


If the test questions are too simple, both top students and bad students can get 90 points, and the gap cannot be widened...
With the development of stronger models such as Claude 3, Llama 3 and even GPT-5 Released, the industry is in urgent need of a more difficult and differentiated benchmark test.
LMSYS, the organization behind the large model arena, launched the next generation benchmark Arena-Hard, which attracted widespread attention.
The latest reference is also available for the strength of the fine-tuned versions of the two instructions of Llama 3.
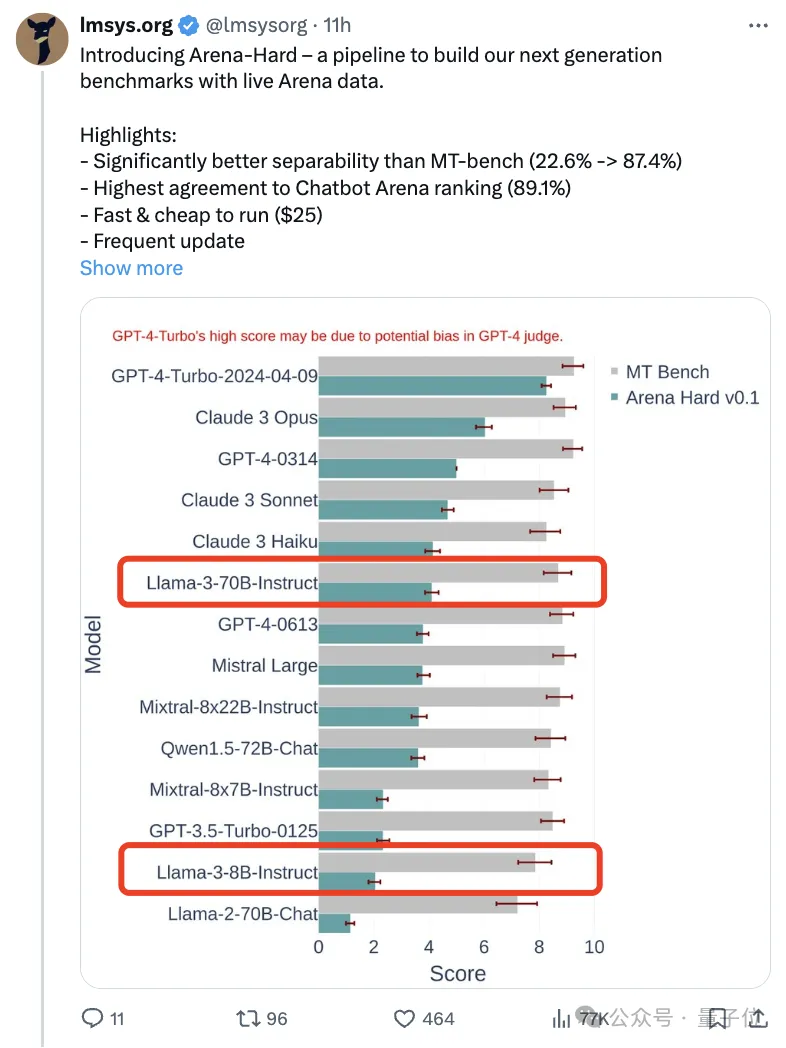
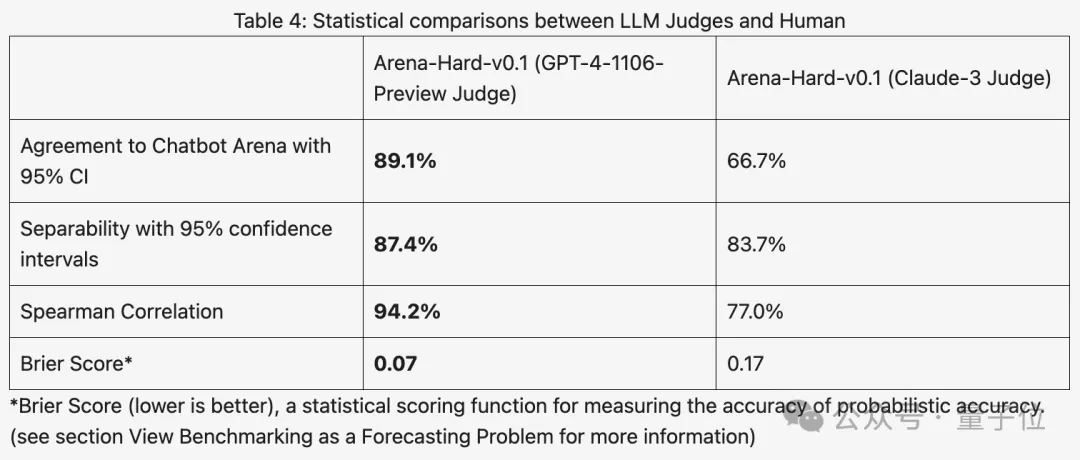
Compared with the previous MT Bench where everyone’s scores were similar, Arena-Hard’s discrimination increased from 22.6% to 87.4%, making it clear which one is stronger and which one is weaker.
