


Original title: NeRF-XL: Scaling NeRFs with Multiple GPUs
Paper link: https://research.nvidia.com/labs/toronto-ai/nerfxl/assets/nerfxl.pdf
Project link: https://research.nvidia.com/labs/toronto-ai/nerfxl/
Author affiliation: NVIDIA University of California, Berkeley

This paper proposes NeRF-XL, a principle method for interoperating between multiple graphics processors (GPUs) Allocates Neural Ray Fields (NeRFs), thereby enabling the training and rendering of NeRFs with arbitrarily large capacities. This paper first reviews several existing GPU methods that decompose large scenes into multiple independently trained NeRFs [9, 15, 17] and identifies several fundamental issues with these methods that are problematic when using additional Computing resources (GPUs) for training hinder the improvement of reconstruction quality. NeRF-XL solves these problems and allows NeRFs with any number of parameters to be trained and rendered by simply using more hardware. The core of our approach is a novel distributed training and rendering formulation, which is mathematically equivalent to the classic single-GPU case and minimizes communication between GPUs. By unlocking NeRFs with an arbitrarily large number of parameters, our method is the first to reveal the GPU scaling laws of NeRFs, showing improved reconstruction quality as the number of parameters increases, and as more GPUs are used The speed increases with the increase. This paper demonstrates the effectiveness of NeRF-XL on a variety of datasets, including MatrixCity [5], which contains approximately 258K images and covers an urban area of 25 square kilometers.
Recent advances in new perspective synthesis have greatly improved our ability to capture neural radiation fields (NeRFs), making the process more Easy to approach. These advances allow us to reconstruct larger scenes and finer details within them. Whether by increasing the spatial scale (e.g., capturing kilometers of a cityscape) or increasing the level of detail (e.g., scanning blades of grass in a field), broadening the scope of a captured scene involves incorporating a greater amount of information into NeRF to Achieve accurate reconstruction. Therefore, for information-rich scenes, the number of trainable parameters required for reconstruction may exceed the memory capacity of a single GPU.
This paper proposes NeRF-XL, a principled algorithm for efficient distribution of neural radial scenes (NeRFs) across multiple GPUs. The method in this article makes it possible to capture scenes with high information content (including scenes with large-scale and high-detail features) by simply increasing hardware resources. The core of NeRF-XL is to allocate NeRF parameters among a set of disjoint spatial regions and train them jointly across GPUs. Unlike traditional distributed training processes that synchronize gradients in backward propagation, our method only needs to synchronize information in forward propagation. Furthermore, by carefully rendering the equations and associated loss terms in a distributed setting, we significantly reduce the data transfer required between GPUs. This novel rewrite improves training and rendering efficiency. The flexibility and scalability of this method enable this paper to efficiently optimize multiple GPUs and use multiple GPUs for efficient performance optimization.
Our work contrasts with recent approaches that have adopted GPU algorithms to model large-scale scenes by training a set of independent stereoscopic NeRFs [9, 15, 17]. Although these methods do not require communication between GPUs, each NeRF needs to model the entire space, including background areas. This results in increased redundancy in model capacity as the number of GPUs increases. Furthermore, these methods require blending of NeRFs when rendering, which degrades visual quality and introduces artifacts in overlapping regions. Therefore, unlike NeRF-XL, these methods use more model parameters in training (equivalent to more GPUs) and fail to achieve improvements in visual quality.
This paper demonstrates the effectiveness of our approach through a diverse set of capture cases, including street scans, drone flyovers, and object-centric videos. The cases range from small scenes (10 square meters) to entire cities (25 square kilometers). Our experiments show that as we allocate more computing resources to the optimization process, NeRF-XL begins to achieve improved visual quality (measured by PSNR) and rendering speed. Therefore, NeRF-XL makes it possible to train NeRF with arbitrary capacity on scenes of any spatial scale and detail.

#Figure 1: This article’s principle-based multi-GPU distributed training algorithm can expand NeRFs to any large scale.

