


「擴散模型」也能攻克演算法難題?
 圖片
圖片
一位博士研究人員做了一個有趣的實驗,用「離散擴散」尋找用圖像表示的迷宮中的最短路徑。
 圖片
圖片
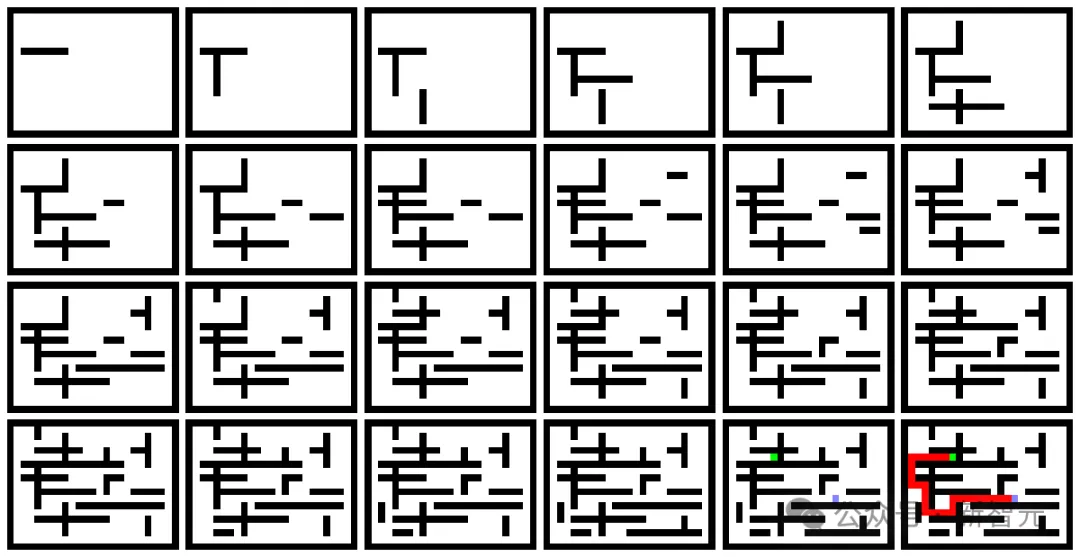
作者介紹,每個迷宮都是透過重複添加水平和垂直牆生成的。
其中,起始點和目標點隨機選取。
從起點到目標點的最短路徑中,隨機取樣一條作為解的路徑。最短路徑是透過精確演算法算出來的。
 圖片
圖片
然後使用離散擴散模型和U-Net。
將起點和目標的迷宮被編碼在一個通道中,而模型在另一個通道中用解來消除迷宮的雜訊。
 圖片
圖片
再難一點的迷宮,也能做的很好。
 圖片
圖片
為了估算去雜訊步驟p(x_{t-1} | x_t),演算法會估算p( x_0 | x_t)。在這個過程中可視化這一估計值(底行),顯示“當前假設”,最終聚焦在結果上。
 圖片
圖片
英偉達資深科學家Jim Fan表示,這是一個有趣的實驗,擴散模型可以「渲染」演算法。它可以只從像素實現迷宮遍歷,甚至使用了比Transforme弱得多的U-Net。
我一直認為擴散模型是渲染器,而Transformer是推理引擎。看起來,渲染器本身也可以編碼非常複雜的順序演算法。
 圖片
圖片
這個實驗簡直驚呆了網友,「擴散模型還能做什麼?!」
 圖片
圖片
也有人表示,一旦有人在足夠好的資料集上訓練擴散Transformer,AGI就解決了。
 圖片
圖片
不過這項研究尚未正式發布,作者表示稍後更新在arxiv上。
值得一提的是,在這個實驗中,他們採用了Google腦團隊曾在2021年提出的離散擴散模型。
 圖片
圖片
就在最近,這項研究重新更新了一版。
「生成模型」是機器學習中的核心問題。
它既可用於衡量我們擷取自然資料集統計資料的能力,也可用於需要產生影像、文字和語音等高維度資料的下游應用程式。
GAN, VAE, large autoregressive neural network models, normalized flow and other methods have their own advantages in sample quality, sampling speed, log likelihood, and training stability.