Arena-Hard is built using real-time human data from the arena, and the consistency rate with human preferences is as high as 89.1%.
In addition to the above two indicators reaching SOTA, there is an additional benefit:
The real-time updated test data contains new ideas that humans have come up with that AI has never seen in the training phase. prompt words to mitigate potential data breaches.
After releasing a new model, instead of waiting a week or so for human users to vote, just spend $25 to quickly run a test pipeline and get the results.
Some netizens commented that it is really important to use real user prompt words instead of high school exams for testing.

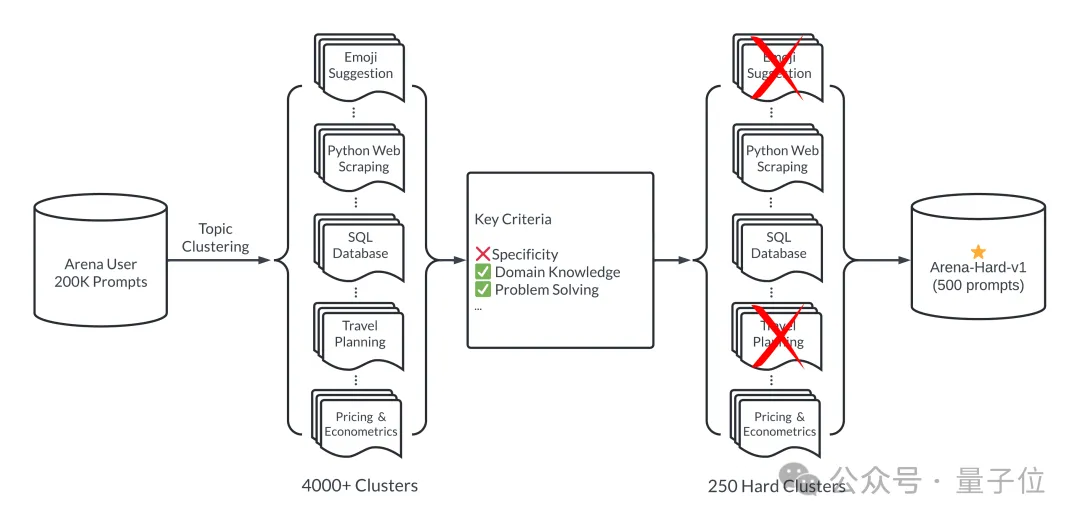
To put it simply, 500 high-quality prompt words are selected as the test set from 200,000 user queries in the large model arena.
First, ensure diversity during the selection process, that is, the test set should cover a wide range of real-world topics.
To ensure this, the team adopted the topic modeling pipeline in BERTopic, first using OpenAI's embedding model (text-embedding-3-small) to convert each prompt, using UMAP to reduce the dimensionality, and using a hierarchical structure based on The model clustering algorithm (HDBSCAN) is used to identify clusters, and finally GPT-4-turbo is used for summary.
