


In layman’s terms, a machine learning model is a mathematical function that maps input data to a predicted output. More specifically, a machine learning model is a mathematical function that adjusts model parameters by learning from training data to minimize the error between the predicted output and the true label.
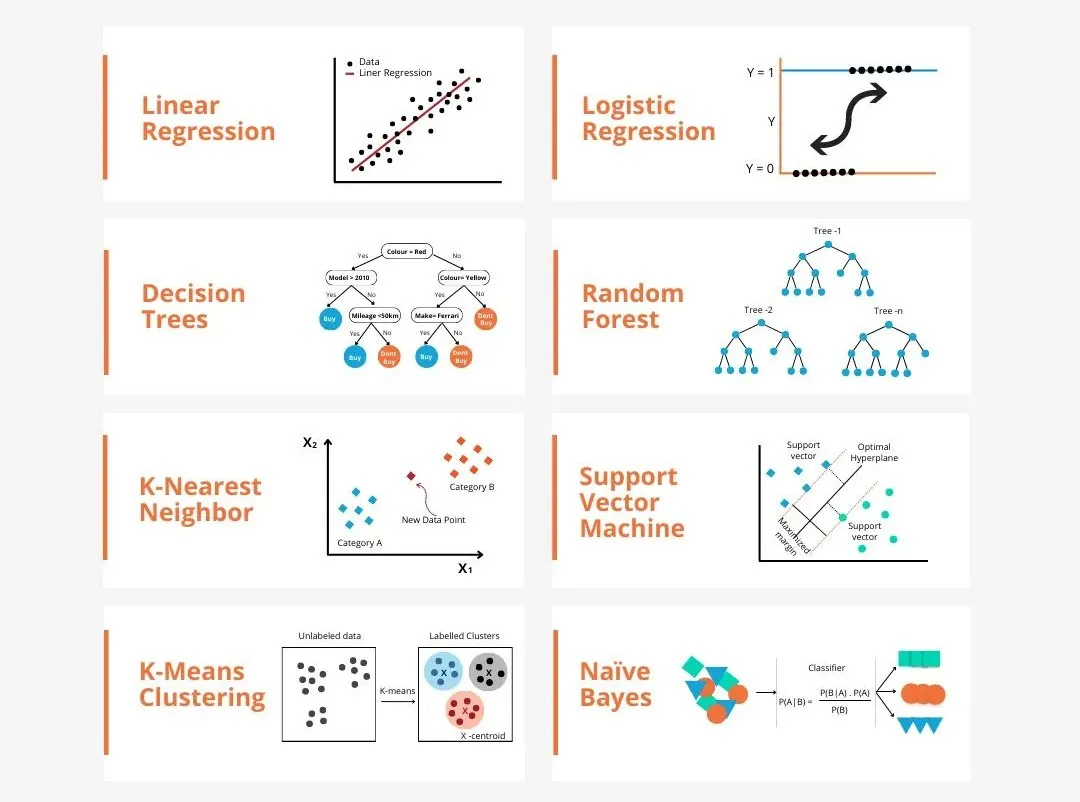
There are many models in machine learning, such as logistic regression model, decision tree model, support vector machine model, etc. Each model has its application data types and question types. At the same time, there are many commonalities between different models, or there is a hidden path for model evolution.
Take the connectionist perceptron as an example. By increasing the number of hidden layers of the perceptron, we can transform it into a deep neural network. If a kernel function is added to the perceptron, it can be converted into an SVM. This process can intuitively demonstrate the intrinsic connections between different models, as well as the possible transformations between models. According to the similarities, I roughly (not rigorously) divided the models into the following 6 categories to facilitate the discovery of basic commonalities and analyze them in depth one by one!
The connectionist model is a computing model that simulates the structure and function of the human brain neural network. . Its basic unit is a neuron. Each neuron receives input from other neurons and changes the influence of the input on the neuron by adjusting the weight. The neural network is a black box. Through the action of multiple nonlinear hidden layers, it can achieve close to the effect.

