



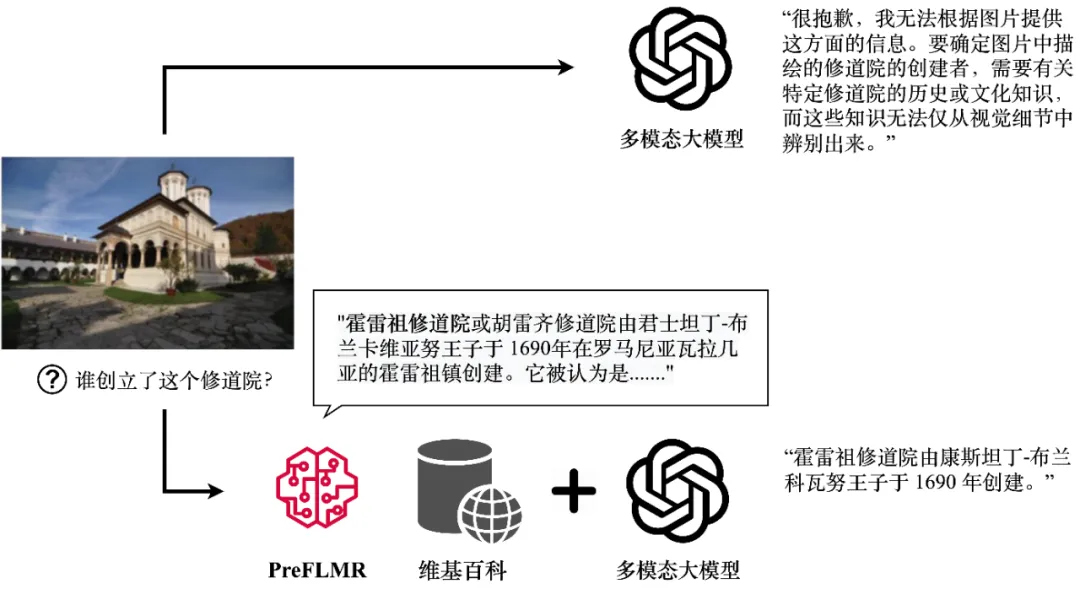
 GPT4-Vision can obtain relevant knowledge through the PreFLMR multi-modal knowledge retriever and generate accurate answers. The figure shows the actual output of the model.
GPT4-Vision can obtain relevant knowledge through the PreFLMR multi-modal knowledge retriever and generate accurate answers. The figure shows the actual output of the model.
Retrieval-Augmented Generation (RAG) provides a simple and effective way to solve this problem, making multi-modal large models become like "domains" in a certain field Experts". Its working principle is as follows: first, use a lightweight knowledge retriever (Knowledge Retriever) to retrieve relevant professional knowledge from professional databases (such as Wikipedia or enterprise knowledge bases); then, the large-scale model takes this knowledge and questions as input and outputs Accurate answer. The knowledge "recall ability" of multi-modal knowledge extractors directly affects whether large-scale models can obtain accurate professional knowledge when answering reasoning questions.
Recently,
The Artificial Intelligence Laboratory of the Department of Information Engineering, University of Cambridge has completely open sourced the first pre-trained, universal multi-modal post-interactive knowledge retrieval PreFLMR(Pre- trained Fine-grained Late-interaction Multi-modal Retriever). Compared with previous common models, PreFLMR has the following characteristics:
PreFLMR is a general pre-training model that can effectively solve multiple sub-tasks such as text retrieval, image retrieval and knowledge retrieval. Pre-trained on millions of levels of multi-modal data, the model performs well in multiple downstream retrieval tasks. In addition, as an excellent basic model, PreFLMR can quickly develop into an excellent domain-specific model after fine-tuning for private data.