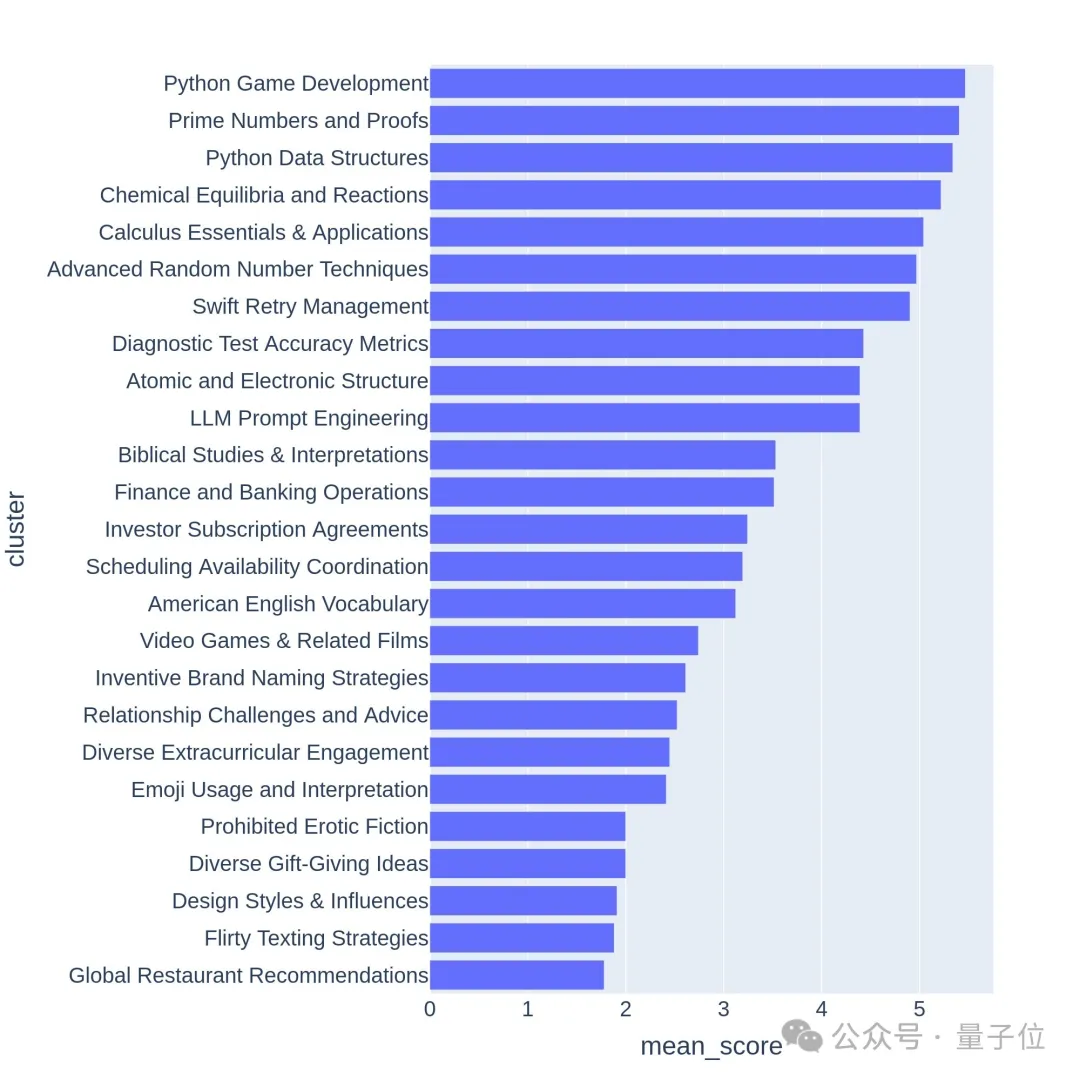
At the same time, ensure that the selected prompt words are of high quality. There are seven key indicators to measure:

Use GPT-3.5-Turbo and GPT-4-Turbo to annotate each prompt from 0 to 7 to determine how many conditions are met. Each cluster is then scored based on the average score of the cues.
High-quality questions are often related to challenging topics or tasks, such as game development or mathematical proofs.
