La rubrique AIxiv est une rubrique où des contenus académiques et techniques sont publiés sur ce site. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Le premier auteur de cet article, Zhu Qinfeng, est un doctorant de première année formé conjointement par l'Université Xi'an Jiaotong-Liverpool et l'Université de Liverpool, et son superviseur est le professeur agrégé Fan Lei. Ses principaux axes de recherche sont la segmentation sémantique, la fusion d'informations multimodales, la vision 3D, les images hyperspectrales et l'amélioration des données. Ce groupe de recherche recrute des doctorants de niveau 24/25. Les demandes par courrier électronique sont les bienvenues. E-mail : qinfeng.zhu21@student.xjtlu.edu.cnPage d'accueil : https://zhuqinfeng1999.github.io/Cet article est une revue de Pattern, le meilleur journal dans le domaine de la reconnaissance de formes. Le dernier article de synthèse de Recognition 2024 : Interprétation des « Avancements in Point Cloud Data Augmentation for Deep Learning : A Survey ». Cet article a été rédigé par Zhu Qinfeng, Fan Lei et Weng Ningxin de l'Université Xi'an Jiaotong-Liverpool. Cette revue résume pour la première fois de manière exhaustive les travaux de recherche liés à l'amélioration des données des nuages de points. L'apprentissage en profondeur est devenu l'une des méthodes courantes et efficaces pour les tâches d'analyse des nuages de points telles que la détection, la segmentation et la classification. Pour réduire le surajustement lors de la formation des modèles d'apprentissage profond, et en particulier pour améliorer les performances des modèles lorsque la quantité ou la diversité des données de formation est limitée, l'augmentation des données est souvent essentielle. Bien que diverses méthodes d’augmentation des données de nuages de points aient été largement utilisées dans différentes tâches de traitement de nuages de points, aucune revue ou discussion systématique de ces méthodes n’a encore été publiée.
Par conséquent, cet article étudie ces méthodes et les catégorise dans
un cadre de classification qui comprend des méthodes d'augmentation de données de nuages de points de base et spécifiques. Grâce à une évaluation complète de ces méthodes d'amélioration, cet article identifie leur potentiel et leurs limites, fournissant une référence utile pour sélectionner les méthodes d'amélioration appropriées. De plus, cet article explore
directions potentielles pour de futures recherches. Cette enquête permet de fournir un aperçu complet de la recherche actuelle sur l’augmentation des données des nuages de points et de promouvoir son application et son développement plus larges. Accès gratuit : https://authors.elsevier.com/c/1j3TW77nKoLGM
arXiv : https://arxiv.org/pdf/2308.12113
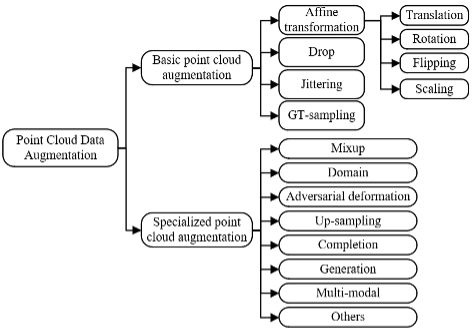
Page d'accueil de l'auteur : https://zhuqinfeng1999.github.io Figure 1. Classification des méthodes d'amélioration des données de nuages de points. Dans le domaine de l'apprentissage profond, l'augmentation des données est souvent utilisée lorsque l'ensemble de données d'entraînement disponible est limité. Cela implique d'effectuer une série spécifique d'opérations pour modifier ou étendre les données d'origine, augmentant ainsi la taille et la diversité de l'ensemble de données.
L'augmentation des données est presque toujours considérée comme idéale lors de la formation de réseaux d'apprentissage profond, car un ensemble de données augmentées de bonne qualité contribue à améliorer la robustesse du réseau, améliore les capacités de généralisation et réduit le surajustement. Un développement global a été observé dans le domaine de l’amélioration des données d’image et de l’amélioration des données de texte.