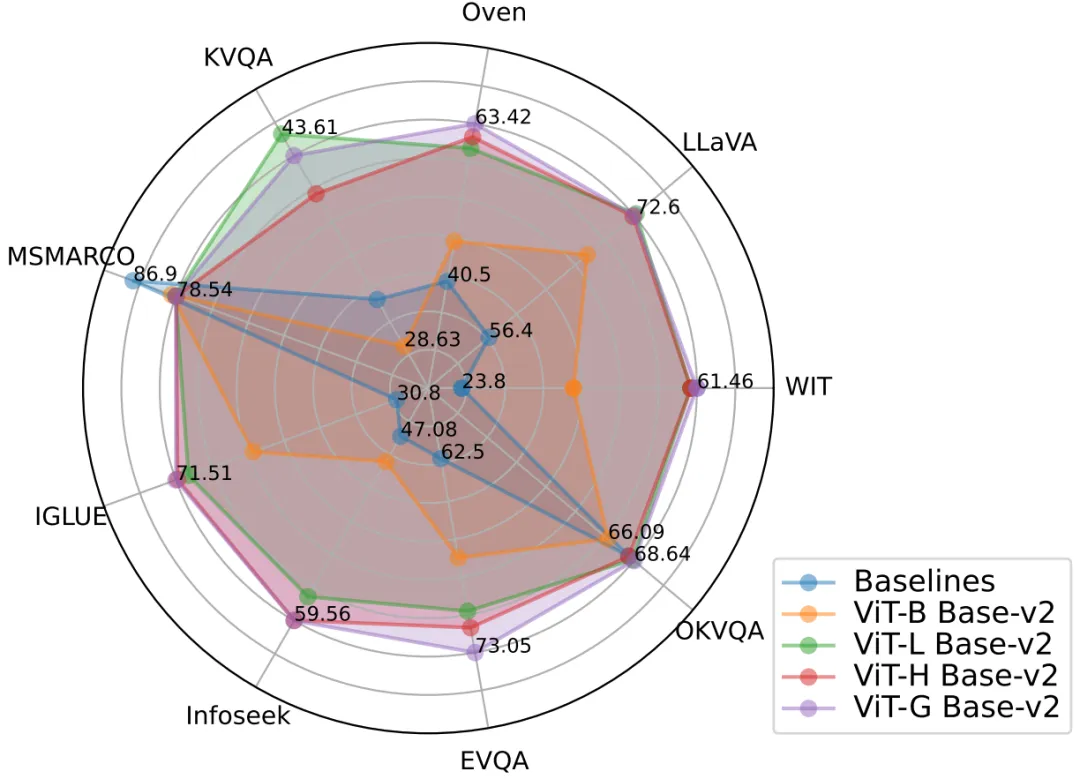
Figure 2: The PreFLMR model achieves excellent multi-modal retrieval performance on multiple tasks at the same time and is an extremely strong pre-training base. Model.
2. Traditional Dense Passage Retrieval (DPR) only uses one vector to represent the query (Query) or document (Document). The FLMR model published by the Cambridge team at NeurIPS 2023 proved that the single-vector representation design of DPR can lead to fine-grained information loss, causing DPR to perform poorly on retrieval tasks that require fine information matching. Especially in multi-modal tasks, the user's query contains complex scene information, and compressing it into a one-dimensional vector greatly inhibits the expressive ability of features. PreFLMR inherits and improves the structure of FLMR, giving it unique advantages in multi-modal knowledge retrieval.
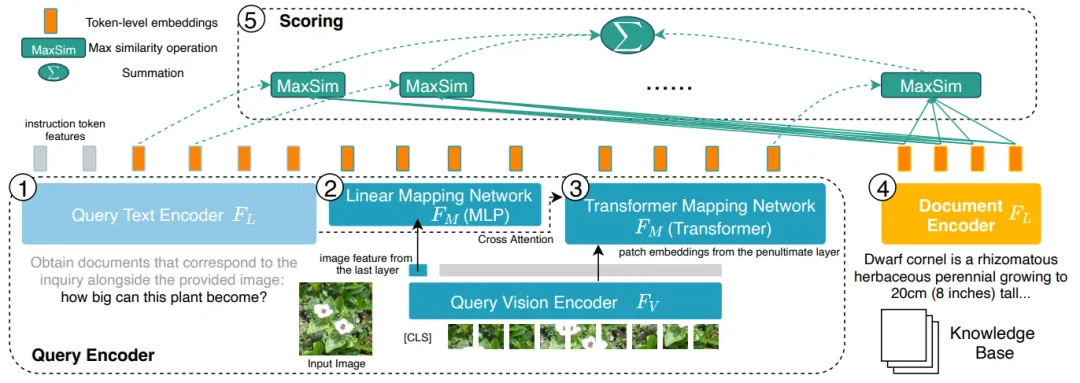
Figure 3: PreFLMR encodes the query (Query, 1, 2 on the left) at the character level (Token level) , 3) and Document (Document, 4 on the right), compared with the DPR system that compresses all information into one-dimensional vectors, it has the advantage of fine-grained information.