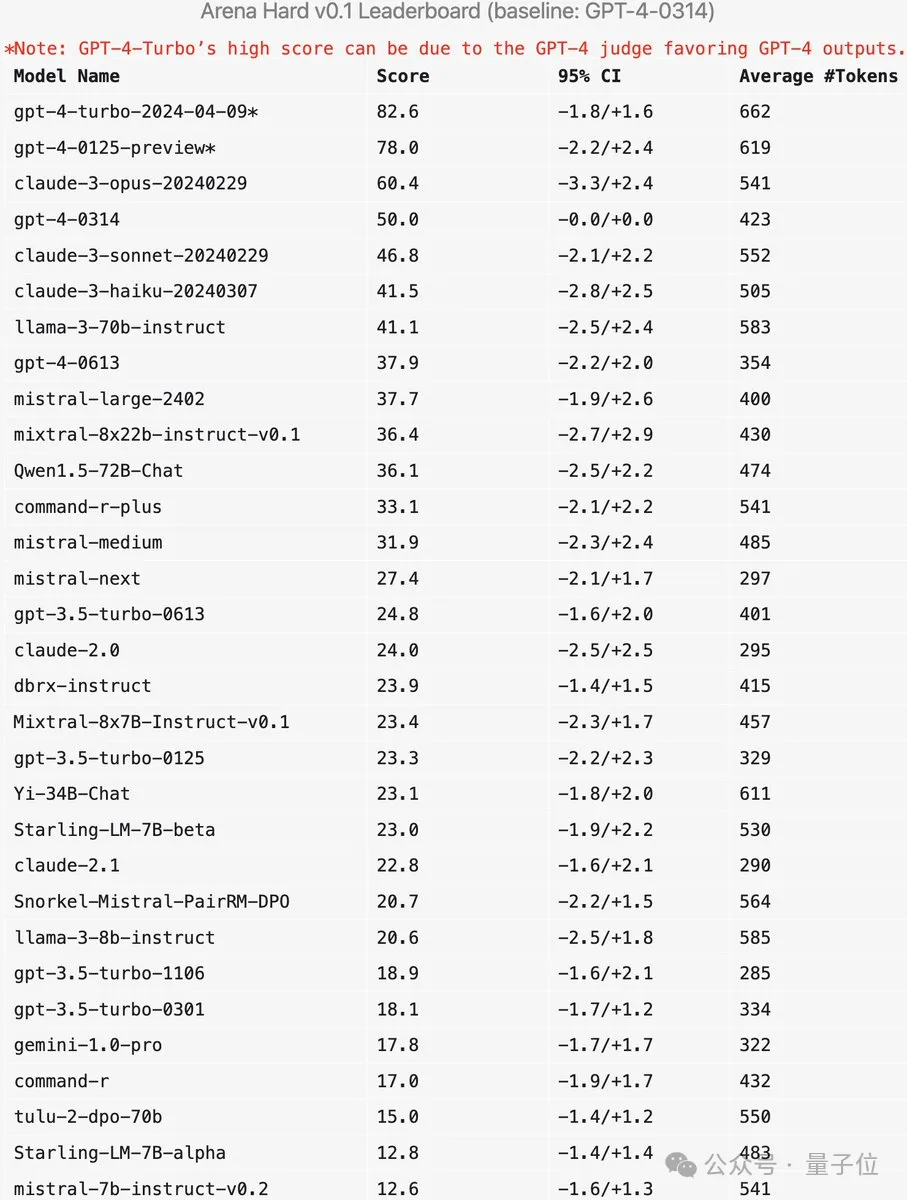
Arena-Hard currently has a weakness: using GPT-4 as a referee prefers its own output. Officials also gave corresponding tips.
It can be seen that the scores of the latest two versions of GPT-4 are much higher than Claude 3 Opus, but the difference in human voting scores is not that obvious.
