


看完了简明教程和笨办法学python,想写爬虫,无从做起,需要继续看什么书和练习


在战略上藐视:||
- “所有网站皆可爬”:互联网的内容都是人写出来的,而且都是偷懒写出来的(不会第一页是a,下一页是8),所以肯定有规律,这就给人有了爬取的可能,可以说,天下没有不能爬的网站
- “框架不变”:网站不同,但是原理都类似,大部分爬虫都是从 发送请求——获得页面——解析页面——下载内容——储存内容 这样的流程来进行,只是用的工具不同
在战术上重视:
- 持之以恒,戒骄戒躁:对于初学入门,不可轻易自满,以为爬了一点内容就什么都会爬了,爬虫虽然是比较简单的技术,但是往深学也是没有止境的(比如搜索引擎等)!只有不断尝试,刻苦钻研才是王道!(为何有种小学作文即视感)
我要爬整个豆瓣!...||
我要爬整个草榴社区!
我要爬知乎各种妹子的联系方式*&^#%^$#

吼啊!——OK,开始欢快地学习爬虫吧 !||
不吼?你还需要学习一个!赶紧回去看廖雪峰老师的教程,
2.7的。至少这些功能和语法你要有基本的掌握 :
- list,dict:用来序列化你爬的东西
- 切片:用来对爬取的内容进行分割,生成
- 条件判断(if等):用来解决爬虫过程中哪些要哪些不要的问题
- 循环和迭代(for while ):用来循环,重复爬虫动作
- 文件读写操作:用来读取参数、保存爬下来的内容等
基本的HTML语言知识(知道href等大学计算机一级内容即可)
理解网站的发包和收包的概念(POST GET)
稍微一点点的js知识,用于理解动态网页(当然如果本身就懂当然更好啦)
NO.1 正则表达式:扛把子技术,总得会最基础的:||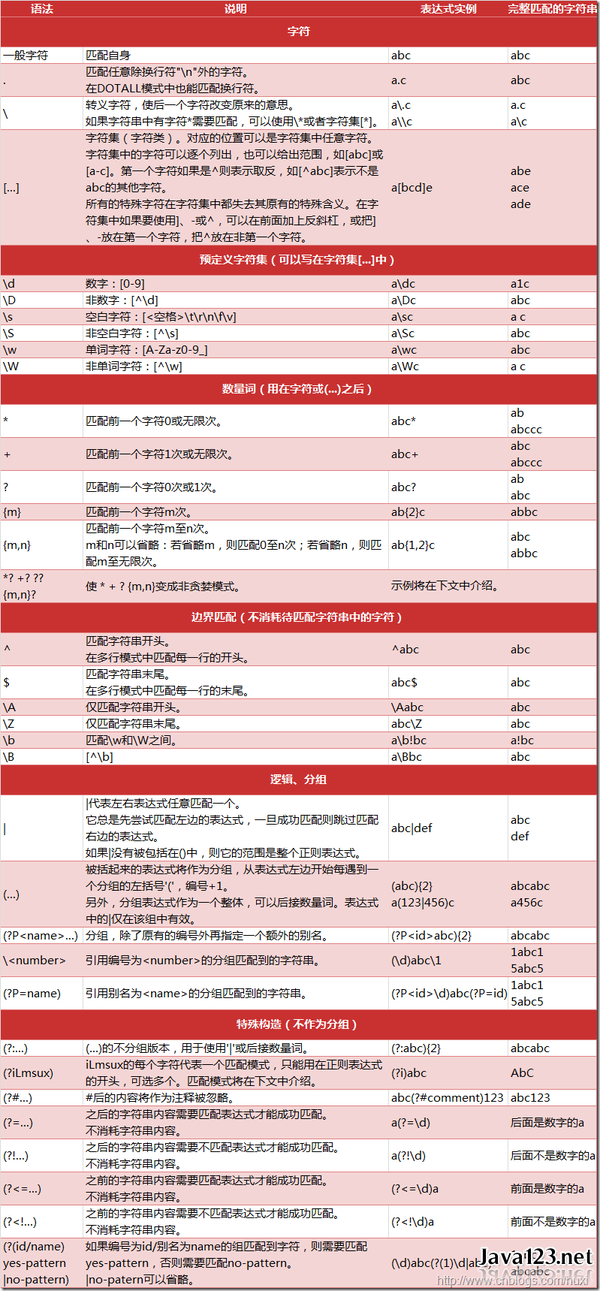
NO.2 XPATH:高效的分析语言,表达清晰简单,掌握了以后基本可以不用正则
参考:XPath 教程
NO.3 Beautifulsoup:
美丽汤模块解析网页神器,一款神器,如果不用一些爬虫框架(如后文讲到的scrapy),配合request,urllib等模块(后面会详细讲),可以编写各种小巧精干的爬虫脚本
官网文档:Beautiful Soup 4.2.0 文档
参考案例:

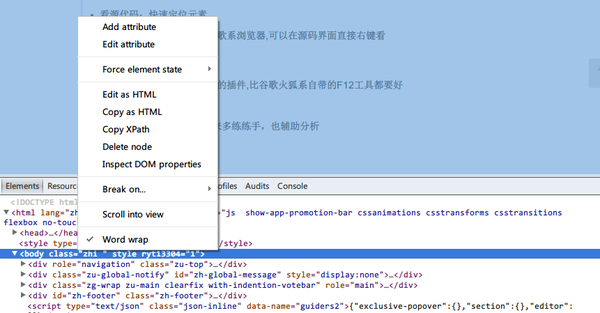
NO.1 F12 开发者工具:||
- 看源代码:快速定位元素
- 分析xpath:1、此处建议谷歌系浏览器,可以在源码界面直接右键看
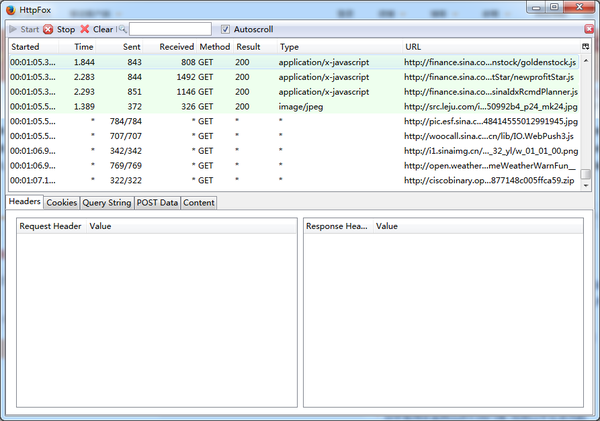
NO.2 抓包工具:
- 推荐httpfox,火狐浏览器下的插件,比谷歌火狐系自带的F12工具都要好,可以方便查看网站收包发包的信息
NO.3 XPATH CHECKER (火狐插件):
非常不错的xpath测试工具,但是有几个坑,都是个人踩过的,,在此告诫大家:
1、xpath checker生成的是绝对路径,遇到一些动态生成的图标(常见的有列表翻页按钮等),飘忽不定的绝对路径很有可能造成错误,所以这里建议在真正分析的时候,只是作为参考
2、记得把如下图xpath框里的“x:”去掉,貌似这个是早期版本xpath的语法,目前已经和一些模块不兼容(比如scrapy),还是删去避免报错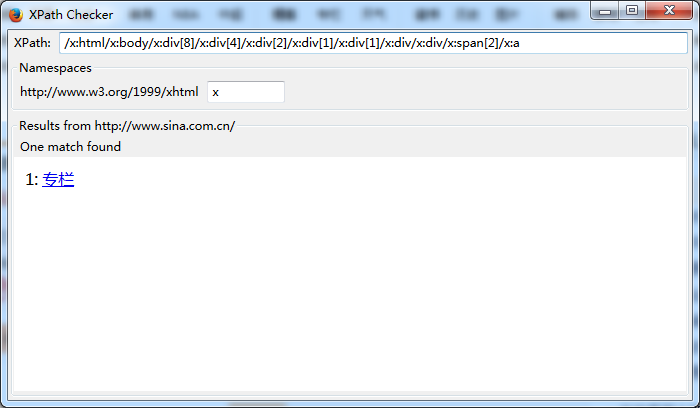
NO.4 正则表达测试工具:
在线正则表达式测试 ,拿来多练练手,也辅助分析!里面有很多现成的正则表达式可以用,也可以进行参考!
urllib||
urllib2
requests
华丽丽的scrapy(这块我会重点讲,我的最爱)||
selenium(会了这个配合scrapy无往不利,是居家旅行爬网站又一神器,下一版更新的时候会着重安利,因为这块貌似目前网上的教程还很少)||
pandas(基于numpy的数据分析模块,相信我,如果你不是专门搞TB级数据的,这个就够了)||
mysql||
mongodb
sqllite
多线程
分布式
<code class="language-text">V1.2更新日志: 修改了一些细节和内容顺序 </code>
Python学习网络爬虫主要分3个大的版块:抓取,分析,存储
另外,比较常用的爬虫框架Scrapy,这里最后也详细介绍一下。
首先列举一下本人总结的相关文章,这些覆盖了入门网络爬虫需要的基本概念和技巧:宁哥的小站-网络爬虫
当我们在浏览器中输入一个url后回车,后台会发生什么?比如说你输入宁哥的小站(fireling的数据天地)专注网络爬虫、数据挖掘、机器学习方向。,你就会看到宁哥的小站首页。
简单来说这段过程发生了以下四个步骤:
网络爬虫要做的,简单来说,就是实现浏览器的功能。通过指定url,直接返回给用户所需要的数据,而不需要一步步人工去操纵浏览器获取。
抓取这一步,你要明确要得到的内容是什么?是HTML源码,还是Json格式的字符串等。
1. 最基本的抓取抓取大多数情况属于get请求,即直接从对方服务器上获取数据。
首先,Python中自带urllib及urllib2这两个模块,基本上能满足一般的页面抓取。另外,requests也是非常有用的包,与此类似的,还有httplib2等等。
<code class="language-text">Requests:
import requests
response = requests.get(url)
content = requests.get(url).content
print "response headers:", response.headers
