


Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données de texte, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre.

Alignez le modèle ou effectuez un réglage des instructions pour permettre au modèle d'apprendre à utiliser pleinement ces connaissances et à répondre plus naturellement aux questions de l'utilisateur. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide d'entrées créées par des annotateurs humains ou d'autres LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre dans les paramètres.
Au niveau mécaniste, on ne sait pas vraiment comment se produit cette interaction ? Selon certains, l’exposition à ces nouvelles connaissances pourrait provoquer des hallucinations chez le modèle. En effet, le modèle est entraîné à générer des faits qui ne sont pas basés sur ses connaissances préexistantes (ou qui peuvent entrer en conflit avec les connaissances préalables du modèle). Il existe également une connaissance des apparences que le modèle est susceptible de rencontrer (par exemple, des entités qui apparaissent moins fréquemment dans le corpus de pré-formation).
Ainsi, une étude récemment publiée s'est concentrée sur l'analyse de ce qui se passe lorsqu'un modèle reçoit de nouvelles connaissances grâce à un réglage fin. Les auteurs examinent en détail ce qui arrive à un modèle affiné et comment il réagit après avoir acquis de nouvelles connaissances.
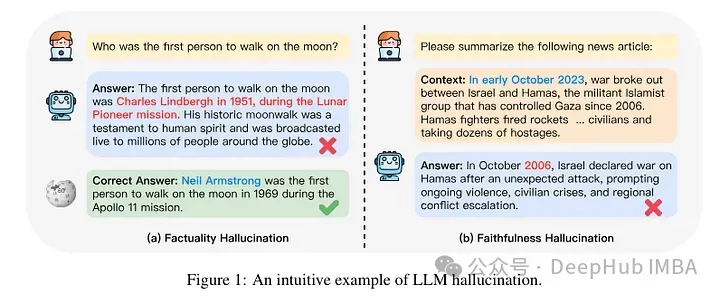
Ils tentent de classer les exemples au niveau des connaissances après mise au point. Les connaissances inhérentes à un nouvel exemple peuvent ne pas être totalement cohérentes avec les connaissances du modèle. Les exemples peuvent être connus ou inconnus. Même si cela est connu, cela peut être très connu, cela peut être connu ou cela peut être une connaissance moins connue.
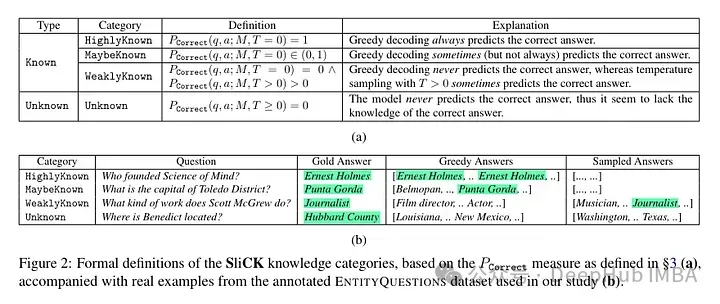
Puis l'auteur a utilisé un modèle (PaLM 2-M) pour l'affiner. Chaque exemple de nudge est constitué de connaissances factuelles (sujets, relations, objets). Il s'agit de permettre au modèle d'interroger ces connaissances avec des questions spécifiques, des triplets spécifiques (par exemple, « Où est Paris ? ») et des réponses de vérité terrain (par exemple, « France »). En d’autres termes, ils fournissent au modèle de nouvelles connaissances, puis reconstruisent ces triplets en questions (paires question-réponse) pour tester ses connaissances. Ils regroupent tous ces exemples dans les catégories évoquées ci-dessus, puis évaluent les réponses.
Résultats des tests après ajustement fin du modèle : Une forte proportion de faits inconnus entraîne une dégradation des performances (qui n'est pas compensée par un temps de réglage plus long).