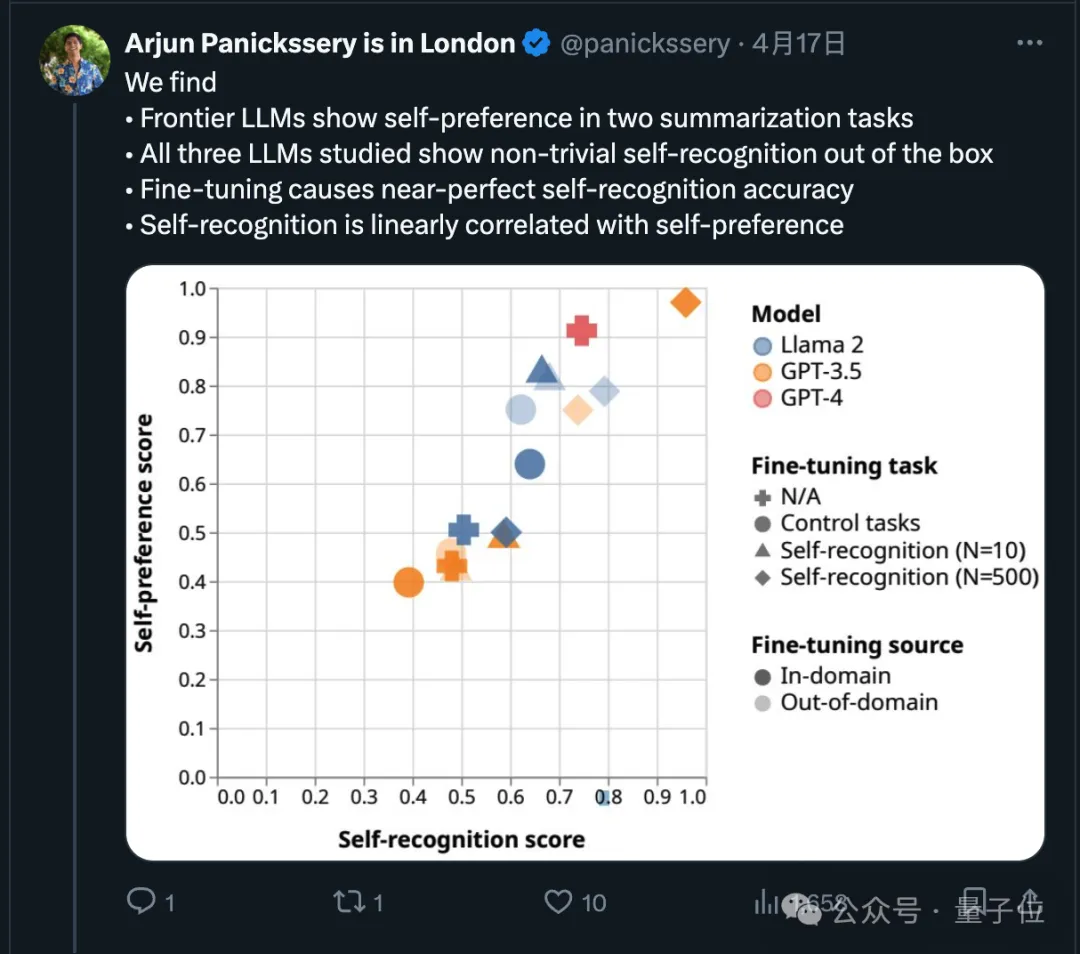
In fact, regarding this point, recent research has demonstrated that cutting-edge models will prefer their own output.

The research team also found that AI can innately determine whether a piece of text was written by itself. After fine-tuning, the self-recognition ability can be enhanced, and the self-recognition ability is consistent with Self-preference is linearly related.
So how will using Claude 3 for scoring change the results? LMSYS has also done relevant experiments.
First of all, the scores of the Claude series will indeed increase.
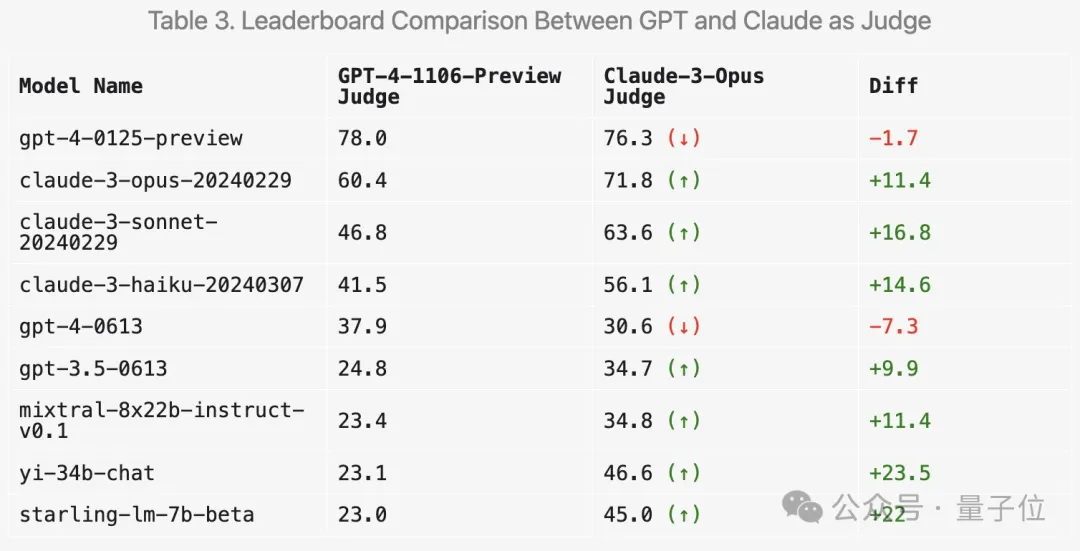
But surprisingly, it prefers several open models such as Mixtral and Zero One Thousand Yi, and even scores significantly higher on GPT-3.5.