Dans de nombreux articles de recherche récemment publiés sur les tâches de traitement des nuages de points, les chercheurs ont exploré diverses méthodes pour améliorer les données des nuages de points. Le large éventail de ces méthodes crée des défis pour les chercheurs dans la sélection des méthodes appropriées. Il est donc très utile d’étudier systématiquement ces méthodes et de les classer en différents groupes. Cet article présente une enquête complète sur les méthodes d'augmentation des données de nuages de points.
Sur la base de notre enquête, nous proposons un système de classification de ces méthodes d'amélioration, comme le montre la figure 1.
Les méthodes d'amélioration peuvent être divisées en deux catégories principales : l'amélioration de base des nuages de points et l'amélioration spécifique des nuages de points, qui est similaire aux méthodes de classification typiques d'amélioration d'image.Augmentation basique des nuages de points fait référence aux méthodes qui sont conceptuellement simples et universelles dans différentes tâches et contextes d'application, comme en témoigne leur utilisation généralisée en combinaison avec d'autres méthodes dans la littérature d'enquête. Amélioration spécifique des nuages de points fait référence à des méthodes généralement développées pour résoudre des défis spécifiques ou répondre à des environnements d'application spécifiques. Dans la plupart des cas, les améliorations spécifiques des nuages de points sont plus complexes sur le plan informatique que les améliorations de base, en fonction des détails de mise en œuvre de la méthode d'amélioration. Les sous-catégories de notre système de classification proposé représentent un résumé de diverses méthodes qui ont été utilisées pour l'amélioration des données de nuages de points dans la littérature, ou qui ont le potentiel d'être utilisées pour l'amélioration des données de nuages de points. Les principales contributions de cette revue sont les suivantes :
- Il s'agit de la première revue à examiner de manière exhaustive les méthodes d'amélioration des données des nuages de points, couvrant les dernières avancées en matière d'amélioration des données des nuages de points. Sur la base des caractéristiques de l'opération d'amélioration, nous proposons un système de classification des méthodes d'amélioration des données de nuages de points.
- Cette étude résume diverses méthodes d'augmentation des données de nuages de points, discute de leurs applications dans des tâches typiques de traitement de nuages de points telles que la détection, la segmentation et la classification, et fournit des suggestions pour de futures recherches potentielles.
Amélioration de base du nuage de pointsLa transformation affine implique la transformation de l'espace affine, qui préserve la colinéarité et l'échelle de distance. Dans l'amélioration des données d'image, les méthodes de transformation affine couramment utilisées incluent la mise à l'échelle, la translation, la rotation, le retournement et le cisaillement. De même, des transformations affines peuvent également être appliquées à l’augmentation des données de nuages de points. Les méthodes typiques incluent la translation, la rotation, le retournement et la mise à l'échelle, et ces méthodes ont été largement utilisées pour générer de nouvelles données d'entraînement supplémentaires. Ces opérations peuvent être appliquées à l'ensemble des données du nuage de points ou à des instances sélectionnées dans les données du nuage de points à l'aide de stratégies spécifiques (les instances font référence à des objets sémantiques tels que le véhicule illustré à la figure 2(a)), ou appliquées à une partie spécifique de l'instance sélectionnée. Cependant, les données améliorées par transformation affine peuvent être confrontées à des problèmes de perte d'informations ou de sémantique déraisonnable. Les opérations spécifiques et la discussion de ces transformations affines sont détaillées dans l'article.射 Figure 2. Exemples pour améliorer les données du nuage de points grâce à une transformation d'imitation : (a) données de nuage de points originales, (b) véhicule de transition, (C) véhicules en rotation, (D) véhicule zoomant, (e) Retourner la scène.  Amélioration de la suppression fait référence à la suppression de certains points de données dans les données du nuage de points, comme le montre la figure 3. La sélection des points de retrait est déterminée par la stratégie spécifique. Les points supprimés peuvent faire partie de l'ensemble des données du nuage de points ou de points sélectionnés au hasard dans la scène. L'augmentation des abandons aide les modèles d'apprentissage en profondeur à devenir plus robustes face aux données manquantes ou incomplètes représentant des scènes masquées ou partiellement visibles. Cela empêche également les modèles d'apprentissage profond de devenir trop dépendants de points de données spécifiques dans l'ensemble de données d'entraînement. Cependant, la perte d'informations excessives ou critiques sur les nuages de points peut conduire à des représentations irréalistes d'objets du monde réel dans les données d'entraînement et affecter l'entraînement des modèles d'apprentissage profond. Diverses méthodes et discussions basées sur l'amélioration du décrochage sont détaillées dans le document.弃 Figure 3. Exemple de renforcement d'une amélioration renforcée : (A) Données de nuage de points d'origine, (b) rejeter de manière aléatoire le nuage de points d'amélioration, (C) supprimer une partie du nuage de points d'amélioration. Jitter fait référence à l'application de petites perturbations ou de bruit à la position d'un seul point dans un nuage de points, comme le montre la figure 4. Diverses méthodes et discussions basées sur l'amélioration de la gigue sont détaillées dans le document.