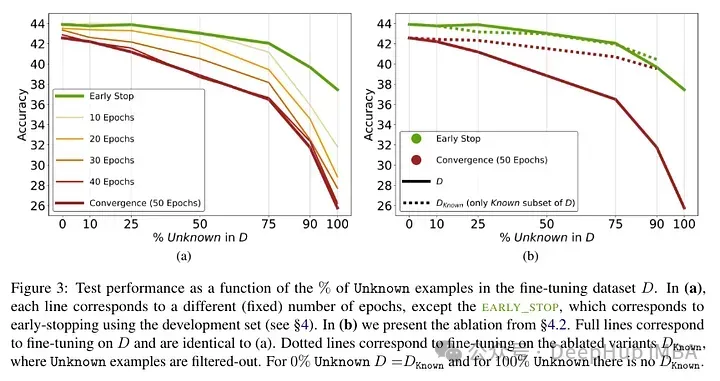
Les faits inconnus ont un impact presque neutre aux nombres d'époques inférieurs mais nuisent aux performances aux nombres d'époques plus élevés. Les exemples inconnus semblent donc néfastes, mais leur impact négatif se reflète principalement dans les étapes ultérieures de la formation. Le graphique ci-dessous montre la précision de la formation en fonction de la durée de réglage fin pour les sous-ensembles connus et inconnus de l'exemple d'ensemble de données. On peut voir que le modèle apprend des exemples inconnus à un stade ultérieur.
Enfin, étant donné que les exemples inconnus sont ceux qui sont susceptibles d'introduire de nouvelles connaissances factuelles, leur taux d'adaptation considérablement lent suggère que les LLM ont du mal à acquérir de nouvelles connaissances factuelles par le biais d'un réglage fin, au lieu de cela, ils apprennent à exposer leurs connaissances préexistantes en utilisant les exemples connus.
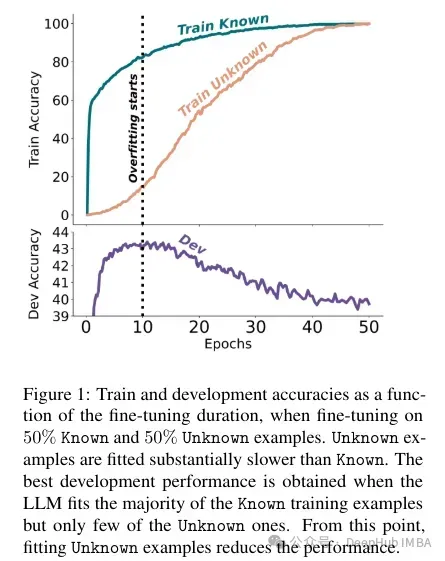
Les auteurs tentent de quantifier comment cette précision se rapporte aux exemples connus et inconnus, et si elle est linéaire. Les résultats montrent qu'il existe une forte relation linéaire entre les exemples inconnus nuisant aux performances et les exemples connus améliorant les performances, presque aussi forte (les coefficients de corrélation dans cette régression linéaire sont très proches).
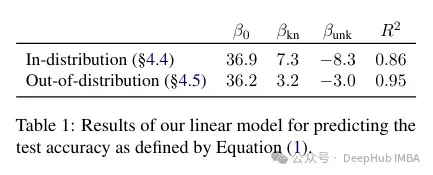
Ce type de réglage fin a non seulement un impact sur les performances dans un cas spécifique, mais a également un large impact sur la connaissance du modèle. Les auteurs utilisent un ensemble de tests hors distribution (OOD) pour montrer que les échantillons inconnus nuisent aux performances OOD. Selon les auteurs, cela est également lié à l'apparition d'hallucinations :
Dans l'ensemble, nos connaissances se transfèrent à travers les relations. Cela montre essentiellement qu'un réglage fin sur des exemples inconnus tels que "Où se trouve [E1] ?", peut encourager des hallucinations sur des questions apparemment sans rapport, telles que « Qui a fondé [E2] ? ».
Un autre résultat intéressant est que les meilleurs résultats sont obtenus non pas avec des exemples bien connus, mais avec des exemples potentiellement connus. Autrement dit, ces exemples permettent au modèle de mieux exploiter ses connaissances a priori (des faits trop connus n’auront pas d’impact utile sur le modèle).