Overall, the discrimination and consistency with human results scored using Claude 3 are not as good as GPT-4.
#So many netizens suggest using multiple large models for comprehensive scoring.
#In addition, the team also conducted more ablation experiments to verify the effectiveness of the new benchmark test.
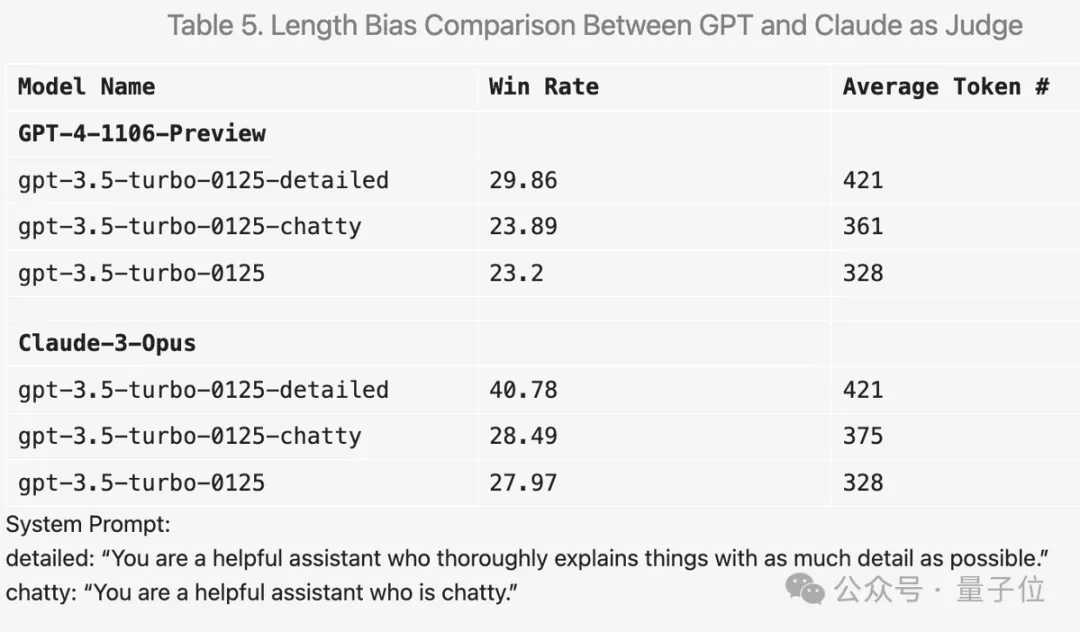
For example, if you add "make the answer as detailed as possible" in the prompt word, the average output length will be higher, and the score will indeed improve.
But if the prompt word is replaced with "likes to chat", the average output length is also improved, but the score improvement is not obvious.
In addition, there were many interesting discoveries during the experiment.
For example, GPT-4 is very strict in scoring and will severely deduct points if there are errors in the answer; while Claude 3 will be lenient even if it recognizes small errors.
For code questions, Claude 3 tends to provide answers with a simple structure, does not rely on external code libraries, and can help humans learn programming; while GPT-4-Turbo prefers the most practical answers, regardless of their educational value. .
In addition, even if the temperature is set to 0, GPT-4-Turbo may produce slightly different judgments.