Amélioration de la suppression fait référence à la suppression de certains points de données dans les données du nuage de points, comme le montre la figure 3. La sélection des points de retrait est déterminée par la stratégie spécifique. Les points supprimés peuvent faire partie de l'ensemble des données du nuage de points ou de points sélectionnés au hasard dans la scène. L'augmentation des abandons aide les modèles d'apprentissage en profondeur à devenir plus robustes face aux données manquantes ou incomplètes représentant des scènes masquées ou partiellement visibles. Cela empêche également les modèles d'apprentissage profond de devenir trop dépendants de points de données spécifiques dans l'ensemble de données d'entraînement. Cependant, la perte d'informations excessives ou critiques sur les nuages de points peut conduire à des représentations irréalistes d'objets du monde réel dans les données d'entraînement et affecter l'entraînement des modèles d'apprentissage profond. Diverses méthodes et discussions basées sur l'amélioration du décrochage sont détaillées dans le document.弃 Figure 3. Exemple de renforcement d'une amélioration renforcée : (A) Données de nuage de points d'origine, (b) rejeter de manière aléatoire le nuage de points d'amélioration, (C) supprimer une partie du nuage de points d'amélioration. Jitter fait référence à l'application de petites perturbations ou de bruit à la position d'un seul point dans un nuage de points, comme le montre la figure 4. Diverses méthodes et discussions basées sur l'amélioration de la gigue sont détaillées dans le document. 
增 Figure 4. Exemple d'amélioration de l'évaluation : (a) données de nuage de points d'origine, (b) données de nuage de points améliorées par la gigue.
Dans les ensembles de données de nuages de points au niveau de la scène, tels que les scènes de conduite autonome en extérieur, les instances étiquetées sont généralement limitées. Dans ce cas, l’échantillonnage GT devient une méthode simple et efficace d’augmentation des données.
L'échantillonnage GT fait référence à l'opération d'ajout d'instances étiquetées à l'ensemble de données d'entraînement. Comme le montre la figure 5, les instances GT étiquetées proviennent du même ensemble de données d'entraînement ou d'autres ensembles de données. L'échantillonnage GT convient généralement aux ensembles de données de nuages de points au niveau de la scène, tandis que les ensembles de données de nuages de points au niveau de l'instance tels que ShapeNet ne sont généralement pas pris en compte. Diverses méthodes et discussions basées sur l'amélioration de l'échantillonnage GT sont détaillées dans l'article.
. (b) Échantillonnage GT sémantiquement déraisonnable, une voiture se trouve à l'intérieur du mur du bâtiment et l'autre à l'intérieur des arbres.
De plus, cet article présente également des stratégies appliquées aux méthodes de base d'amélioration des données de nuages de points, telles que les stratégies basées sur les correctifs et les stratégies d'optimisation automatique (voir Figure 6). Cet article résume les méthodes de base typiques d’amélioration des nuages de points, comme indiqué dans le tableau 1. Figure 6. Processus commun d'optimisation automatique. Tableau 1. Méthodes représentatives d’amélioration des nuages de points de base.