Representative models include DNN, SVM, Transformer, and LSTM. In some cases, the last layer of the deep neural network can be regarded as a logic Regression model used to classify input data. The support vector machine can also be regarded as a special type of neural network. There are only two layers in it: the input layer and the output layer. SVM additionally implements complex nonlinear transformation through kernel functions to achieve results similar to deep neural networks. Effect. The following is an analysis of the principle of the classic DNN model:
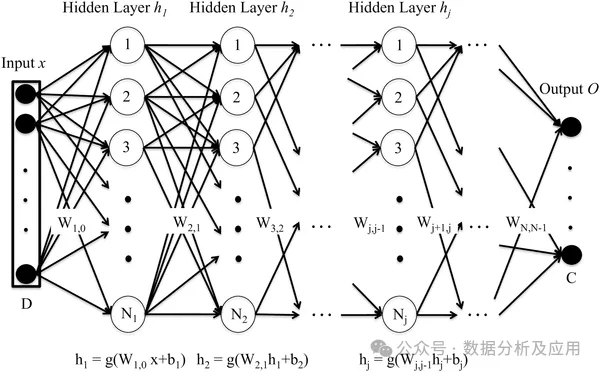
Deep neural network (DNN) is composed of multiple layers of neurons and passes the input data through the forward propagation process. To each layer of neurons, the output is obtained through layer-by-layer calculation. Each layer of neurons receives the output of the previous layer's neurons as input and outputs it to the next layer's neurons. The training process of DNN is implemented through the back propagation algorithm. During the training process, the error between the output layer and the real label is calculated, the error is back-propagated to each layer of neurons, and the weights and bias terms of the neurons are updated according to the gradient descent algorithm. By repeatedly iterating this process, the network parameters are continuously optimized, and the prediction error of the network is ultimately minimized.
The advantage of deep neural network (DNN) is its powerful feature learning ability. DNN can automatically learn the characteristics of data without manually designing features. Highly nonlinear and strong generalization ability. The disadvantage is that DNN requires a large number of parameters, which may lead to overfitting problems. At the same time, DNN requires a large amount of calculation and takes a long time to train. The following is a simple Python code example, using the Keras library to build a deep neural network model:
from keras.models import Sequentialfrom keras.layers import Densefrom keras.optimizers import Adamfrom keras.losses import BinaryCrossentropyimport numpy as np# 构建模型model = Sequential()model.add(Dense(64, activatinotallow='relu', input_shape=(10,))) # 输入层有10个特征model.add(Dense(64, activatinotallow='relu')) # 隐藏层有64个神经元model.add(Dense(1, activatinotallow='sigmoid')) # 输出层有1个神经元,使用sigmoid激活函数进行二分类任务# 编译模型model.compile(optimizer=Adam(lr=0.001), loss=BinaryCrossentropy(), metrics=['accuracy'])# 生成模拟数据集x_train = np.random.rand(1000, 10) # 1000个样本,每个样本有10个特征y_train = np.random.randint(2, size=1000) # 1000个标签,二分类任务# 训练模型model.fit(x_train, y_train, epochs=10, batch_size=32) # 训练10个轮次,每次使用32个样本进行训练
Symbolism model is an intelligent simulation method based on logical reasoning. It believes that human beings are a physical symbol system and computers are also physical symbol systems. Therefore, the computer’s rule base and reasoning engine can be used to simulate human beings. Intelligent behavior is to use computer symbolic operations to simulate human cognitive processes (to put it bluntly, it is to store human logic into computers to achieve intelligent execution).