3. PreFLMR can extract documents related to the items in the picture according to the instructions entered by the user (such as "Extract documents that can be used to answer the following questions" or "Extract documents related to the items in the picture"). Relevant documents are extracted from the knowledge base to help multi-modal large models significantly improve the performance of professional knowledge question and answer tasks.


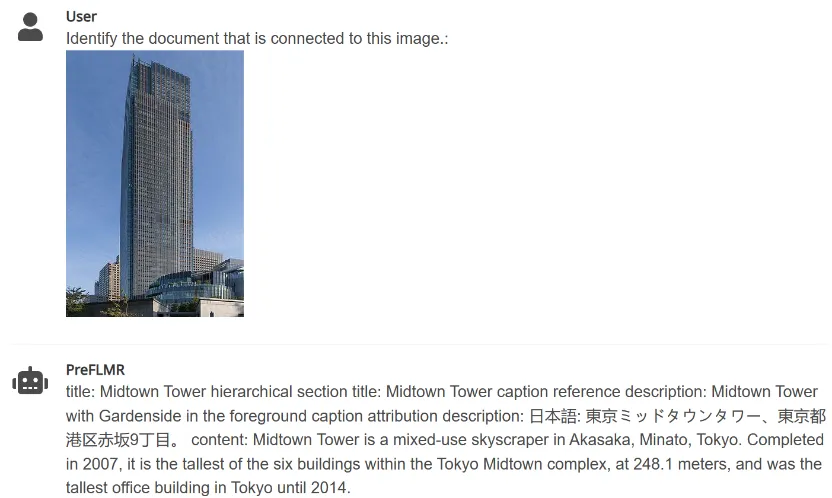
Figure 4: PreFLMR can simultaneously process multi-modal queries that extract documents from pictures, extract documents based on questions, and extract documents based on questions and pictures together. Task.
The Cambridge University team has open sourced three models of different sizes. The parameters of the models from small to large are:PreFLMR_ViT-B (207M), PreFLMR_ViT-L (422M) ), PreFLMR_ViT-G (2B), for users to choose according to actual conditions.
In addition to the open source model PreFLMR itself, this project has also made two important contributions in this research direction:
The following will briefly introduce the M2KR data set, PreFLMR model and experimental result analysis.
To pretrain and evaluate general multi-modal retrieval models at scale, the authors compiled ten publicly available datasets and convert it into a unified question-document retrieval format. The original tasks of these data sets include image captioning, multi-modal dialogue, etc. The figure below shows the questions (first row) and corresponding documents (second row) for five of the tasks.

Figure 5: Part of the knowledge extraction task in the M2KR dataset
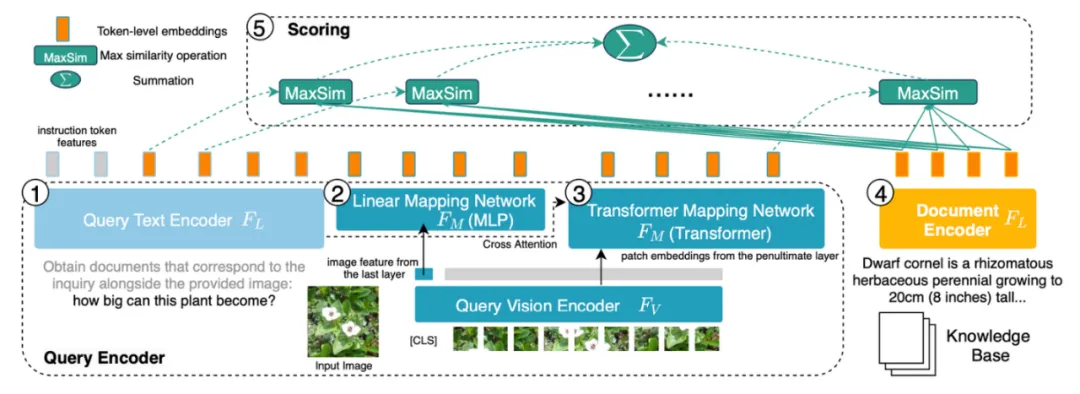
# Figure 6: Model structure of PreFLMR. Query is encoded as a Token-level feature. For each vector in the query matrix, PreFLMR finds the nearest vector in the document matrix and calculates the dot product, and then sums these maximum dot products to obtain the final relevance.