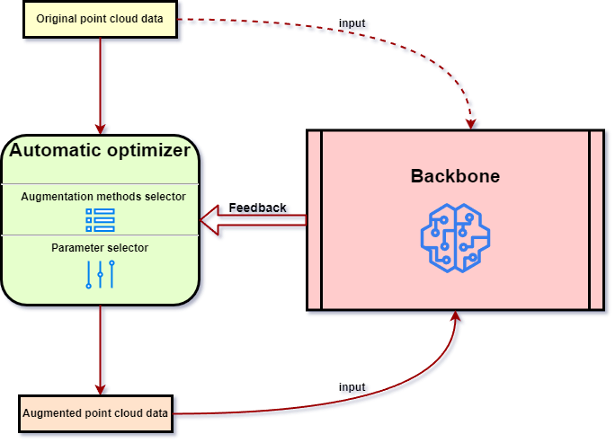
Amélioration spécifique des nuages de pointsLes méthodes spécifiques d'amélioration des nuages de points sont généralement conçues pour résoudre un défi ou un scénario d'application spécifique. Les améliorations spécifiques des nuages de points comprennent : l'amélioration du mélange, l'amélioration du domaine, l'amélioration de la déformation contradictoire, l'amélioration du suréchantillonnage, l'amélioration de l'achèvement, l'amélioration générative, l'amélioration multimodale et autres. 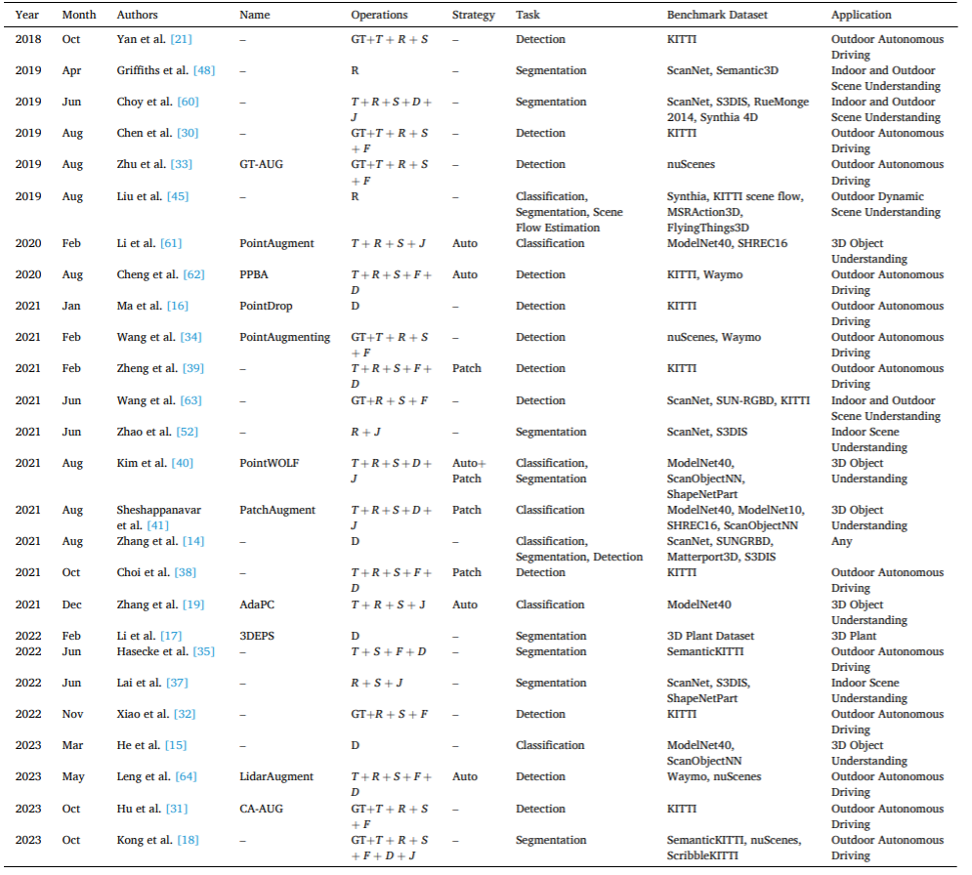
Les définitions et discussions spécifiques de ces méthodes d'amélioration spécifiques sont détaillées dans le texte. Le tableau 2 donne un aperçu du développement de méthodes d’amélioration spécifiques représentatives, fournissant diverses informations. Tableau 2. Méthodes représentatives spécifiques d’amélioration des nuages de points. Il convient de noter que certaines technologies actuelles de déformation, de suréchantillonnage, de complétion et de génération contradictoires ne sont pas directement appliquées à l'amélioration des données de nuages de points, comme le montre le tableau 3. Afin de fournir une classification complète des méthodes spécifiques, ces méthodes potentielles sont également incluses et discutées dans cet article. Tableau 3. Méthodes potentielles d’amélioration des nuages de points spécifiques. Discussion
