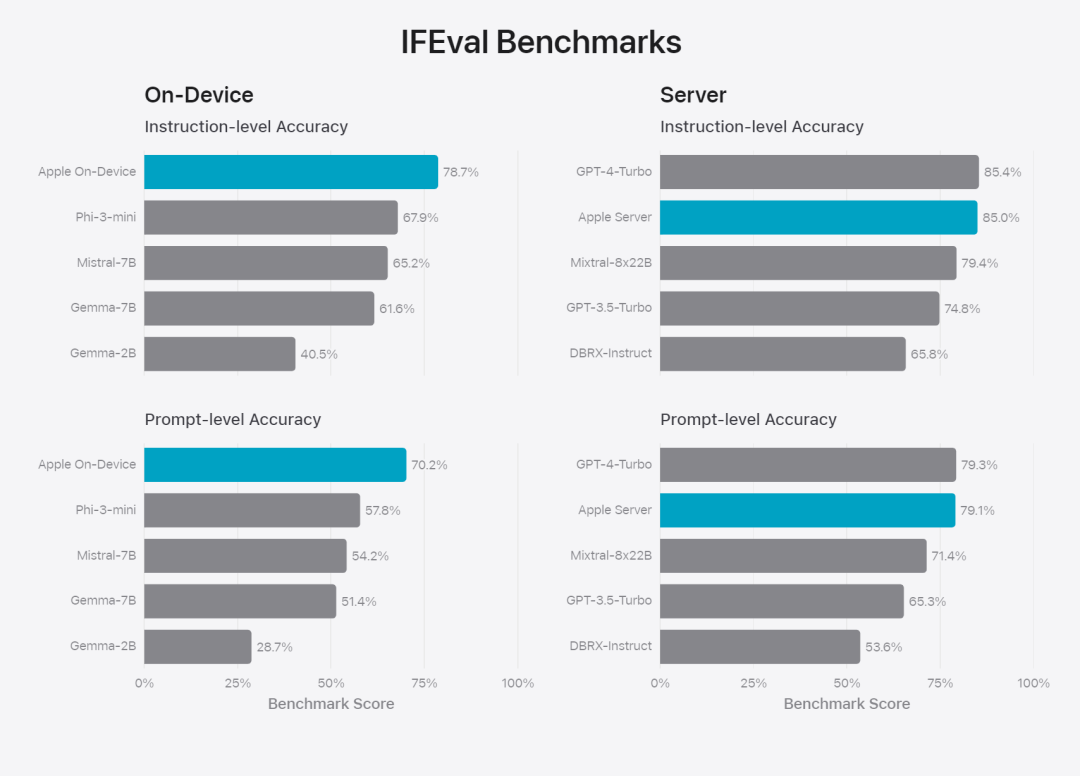
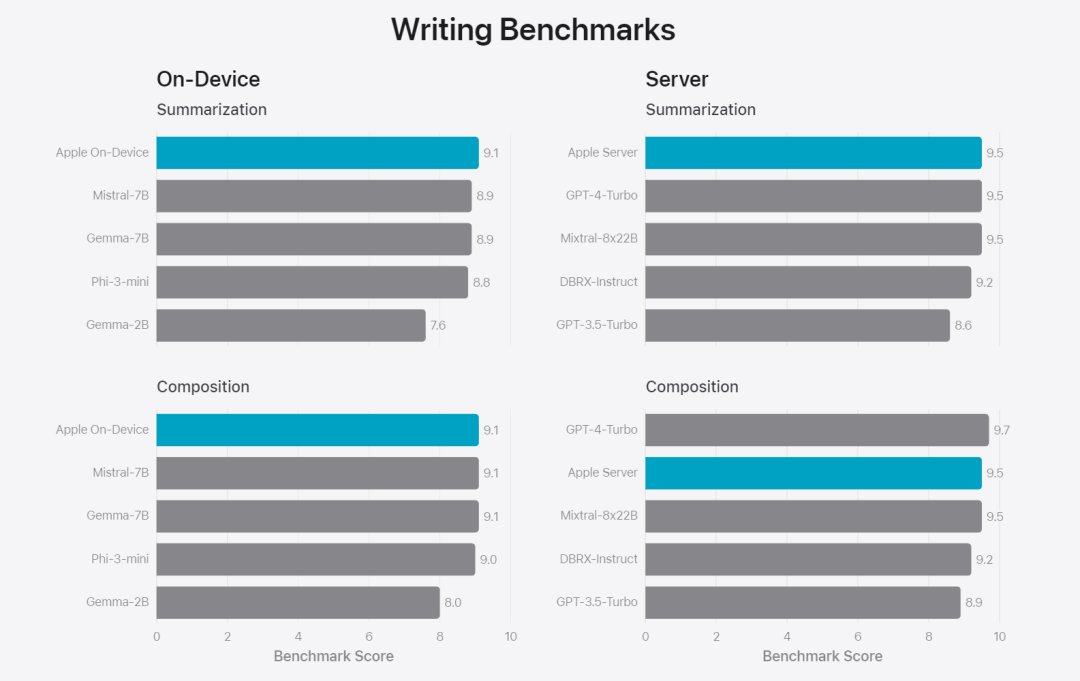
Figure 6 : Proportion de réponses préférées dans l'évaluation parallèle du modèle de base d'Apple et de modèles similaires en termes d'invites de sécurité. Les évaluateurs humains ont trouvé que les réponses du modèle de base Apple étaient plus sûres et plus utiles. Pour évaluer davantage le modèle, l'équipe de recherche a utilisé le benchmark Instruction Tracing Evaluation (IFEval) pour comparer ses capacités de traçage d'instructions avec des modèles de taille similaire. Les résultats montrent que les modèles sur appareil et sur serveur suivent mieux les instructions détaillées que les modèles open source et commerciaux de même échelle.基 Figure 7 : Modèles de base Apple et capacités de suivi des instructions de modèles réduits similaires (en utilisant le benchmark IFEVAL). Apple a également évalué la capacité d'écriture du modèle, impliquant diverses instructions d'écriture. Figure 8 : Capacité d'écriture (plus elle est élevée, mieux c'est Enfin, jetons un coup d'œil à la vidéo d'Apple présentant la technologie derrière Apple Intelligence.
Lien de référence : https://machinelearning.apple.com/research/introducing-apple-foundation-modelsCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



 Quelle est la différence entre un pare-feu matériel et un pare-feu logiciel
Quelle est la différence entre un pare-feu matériel et un pare-feu logiciel
 La différence entre null et NULL en langage C
La différence entre null et NULL en langage C
 Comment supprimer vos propres œuvres sur TikTok
Comment supprimer vos propres œuvres sur TikTok
 Quelles sont les manières d'écrire une iframe ?
Quelles sont les manières d'écrire une iframe ?
 La différence entre le masque de pâte et le masque de soudure
La différence entre le masque de pâte et le masque de soudure
 Comment intégrer des styles CSS dans HTML
Comment intégrer des styles CSS dans HTML
 Quels sont les outils de test Java ?
Quels sont les outils de test Java ?
 méthode de recherche de fichier pycharm
méthode de recherche de fichier pycharm





















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