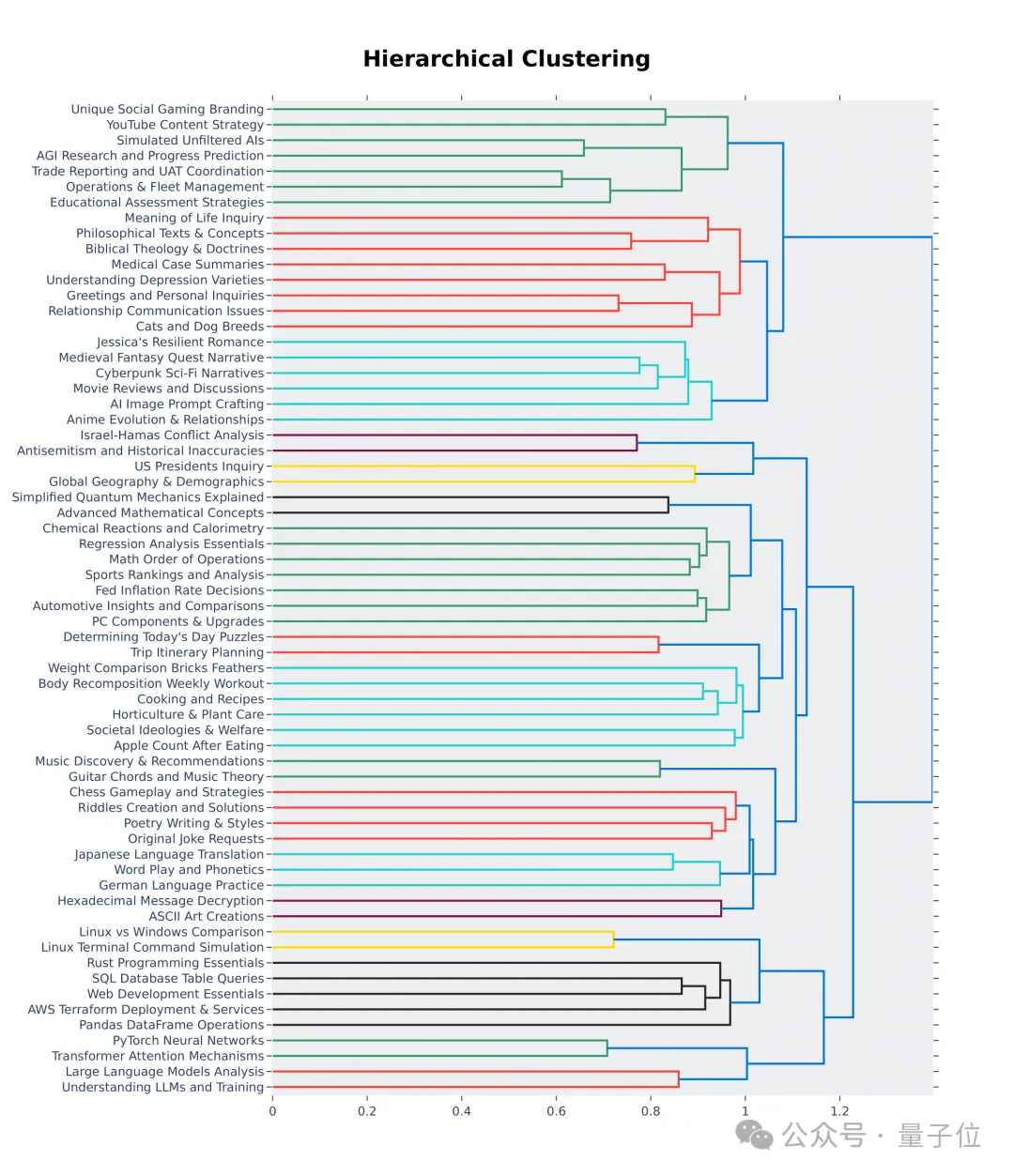
It can also be seen from the first 64 clusters in the hierarchy visualization that the quality and diversity of questions asked by users in the large model arena is indeed high.
Maybe there is your contribution in this.
Arena-Hard GitHub: https://github.com/lm-sys/arena-hard
Arena-Hard HuggingFace: https://huggingface.co/spaces/lmsys/arena-hard- browser
Large model arena: https://arena.lmsys.org
Reference link:
[1]https://x.com/lmsysorg/status/1782179997622649330
[2]https://lmsys.org/blog/2024-04-19-arena-hard/
The above is the detailed content of New test benchmark released, the most powerful open source Llama 3 is embarrassed. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