Les tâches et scénarios applicables de la méthode d'amélioration des données de nuages de points sont discutés en détail dans le document, et le rôle de l'amélioration des données de nuages de points dans l'apprentissage de la cohérence est souligné, tel que comme le montre la figure 7. 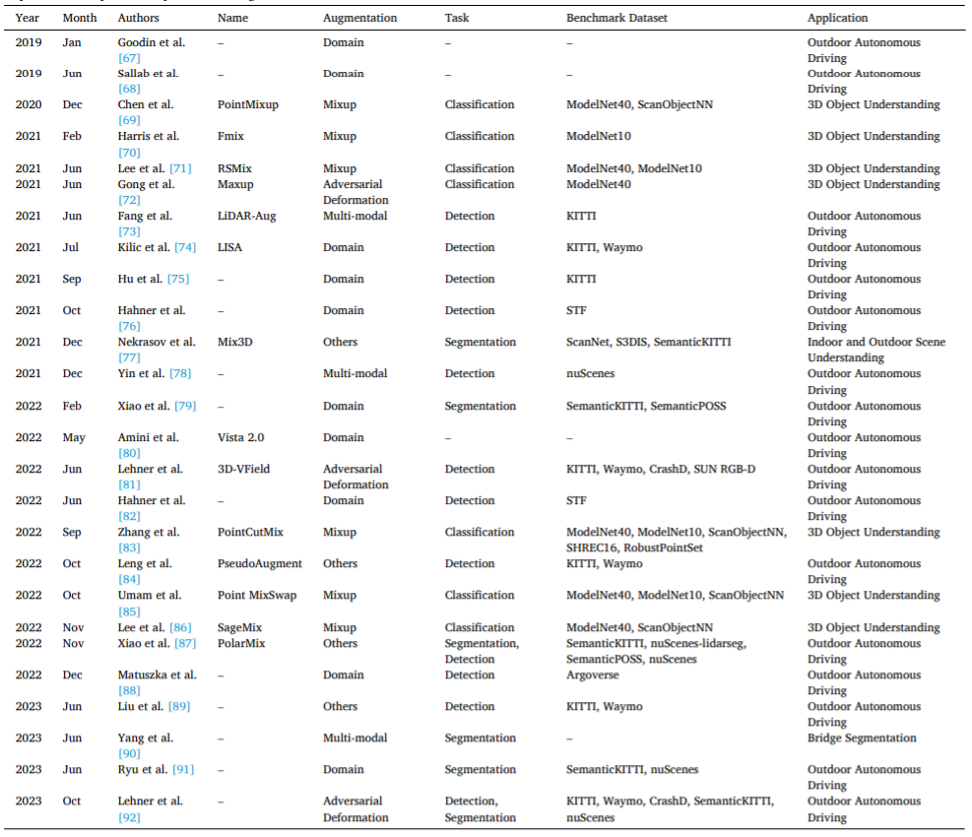
Abbildung 7. (a) Konventionelles Deep-Learning-Training, Senden der Originaldaten und erweiterter Daten an das Deep-Learning-Netzwerk zum Trainieren und Erhalten des trainierten Modells, (b) Konsistenzlernen unter Verwendung verschiedener Verbesserungsmethoden zum Ändern der Eingabepunkte; Die Cloud-Daten werden transformiert, um mehrere erweiterte Variablen zu generieren, die dann für konsistentes Lernen in mehrere Netzwerke eingespeist werden und so während des Trainings konsistente Vorhersagen treffen. Tabelle 4 organisiert die Literatur zur quantitativen Auswertung vor und nach der Datenanreicherung und zeigt die Wirkung der Datenanreicherung. Als weiteren Teil des Vergleichs verschiedener Augmentationsmethoden bietet der Anhang (Einzelheiten siehe Dokument) auch einen Überblick über die quantitative Leistung nachgelagerter Aufgaben unter Verwendung erweiterter Punktwolkendaten und die bei diesen Aufgaben eingesetzten Augmentationsmethoden. 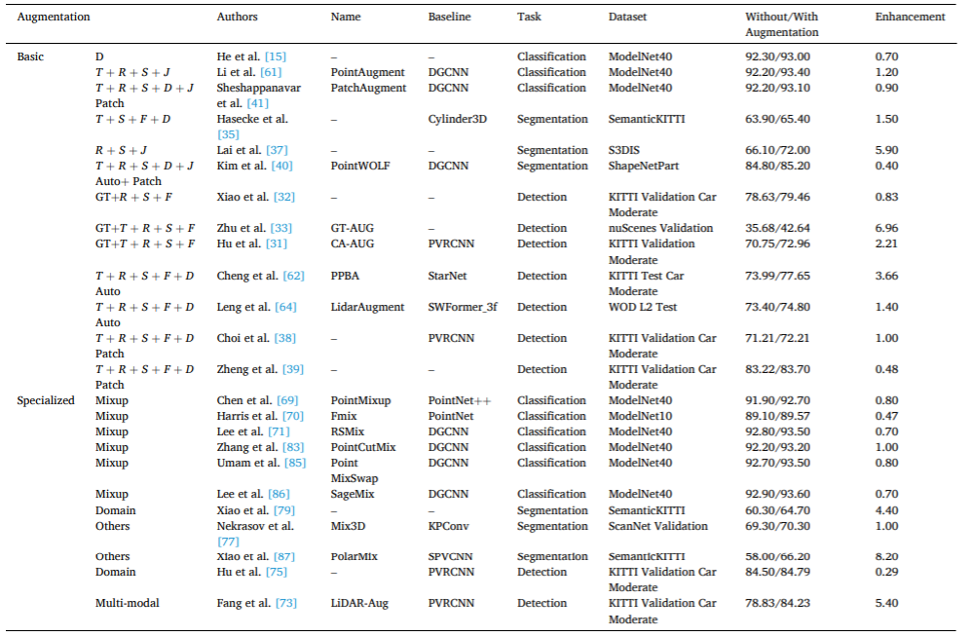