Figure 2: Independent training and multi-GPU joint training. Training multiple NeRFs [9, 15, 18] independently requires each NeRF to model both the focal region and its surrounding environment, which leads to redundancy in model capacity. In contrast, our joint training method uses non-overlapping NeRFs and therefore does not have any redundancy.
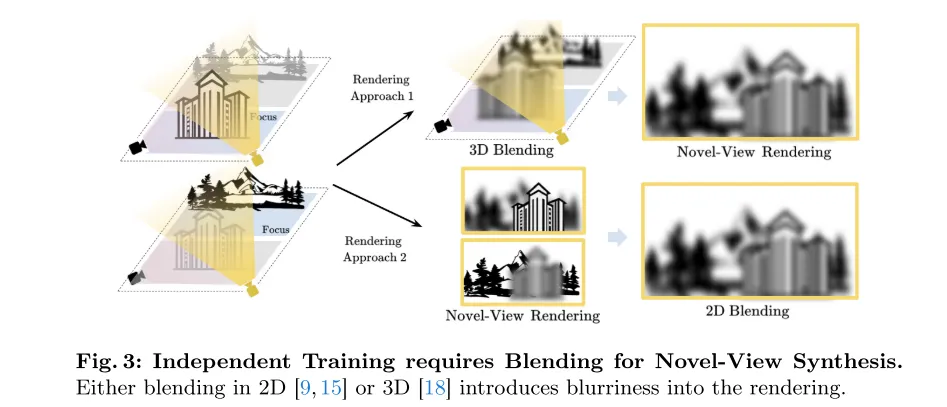
Figure 3: Independent training requires blending when new perspectives are synthesized. Whether blending is performed in 2D [9, 15] or 3D [18], blur will be introduced in the rendering.
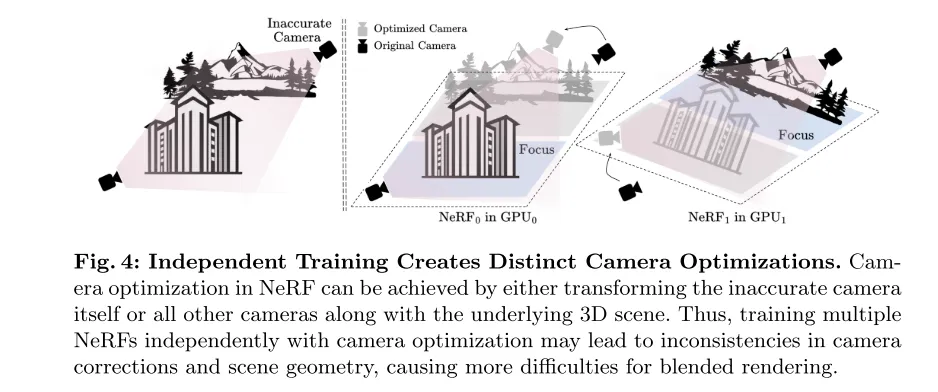
Figure 4: Independent training leads to different camera optimizations. In NeRF, camera optimization can be achieved by transforming the inaccurate camera itself or all other cameras as well as the underlying 3D scene. Therefore, training multiple NeRFs independently along with camera optimization may lead to inconsistencies in camera corrections and scene geometry, which brings more difficulties to hybrid rendering.
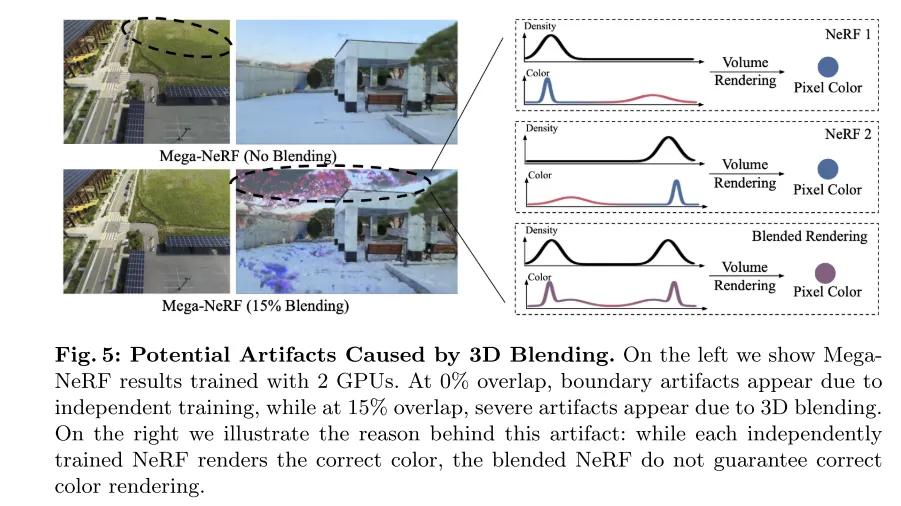
Figure 5: Visual artifacts that may be caused by 3D blending. The image on the left shows the results of MegaNeRF trained using 2 GPUs. At 0% overlap, artifacts appear at the boundaries due to independent training, while at 15% overlap, severe artifacts appear due to 3D blending. The image on the right illustrates the cause of this artifact: while each independently trained NeRF renders the correct color, the blended NeRF does not guarantee correct color rendering.
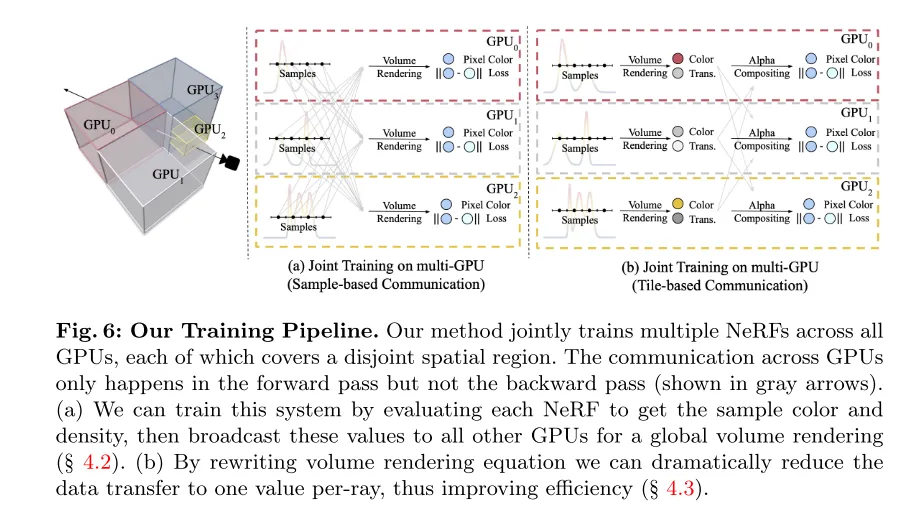
Figure 6: The training process of this article. Our method jointly trains multiple NeRFs on all GPUs, with each NeRF covering a disjoint spatial region. Communication between GPUs only occurs in forward pass and not in backward pass (as indicated by the gray arrow). (a) This paper can be implemented by evaluating each NeRF to obtain sample color and density, and then broadcasting these values to all other GPUs for global volume rendering (see Section 4.2). (b) By rewriting the volume rendering equation, this paper can significantly reduce the amount of data transmission to one value per ray, thus improving efficiency (see Section 4.3).