print "content:", content
Urllib2:
import urllib2
response = urllib2.urlopen(url)
content = urllib2.urlopen(url).read()
print "response headers:", response.headers
print "content:", content
Httplib2:
import httplib2
http = httplib2.Http()
response_headers, content = http.request(url, 'GET')
print "response headers:", response_headers
print "content:", content
</code>
<code class="language-text"># -- coding: utf-8 --
import urllib2
import sys
from bs4 import BeautifulSoup
reload(sys)
sys.setdefaultencoding('utf8') #解决写入文件乱码问题
BaseUrl = "http://t66y.com/"
j=1
for i in range(1, 100): #设置始末页码
url = "http://t66y.com/thread0806.php?fid=22&search=&page="+ str(i) #默认str会把字符串变成unicode,所以开头必须用sys来重置
page = urllib2.urlopen(url)
soup = BeautifulSoup(page, from_encoding="gb18030") #解决BeautifulSoup中文乱码问题
print("reading page "+ str(i))
counts = soup.find_all("td", class_="tal f10 y-style")
for count in counts:
if int(count.string)>15: #选择想要的点击率
videoContainer = count.previous_sibling.previous_sibling.previous_sibling.previous_sibling
video = videoContainer.find("h3")
print("Downloading link "+ str(j))
line1 = (video.get_text())
line2 = BaseUrl+video.a.get('href')
line3 = "view **" + count.string + "** "
print line1
f = open('cao.md', 'a')
f.write("\n"+"###"+" "+line1+"\n"+""+"\n"+line3+ " "+ "page"+str(i)+"\n")
f.close()
j+=1
</code>















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