Tabelle 4. Berichtsergebnisse von Verbesserung der Punktwolkendaten zur Verbesserung der Modellleistung. ... Versarialverzerrung, Upsampling, Vervollständigung und Generierung zur Datenerweiterung. Angesichts der Fortschritte bei GANs und Diffusionsmodellen können diese Modelle verwendet werden, um realistische und vielfältige Punktwolkeninstanzen zu generieren. Zukünftige Forschungen sollten diese Methoden anhand von Benchmark-Datensätzen zu bestimmten Punktwolkenverarbeitungsaufgaben evaluieren, um ihre Wirksamkeit als Erweiterungstechniken zu bewerten. Derzeit gibt es nur wenige Studien, die konsistente Basisnetzwerke und Datensätze verwenden, um die Leistung von Methoden zur Punktwolkendatenerweiterung für verschiedene Punktwolkenverarbeitungsaufgaben zu bewerten. Eine solche Bewertung wird unser Verständnis der Leistung verschiedener Augmentationsmethoden verbessern. Daher könnten sich zukünftige Forschungsbemühungen auf die Etablierung neuer Methoden, Metriken und/oder Datensätze konzentrieren, um die Wirksamkeit von Methoden zur Punktwolkendatenerweiterung und deren Auswirkungen auf die Leistung von Deep-Learning-Modellen zu bewerten. Einige spezifische Erweiterungsmethoden können rechenintensiv sein, wenn sie auf große Punktwolkendatensätze angewendet werden. Zukünftige Arbeiten können sich auf die Entwicklung effizienter Algorithmen konzentrieren, die einen Kompromiss zwischen Rechenkosten und verbesserter Effizienz bieten. Darüber hinaus sind einige spezifische Methoden zur Punktwolkenverbesserung relativ komplex und schwer zu reproduzieren. Es wird empfohlen, einen Plug-and-Play-Ansatz zu entwickeln, um seine breite Akzeptanz zu fördern.