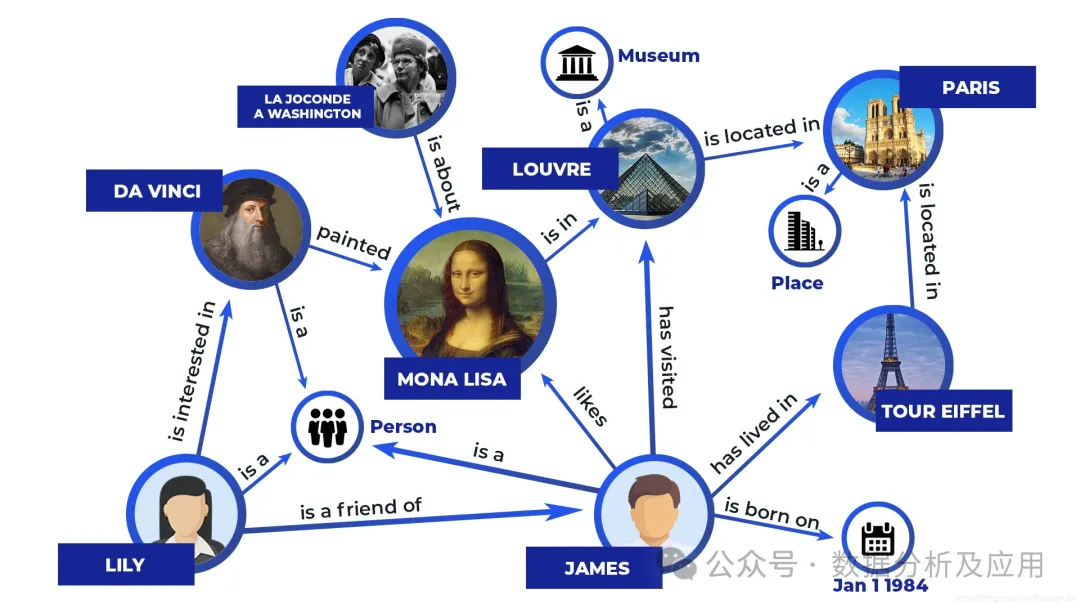
The representative models include expert systems, knowledge bases, and knowledge graphs. The principle is to encode information into a set of identifiable symbols, through explicit Rules for manipulating symbols to produce results. A simple example of an expert system is as follows:
# 定义规则库rules = [{"name": "rule1", "condition": "sym1 == 'A' and sym2 == 'B'", "action": "result = 'C'"},{"name": "rule2", "condition": "sym1 == 'B' and sym2 == 'C'", "action": "result = 'D'"},{"name": "rule3", "condition": "sym1 == 'A' or sym2 == 'B'", "action": "result = 'E'"},]# 定义推理引擎def infer(rules, sym1, sym2):for rule in rules:if rule["condition"] == True:# 条件为真时执行动作return rule["action"]return None# 没有满足条件的规则时返回None# 测试专家系统print(infer(rules, 'A', 'B'))# 输出: Cprint(infer(rules, 'B', 'C'))# 输出: Dprint(infer(rules, 'A', 'C'))# 输出: Eprint(infer(rules, 'B', 'B'))# 输出: E
决策树模型是一种非参数的分类和回归方法,它利用树形图表示决策过程。更通俗来讲,树模型的数学描述就是“分段函数”。它利用信息论中的熵理论选择决策树的最佳划分属性,以构建出一棵具有最佳分类性能的决策树。
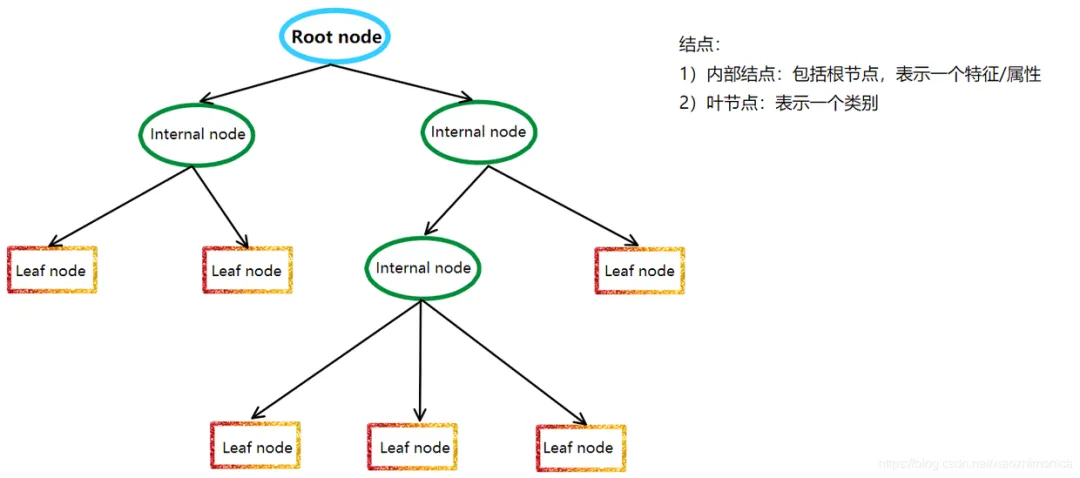
决策树模型的基本原理是递归地将数据集划分成若干个子数据集,直到每个子数据集都属于同一类别或者满足某个停止条件。在划分过程中,决策树模型采用信息增益、信息增益率、基尼指数等指标来评估划分的好坏,以选择最佳的划分属性。