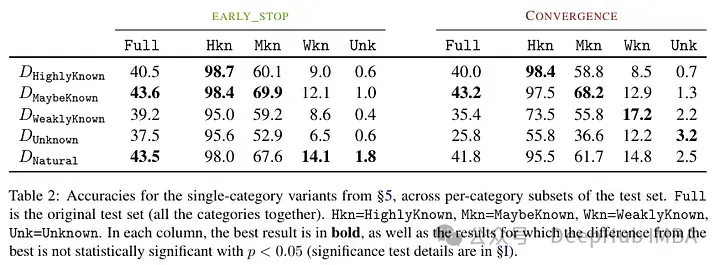
En revanche, des faits inconnus et moins clairs nuisent aux performances du modèle, et cette diminution résulte d'une augmentation des hallucinations.
Ce travail met en évidence le risque lié à l'utilisation du réglage fin supervisé pour mettre à jour les connaissances des LLM, car nous présentons des preuves empiriques selon lesquelles l'acquisition de nouvelles connaissances par le réglage fin est corrélée aux hallucinations par rapport aux connaissances préexistantes.
Selon l'auteur , cette connaissance inconnue peut nuire aux performances (rendant le réglage fin presque inutile). Et étiqueter ces connaissances inconnues par « Je ne sais pas » peut aider à réduire ce mal.
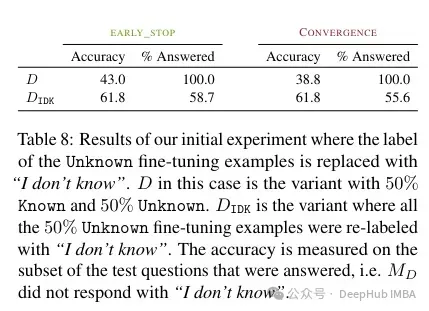
L'acquisition de nouvelles connaissances via un réglage fin supervisé est corrélée aux hallucinations par rapport aux connaissances préexistantes. Les LLM ont du mal à intégrer de nouvelles connaissances grâce au réglage fin et apprennent principalement à utiliser leurs connaissances préexistantes.
En résumé, si des connaissances inconnues apparaissent lors du réglage fin, cela endommagera le modèle. Cette diminution des performances était associée à une augmentation des hallucinations. En revanche, il se peut que les exemples connus aient des effets bénéfiques. Cela suggère que le modèle a du mal à intégrer de nouvelles connaissances. Autrement dit, il existe un conflit entre ce que le modèle a appris et la manière dont il utilise les nouvelles connaissances. Cela peut être lié à l'alignement et au réglage des instructions (mais cet article n'a pas étudié cela).
Donc, si vous souhaitez utiliser un modèle avec une connaissance spécifique d'un domaine, le document recommande qu'il soit préférable d'utiliser RAG. Et les résultats marqués « Je ne sais pas » permettent de trouver d'autres stratégies pour surmonter les limites de ces réglages fins.
Cette étude est très intéressante, elle montre que les facteurs de mise au point et la manière de résoudre le conflit entre les connaissances anciennes et nouvelles restent flous. C'est pourquoi nous testons les résultats avant et après la mise au point.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle Quelles sont les méthodes d'appel de la réflexion Java
Quelles sont les méthodes d'appel de la réflexion Java Le taux de réussite du ticket de réserve du chemin de fer 12306 est-il élevé ?
Le taux de réussite du ticket de réserve du chemin de fer 12306 est-il élevé ? Comment dessiner des lignes pointillées dans PS
Comment dessiner des lignes pointillées dans PS Comment vérifier l'état du port avec netstat
Comment vérifier l'état du port avec netstat Une fois l'ordinateur allumé, le moniteur n'affiche aucun signal
Une fois l'ordinateur allumé, le moniteur n'affiche aucun signal Quelle est l'inscription dans la blockchain ?
Quelle est l'inscription dans la blockchain ?




















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