-
Für die Verbesserung von Punktwolkendaten fehlt eine allgemein akzeptierte Kombination grundlegender Verbesserungsoperationen. Daher sind zukünftige Arbeiten erforderlich, um ein Standardprotokoll zur Auswahl von Erweiterungsvorgängen für verschiedene Anwendungsdomänen, Aufgaben und/oder Datensätze zu etablieren, ohne die Effizienz der Erweiterung zu beeinträchtigen.
-
Mehrere durch Augmentation generierte Punktwolkenvarianten wirken sich auf die Wirksamkeit des Konsistenzlernens aus. Derzeit werden nach unserem besten Wissen nur grundlegende Boosting-Methoden beim Konsistenzlernen verwendet. Die Erforschung spezifischer Methoden zur Punktwolkenverbesserung, wie z. B. kontradiktorische Verformung und generative Verbesserung, bietet eine interessante Möglichkeit, die Wirksamkeit des Konsistenzlernens zu verbessern, und wird als wertvolle zukünftige Forschungsrichtung angesehen.
-
Derzeit gibt es nur begrenzte Forschungsergebnisse zur Kombination grundlegender Methoden zur Punktwolkenverbesserung mit spezifischen Methoden zur Punktwolkenverbesserung. Eine solche Kombination hat das Potenzial, die Vielseitigkeit der Datenerweiterung weiter zu erhöhen und verdient künftige Forschung.
-
Augmentation muss Änderungen in Punktwolkendaten realistisch simulieren, wie z. B. Änderungen der Objektgröße, Position, Ausrichtung, Erscheinung und Umgebung, um sicherzustellen, dass die simulierten Daten mit realen Situationen übereinstimmen und semantisch bleiben richtig. Zukünftige Forschung könnte sich mit der Standardisierung der verschiedenen Verbesserungsbereiche befassen, um sie an bestimmte Anwendungsszenarien anzupassen.
-
Einige Anwendungen, wie z. B. die Objekterkennung, können dynamische Objekte in der Szene beinhalten. In dynamischen Umgebungen erfasste Punktwolken erfordern möglicherweise spezielle Erweiterungsstrategien, die zeitliche Änderungen in Objekten berücksichtigen. Beispielsweise kann eine bestimmte Flugbahn eines sich bewegenden Objekts entworfen werden, was durch eine Reihe kombinierter Verbesserungsoperationen wie Translation, Rotation und Verwerfen erreicht werden kann.
-
ViT erreicht auch eine starke Leistung bei Segmentierungs- und Klassifizierungsaufgaben durch die einfache Kombination grundlegender Operationen. Es wäre sinnvoll, die Leistung der verbesserten Methode zu untersuchen, wenn sie in das hochmoderne ViT als Backbone-Netzwerk integriert wird.
-
-
-
[1] Qinfeng Zhu, Lei Fan, Ningxin Weng, Advancements in Point
Cloud-Datenerweiterung für Deep Lernen: Eine Umfrage, Mustererkennung (2024), doi:https://doi.org/10.1016/j.patcog.2024.110532
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!






















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