The PreFLMR model is based on the Fine-grained Late-interaction Multi-modal Retriever (FLMR) published in NeurIPS 2023 and undergoes model improvements and large-scale pre-training on M2KR. Compared with DPR, FLMR and PreFLMR use a matrix composed of all token vectors to characterize documents and queries. Tokens include text tokens and image tokens projected into the text space. Late interaction is an algorithm for efficiently calculating the correlation between two representation matrices. The specific method is: for each vector in the query matrix, find the nearest vector in the document matrix and calculate the dot product. These maximum dot products are then summed to obtain the final correlation. In this way, each token's representation can explicitly affect the final correlation, thus preserving token-level fine-grained information. Thanks to a dedicated post-interactive retrieval engine, PreFLMR can extract 100 relevant documents out of 400,000 documents in just 0.2 seconds, which greatly improves usability in RAG scenarios.
The pre-training of PreFLMR consists of the following four stages:
At the same time, the authors show that PreFLMR can be further fine-tuned on sub-datasets (such as OK-VQA, Infoseek) to obtain better retrieval performance on specific tasks.
Best retrieval results: The best performing PreFLMR model uses ViT-G as the image encoder and ColBERT -base-v2 as text encoder, two billion parameters in total. It achieves performance beyond baseline models on 7 M2KR retrieval subtasks (WIT, OVEN, Infoseek, E-VQA, OKVQA, etc.).
Extended visual encoding is more effective: The author found that upgrading the image encoder ViT from ViT-B (86M) to ViT-L (307M) brought significant performance improvements, but upgrading the text encoder ColBERT from Expanding base (110M) to large (345M) resulted in performance degradation and training instability. Experimental results show that for later interactive multi-modal retrieval systems, increasing the parameters of the visual encoder brings greater returns. At the same time, using multiple layers of Cross-attention for image-text projection has the same effect as using a single layer, so the design of the image-text projection network does not need to be too complicated.
PreFLMR makes RAG more effective: On knowledge-intensive visual question answering tasks, retrieval enhancement using PreFLMR greatly improves the performance of the final system: reaching 94% on Infoseek and EVQA respectively And an effect improvement of 275%. After simple fine-tuning, the model based on BLIP-2 can beat the PALI-X model with hundreds of billions of parameters and the PaLM-Bison Lens system enhanced with Google API.
The PreFLMR model proposed by Cambridge Artificial Intelligence Laboratory is the first open source general late interactive multi-modal retrieval model. After pre-training on millions of data on M2KR, PreFLMR shows strong performance in multiple retrieval subtasks. The M2KR dataset, PreFLMR model weights and code are available on the project homepage https://preflmr.github.io/.
Expand resources
The above is the detailed content of Cambridge team's open source: empowering multi-modal large model RAG applications, the first pre-trained universal multi-modal post-interactive knowledge retriever. For more information, please follow other related articles on the PHP Chinese website!
 Introduction to SSL detection tools
Introduction to SSL detection tools oracle database recovery method
oracle database recovery method How to solve the problem of forgetting the power-on password of Windows 8 computer
How to solve the problem of forgetting the power-on password of Windows 8 computer The difference between threads and processes
The difference between threads and processes MySQL restore database
MySQL restore database How to export Apipost offline
How to export Apipost offline What are the application areas of mongodb?
What are the application areas of mongodb? How to set up the router
How to set up the router




















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