Figure 7: Qualitative comparison. Compared with previous work, our method effectively leverages multi-GPU configurations and improves performance on all types of data.
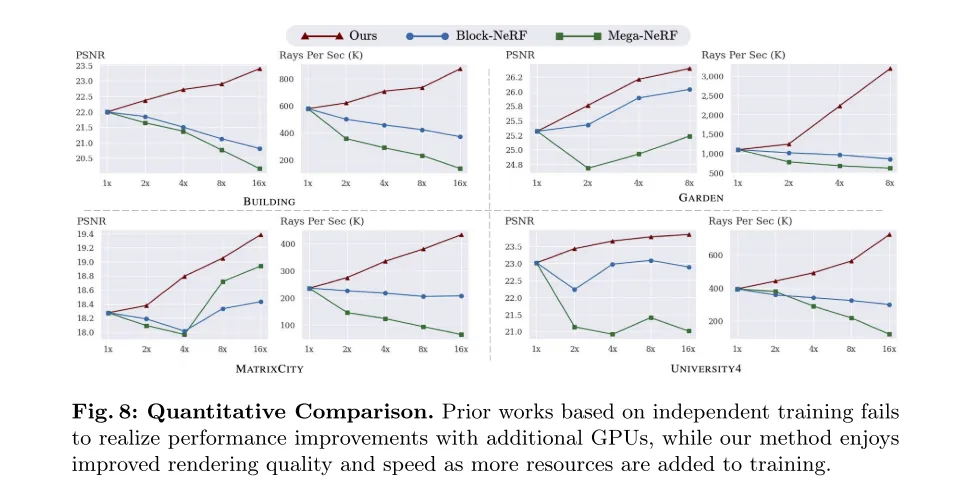
Figure 8: Quantitative comparison. Previous work based on independent training failed to achieve performance improvements with the addition of additional GPUs, while our method enjoys improvements in rendering quality and speed as training resources increase.

Figure 9: Scalability of this article’s method. More GPUs allow for more learnable parameters, which results in greater model capacity and better quality.