Recently, the "diffusion model" has become the most popular alternative for image and audio generation.
It can achieve sample quality comparable to GAN and log-likelihood comparable to autoregressive models with fewer inference steps.
 Picture
Picture
Paper address: //m.sbmmt.com/link/46994a3cd8d943d03b44b8fc9792d435
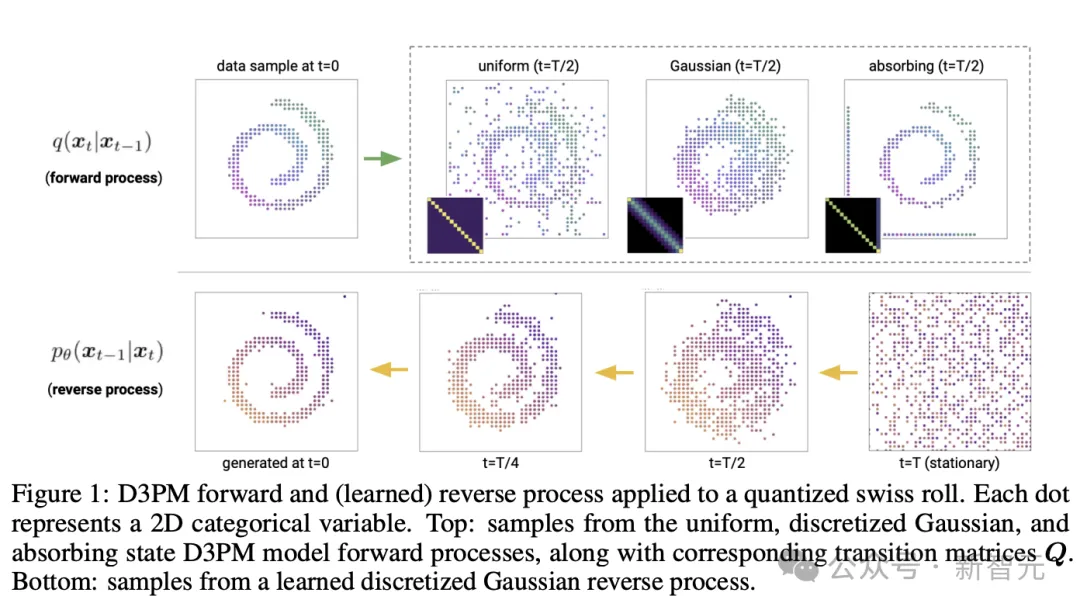
Although diffusion models for discrete and continuous state spaces have been proposed, recent research has mainly focused on Gaussian diffusion processes operating in continuous state spaces (such as real-valued images and waveform data).
Discrete state space diffusion models have been explored in the field of text and image segmentation, but have not yet proven to be a competitive solution in large-scale text and image generation tasks. model.
The Google research team proposed a new discrete denoising diffusion probability model (D3PM).
In the study, the authors demonstrate that the choice of transition matrix is an important design decision that can improve results in both image and text domains.
Additionally, they proposed a new loss function that combines a variational lower bound and an auxiliary cross-entropy loss.
In terms of text, this model achieves good results in character-level text generation and can be extended to the large vocabulary LM1B dataset.
On the CIFAR-10 image dataset, the latest model approaches the sample quality of the continuous space DDPM model and exceeds the log-likelihood of the continuous space DDPM model.
 Picture
Picture
Arnaud Pannatier

Arnaud Pannatier started studying for his PhD in March 2020 in the machine learning group of his supervisor François Fleuret.
He recently developed HyperMixer, which uses a super network to enable MLPMixer to handle inputs of various lengths. This enables the model to process the input in a permutation-invariant manner and has been shown to give the model an attentional behavior that scales linearly with the length of the input.
At EPFL, he earned a bachelor’s degree in physics and a master’s degree in computer science and engineering (CSE-MASH).
The above is the detailed content of Diffusion model overcomes algorithmic problems, AGI is not far away! Google Brain finds the shortest path in a maze. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