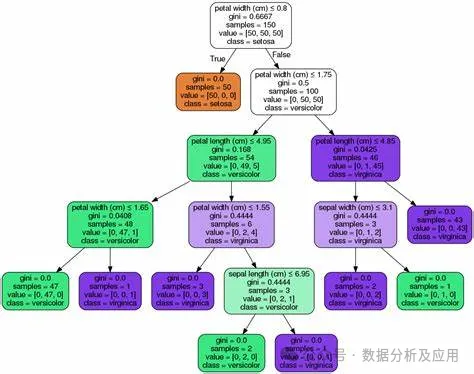
决策树模型的代表模型有很多,其中最著名的有ID3、C4.5、CART等。ID3算法是决策树算法的鼻祖,它采用信息增益来选择最佳划分属性;C4.5算法是ID3算法的改进版,它采用信息增益率来选择最佳划分属性,同时采用剪枝策略来提高决策树的泛化能力;CART算法则是分类和回归树的简称,它采用基尼指数来选择最佳划分属性,并能够处理连续属性和有序属性。
以下是使用Python中的Scikit-learn库实现CART算法的代码示例:
from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.tree import DecisionTreeClassifier, plot_tree# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建决策树模型clf = DecisionTreeClassifier(criterinotallow='gini')clf.fit(X_train, y_train)# 预测测试集结果y_pred = clf.predict(X_test)# 可视化决策树plot_tree(clf)
概率模型是一种基于概率论的数学模型,用于描述随机现象或事件的分布、发生概率以及它们之间的概率关系。概率模型在各个领域都有广泛的应用,如统计学、经济学、机器学习等。
概率模型的原理基于概率论和统计学的基本原理。它使用概率分布来描述随机变量的分布情况,并使用概率规则来描述事件之间的条件关系。通过这些原理,概率模型可以对随机现象或事件进行定量分析和预测。
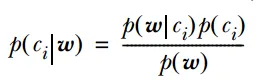
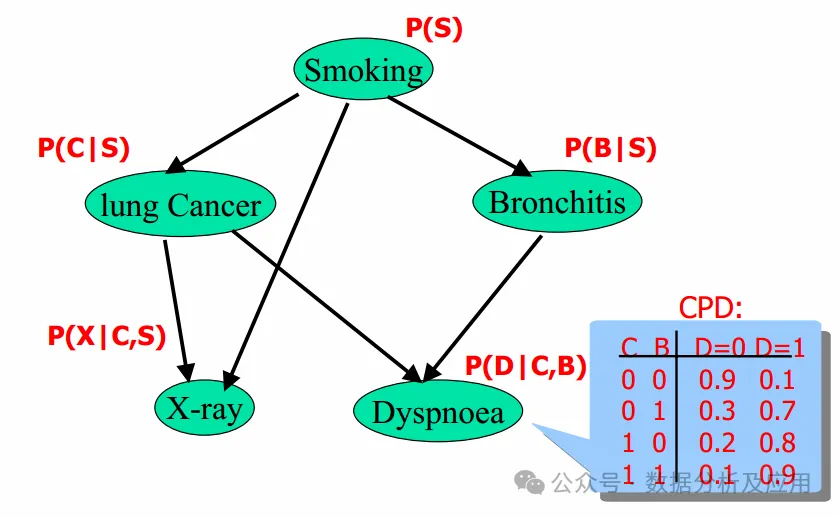
代表模型主要有:朴素贝叶斯分类器、贝叶斯网络、隐马尔可夫模型。其中,朴素贝叶斯分类器和逻辑回归都基于贝叶斯定理,它们都使用概率来表示分类的不确定性。
隐马尔可夫模型和贝叶斯网络都是基于概率的模型,可用于描述随机序列和随机变量之间的关系。
朴素贝叶斯分类器和贝叶斯网络都是基于概率的图模型,可用于描述随机变量之间的概率关系。
以下是使用Python中的Scikit-learn库实现朴素贝叶斯分类器的代码示例:
from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNB# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建朴素贝叶斯分类器模型clf = GaussianNB()clf.fit(X_train, y_train)# 预测测试集结果y_pred = clf.predict(X_test)