Figure 10: More rendering results on the large scale capture. This paper tests the robustness of our method on a larger captured data set using more GPUs. Please see the web page of this article for a video tour of these data.
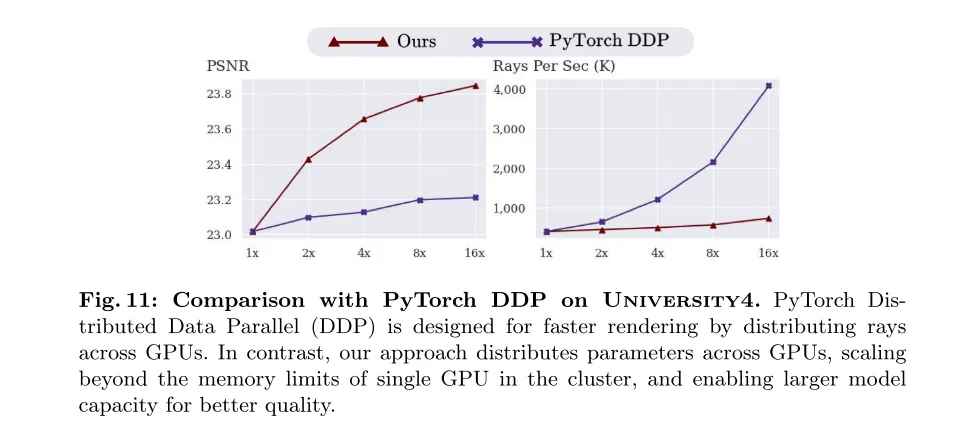
Figure 11: Comparison with PyTorch DDP on University4 dataset. PyTorch Distributed Data Parallel (DDP) is designed to speed up rendering by distributing light across the GPU. In contrast, our method distributes parameters across GPUs, breaking through the memory limitations of a single GPU in the cluster and being able to expand model capacity for better quality.
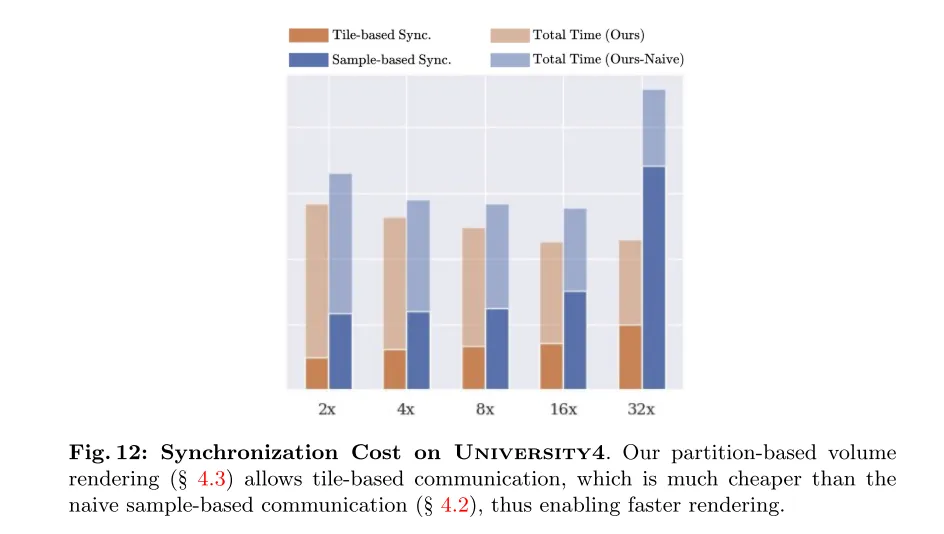
Figure 12: Synchronization cost on University4. Our partition-based volume rendering (see Section 4.3) allows tile-based communication, which is much less expensive than the original sample-based communication (see Section 4.2) and therefore enables faster rendering.
In summary, this paper revisits existing methods of decomposing large-scale scenes into independently trained NeRFs (Neural Radiation Fields) and finds that This presents a significant problem that hinders the efficient utilization of additional computing resources (GPUs), which contradicts the core goal of leveraging multi-GPU setups to improve large-scale NeRF performance. Therefore, this paper introduces NeRF-XL, a principled algorithm capable of efficiently leveraging multi-GPU setups and enhancing NeRF performance at any scale by jointly training multiple non-overlapping NeRFs. Importantly, our method does not rely on any heuristic rules and follows NeRF’s scaling laws in a multi-GPU setting and is applicable to various types of data.
@misc{li2024nerfxl,title={NeRF-XL: Scaling NeRFs with Multiple GPUs}, author={Ruilong Li and Sanja Fidler and Angjoo Kanazawa and Francis Williams},year={2024},eprint={2404.16221},archivePrefix={arXiv},primaryClass={cs.CV}}The above is the detailed content of The largest reconstruction in history of 25km²! NeRF-XL: Really effective use of multi-card joint training!. For more information, please follow other related articles on the PHP Chinese website!
 Is the speed of php8.0 improved?
Is the speed of php8.0 improved?
 What does ps mask mean?
What does ps mask mean?
 Velocity syntax introduction
Velocity syntax introduction
 How to restore Bluetooth headset to binaural mode
How to restore Bluetooth headset to binaural mode
 How is the performance of thinkphp?
How is the performance of thinkphp?
 what is world wide web
what is world wide web
 Win11 My Computer Added to Desktop Tutorial
Win11 My Computer Added to Desktop Tutorial
 What is the difference between hardware firewall and software firewall
What is the difference between hardware firewall and software firewall








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