近邻类模型(本来想命名为距离类模型,但是距离类的定义就比较宽泛了)是一种非参数的分类和回归方法,它基于实例的学习不需要明确的训练和测试集的划分。它通过测量不同数据点之间的距离来决定数据的相似性。
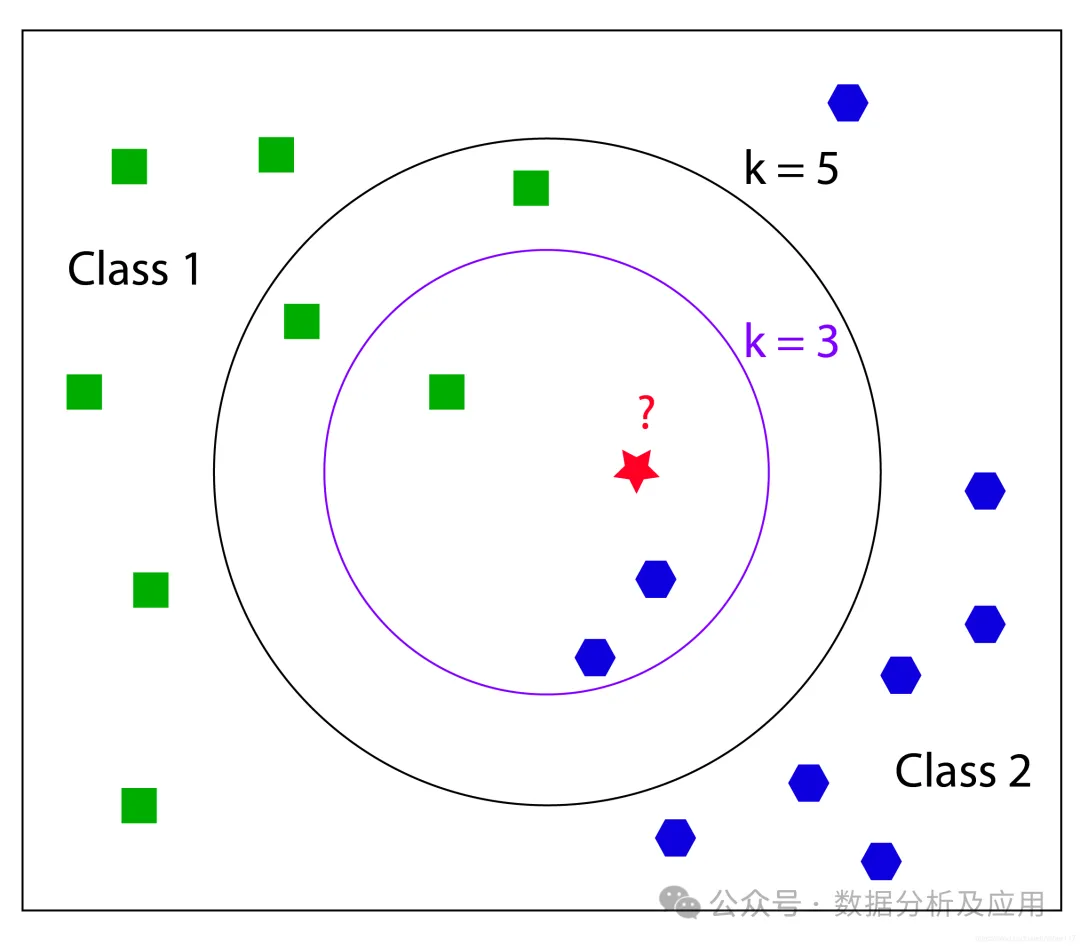
以KNN算法为例,其核心思想是,如果一个样本在特征空间中的 k 个最接近的训练样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法基于实例的学习不需要明确的训练和测试集的划分,而是通过测量不同数据点之间的距离来决定数据的相似性。
代表模型有:k-近邻算法(k-Nearest Neighbors,KNN)、半径搜索(Radius Search)、K-means、权重KNN、多级分类KNN(Multi-level Classification KNN)、近似最近邻算法(Approximate Nearest Neighbor, ANN)
近邻模型基于相似的原理,即通过测量不同数据点之间的距离来决定数据的相似性。
除了最基础的KNN算法外,其他变种如权重KNN和多级分类KNN都在基础算法上进行了改进,以更好地适应不同的分类问题。
近似最近邻算法(ANN)是一种通过牺牲精度来换取时间和空间的方式,从大量样本中获取最近邻的方法。ANN算法通过降低存储空间和提高查找效率来处理大规模数据集。它通过“近似”的方法来减少搜索时间,这种方法允许在搜索过程中存在少量误差。
以下是使用Python中的Scikit-learn库实现KNN算法的代码示例:
from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.neighbors import KNeighborsClassifier# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建KNN分类器模型knn = KNeighborsClassifier(n_neighbors=3)knn.fit(X_train, y_train)# 预测测试集结果y_pred = knn.predict(X_test)
集成学习(Ensemble Learning)不仅仅是一类的模型,更是一种多模型融合的思想,通过将多个学习器的预测结果进行合并,以提高整体的预测精度和稳定性。在实际应用中,集成学习无疑是数据挖掘的神器!
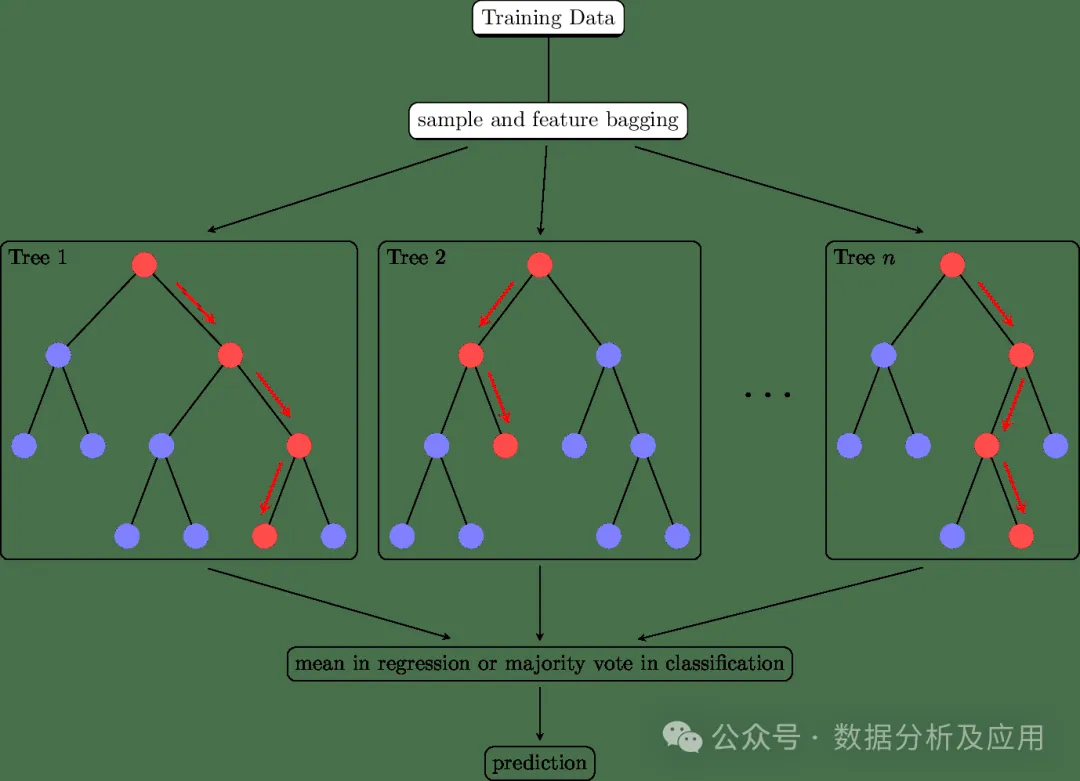
集成学习的核心思想是通过集成多个基学习器来提高整体的预测性能。具体来说,通过将多个学习器的预测结果进行合并,可以减少单一学习器的过拟合和欠拟合问题,提高模型的泛化能力。同时,通过引入多样性(如不同的基学习器、不同的训练数据等),可以进一步提高模型的性能。常用的集成学习方法有:
集成学习代表模型有:随机森林、孤立森林、GBDT、Adaboost、Xgboost等。以下是使用Python中的Scikit-learn库实现随机森林算法的代码示例:
from sklearn.ensemble import RandomForestClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split# 加载数据集iris = load_iris()X = iris.datay = iris.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建随机森林分类器模型clf = RandomForestClassifier(n_estimators=100, random_state=42)clf.fit(X_train, y_train)# 预测测试集结果y_pred = clf.predict(X_test)
综上,我们通过将相似原理的模型归纳为各种类别,以此逐个类别地探索其原理,可以更为系统全面地了解模型的原理及联系。希望对大家有所帮助!
The above is the detailed content of Transparent! An in-depth analysis of the principles of major machine learning models!. For more information, please follow other related articles on the PHP Chinese website!





























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



